Command Palette
Search for a command to run...
لتحسين توفر البيانات العلمية، اقترح فريق Zhang Zhengde في الأكاديمية الصينية للعلوم حلاً لمعالجة البيانات وتوفيرها جاهزًا للذكاء الاصطناعي يعتمد على وكلاء أذكياء.

في أبحاث فيزياء الطاقة العالية اليوم، تُنتج المرافق العلمية المتطورة وواسعة النطاق كميات هائلة من البيانات باستمرار. ونظرًا لأن هذا التدفق الهائل من البيانات يتجاوز بكثير حدود معالجة الطرق التحليلية التقليدية، فإن تقنيات الذكاء الاصطناعي، وخاصةً التعلم الآلي والشبكات العصبية العميقة، تُصبح بسرعة أدوات أساسية في جميع مسارات أبحاث فيزياء الطاقة العالية. لا تقتصر خوارزميات الذكاء الاصطناعي على معالجة كميات هائلة من البيانات الخام بكفاءة، وكشف الأنماط والارتباطات الضمنية وغير الخطية والمعقدة فيها فحسب، بل تُظهر أيضًا مزايا تطبيقية في تحسين تشغيل المُسرِّعات، ومحاكاة أداء الكواشف، وتصميم أنظمة التشغيل التجريبية، واستكشاف النماذج النظرية. وقد أصبح الابتكار المستمر والتكامل العميق لأساليب الذكاء الاصطناعي قوة دافعة محتملة للتطوير المستقبلي لفيزياء الطاقة العالية.
في مؤتمر CCF الوطني الأكاديمي للحوسبة عالية الأداء لعام 2025، تحدث تشانغ تشنغده، الباحث ورئيس AI4S في مركز الحوسبة التابع لمعهد فيزياء الطاقة العالية، في منتدى "تكنولوجيا البيانات العلمية الجاهزة للذكاء الاصطناعي" حول موضوع "التقدم وممارسات معالجة البيانات للوكلاء الأذكياء بناءً على النماذج الكبيرة".انطلاقًا من الوضع الحالي للبيانات العلمية من المرافق واسعة النطاق، يشرح هذا البحث بشكل منهجي خطة البناء الفعالة وعالية الجودة الجاهزة للذكاء الاصطناعي للبيانات، بالإضافة إلى تطبيق الوكلاء الأذكياء وأطر الوكلاء المتعددين في شرح البيانات وتوفيرها.

قامت شركة HyperAI بتلخيص خطاب البروفيسور تشانغ تشنغده دون المساس بالهدف الأصلي. فيما يلي نص الخطاب.
حالة البيانات الجاهزة للذكاء الاصطناعي والبيانات العلمية
في سياق خوارزميات AI4S مفتوحة المصدر، أصبحت البيانات هي القضية الأساسية الأكثر أهمية. يتطلب الذكاء الاصطناعي من أجل الاستدامة (AI4S) أن تكون للبيانات معايير موحدة لتحليلها بكفاءة. مع أن البيانات من المنشآت العلمية الكبيرة عادةً ما تكون بتنسيق وبنية تخزين موحدة، إلا أن معظم البيانات العلمية في الواقع ليست جاهزة للذكاء الاصطناعي.
إن الكم الهائل من البيانات المُولَّدة في فيزياء الطاقة العالية لا يُلقي بظلاله على تقنيات جمع البيانات ومعالجتها ودمجها فحسب، بل يُوفر أيضًا موردًا حيويًا لتطوير أساليب الذكاء الاصطناعي. وتشمل أنواع البيانات المذكورة في تقرير اليوم ليس فقط البيانات التجريبية، بل أيضًا بيانات المحاكاة، وبيانات تشغيل الأجهزة، وبيانات المجموعة.
