Command Palette
Search for a command to run...
يقترح معهد ماساتشوستس للتكنولوجيا (MIT) استخدام AutoSciDACT، وهي أداة اكتشاف علمية آلية شديدة الحساسية للبيانات الشاذة في علم الفلك والفيزياء والطب الحيوي.

على مر التاريخ، غالبًا ما كانت الاكتشافات العلمية مرتبطة بالصدفة. على سبيل المثال، اكتُشف البنسلين صدفةً في طبق بتري متعفن، ونشأ إشعاع الخلفية الكونية الميكروي من "ضوضاء غير طبيعية" التقطها هوائي. أصبحت هذه الملاحظات غير المقصودة في نهاية المطاف قوى دافعة رئيسية لتقدم الحضارة الإنسانية. اليوم، في بيئة بحثية "كثيفة البيانات"، تحتوي كميات هائلة من البيانات متعددة التخصصات على ملاحظات أكثر غرابة وغموضًا، مما يضاعف نظريًا فرص الاكتشافات العلمية العرضية. ومع ذلك، ومن المفارقات، أن التقاط "اكتشافات جديدة" بدقة من كميات هائلة ومعقدة من بيانات البحث أصعب بكثير من البحث عن إبرة في كومة قش.
تعتمد أساليب الاكتشاف العلمي التقليدية بشكل كبير على حدس العلماء وخبرتهم، وتتطلب عملية معقدة من الملاحظة والبحث والفرضيات والتجريب والتحقق لتحديد القيمة العلمية الحقيقية لأي "اكتشاف جديد". ومع ذلك، مع النمو الهائل وتزايد تعقيد البيانات العلمية، أصبح تحديد "الاكتشافات الجديدة" من خلال الملاحظة الدقيقة فقط أمرًا شبه مستحيل. في حين أن أساليب البحث العلمي الآلية القائمة على الذكاء الاصطناعي ونماذج اللغة الكبيرة قد أظهرت مؤخرًا نتائج واعدة،ومع ذلك، بسبب عدم وجود إطار عمل متكامل قادر على اختبار الفرضيات والتحقق منها بشكل صارم وآلي،وحتى مع هذه الأساليب، فإنه لا يزال من المحتم أن "الإرادة راغبة ولكن القدرة غير كافية".
ولمعالجة تحديات الاكتشاف العلمي، اقترح فريق من معهد ماساتشوستس للتكنولوجيا، وجامعة ويسكونسن ماديسون، ومعهد الذكاء الاصطناعي والتفاعلات الأساسية التابع للمؤسسة الوطنية للعلوم (IAIFI)، طريقة تسمى AutoSciDACT (الاكتشاف العلمي الآلي مع الاختبار التبايني الشاذ).يمكن استخدامه لأتمتة اكتشاف "الاكتشافات الجديدة" في البيانات العلمية، وبالتالي تبسيط الاستقصاء العلمي.وقد قام الباحثون بإثبات صحة الطريقة على مجموعات بيانات حقيقية في علم الفلك والفيزياء والطب الحيوي والتصوير، وكذلك على مجموعة بيانات اصطناعية، مما يدل على أن الطريقة حساسة للغاية لكميات صغيرة من البيانات الشاذة المحقونة عبر جميع المجالات.
وقد نُشرت نتائج البحث ذات الصلة، بعنوان "AutoSciDACT: الاكتشاف العلمي الآلي من خلال التضمين التبايني واختبار الفرضيات"، في مجلة NeurIPS 2025.
أبرز الأبحاث:
* AutoSciDACT هو إطار عمل عام شامل لاكتشاف حداثة البيانات العلمية، مع إمكانية النقل عبر المجالات؛
* تم تصميم عملية منهجية من خلال دمج بيانات المحاكاة العلمية والبيانات المصنفة يدويًا والمعرفة المتخصصة في سير عمل تقليل الأبعاد المقارنة؛
* تم إنشاء إطار إحصائي صارم لقياس أهمية الشذوذ الملحوظ وتحديد ما إذا كانت الشذوذ لها أهمية علمية من منظور إحصائي.
* تم التحقق من صحة النتائج باستخدام بيانات حقيقية في أربعة مجالات علمية مختلفة بشكل كبير، مما يدل على الفعالية والإقناع والقيمة الترويجية الكبيرة.

