Command Palette
Search for a command to run...
نموذج خفيف الوزن 270M! يركز Gemma-3-270M-IT على تفاعل النصوص الطويلة البسيط؛ الخيار الأمثل لوكلاء واجهة المستخدم الرسومية متعددي المنصات! يغطي AgentNet أكثر من 200 موقع إلكتروني.

مع تزايد حجم معلمات النماذج الكبيرة، تتباين متطلبات المستخدمين لاستخدام الذكاء الاصطناعي تدريجيًا: فمن جهة، يحتاجون إلى نماذج عالية الأداء للتعامل مع المهام المعقدة، ومن جهة أخرى، يتطلعون إلى تجربة محادثة سهلة وعملية في بيئة حاسوبية منخفضة. في المحادثات النصية الطويلة وسيناريوهات المهام اليومية،لا تتطلب النماذج الكبيرة التقليدية دعمًا لقوة حوسبة عالية فحسب، بل إنها أيضًا عرضة لتأخيرات الاستجابة، أو فقدان السياق، أو مشاكل التوليد غير المتماسكة، مما يجعل النماذج خفيفة الوزن التي "قابلة للاستخدام، وسهلة الاستخدام، وتعمل بشكل جيد" نقطة ضعف تحتاج إلى معالجة عاجلة.
وبناءً على ذلك، أطلقت Google نموذجًا خفيف الوزن لضبط التعليمات الدقيقة Gemma-3-270M-IT.يحتوي هذا النظام على 270 مليون معلمة فقط، ولكنه قادر على العمل بسلاسة في بيئة ذاكرة فيديو بسعة 1 جيجابايت لبطاقة واحدة، مما يخفض بشكل كبير عتبة النشر المحلي.يدعم أيضًا نافذة سياق رمزية بحجم 32 ألف رمز، مما يجعله قادرًا على التعامل مع المحادثات النصية الطويلة ومعالجة المستندات. بفضل الضبط الدقيق المتخصص لجلسات الأسئلة والأجوبة اليومية والمهام البسيطة، يحافظ جهاز Gemma-3-270M-IT على خفة وزنه وكفاءته، مع تحقيق التوازن بين عملية التفاعل الحواري.
يُظهر Gemma-3-270M-IT مسارًا آخر للتطوير: بالإضافة إلى اتجاه "الأكبر والأقوى"،من خلال دعم السياق الخفيف والطويل، فإنه يوفر إمكانيات جديدة لنشر الحافة والتطبيقات الشاملة.
أطلق الموقع الرسمي لـ HyperAI Hyperneuron ميزة "vLLM + Open WebUIdeploy gemma-3-270m-it". جربها!
الاستخدام عبر الإنترنت:https://go.hyper.ai/kBjw3
من 25 أغسطس إلى 29 أغسطس، إليك نظرة عامة سريعة على تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 12
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 4
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 6 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في سبتمبر: 5
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات ما بعد التدريب Nemotron-Post-Training-Dataset-v2
مجموعة بيانات ما بعد التدريب Nemotron-Post-Training-Dataset-v2 هي امتداد لمجموعة بيانات ما بعد التدريب الحالية من NVIDIA. تُوسّع هذه المجموعة بيانات SFT وRL لتشمل خمس لغات مستهدفة (الإسبانية، الفرنسية، الألمانية، الإيطالية، واليابانية)، وتغطي مجالات مثل الرياضيات، والبرمجة، والعلوم والتكنولوجيا والهندسة والرياضيات (STEM)، والمحادثة.
الاستخدام المباشر: https://go.hyper.ai/lSIjR
2. مجموعة بيانات ما قبل التدريب Nemotron-CC-v2
يضيف Nemotron-CC-v2 ثماني لقطات من Common Crawl من عامي 2024 و2025 إلى مجموعة صفحات الويب الأصلية باللغة الإنجليزية، ويُجري إزالةً شاملةً للتكرار وتصفيةً باللغة الإنجليزية. كما يستخدم Qwen3-30B-A3B لتجميع محتوى صفحات الويب وإعادة صياغته، مُضافًا إليه أسئلة وأجوبة متنوعة، ومُترجمًا إلى 15 لغةً أخرى لتعزيز التفكير المنطقي متعدد اللغات والتدريب المسبق على المعرفة العامة.