التعريف العام لمجموعة البيانات الجاهزة للذكاء الاصطناعي هي مجموعة من البيانات التي يمكن استخدامها بكفاءة وأمان وقابلية للتكرار للتدريب وتقييم ونشر التعلم الآلي والذكاء الاصطناعي.تتمتع البيانات عالية الجودة الجاهزة للذكاء الاصطناعي بعشر خصائص:
* التكيف مع المهمة.أهمية قوية لسيناريو الهدف والمهمة، مع تغطية شاملة وتمثيلية؛
* جودة عالية وثبات.دقيقة، كاملة، متسقة، خالية من التكرار، وخالية من الضوضاء؛
* تلبية متطلبات الجسم والعلامة،إنها تحتوي على علامات عالية الجودة، وتسلسلات هرمية، وتعيينات أنطولوجية، كما أنها مزودة بتعليقات توضيحية من خلال عمليات التدقيق؛
* الهندسة متاحة.قابلة للقراءة آليًا، مثل وجود تنسيق قياسي، وتجزئة/تقسيم معقول، وقابلية التدفق، والتوازي؛
* قابلة للتقييم وإعادة الاستخدام.قم بتقسيم بيانات التدريب والاختبار والتحقق بشكل صارم، ويجب أن تحتوي مجموعة المعايير على مؤشرات تقييم واضحة ومعقولة؛
* البيانات الوصفية والإثراء.يغطي طريقة جمع البيانات الوصفية والوقت ونظام الجهاز والسياق والإصدار والمعلومات الأخرى؛
* التحكم في انحراف البيانات.مثل تحيز العينة، وتحيز التسمية، والتحيز التاريخي؛
* متاح.واجهة وصول مستقرة، والتوثيق والأمثلة؛
* معقولة ومتوافقة.الأذونات وحقوق الاستخدام وحماية الخصوصية وأفضل المعلومات الشخصية؛
* آمنة وموثوقة.التشفير (أثناء النقل/في حالة السكون)، الحد الأدنى من الامتيازات، إدارة المفاتيح، وما إلى ذلك.
في البحث العملي، لا تُستخدم البيانات لتدريب النماذج فحسب، بل يجب أن تدعم تقييمها أيضًا. لذلك، تتطلب مجموعات البيانات إنشاء مقاييس تقييم مقابلة، مثل الدقة، والتذكر، ودرجة F1. مع ذلك، ورغم أن هذه المقاييس قابلة للتطبيق عمومًا على بعض المهام (مثل التصنيف)، إلا أنها أقل فعالية في مسائل مثل الانحدار. وهذا يفرض متطلبات أعلى على جودة مجموعات البيانات الجاهزة للذكاء الاصطناعي، ويطرح تحديات.
في الوقت الحالي،بالإضافة إلى احتوائها على بيانات وجودية وشرحية، يجب أن توفر مجموعة البيانات المؤهلة الجاهزة للذكاء الاصطناعي بيانات وصفية، بما في ذلك معلومات مثل وصف مهمة الذكاء الاصطناعي. والأهم من ذلك، يجب أن ترتبط مجموعة البيانات الجاهزة للذكاء الاصطناعي ارتباطًا مباشرًا بمهام ذكاء اصطناعي قيّمة.وباستخدام مصادر الضوء كمثال، ينبغي أن تكون تطبيقات الذكاء الاصطناعي قادرة على دعم المهام العلمية المحددة بشكل فعال مثل التصوير، والطيف، وتشتت الحيود.
سأستخدم بعد ذلك مثالين لتوضيح ماهية مجموعة البيانات الجاهزة للذكاء الاصطناعي. على سبيل المثال، لمجموعة بيانات الذكاء الاصطناعي للتنبؤ باتجاه الألياف النانوية مهمة ذكاء اصطناعي واضحة: التنبؤ المباشر بمعلمات اتجاه الألياف النانوية بناءً على أطياف حيود واسعة الزاوية. يتطلب بناء مثل هذه المجموعة تضافر جهود البيانات المحاكية والتجريبية.