عنوان الورقة:
https://openreview.net/forum?id=vKyiv67VWa
قم بمتابعة الحساب العام والرد على " أوتوسيكداكت احصل على ملف PDF كامل
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:
https://hyper.ai/papers
مجموعات البيانات: مجموعات البيانات المتنوعة ومتعددة التخصصات تؤكد الأداء المتفوق لـ AutoSciDACT
للتحقق بدقة من الأداء المتفوق لـ AutoSciDACT،قام الباحثون باختباره على خمس مجموعات بيانات من مجالات مختلفة تمامًا.تتضمن مجموعات البيانات هذه بيانات من أربعة مجالات مميزة: علم الفلك، والفيزياء، والطب الحيوي، والتصوير، بالإضافة إلى مجموعة بيانات تم إنشاؤها صناعياً.
فيما يتعلق بمجموعات البيانات الفلكية،اختار الفريق بيانات الموجات الثقالية التي سجلها مرصد الموجات الثقالية بالتداخل الليزري (LIGO) في هانفورد، واشنطن، وليفينغستون، لويزيانا، كمعيار فلكي، يمتد على مدار جولة الرصد الثالثة من أبريل 2019 إلى مارس 2020. تتكون هذه البيانات من إشارات متسلسلة زمنية مدتها 50 ميلي ثانية من قناتين (قناة واحدة لكل مقياس تداخل)، مأخوذة بتردد 4096 هرتز (200 قياس لكل قناة). أُدرجت فئات مختلفة من البيانات، مثل "الضوضاء الصرفة"، و"تداخل الأجهزة"، و"الإشارات الفيزيائية الفلكية المعروفة"، ونوع خفي من الإشارات يُسمى "انفجار الضوضاء البيضاء" (WNB) (كشذوذ). استُبعدت إشارات WNB أثناء التدريب المسبق، ثم أُضيفت إلى البيانات لاختبار قدرة النموذج على تحديد هذه الإشارة غير المرئية من إشارات الموجات الثقالية.
مجموعات بيانات الفيزياءاختار الفريق مجموعة بيانات JETCLASS كمرجعٍ مرجعي في فيزياء الجسيمات، وهي مجموعة بيانات كبيرة تحتوي على "نفاثات" مُحاكية من تصادمات بروتون-بروتون في مصادم الهدرونات الكبير (LHC). استخدمت الدراسة مجموعةً فرعيةً من هذه المجموعة، والتي تضمنت نفاثات من عمليات الديناميكا اللونية الكمومية (QCD) (كوارك/غلوون)، واضمحلال الكوارك القمي (t → bqq′)، واضمحلال بوزون متجه W/Z (V → qq′). كما احتفظ الفريق بنفاثات الإشارة من اضمحلال بوزون هيغز المُحسَّن إلى الكوارك القعري (H → bb¯). استخدم الفريق مُحوّل الجسيمات (ParT) كمُشفِّر تبايني، وهو أحد أشكال بنية المُحوّل المُناسب لفيزياء الجسيمات.
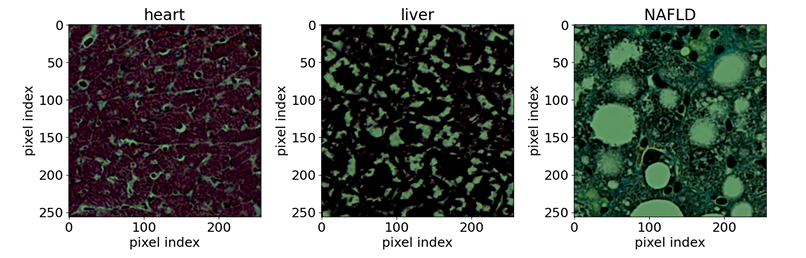
في مجال الطب الحيوي،استخدم الفريق صورًا مجهريًا ضوئيًا متاحة للعامة لعينات أنسجة مصبوغة. وشملت العينات المرجعية سبعة أنواع من أنسجة الفئران (الدماغ، والقلب، والكلى، والكبد، والرئة، والبنكرياس، والطحال) ونوعًا واحدًا من أنسجة كبد الفئران الطبيعية. كان الهدف من البحث الكشف عن أنسجة كبد الفئران غير الطبيعية الناتجة عن مرض الكبد الدهني غير الكحولي (NAFLD). كانت العينات المدخلة مقاطع نسيجية بدقة 256 × 256 بكسل، مستخرجة من صور مقطعية كاملة، مصبوغة باستخدام صبغة ماسون ثلاثية الألوان. الشبكة الأساسية المستخدمة هي EfficientNet-B0.