الاستخدام المباشر: https://go.hyper.ai/xRtbR
3.مجموعة بيانات أخذ العينات من مجموعة بيانات التدريب المسبق لـ Nemotron
تحتوي مجموعة بيانات Nemotron-Pretraining-Dataset-sample على 10 مجموعات فرعية تمثيلية مختارة من مكونات مختلفة من مجموعة SFT الكاملة ومجموعة التدريب المسبق، والتي تغطي بيانات الإجابة على الأسئلة عالية الجودة، والمستخلصات التي تركز على الرياضيات، وبيانات التعريف، وبيانات التعليمات على غرار SFT، وهي مناسبة للمراجعة والتجارب السريعة.
الاستخدام المباشر: https://go.hyper.ai/xzwY5
4. مجموعة بيانات كود Nemotron-Pretraining-Code-v1
Nemotron-Pretraining-Code-v1 هي مجموعة بيانات برمجية واسعة النطاق ومنسقة، مبنية على GitHub. خضعت هذه المجموعة من البيانات للتصفية من خلال إزالة التكرارات متعددة المراحل، وتطبيق التراخيص، وفحوصات الجودة الاستدلالية، وتحتوي على أزواج أسئلة وأجوبة برمجية مُولّدة من قِبل LLM بـ 11 لغة برمجة.
الاستخدام المباشر: https://go.hyper.ai/DRWAw
5. مجموعة بيانات الضبط الدقيق المُشرف عليها Nemotron-Pretraining-SFT-v1
صُمم برنامج Nemotron-Pretraining-SFT-v1 خصيصًا لمجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM)، والمجالات الأكاديمية، والتفكير المنطقي، والمجالات متعددة اللغات. يُولّد البرنامج من مواد رياضية وعلمية عالية الجودة، ويجمع بين نصوص أكاديمية للدراسات العليا وبيانات SFT مُدرّبة مسبقًا لبناء أسئلة تحليلية معقدة (مع إجابات/أفكار كاملة)، تغطي مجموعة متنوعة من المهام، بما في ذلك الرياضيات، والبرمجة، والمعرفة العامة، والتفكير المنطقي.
الاستخدام المباشر: https://go.hyper.ai/g568w
6. مجموعة بيانات التدريب المسبق للرياضيات Nemotron-CC-Math
Nemotron-CC-Math هي مجموعة بيانات عالية الجودة وواسعة النطاق مُدرَّبة مسبقًا، تُركِّز على الرياضيات. تحتوي هذه المجموعة على 133 مليار رمز، وتحافظ على بنية المعادلات والرموز، مع توحيد المحتوى الرياضي في صيغة LaTeX قابلة للتعديل. وهي أول مجموعة بيانات تُغطِّي بدقة مجموعة واسعة من الصيغ الرياضية (بما في ذلك الصيغ طويلة الذيل) على نطاق الويب.
الاستخدام المباشر: https://go.hyper.ai/aEGc4
7. مجموعة بيانات توليد الصور الاصطناعية Echo-4o-Image
تحتوي مجموعة بيانات صور Echo-4o، المُولَّدة بواسطة GPT-4o، على ما يقارب 179,000 مثال موزعة على ثلاثة أنواع مختلفة من المهام: تنفيذ تعليمات معقدة (حوالي 68,000 مثال)؛ وتوليد صور خيالية فائقة الواقعية (حوالي 38,000 مثال)؛ وتوليد صور متعددة المراجع (حوالي 73,000 مثال). يتكون كل مثال من شبكة صور 2×2 بدقة 1024×1024، تحتوي على معلومات مُنظَّمة حول مسار الصورة، والخصائص (السمات/الموضوعات)، والمُوجَّه المُولَّد.