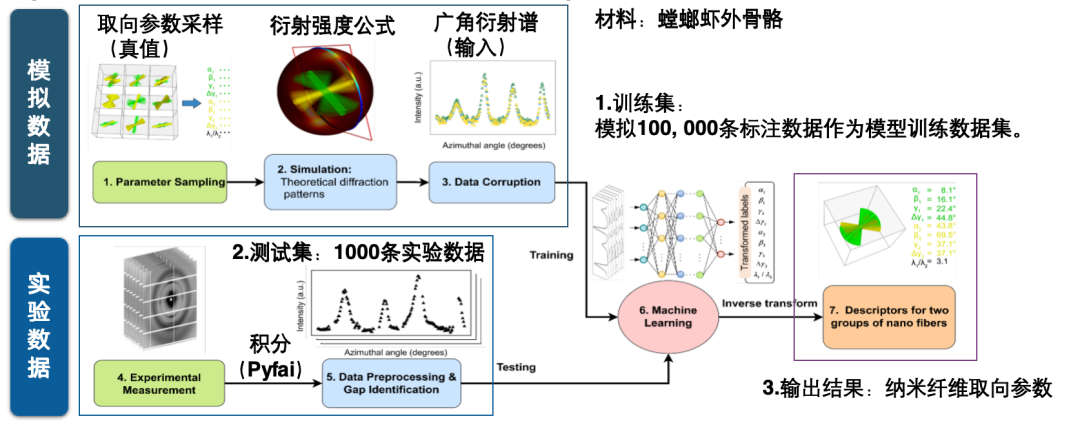
على سبيل المثال، تُمكّن مجموعة بيانات الذكاء الاصطناعي لإعادة بناء الصور المكدسة بسرعة من إكمال مهمة الذكاء الاصطناعي المتمثلة في إدخال نمط حيود، والتنبؤ بطوره وسعته، وحساب الصورة المُعاد بناؤها، مُكملةً بذلك الجهد الحسابي المُكثّف المُستلزم لإعادة بناء الصورة. تتضمن هذه البنية فرعين، أحدهما للتنبؤ بالطور والآخر للسعة. تُشتق القيم الحقيقية باستخدام خوارزمية حسابية علمية تكرارية وعدد كبير من الإسقاطات.
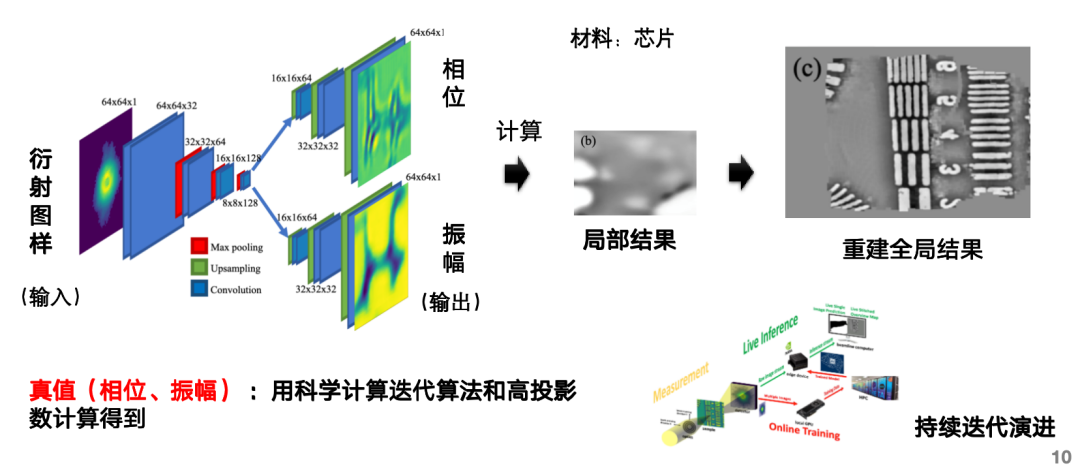
تطبيق تكنولوجيا الوكيل في معالجة البيانات
تعريف الوكيل قريب جدًا من التعريف الأصلي للذكاء الاصطناعي، والذي يشير إلى البرامج أو الأنظمة التي يمكنها اتخاذ القرارات أو تنفيذ الإجراءات نيابة عن المستخدمين بناءً على معرفتهم وبرامجهم وبيئتهم ومعلومات الإدخال.
على الرغم من تشابه الوكلاء الأذكياء مع تقنية الأتمتة، إلا أن الأخيرة تعتمد عادةً على عمليات ثابتة. وعلى عكس الأتمتة التقليدية، تُعد الوكلاء الأذكياء مناسبين بشكل خاص لمعالجة سير العمل التي لا يمكن تغطيتها بفعالية بقواعد حتمية، ويمكنهم التعامل مع مهام يصعب على أساليب الحوسبة التقليدية القائمة على القواعد التعامل معها.لا تناسب الوكلاء الأذكياء جميع السيناريوهات. ففعاليتهم تعتمد بشكل كبير على بيئة المهمة المحددة، وتتطلب مراعاةً كاملةً لتعقيد عملية صنع القرار ومعالجته. لذلك، يتطلب بناء وكلاء أذكياء إعادة النظر في كيفية تعامل النظام مع عمليات صنع القرار المعقدة.