من حيث علم الصورة،استخدم الفريق مجموعة بيانات صور CIFAR-10 (50,000 صورة إجمالاً)، واختاروا عشوائيًا الفئة الأولى كفئة شذوذ، ثم أجروا تدريبًا مسبقًا على الفئات التسع المتبقية. خلال مرحلة الاكتشاف، استكمل الفريق مجموعة اختبار CIFAR-10 بـ 100,000 صورة من CIFAR-5m، مما زاد من عدد نقاط البيانات المتاحة لاختبار الفرضيات. استخدم الهيكل الأساسي للمُشفِّر شبكة ResNet-50 بأوزان مُدرَّبة مسبقًا، واستبدلوا الطبقة النهائية المتصلة بالكامل فقط بطبقة MLP أكبر قليلًا، وضبطوها بدقة في مهمة التضمين التبايني CIFAR.
فيما يتعلق بمجموعات البيانات الاصطناعية،الغرض الرئيسي منه هو إظهار القدرات الأساسية لبرنامج AutoSciDACT والتأكد من عدم تأثره بتفاصيل محددة لمجموعات البيانات العلمية الحقيقية. تتكون مجموعة البيانات المركبة من X⊂R^D+M، وتحتوي على D بُعدًا ذا دلالة وM بُعدًا ضوضاء. تُولّد الأبعاد الضوضائية بشكل موحد من 0 إلى 1، بينما تتكون الأبعاد ذات الدلالة من N عنقود غاوسي بمتوسط موحد 0-1 وتباينات مُولّدة عشوائيًا (موزعة بشكل موحد 0، 0.5). بعد ذلك، تُدوّر جميع الأبعاد عشوائيًا لإخفاء المتغيرات التمييزية الفعالة الأصلية. يُجرى التدريب باستخدام طريقة التضمين التبايني، باستخدام N-1 عنقود فقط كبيانات تدريب، مع الاحتفاظ بعنق واحد كإشارة للكشف. النموذج الأساسي المستخدم للتدريب هو مُدرك بسيط متعدد الطبقات (MLP).
بالإضافة إلى ذلك، شملت عملية التحقق التكميلي مجموعات بيانات أخرى، مثل مجموعة بيانات الجينوم لتحديد هجائن الفراشات، وبيانات حقيقية حول اضمحلال رباعيات البتون في بوزون هيغز في مصادم الهادرونات الكبير (LHC)، وذلك للتحقق بشكل أكبر من قدرة النموذج على التعميم عبر النطاقات. باختصار، بُنيت جميع هذه المجموعات المختلفة باستخدام "بيانات الخلفية" و"بيانات الإشارة غير الطبيعية"، واستُخدمت للتدريب المسبق للنموذج، وللتحقق من قدرته على اكتشاف الحداثة، على التوالي. تُظهر جميع نتائج التحقق فعالية AutoSciDACT كعملية عامة لاكتشاف الحداثة في البيانات العلمية، بالإضافة إلى قدرتها على التعميم عبر النطاقات.
هندسة النموذج: عملية من مرحلتين: "التدريب المسبق" + "الاكتشاف" تُنشئ أساليب جديدة للاكتشاف العلمي
يتم تنفيذ جوهر AutoSciDACT من خلال خطوتين: "التدريب المسبق - الاكتشاف".من خلال الجمع بين تضمين الميزات منخفضة الأبعاد والاختبارات الإحصائية، يمكننا استخراج "إشارات جديدة" ذات دلالة إحصائية من البيانات العلمية عالية الأبعاد.