الاستخدام المباشر: https://go.hyper.ai/uLJEh

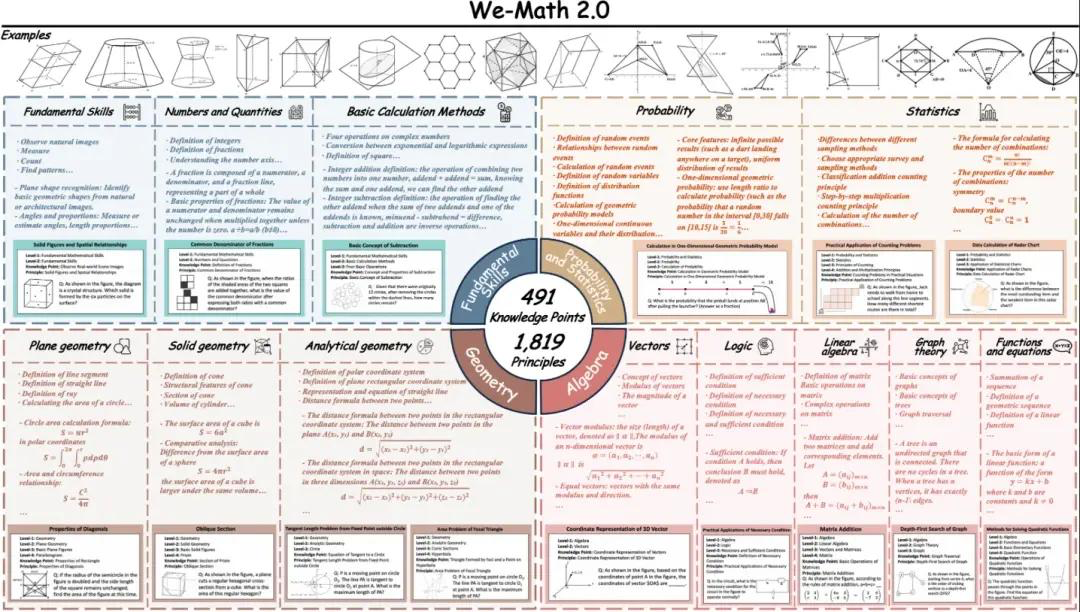
8. مجموعة بيانات معيارية للمنطق الرياضي البصري We-Math2.0
يُرسي معيار We-Math2.0 مساحةً موحدةً للتصنيف حول 1819 مبدأً مُعرّفًا بدقة. كل مسألة مُصنّفةٌ بشكلٍ واضحٍ بالمبدأ، ومُختارةٌ بعناية، مما يُحقق تغطيةً واسعةً ومتوازنةً بشكلٍ عام، ويُحسّن بشكلٍ خاصّ المجالات الفرعية وأنواع المسائل الرياضية التي لم تكن مُمثلةً بشكلٍ كافٍ سابقًا. تستخدم مجموعة البيانات تصميمًا ثنائي التوسع: أشكالٌ متعددة لكل مسألة، وأسئلةٌ متعددة لكل شكل.
الاستخدام المباشر: https://go.hyper.ai/VlqK1
9. مجموعة بيانات مهام تشغيل سطح المكتب AgentNet
AgentNet هي أول مجموعة بيانات واسعة النطاق لمسار استخدام وكلاء أجهزة الكمبيوتر المكتبية، مصممة لدعم وتقييم وكلاء معالجة واجهة المستخدم الرسومية (GUI) ونماذج الرؤية واللغة والفعل متعددة المنصات. تحتوي مجموعة البيانات على 22.6 ألف مسار استخدام حاسوبي مُعلّق يدويًا عبر أنظمة Windows وmacOS وUbuntu، بالإضافة إلى أكثر من 200 تطبيق وموقع ويب. تنقسم السيناريوهات إلى أربع فئات: المكتب، والمهنية، والحياة اليومية، واستخدام النظام.