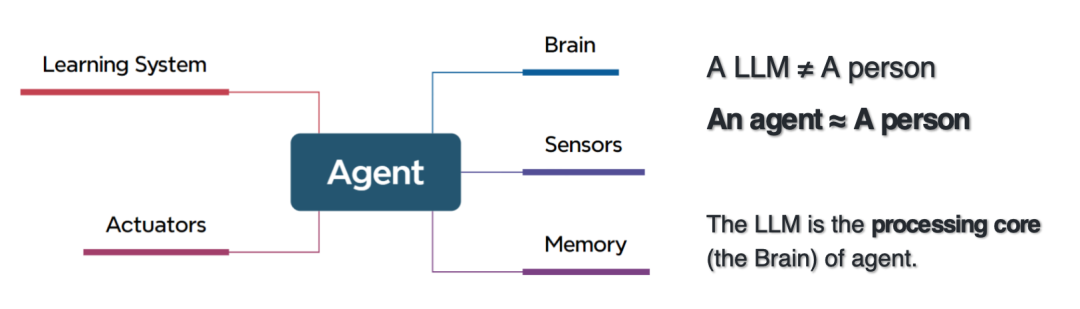
إن دماغ العميل الذكي عبارة عن نموذج كبير، وبالتالي فإن العلاقة بين العميل الذكي والنموذج الكبير هي في الواقع علاقة تضمين.الفرق بين الوكيل الذكي والنموذج الكبير هو أنه يتضمن طبقة الإدراك، وطبقة التنفيذ، وطبقة الذاكرة، ومركز المعالجة.القدرة على تعلم خبرة المجال وأدوات التحليل العلمي وإدراك البيانات والبيانات الوصفية وكتابة التعليمات البرمجية وتنفيذ البرامج وتخطيط المهام وتخصيص الأدوار والتعاون وما إلى ذلك.
في الوقت نفسه، تختلف سيناريوهات تطبيق أنظمة العامل الواحد عن الأنظمة متعددة العوامل. عادةً، يُجهّز نظام العامل الواحد بأداة واحدة. مع زيادة عدد الأدوات التي يحملها، تقل دقة اختيار الأداة. في هذه الحالة، يمكن استخدام أنظمة متعددة العوامل لتجنب أي لبس.
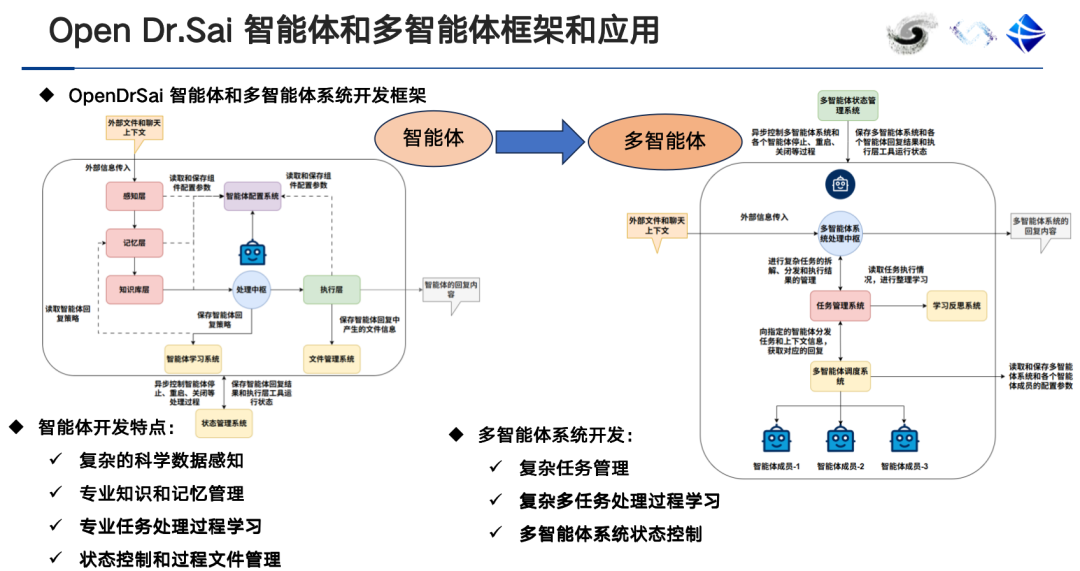
تتميز عملية وسم البيانات المدعومة بالذكاء الاصطناعي، والمعتمدة على أدوات الوسم، بدقة عالية، لكنها تتطلب مشاركة يدوية مكثفة. وتتميز هذه العملية، المعتمدة على عوامل ذكية، بأتمتة عالية وفعالية عالية، ويمكنها توفير فهم معلومات البيانات والمساعدة في فهمها. وهي مناسبة للبحوث متعددة التخصصات، إلا أن دقتها الأولية قد تكون منخفضة نسبيًا، وتحتاج دقة الوسم إلى تحسين مستمر من خلال آليات التعلم المستمر والتغذية الراجعة.في الوقت الحاضر، انتقلت العديد من أدوات التوضيح التي تعتمد على التوضيح تدريجيًا إلى نموذج "مجهز بوحدة وكيل ذكية + تفاعل بين الإنسان والحاسوب + مساعدة ذكية + نظام مراجعة + قاعدة بيانات".