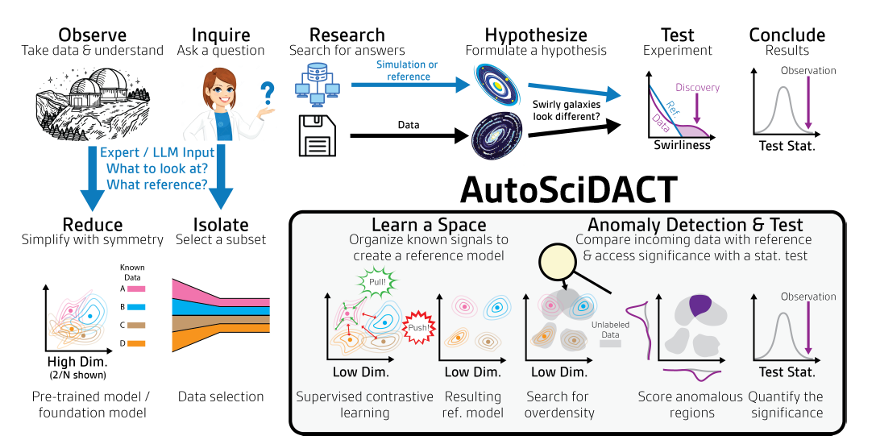
على وجه التحديد، تُعالج مرحلة ما قبل التدريب مشكلة تكرار البيانات عالية الأبعاد. فهي تُضغط بشكل رئيسي مئات أو آلاف أبعاد سمات الإدخال التي قد تحتويها البيانات العلمية الأصلية في متجهات منخفضة الأبعاد، مع الحفاظ على السمات الدلالية الرئيسية للبيانات - أي المعلومات الأساسية بالمعنى العلمي - مما يُرسي الأساس للتحليل اللاحق.
من حيث التنفيذ، يعتمد خط الأنابيب المُدرَّب مسبقًا على مُرمِّز fθ : X → Rᵈ مُدرَّب من خلال التعلم التبايني، الذي يُرسِل البيانات الخام من مساحة الإدخال عالية الأبعاد X إلى تمثيل منخفض الأبعاد في Rᵈ. صُمِّمَ الهدف التبايني لتعظيم التوافق بين المدخلات المتشابهة (الأزواج الموجبة) مع فصل المدخلات غير المتشابهة (الأزواج السالبة) في مساحة التعلم. يستخدم الإطار الأساسي SimCLR، الذي يُدرِّب المُرمِّز fθ ورأس الإسقاط gϕ.بعد التدريب، يتم الاحتفاظ فقط بالمشفر fθ لإخراج التضمين النهائي منخفض الأبعاد.عمليًا، يُستخدم التعلم التبايني المُشرف (SupCon). يستخدم هذا التعلم بيانات تدريب مُصنّفة لإنشاء أزواج موجبة من نفس الفئة وأزواج سالبة من فئات مختلفة، بحيث تكون دالة الخسارة هي خسارة SupCon. يمكن تصميم استراتيجيات لزيادة البيانات تتضمن معرفة المجال لتكملة بناء الأزواج الموجبة. علاوة على ذلك، يمكن إضافة خسارة الإنتروبيا المتقاطعة المُشرفة (LCE) اختياريًا، مما ينتج عنه خسارة إجمالية قدرها L = LSupCon + λCELCE (حيث تتراوح قيمة λCE بين 0.1 و0.5 لضمان عدم هيمنة هدف التصنيف).
تستفيد مرحلة الاكتشاف من التضمينات منخفضة الأبعاد التي تم الحصول عليها في الخطوة السابقة ضمن إطار NPLM (آلة التعلم الفيزيائية الجديدة) لاكتشاف الشذوذ واختبار الفرضيات.البحث عن "إشارات جديدة" محتملة في بيانات البحث وقياس أهميتها من خلال الاختبارات الإحصائية.
في هذه المرحلة، يستخدم الباحثون متجهات التضمين fθ لمعالجة مجموعات البيانات غير المرئية والبحث عن التجمعات الشاذة، أو تشوهات الكثافة، أو القيم المتطرفة التي تنحرف عن توزيع الخلفية في الفضاء منخفض الأبعاد. تعتمد عملية البحث على نهج اختبار الفرضيات العلمية الكلاسيكي، بمقارنة مجموعة بيانات مرجعية R مكونة من خلفية معروفة بمجموعة بيانات مرصودة D ذات تركيب غير معروف، في محاولة لقبول أو رفض الفرضية الصفرية القائلة بأن R وD لهما نفس التوزيع. تُختبر الفرضية باستخدام خوارزمية NPLM (المستندة إلى اختبار نسبة الاحتمالية الكلاسيكي الذي اقترحه نيمان وآخرون).عندما يتم دمجه مع متجهات التضمين المعبر عنها المكتسبة، يصبح هذا النموذج حساسًا للغاية للإشارات الجديدة.