الاستخدام المباشر: https://go.hyper.ai/3DGDs
10. مجموعة بيانات معيارية لجمع المعلومات من WideSearch
WideSearch هي أول مجموعة بيانات مرجعية مصممة خصيصًا لجمع معلومات واسعة النطاق. تتكون هذه المجموعة من 200 سؤال عالي الجودة (100 باللغة الإنجليزية و100 باللغة الصينية) مختارة بعناية ومُنقّاة يدويًا من استعلامات المستخدمين الفعلية. تأتي هذه الأسئلة من أكثر من 15 مجالًا مختلفًا.
الاستخدام المباشر: https://go.hyper.ai/36kKj
11. مجموعة بيانات توليد الكود متعدد الوسائط MCD
يحتوي MCD على ما يقارب 598,000 مثال/زوج عالي الجودة، مُرتبة بصيغة تتبع الأوامر. يغطي مجموعة متنوعة من وسائط الإدخال (نصوص، صور، أكواد) ووسائط الإخراج (أكواد، إجابات، شروحات)، مما يجعله مناسبًا لمهام فهم وتوليد أكواد متعددة الوسائط. تتضمن البيانات: أكواد HTML مُحسّنة، ومخططات بيانية، وأسئلة وأجوبة، وخوارزميات.
الاستخدام المباشر: https://go.hyper.ai/yMPeD
12. مجموعة بيانات ما بعد التدريب Llama-Nemotron مجموعة بيانات ما بعد التدريب
مجموعة بيانات ما بعد التدريب Llama-Nemotron هي مجموعة بيانات واسعة النطاق لما بعد التدريب، مصممة لتحسين قدرات الرياضيات والبرمجة والاستدلال العام واتباع التعليمات لعائلة نماذج Llama-Nemotron خلال مراحل ما بعد التدريب (مثل SFT وRL). تجمع هذه المجموعة البيانات من مرحلتي الضبط الدقيق المُشرف والتعلم التعزيزي.
الاستخدام المباشر: https://go.hyper.ai/Vk0Pk
دروس تعليمية عامة مختارة
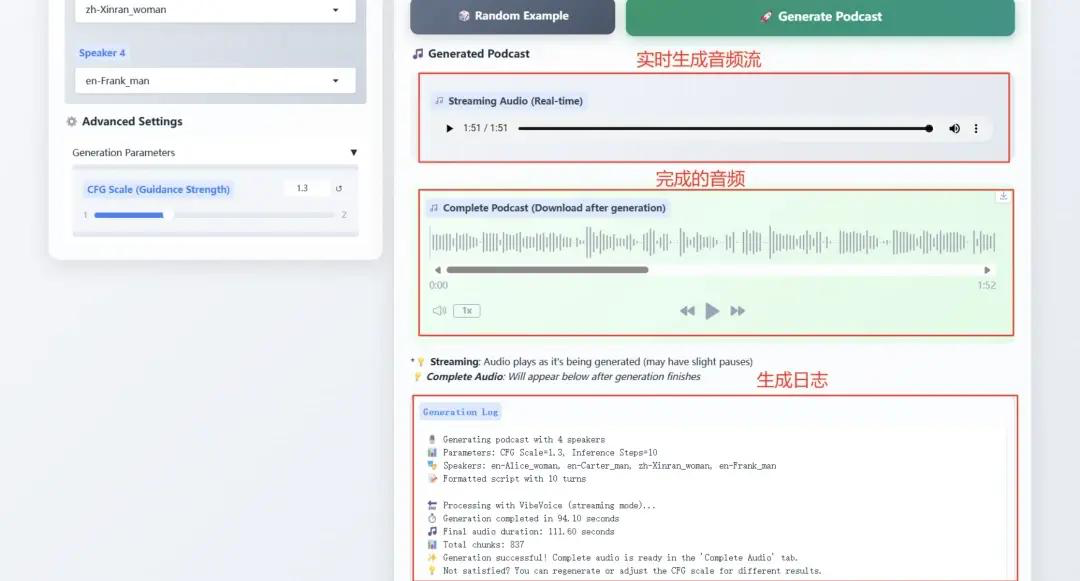
1. Microsoft VibeVoice-1.5B يعيد تعريف تقنية TTSالحدود
VibeVoice-1.5B هو نموذج جديد لتحويل النص إلى كلام (TTS)، يُنتج صوتًا حواريًا مُعبّرًا وطويلًا ومتعدد المتحدثين، مثل البودكاست. يُعالج VibeVoice بكفاءة تسلسلات صوتية طويلة مع الحفاظ على دقة عالية، ويدعم توليف ما يصل إلى 90 دقيقة من الكلام مع ما يصل إلى أربعة متحدثين مختلفين.