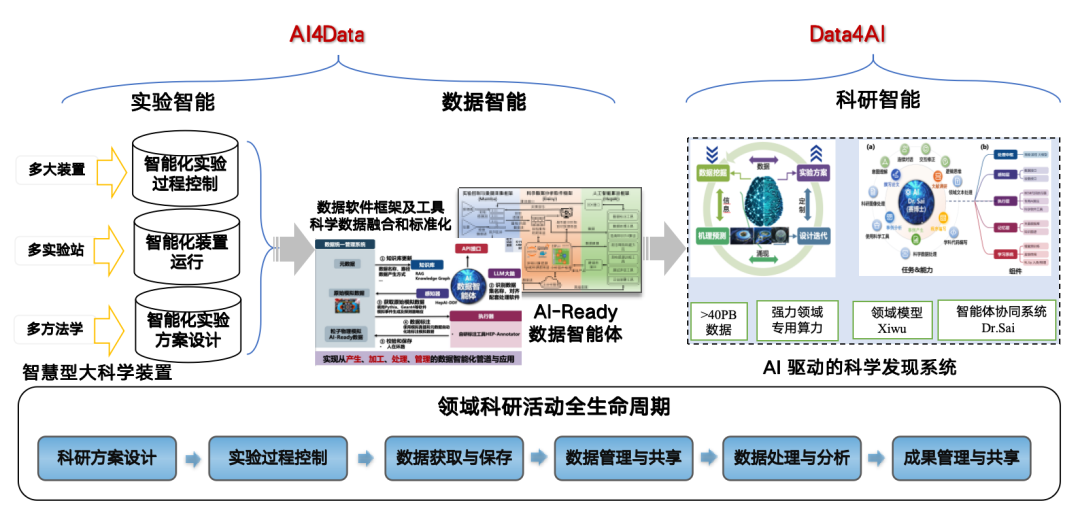
وكيل البيانات المطبق على مشاهد مصدر الضوء
يُستخدم وكيل بيانات فريقنا بشكل أساسي في سيناريوهات مصادر الضوء (HEPS)/مصادر النيوترون (CSNS)، حيث يدعم معالجة البيانات وتزويدها. المصدر الرئيسي للوكيل هو نظام إدارة بيانات Domas، والذي يتصل بدوره بنظام جمع البيانات الخاص بجهاز البيانات الضخمة، والذي يتصل بدوره بالكاشف نفسه.
لمزيد من المعلومات حول وكلاء البيانات:
https://github.com/hepaihub/drsai
رابط منصة HepAI:
يتم تقسيم سير عمل الوكيل إلى 5 خطوات:
* الاتصال بـ Domas للحصول على معلومات البيانات بما في ذلك البيانات التجريبية والبيانات الوصفية؛
* تحديث قاعدة المعرفة بناءً على البيانات المكتسبة؛
* يقوم العميل أيضًا بإدراك البيانات استنادًا إلى مهام محددة ويكمل تفاعل البيانات عن طريق تحويل تنسيقات البيانات وتنفيذ الأوامر؛
* استخدام مجموعة متنوعة من أدوات الحوسبة العلمية لمعالجة البيانات؛
* إدخال البيانات إلى المنفذ لتوجيه تنفيذ المهمة، وإدخال نتائج الإخراج مرة أخرى إلى Domas.