تجدر الإشارة إلى أن تقليل الأبعاد أثناء التدريب المسبق أمر بالغ الأهمية، لأن فعالية أي طريقة اختبار إحصائي، بما في ذلك NPLM، تنخفض بشكل ملحوظ مع زيادة أبعاد البيانات. بمعنى آخر، تتطلب الأبعاد الأعلى حجم عينة أكبر لاكتشاف الإشارات الصغيرة ذات الدلالة الإحصائية، ولكن في البحث العلمي العملي، غالبًا ما يكون حجم العينة أقل من متطلبات الأبعاد العالية. لذلك، لا يمكن لأدوات مثل NPLM أن تعمل بفعالية إلا من خلال ضغط البيانات عالية الأبعاد، مما يُمكّن من اكتشاف الشذوذات ذات الدلالة الإحصائية، وبالتالي تعزيز قيمتها العلمية.
النتائج التجريبية: تسلط المقارنات متعددة الأبعاد والواسعة النطاق الضوء على قابلية نقل AutoSciDACT وقدراته عبر المجالات
قام الباحثون بتدريب وتقييم AutoSciDACT على كل مجموعة بيانات باستخدام نفس الطريقة، وإجراء تعديلات طفيفة فقط أثناء مرحلة ما قبل التدريب لتناسب الاحتياجات المحددة لكل مجموعة بيانات.
جميع المُرمِّزات لها بُعد تضمين d=4. تظهر نتائج التضمين كما هو موضح في الشكل أدناه.بالإضافة إلى ذلك، أنشأت التجربة ثلاثة أنواع من معايير المقارنة، بما في ذلك معيار الإشراف، ومعيار الإشراف المثالي، وخط الأساس ماهالانوبيس.
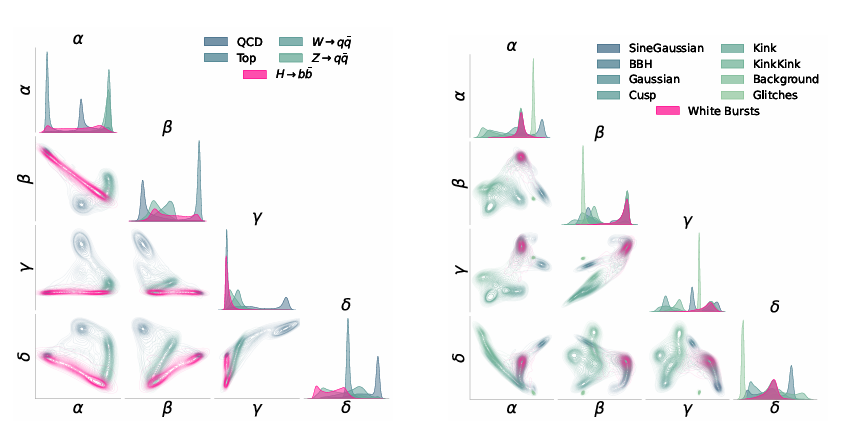
كما هو موضح في الشكل أدناه، تُظهر النتائج قدرة NPLM على اكتشاف انحيازات ذات دلالة إحصائية عالية (Z≳3 أو p≲10⁻³) بنسب إشارة منخفضة تصل إلى 11TP³T. يوفر خطا الأساس المُراقَبان، مع فهم كامل لتوزيع الإشارة في مساحة التضمين، حدًا أعلى معقولًا لحساسية الإشارة، وفي بعض الحالات، يقترب أداء NPLM من هذا الحد. عند تجاوز قيمة 5σ تقريبًا، تصبح بعض الاتجاهات غير صحيحة، ولكن عند هذا المستوى من الدلالة (p∼10⁻⁷)، تكون النتائج مُحددة آليًا.