التشغيل عبر الإنترنت:https://go.hyper.ai/Ofjb1
2. vLLM + Open WebUI نشر NVIDIA-Nemotron-Nano-9B-v2
يجمع NVIDIA-Nemotron-Nano-9B-v2 بشكل مبتكر بين كفاءة معالجة التسلسلات الطويلة في Mamba وقدرات النمذجة الدلالية القوية في Transformer، محققًا دعمًا لسياقات فائقة الطول يصل إلى 128 ألفًا باستخدام 9 مليارات (9 مليار) معلمة فقط. تُضاهي كفاءة الاستدلال وأداء المهام على أجهزة الحوسبة الطرفية (مثل وحدات معالجة الرسومات من فئة RTX 4090) النماذج المتطورة بنفس مقياس المعلمات.
تشغيل عبر الإنترنت: https://go.hyper.ai/cVzPp
3. vLLM + Open WebUI نشر Gemma-3-270m-it
صُمم gemma-3-270m-it باستخدام 270 مليون معلمة، مع التركيز على التفاعل الحواري الفعال والنشر البسيط. يتطلب هذا النموذج الخفيف والفعال ذاكرة رسومات بسعة 1 جيجابايت أو أكثر على بطاقة رسومات واحدة، مما يجعله مناسبًا لأجهزة الحافة وفي ظروف الاستخدام منخفضة الموارد. يدعم النموذج المحادثات متعددة الأدوار، وهو مُصمم خصيصًا للأسئلة والأجوبة اليومية وتعليمات المهام البسيطة. يركز النموذج على توليد النصوص وفهمها، ويدعم نافذة سياقية تتسع لـ 32 ألف رمز، مما يُمكّنه من التعامل مع المحادثات النصية الطويلة.
تشغيل عبر الإنترنت: https://go.hyper.ai/kBjw3

4. vLLM+Open WebUI Deployment Seed-OSS-36B-Instruct
استخدم Seed-OSS-36B-Instruct 12 تريليون (12 تيرابايت) من الرموز للتدريب، وحقق أداءً متميزًا في العديد من معايير البرمجيات مفتوحة المصدر السائدة. ومن أبرز ميزاته قدرته الأصلية على التعامل مع السياقات الطويلة، حيث يبلغ طول السياق الأقصى 512 ألف رمز، مما يُمكّنه من التعامل مع مستندات وسلاسل استدلال طويلة للغاية دون التضحية بالأداء. هذا الطول ضعف طول أحدث عائلة نماذج GPT-5 من OpenAI، ويعادل حوالي 1600 صفحة نصية.
تشغيل عبر الإنترنت: https://go.hyper.ai/aKw9w

💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

توصيات الورقة البحثية لهذا الأسبوع
1. ما وراء Pass@1: اللعب الذاتي مع تركيب المشكلة المتغيرة يدعم RLVR
تقترح هذه الورقة استراتيجيةً لتوليف مسائل التباين ذاتية اللعب لتحسين تعلم تعزيز المكافأة القابل للتحقق منه في نماذج اللغات الكبيرة. في حين أن RLVR التقليدي يُحسّن Pass@1، إلا أنه يُقلل من تنوع الأجيال بسبب انهيار الإنتروبيا، مما يُحد من أداء Pass@k. تُخفف SvS من انهيار الإنتروبيا وتُحافظ على تنوع التدريب من خلال توليف مسائل تباينية مُكافئة بناءً على حلول صحيحة.
