Command Palette
Search for a command to run...
أحدث التقنيات في تحرير الصور! يجمع Qwen-Image-Edit بين إمكانيات التحرير الدلالي والمظهري؛ بينما يحلّ Granary مشكلة نقص البيانات في النماذج متعددة اللغات بـ 25 لغة أوروبية.

مع استمرار تطوير نماذج الصور ونضجها، لم يعد طلب المستخدمين لاستخدام النماذج الكبيرة يقتصر على إنشاء صورة واحدة، بل يأملون أيضًا في إجراء تعديلات أكثر تفصيلاً وقابلية للتحكم على الصور الموجودة. "التحرير" هو متطلب استخدام أكثر تفصيلاً ودقة من "التوليد".تتمتع برامج تحرير الصور التقليدية (مثل Photoshop) بعتبة استخدام معينة وغالبًا ما تتطلب من المستخدمين إجراء تعلم منهجي؛ وتتمتع تطبيقات الذكاء الاصطناعي لتحرير الصور الحالية بمجال للتحسين في كل من الوظائف والتأثيرات، وخاصة في قدرات عرض النص وتحريره.
وبناء على هذا،أصدر فريق Alitong Yiqianwen نموذج تحرير الصور الشامل Qwen-Image-Edit، الذي يتمتع بقدرات تحرير مزدوجة للدلالات والمظهر.لا يمكنه فقط فهم نية تعليمات تحرير المظهر بدقة، بل يمكنه أيضًا إجراء تحرير دلالي بصري متقدم مع الحفاظ على اتساق الأسلوب المرئي للصورة.ويمتد هذا النموذج أيضًا إلى قدرات عرض النصوص الصينية الممتازة التي تتمتع بها Qwen-Image في مجال تحرير الصور، مما يتيح التحرير الدقيق للنص في الصور.
باعتباره إصدارًا جديدًا من Qwen-Image، يعمل Qwen-Image-Edit على تحسين الحلقة المغلقة من إنشاء الصورة وتحرير السلسلة إلى عرض التأثير النهائي، مما يحسن بشكل كبير من قابلية استخدام الصور.تظهر التقييمات على معايير عامة متعددة أداءً متطورًا في مهام تحرير الصور.
أطلق الموقع الرسمي لـ HyperAI النسخة التجريبية "Qwen-Image-Edit: نموذج شامل لتحرير الصور". جربه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/nmjYo
من 18 أغسطس إلى 22 أغسطس، إليك نظرة عامة سريعة على تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 4
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في أغسطس: 2
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات التعرف على الكلام والترجمة الأوروبية Granary
Granary هي مجموعة بيانات كلامية متعددة اللغات واسعة النطاق، أصدرتها NVIDIA، وهي مصممة لتوفير مواد تدريب وتقييم عالية الجودة لنماذج التعرف التلقائي على الكلام (ASR)/التعرف التلقائي على الكلام (AST) متعددة اللغات. تحتوي مجموعة البيانات على ما يقارب مليون ساعة من بيانات الكلام عالية الجودة شبه المُسمّاة (ASR)، وتغطي 25 لغة أوروبية.
الاستخدام المباشر:https://go.hyper.ai/D3926
2. مجموعة بيانات معيارية للإجابة على أسئلة الفيديو الطويلة M3-Bench
M3-Bench، وهي مجموعة بيانات مرجعية للإجابة على الأسئلة باستخدام مقاطع فيديو طويلة، أصدرها فريق ByteDance Seed، مصممة لتقييم الذاكرة طويلة المدى وقدرات التفكير المنطقي لدى الوكلاء متعددي الوسائط. تحتوي مجموعة البيانات على 1020 عينة فيديو، تتضمن كل منها تعليقات توضيحية، ومخرجات وسيطة، ورسومًا بيانية للذاكرة.
الاستخدام المباشر:https://go.hyper.ai/LIHsO
3. مجموعة بيانات الكلام عالية النطاق الترددي واسعة النطاق HiFiTTS-2
HiFiTTS-2 هي مجموعة بيانات صوتية واسعة النطاق وعالية النطاق الترددي، مصممة لدعم تدريب وتقييم نماذج تحويل النص إلى كلام (TTS) عالية الجودة. تحتوي مجموعة البيانات على بيانات وصفية صوتية من 5000 متحدث، أي ما يقارب 36700 ساعة من تسجيلات الكلام الإنجليزية بتردد 22.05 كيلوهرتز و31700 ساعة بتردد 44.1 كيلوهرتز، مُرتبة في طبقات بناءً على جودة النطاق الترددي ومعدل أخذ العينات.