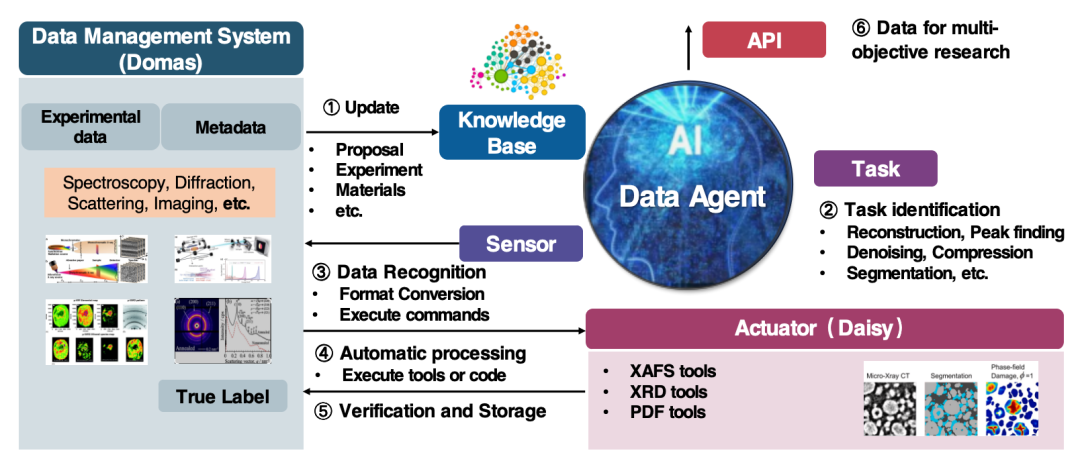
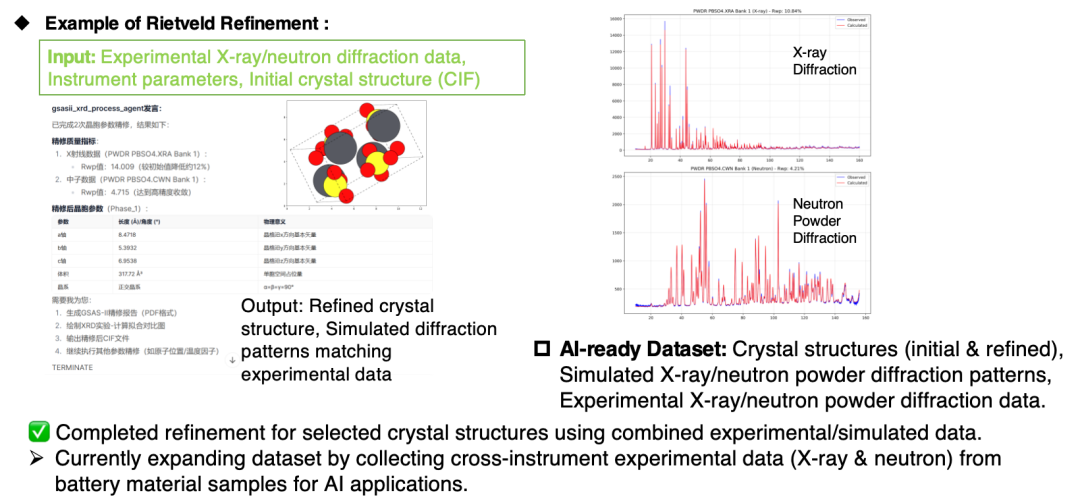
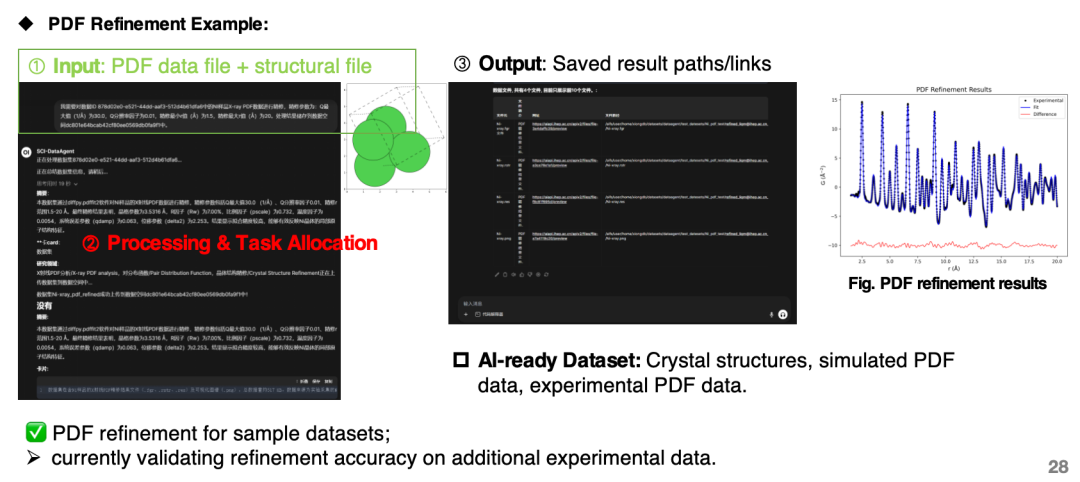
حاليًا، يمكن استخدام الوكيل لإنشاء مجموعات بيانات الذكاء الاصطناعي لتجارب ومحاكاة حيود الأشعة السينية عبر الأجهزة وحيود مسحوق النيوترون، وإنشاء مجموعات بيانات اندماج محاكاة تجريبية لوظائف توزيع الزوج (ملفات PDF).