رابط الورقة: https://go.hyper.ai/IU71P
2. تذكار: ضبط دقيق لوكلاء ماجستير القانون دون ضبط دقيق لطلاب ماجستير القانون
تقترح هذه الورقة نموذجًا تعليميًا جديدًا لوكلاء نموذج اللغة الكبيرة التكيفي، يُغني عن ضبط لغة البرمجة الأساسية بدقة. غالبًا ما تعاني الأساليب الحالية من قيدين: إما أنها صارمة للغاية أو مكلفة حسابيًا. يحقق فريق البحث تكيفًا مستمرًا منخفض التكلفة من خلال التعلم التعزيزي عبر الإنترنت القائم على الذاكرة. يُصوغ الفريق هذه العملية رسميًا كعملية قرار ماركوف مُحسّنة بالذاكرة (M-MDP)، ويُقدم استراتيجية اختيار حالة عصبية لتوجيه قرارات العمل.
رابط الورقة: https://go.hyper.ai/sl9Yj
3. TreePO: سد الفجوة بين تحسين السياسات وفعاليتها وكفاءة الاستدلال باستخدام النمذجة القائمة على الشجرة الاستدلالية
تقترح هذه الورقة البحثية خوارزمية طرح ذاتية التوجيه تُعامل توليد التسلسل كعملية بحث شبيهة بالشجرة. تتكون خوارزمية TreePO من استراتيجية ديناميكية لأخذ العينات الشجرية وفك تشفير مقطع ثابت الطول، مستغلةً عدم اليقين المحلي لتوليد فروع إضافية. من خلال تخفيف العبء الحسابي على البادئات الشائعة وتقليص المسارات منخفضة القيمة مبكرًا، تُقلل TreePO بشكل فعال العبء الحسابي لكل تحديث مع الحفاظ على تنوع الاستكشاف أو تحسينه.
رابط الورقة: https://go.hyper.ai/J8tKk
4. تقرير فني عن VibeVoice
تقترح هذه الورقة نموذجًا جديدًا لتوليف الكلام، VibeVoice، يُولّد كلامًا طويلًا متعدد المتحدثين استنادًا إلى انتشار الرمز التالي. يُحسّن مُرمّز الكلام المستمر هذا من معدل الضغط بمقدار 80 ضعفًا مقارنةً بـ Encodec، مما يُحسّن بشكل كبير كفاءة معالجة التسلسلات الطويلة مع الحفاظ على جودة الصوت. يدعم النموذج توليف ما يصل إلى 90 دقيقة من الكلام المُحادثي لما يصل إلى أربعة متحدثين ضمن سياق 64 كيلوبت في الثانية، مُعيدًا بذلك خلق جو التواصل بشكل أصيل، ومتجاوزًا بذلك النماذج مفتوحة المصدر والتجارية الحالية.
رابط الورقة: https://go.hyper.ai/pokVi
5. CMPhysBench: معيار لتقييم نماذج اللغة الكبيرة في فيزياء المادة المكثفة
تقدم هذه الورقة البحثية CMPhysBench، وهو معيار مبتكر لتقييم قدرات نماذج اللغات الكبيرة في فيزياء المادة المكثفة. يتألف CMPhysBench من أكثر من 520 مسألة دراسية مُختارة بعناية لطلاب الدراسات العليا، تغطي مجالات فرعية نموذجية وأطرًا نظرية أساسية لفيزياء المادة المكثفة، مثل المغناطيسية، والموصلية الفائقة، والأنظمة المترابطة بقوة.
رابط الورقة: https://go.hyper.ai/uo8de
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
في الدورة الثالثة من "مدرسة الذكاء الاصطناعي للهندسة الحيوية الصيفية" التي استضافتها جامعة شنغهاي جياو تونغ، شارك لي مينغ تشين، وهو زميل ما بعد الدكتوراه في مجموعة هونغ ليانغ البحثية في معهد العلوم الطبيعية بجامعة شنغهاي جياو تونغ، أحدث التقدم البحثي والاختراقات التكنولوجية في النموذج الأساسي للبروتينات والجينومات مع الجميع تحت عنوان "النموذج الأساسي للبروتين والجينوم".