الاستخدام المباشر:https://go.hyper.ai/XZwDD
4. مجموعة بيانات الإجابة على الأسئلة الثقافية البصرية متعددة اللغات من CulturalGround
CulturalGround هي مجموعة بيانات بصرية متعددة اللغات والوسائط للإجابة على الأسئلة، تهدف إلى مواءمة المعرفة الثقافية، أصدرها مختبر NeuLab بجامعة كارنيجي ميلون. تهدف إلى تحسين قدرات فهم واستدلال نماذج اللغات الكبيرة متعددة الوسائط للكيانات الثقافية المتخصصة واللغات محدودة الموارد.
الاستخدام المباشر:https://go.hyper.ai/wayAA
5. مجموعة بيانات التفضيلات البشرية HPDv3
HPDv3 هي أول مجموعة بيانات واسعة النطاق للتفضيلات البشرية، أصدرتها MizzenAI وMMLab في الجامعة الصينية في هونغ كونغ. وقد اختيرت الورقة البحثية ذات الصلة لمؤتمر ICCV 2025. صُممت هذه المجموعة من البيانات لمواءمة نماذج توليد النصوص إلى صور، وتعديلها، وتقييمها، بهدف تعزيز تطور النماذج في مواءمتها مع الجماليات البشرية وتحسين الاتساق الدلالي.
الاستخدام المباشر:https://go.hyper.ai/xV8fK
6. مجموعة بيانات معيارية للإجابة على الأسئلة المرئية COREVQA
COREVQA، وهي مجموعة بيانات مرجعية للإجابة على الأسئلة البصرية، أصدرها مركز أبحاث الذكاء الاصطناعي Algoverse، مصممة لتقييم قدرات نماذج اللغة البصرية (VLMs) على التفكير المنطقي في مشاهد الحشود. تركز مجموعة البيانات بشكل أساسي على مشاهد الحشود الواقعية، مع التركيز على تحديات مثل الانسداد، وتغييرات المنظور، وتداخل الخلفية. وتهدف إلى تحسين قدرات نماذج اللغة البصرية على الإدراك الدقيق والتفكير المنطقي في السيناريوهات الاجتماعية المعقدة.
الاستخدام المباشر:https://go.hyper.ai/tOFNw
7. مجموعة بيانات تجزئة العمق والعقبات لطائرات بدون طيار DDOS
DDOS هي مجموعة بيانات صور جوية اصطناعية مصممة لتطوير خوارزميات التحكم الذاتي بالطائرات بدون طيار. صُنفت مجموعة البيانات بعناية حسب نوع البيئة. تتكون مجموعة التدريب من 300 رحلة جوية، بإجمالي 30,000 صورة؛ وتتكون مجموعة التحقق من 20 رحلة جوية، بإجمالي 2,000 صورة؛ وتتكون مجموعة الاختبار من 20 رحلة جوية، بإجمالي 2,000 صورة.
الاستخدام المباشر:https://go.hyper.ai/XRE6R

8. مجموعة بيانات الاستدلال متعدد المجالات من نيموترون
Nemotron هي مجموعة بيانات استدلال متعددة المجالات أصدرتها NVIDIA، وهي مصممة لتحسين كفاءة الاستدلال ودقته في نموذج Llama. تحتوي مجموعة البيانات على 25.66 مليون عينة تغطي خمس فئات: المحادثة، والبرمجة، والرياضيات، والعلوم والتكنولوجيا والهندسة والرياضيات (STEM)، واستدعاءات الأدوات.
الاستخدام المباشر:https://go.hyper.ai/WP2Ym
9. مجموعة بيانات معيارية متعددة الوسائط لوثائق Haystack
دوك هايستاك (Document Haystack) هي مجموعة بيانات مرجعية متعددة الوسائط للوثائق، أصدرتها أمازون إيه جي آي. تحتوي على 400 صنف من الوثائق و8250 سؤال استرجاع. تهدف إلى تقييم قدرات استرجاع المعلومات وفهمها لنماذج اللغة المرئية (VLMs) في الوثائق ذات السياقات الطويلة والمعقدة.