نظام اكتشاف علمي مدفوع بالذكاء الاصطناعي
يعود سبب استخدامنا لتقنية الوكلاء الأذكياء في معالجة البيانات إلى أن الذكاء الاصطناعي من أجل الخدمات (AI4S) أصبح تدريجيًا اتجاهًا تطويريًا. يُسهم الذكاء الاصطناعي في البحث والاكتشاف في مجال فيزياء الطاقة العالية، إلا أنه يتطلب بيانات عالية.ولذلك، اعتمدنا استراتيجية "AI4Data" إلى "Data4AI"، باستخدام الذكاء الاصطناعي لتحويل البيانات الخام إلى نموذج جاهز للذكاء الاصطناعي لتعزيز نتائج البحث والتطوير وبناء نظام اكتشاف علمي مدفوع بالذكاء الاصطناعي.
نبذة عن الباحث تشانغ تشنغده وفريقه
الدكتور تشانغ تشنغده باحث شاب متميز في معهد فيزياء الطاقة العالية التابع للأكاديمية الصينية للعلوم. تخرج من معهد شنغهاي للفيزياء التطبيقية التابع للأكاديمية الصينية للعلوم، وحصل على درجة الدكتوراه في فيزياء الجسيمات والفيزياء النووية. تتركز أبحاثه الرئيسية حول خوارزميات الذكاء الاصطناعي، والنماذج الكبيرة، والعوامل الذكية للاكتشاف العلمي، بما في ذلك خوارزميات التعلم العميق، والنماذج الكبيرة للبيانات العلمية، ومنصات الذكاء الاصطناعي، وأنظمة البرمجيات. يهدف بشكل رئيسي إلى تعزيز تطبيق الذكاء الاصطناعي في فيزياء الجسيمات، والفيزياء الفلكية للجسيمات، وإشعاع السنكروترون، وعلم النيوترونات، والمسرعات.

حاليًا، نشر الباحث تشانغ تشنغده ستة مشاريع نموذجية مفتوحة المصدر على منصة GitHub، وطوّر شبكات عصبية مثل CDNet وFINet وMWNet، وطوّر نموذج لغة Xiwu عالي الطاقة ووكيل البحث العلمي "Science Doctor"، وخطط وبنى منصة الذكاء الاصطناعي HepAI لفيزياء الطاقة العالية[4]. وفي الوقت نفسه، أشرف على عدد من مشاريع البحث العلمي المهمة، منها "مشروع من الصفر إلى واحد - بحث في الاكتشاف العلمي لفيزياء الطاقة العالية المستند إلى نموذج كبير للذكاء الاصطناعي" و"بحث وإثبات تقنية البيانات الضخمة لفيزياء الطاقة العالية القائمة على الذكاء الاصطناعي".
مراجع:
[3] مجموعة hepai. (nd). Open drsai [برنامج حاسوبي]. GitHub. https://github.com/hepaihub/drsai
[4] مجموعة hepai. (nd). منصة hepAI. https://ai.ihep.ac.cn
احصل على أوراق بحثية عالية الجودة ومقالات تفسيرية متعمقة في مجال AI4S من عام 2023 إلى عام 2024 بنقرة واحدة⬇️