شاهد التقرير الكامل: https://go.hyper.ai/Ynjdj
بدمج أدوات المعلوماتية الكيميائية مع قاعدة بيانات الذوبان العضوي الجديدة BigSolDB، حسّن فريق البحث في معهد ماساتشوستس للتكنولوجيا (MIT) بنيتي نموذجي FASTPROP وCHEMPROP، مما مكّن النموذج من إدخال جزيئات المذاب والمذيب في آنٍ واحد، بالإضافة إلى معلمات درجة الحرارة، لتدريب الانحدار المباشر على logS. في سيناريو استقراء دقيق للمذاب، حقق النموذج المُحسّن انخفاضًا في RMSE بمقدار 2-3 مرات وزيادة في سرعة الاستدلال بمقدار 50 مرة مقارنةً بالنموذج المتطور الذي طوره فيرمير وآخرون.
شاهد التقرير الكامل: https://go.hyper.ai/cj9RX
أعلنت شركة NVIDIA عن الإطلاق الرسمي لمجموعة تطوير Jetson AGX Thor، بسعر يبدأ من 3,499 دولارًا أمريكيًا. وحدة Thor T5000 الإنتاجية متاحة الآن لعملاء المؤسسات. تهدف Jetson AGX Thor، التي تُعرف بـ"عقل الروبوت"، إلى تمكين ملايين الروبوتات في قطاعات مثل التصنيع والخدمات اللوجستية والنقل والرعاية الصحية والزراعة وتجارة التجزئة.
شاهد التقرير الكامل: https://go.hyper.ai/1XLXn
اقترح فريق بحثي من قسم الهندسة الكيميائية والكيمياء التطبيقية بجامعة تورنتو في كندا أسلوبًا متعدد الوسائط للتعلم الآلي، يستخدم المعلومات المتاحة بعد تصنيع الأطر العضوية المعدنية: PXRD والمواد الكيميائية المستخدمة في التصنيع، لتحديد الأطر العضوية المعدنية ذات الإمكانات في مجالات مختلفة عن التطبيقات المُبلغ عنها سابقًا. يُسرّع هذا البحث من الربط بين تصنيع الأطر العضوية المعدنية وسيناريوهات التطبيق.
شاهد التقرير الكامل: https://go.hyper.ai/cqX1t
في مؤتمر 2025CCF الوطني الأكاديمي للحوسبة عالية الأداء، قام الباحث Zhang Zhengde، رئيس AI4S في مركز الحوسبة التابع لمعهد فيزياء الطاقة العالية، بشرح خطة البناء الفعالة وعالية الجودة للبيانات الجاهزة للذكاء الاصطناعي، بناءً على الحالة الحالية للبيانات العلمية من المرافق واسعة النطاق، بالإضافة إلى تطبيق الوكلاء الأذكياء وأطر الوكلاء المتعددين في شرح البيانات وتوفيرها.
شاهد التقرير الكامل: https://go.hyper.ai/u7F9L
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:https://go.hyper.ai/wiki
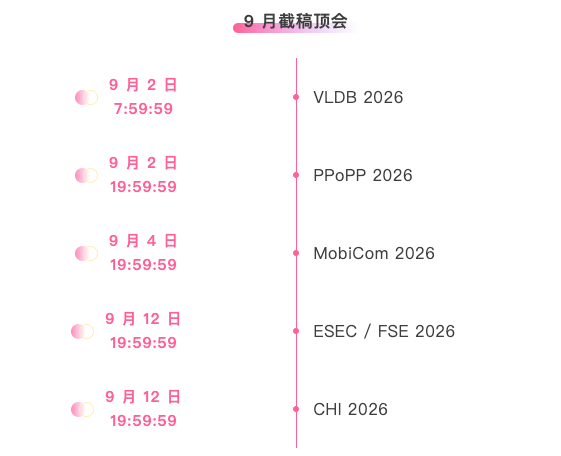
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