الاستخدام المباشر:https://go.hyper.ai/Q08Xt
10. مجموعة بيانات الصوت العاطفي CSEMOTIONS
CSEMOTIONS هي مجموعة بيانات صوتية عاطفية مصممة لدعم الأبحاث في مجال التحكم وتوليد الكلام الطبيعي. تحتوي مجموعة البيانات على ما يقارب 10 ساعات من البيانات الصوتية عالية الجودة، تغطي سبع فئات عاطفية، منها الهدوء والسعادة والغضب، وقد سجّلها 10 ممثلين صوتيين محترفين.
الاستخدام المباشر:https://go.hyper.ai/4fe7A
دروس تعليمية عامة مختارة
1. نشر vLLM + Open-WebUI في يناير-v1-4B
Jan-v1-4B هو نموذج لغوي مفتوح المصدر، يحتوي على 4 مليارات معلمة، أصدره فريق Jan. يستهدف هذا النموذج الاستدلال الذكي القائم على الجسم واستدعاء الأدوات، وهو الإصدار الأول من عائلة Jan، ومُحسّن لسيناريوهات سير العمل الواقعية في تطبيقات Jan. استنادًا إلى Qwen3-4B-Thinking-2507، تم تحسين هذا النموذج وتوسيعه بدقة 91.1% على معيار SimpleQA، مما يُظهر تحسينات كبيرة في الأداء من خلال توسيع النموذج وضبطه.
تشغيل عبر الإنترنت:https://go.hyper.ai/CZf3s
2. برنامج تعليمي للتنبؤ بتصنيف مجموعات بيانات تشخيص سرطان الثدي باستخدام التعلم الآلي
يوضح هذا البرنامج التعليمي، المستند إلى مجموعة بيانات تشخيص سرطان الثدي في ويسكونسن (WDBC)، عملية التعلم الآلي الكاملة لمشكلة تصنيف ثنائي. يساعدك هذا البرنامج التعليمي على فهم جوهر عملية اختيار الميزات، وضبط النموذج، وتصور النتائج، مما يوفر مرجعًا لنمذجة تشخيصات أمراض أخرى.
تشغيل عبر الإنترنت:https://go.hyper.ai/zFjil
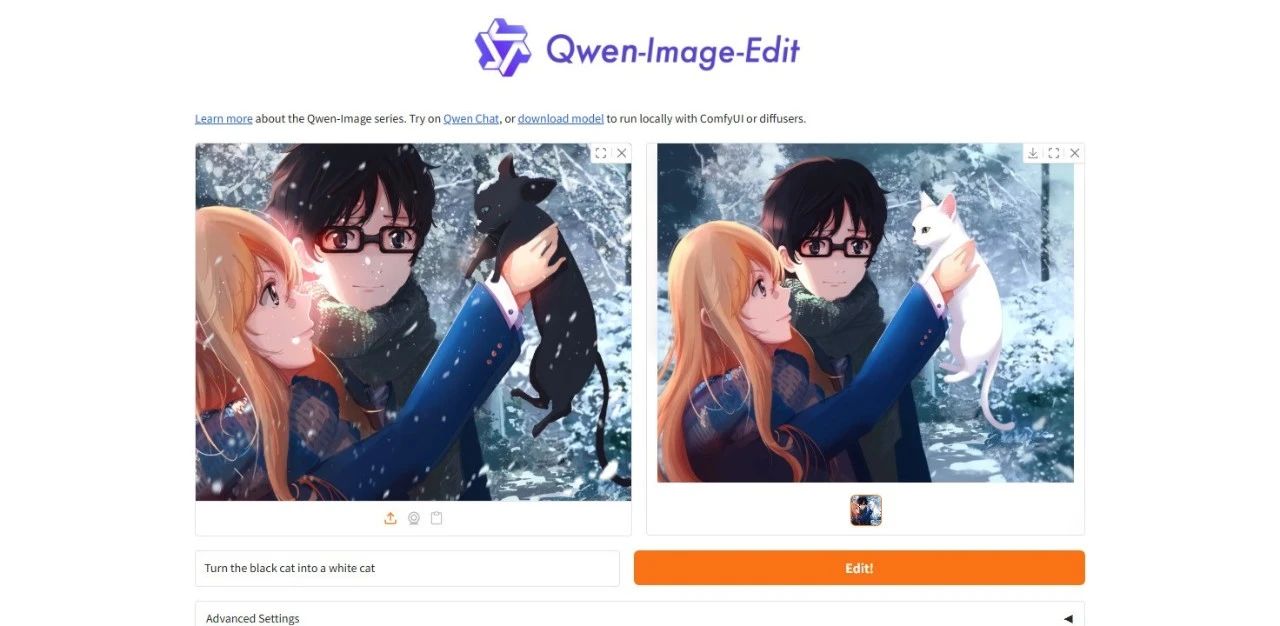
3. Qwen-Image-Edit: عرض توضيحي لنموذج تحرير الصور الشامل
Qwen-Image-Edit هو نموذج شامل لتحرير الصور، طوّره فريق Alibaba Tongyi Qianwen. يجمع هذا النموذج بين إمكانيات التحرير الدلالي والبصري، ويدعم التحرير الدقيق للنصوص باللغتين الصينية والإنجليزية، ويتيح تعديل النصوص داخل الصور مع الحفاظ على الخط والحجم والنمط الأصلي.