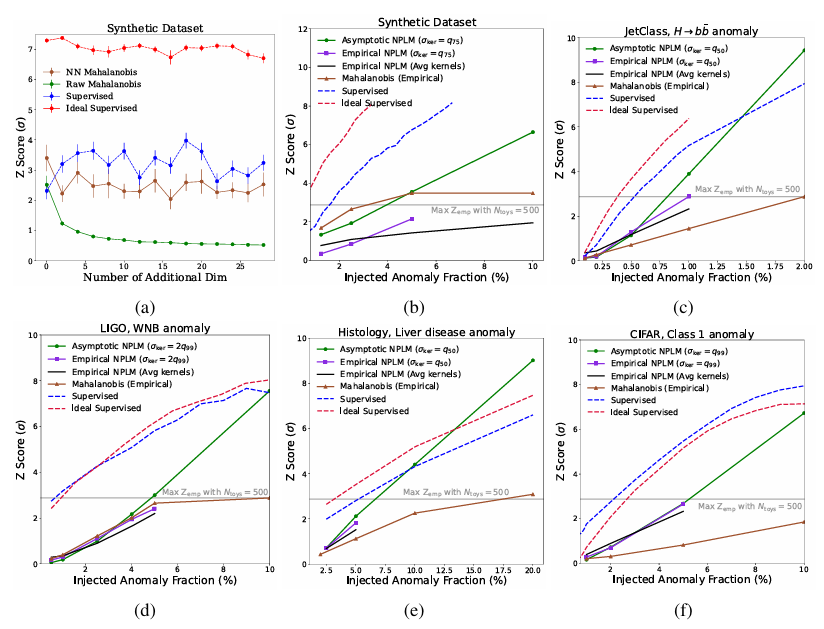
بالإضافة إلى البيانات الاصطناعيةفي جميع مجموعات البيانات الأخرى، يتفوق NPLM بشكل كبير على خط الأساس لمسافة Mahalanobis.ويرجع ذلك إلى قدرته على نمذجة التشوهات المختلفة في مساحة الإدخال.
بالنسبة لمجموعات بيانات LIGO وJETClass، تقترب الطريقة المقترحة من الحد الأعلى المُراقَب بدرجة Z تساوي 3، وهي تُضاهي أو تتجاوز جميع خوارزميات كشف الشذوذ في مجالاتها. في حين أن علم الفلك وفيزياء الجسيمات لطالما استخدما تقنيات كشف الشذوذ المُتطورة إحصائيًا، فإن تطبيقها على علم الأنسجة يُظهر قابلية تطبيق المنهجية عبر التخصصات العلمية.
من حيث علم الأنسجة،تظهر التجارب أن مساحة التضمين التي تم إنشاؤها باستخدام معلومات الملصق تتفوق على مساحة التضمين التي تم إنشاؤها فقط على أساس زيادة البيانات.بمساعدة AutoSciDACT، قدّم الباحثون طريقة جديدة تُمكّن من اكتشاف التشوهات الموضعية التي قد لا توجد إلا في أجزاء صغيرة من الأنسجة. تُعد هذه القدرة أساسية للكشف المبكر عن الأمراض، ولتوجيه أخصائيي علم الأمراض في تحديد المركبات السامة.
في عصر النمو الهائل للبيانات، أصبح "علماء الذكاء الاصطناعي" حقيقة واقعة.
تتسارع موجة الذكاء الاصطناعي، مُهددةً بزعزعة كل شيء. يشهد الاستكشاف العلمي، باعتباره طليعة البحث العلمي، تغييرات غير مسبوقة بفضل تمكين الذكاء الاصطناعي، ليصبح مجالًا أساسيًا أعادت موجة الذكاء الاصطناعي تشكيله جذريًا.
بالإضافة إلى AutoSciDACT المذكور في الورقة المذكورة أعلاهوفي المجال نفسه، اقترحت فرق من جوجل وجامعة ستانفورد وغيرهما أيضًا علماء مشاركين في مجال الذكاء الاصطناعي يمكنهم تقليد العلماء البشريين.يمكنه توليد الأفكار، والمناقشة، وطرح الأسئلة، والتحسين والتطوير، تمامًا كالإنسان. وتحديدًا، هو نظام متعدد الوكلاء مبني على منصة جيميني 2.0، يساعد العلماء على اكتشاف معارف جديدة ومبتكرة، واقتراح فرضيات وحلول بحثية مبتكرة قابلة للإثبات، استنادًا إلى الأدلة المتوفرة، وبالتزامن مع أهداف البحث والتوجيهات التي تقدمها مجلة ساينس.