تشغيل عبر الإنترنت:https://go.hyper.ai/nmjYo
4. نشر Qwen3-4B-2507 بنقرة واحدة
Qwen3-4B-Thinking-2507 وQwen3-4B-Instruct-2507 نموذجان لغويان كبيران طورهما فريق Alibaba Tongyi Qianwen. من حيث الأداء، يتفوق Qwen3-4B-Thinking-2507 بشكل ملحوظ على نموذج Qwen3 الأصغر حجمًا من نفس الحجم في حل المشكلات المعقدة، والقدرات الرياضية، وقدرات الترميز، وقدرات استدعاء الدوال متعددة الجولات. في المجالات غير المتعلقة بالاستدلال، يتفوق Qwen3-4B-Instruct-2507 بشكل شامل على نموذج GPT-4.1-nano صغير الحجم مغلق المصدر في المعرفة، والاستدلال، والبرمجة، والمحاذاة، وقدرات الوكيل، ويقترب من الأداء الذي يحققه نموذج Qwen3-30B-A3B متوسط الحجم (غير المتعلق بالاستدلال).
تشغيل عبر الإنترنت:https://go.hyper.ai/HiqSR
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

توصيات الورقة البحثية لهذا الأسبوع
1. DINOv3
يُقدّم هذا التقرير الفني DINOv3، الذي يُولّد خصائص كثيفة وعالية الجودة، ويُحقق أداءً استثنائيًا في مجموعة واسعة من مهام الرؤية، مُتفوّقًا بشكل ملحوظ على نماذج خط الأساس السابقة ذاتية الإشراف وضعيفة الإشراف. كما أصدر الباحثون سلسلة نماذج الرؤية DINOv3، بهدف تطوير أحدث التقنيات في مجموعة واسعة من المهام ومجموعات البيانات من خلال توفير حلول قابلة للتطوير لمواجهة قيود الموارد المتنوعة وسيناريوهات النشر المُختلفة.
رابط الورقة:https://go.hyper.ai/tBuYx
2. التقرير الفني لـ Ovis2.5
تقدم هذه الورقة البحثية نظام Ovis2.5، خليفة Ovis2، المصمم للإدراك البصري بدقة أصلية والتفكير متعدد الوسائط القوي. يدمج Ovis2.5 محولًا بصريًا بدقة أصلية يعالج الصور مباشرةً بدقتها الأصلية المتغيرة، متجنبًا تدهور الجودة المرتبط بالتجزئة بدقة ثابتة، مع الحفاظ التام على التفاصيل الدقيقة والتخطيط الشامل.
رابط الورقة:https://go.hyper.ai/jlEXl
3. SSRL: التعلم التعزيزي بالبحث الذاتي
يدرس الباحثون إمكانات نماذج اللغات الكبيرة (LLMs) كمحاكيات فعّالة لمهام بحث الوكلاء في التعلم التعزيزي (RL)، مما يقلل الاعتماد على تفاعلات محركات البحث الخارجية المكلفة. تُظهر التقييمات التجريبية أن نماذج السياسات المُدرّبة باستخدام SSRL توفر بيئةً اقتصاديةً ومستقرةً لتدريب التعلم التعزيزي القائم على البحث، مما يقلل بشكل كبير من الاعتماد على محركات البحث الخارجية ويُسهّل الانتقال السلس من المحاكاة إلى الواقع.
رابط الورقة:https://go.hyper.ai/4TFRe
4. الزعتر: فكر فيما وراء الصور
نظرًا لعدم وجود عمل مفتوح المصدر يقدم حاليًا مجموعة ميزات قابلة للمقارنة بتلك الموجودة في النماذج الملكية، فإن هذه الورقة تجري استكشافًا أوليًا في هذا الاتجاه وتقترح Thyme (التفكير خارج نطاق الصور)، والذي يمكّن نماذج اللغة الكبيرة متعددة الوسائط (MLLMs) من تجاوز أساليب "التفكير من خلال الصور" الحالية وإنشاء وتنفيذ عمليات معالجة الصور والعمليات الحسابية المختلفة بشكل مستقل من خلال التعليمات البرمجية القابلة للتنفيذ.
رابط الورقة:https://go.hyper.ai/ZhLMI
5. سلسلة العوامل: نماذج أساسية للعوامل من البداية إلى النهاية عبر التقطير متعدد العوامل والتعزيز التعزيزي للعوامل
تعتمد معظم أنظمة الوكلاء المتعددة الحالية على توجيهات مُعدّة يدويًا أو هندسة سير عمل، وهي مبنية على أطر عمل وكلاء معقدة، مما يؤدي إلى ضعف كفاءة الحوسبة، ومحدودية القدرات، وعدم القدرة على الاستفادة من التعلم المُركّز على البيانات. يقترح هذا البحث نموذجًا جديدًا للتفكير في ماجستير القانون (LLM)، يُمكّن من حل المشكلات المعقدة بشكل متكامل ضمن نموذج واحد، باستخدام نفس آليات أنظمة الوكلاء المتعددة.
رابط الورقة:https://go.hyper.ai/5m3gV
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
اقترح فريق مشترك من جامعة أكسفورد وآخرين طريقةً قائمةً على الرسوم البيانية لتحليل المصطلحات الطبية (RAG)، مُصممة خصيصًا للمجال الطبي، وهي Medical GraphRAG. تُحسّن هذه الطريقة أداء ماجستير الحقوق في المجال الطبي بشكل فعال من خلال توليد إجابات مبنية على الأدلة وشروحات رسمية للمصطلحات الطبية.
شاهد التقرير الكامل:https://go.hyper.ai/3458z
يواصل فريق تونغي تشيانوين إثراء مصفوفة نماذجه مفتوحة المصدر، بالتركيز على الابتكارات المعمارية، وتحسينات الكفاءة، وتحقيق إنجازات في سيناريوهات التعمق، محققًا أداءً يُضاهي أداء رواد الصناعة. وقد نشر قسم "الدروس التعليمية" في الموقع الرسمي لشركة هايبر إيه آي العديد من الدروس التعليمية لنماذج تونغي مفتوحة المصدر.
شاهد التقرير الكامل:https://go.hyper.ai/JKJTY
اقترح فريق من جامعة كورنيل دائرة متكاملة تُسمى الشبكة العصبية الميكروية (MNN)، قادرة على معالجة البيانات فائقة السرعة وإشارات الاتصالات اللاسلكية في آنٍ واحد. بفضل استهلاكها المنخفض للطاقة وحجمها الصغير، تُقدم هذه الدائرة حلاً جديدًا لتطبيقات النطاق الترددي العالي.
شاهد التقرير الكامل:https://go.hyper.ai/Cki2I
في الدورة الصيفية للذكاء الاصطناعي للهندسة الحيوية بجامعة شنغهاي جياو تونغ لعام ٢٠٢٥، شاركت البروفيسورة تشوانغ ينغ بينغ من جامعة شرق الصين للعلوم والتكنولوجيا آراءها حول "الذكاء الاصطناعي يُساعد في عمليات التصنيع الحيوي الفعّالة". وقدّمت شرحًا للنظام التقني وإنجازات الفريق من ثلاثة جوانب: العلاقة بين التصنيع الحيوي والبيولوجيا التركيبية، ومجالات تطبيق منتجات البيولوجيا التركيبية، وتكنولوجيا وممارسات التصنيع الحيوي الذكي.
شاهد التقرير الكامل:https://go.hyper.ai/LgKcG
لتعزيز التطبيق الواسع النطاق للذكاء الاصطناعي في مجال هندسة البروتينات، طورت مجموعة الأبحاث التابعة للبروفيسور هونغ ليانغ في جامعة شنغهاي جياو تونغ منصة عمل مفتوحة المصدر للهندسة البروتينية VenusFactory لدمج استرجاع البيانات البيولوجية ومعايرة المهام الموحدة ونماذج لغة البروتين المدربة مسبقًا.
شاهد التقرير الكامل:https://go.hyper.ai/p3llU
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:https://go.hyper.ai/wiki

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