عنوان الورقة:نحو عالم مشارك في مجال الذكاء الاصطناعي
عنوان الورقة:https://arxiv.org/abs/2502.18864
علاوة على ذلك، تتزايد قدرة الذكاء الاصطناعي على إجراء البحوث العلمية، حتى أنها تتطور من "التفكير التلقائي في أبحاث الإلكترونات" إلى "كتابة أوراق علمية كاملة". وقد اقترح فريق من جامعتي أكسفورد وكولومبيا عالم ذكاء اصطناعي كهذا.هذا هو أول إطار عمل شامل للاكتشاف العلمي الآلي بالكامل.يُمكّن هذا نماذج اللغات الكبيرة المتقدمة من إجراء البحوث بشكل مستقل ونشر نتائجها. ببساطة، يستطيع عالم الذكاء الاصطناعي هذا توليد أفكار بحثية مبتكرة، وكتابة الأكواد البرمجية، وإجراء التجارب، وتصور النتائج، ووصف نتائجه من خلال كتابة أوراق علمية كاملة، ثم إجراء عملية محاكاة لمراجعة الأقران للتقييم.
عنوان الورقة:عالم الذكاء الاصطناعي: نحو اكتشاف علمي مفتوح النهاية آلي بالكامل
عنوان الورقة:https://arxiv.org/abs/2408.06292
في النصف الأول من هذا العام، خضع تطبيق AI Scientist لتحديث رئيسي، ليتطور إلى الإصدار الثاني من AI Scientist. وبالمقارنة مع سابقه،لم يعد AI Scientist-v2 يعتمد على قوالب التعليمات البرمجية المحمولة بين البشر؛ بل يمكنه التعميم بشكل فعال عبر مجالات التعلم الآلي المختلفة.يستخدم هذا النظام أسلوب بحث شجرة الوكلاء التقدمي المبتكر، والذي يُدار بواسطة وكيل إدارة تجارب مُخصص، ويدمج حلقة تغذية راجعة لنموذج اللغة البصرية (VLM) لتعزيز مُكوّن مراجعة الذكاء الاصطناعي، مما يُحسّن بشكل متكرر محتوى الرسوم البيانية وجمالياتها. قيّم الباحثون AI Scientist-v2 بتقديم ثلاث مخطوطات مكتوبة ذاتيًا بالكامل إلى ورشة عمل ICLR المُراجعة من قِبل الأقران، وقد حققوا نتائج إيجابية للغاية. حصلت إحدى المخطوطات على درجة عالية بما يكفي لتجاوز متوسط الحد الأدنى البشري، مُسجلةً بذلك أول مرة تجتاز فيها ورقة بحثية مُولدة بالكامل بواسطة الذكاء الاصطناعي مراجعة الأقران بنجاح.
عنوان الورقة:عالم الذكاء الاصطناعي - الإصدار الثاني: اكتشاف علمي آلي على مستوى ورشة العمل عبر البحث الشجري الوكيل
عنوان الورقة:https://arxiv.org/abs/2504.08066
من الواضح أن الذكاء الاصطناعي والاستكشاف العلمي يتكاملان ويتطوران بعمق، بدءًا من المساعدة في صياغة الفرضيات وصولًا إلى البحث العلمي المستقل تمامًا، ومن التحقق في مجال واحد إلى التطبيق الواسع متعدد التخصصات. لا تقتصر هذه الأنظمة على تجاوز عوائق الكفاءة في الاكتشاف العلمي التقليدي، بل تدفع أيضًا نحو تحوله من "مدفوع بالتجربة" إلى "مدفوع بالبيانات". في المستقبل، ومع تحقيق نموذج التعاون بين الإنسان والآلة، سيفتح الذكاء الاصطناعي فصلًا جديدًا من الاكتشاف الفعال للمجتمع العلمي، مع إعطاء زخم جديد لتقدم الحضارة العالمية.








