Command Palette
Search for a command to run...
١٠ ملايين ساعة من البيانات الصوتية! نموذج Higgs Audio V2 الصوتي يُحسّن القدرات العاطفية؛ MathCaptcha10k يُحسّن تقنية التعرف على رموز التحقق.

ماذا سيحدث إذا أُضيفت عشرة ملايين ساعة من بيانات الكلام إلى تدريب نموذج لغوي كبير للنص؟ بناءً على هذه الفكرة،بعد إجراء العديد من الأبحاث، أصدر لي مو وفريقه Boson AI رسميًا نموذج الكلام واسع النطاق "Higgs Audio V2".
غالبًا ما تستخدم أنظمة تحويل النص إلى كلام (TTS) التقليدية إخراجًا صوتيًا ميكانيكيًا، مما يفتقر إلى التكيف العاطفي والإيقاع الطبيعي. تتطلب الحوارات متعددة الشخصيات تجزئة يدوية، ويصعب مطابقة جرس الصوت مع الشخصية باستخدام النماذج وحدها. من ناحية أخرى، يقدم Higgs Audio V2 ميزات مبتكرة نادرًا ما تُرى في أنظمة تحويل النص إلى كلام التقليدية.ويشمل ذلك التكيف التلقائي للإيقاع أثناء السرد، والقدرة على إنشاء حوارات متعددة المتحدثين، واستنساخ الصوت بدون عينة والطنين اللحني، والتوليد المتزامن للكلام والموسيقى الخلفية، مما يمثل قفزة كبيرة في قدرات الذكاء الاصطناعي الصوتي.
ومن الجدير بالذكر أنه في EmergentTTS-Eval،تفوق النموذج على gpt-4o-mini-tts بمقدار 75.7% و55.7% في فئات المشاعر والأسئلة على التوالي.وهذا يعكس أن "التفاعل العاطفي" أصبح خطوة أساسية للنموذج في مجال الصوت.
أطلق الموقع الرسمي لشركة HyperAI مؤخرًا "Higgs Audio V2: إعادة تعريف القوة التعبيرية لتوليد الكلام". تعالوا وجرّبوه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/Ty0CM
من 4 أغسطس إلى 8 أغسطس، إليك نظرة عامة سريعة على تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 7
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في أغسطس: 2
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات الإجابة على أسئلة القيادة الذاتية STRIDE-QA-Mini
STRIDE-QA-Mini هي مجموعة بيانات للإجابة على الأسئلة في مجال القيادة الذاتية، مصممة لدراسة قدرات الاستدلال المكاني الزمني لنماذج اللغة البصرية (VLMs) في سيناريوهات القيادة الذاتية. تحتوي مجموعة البيانات على 103,220 زوجًا من الأسئلة والأجوبة و5,539 عينة صور. البيانات مستمدة من لقطات حقيقية لكاميرات مراقبة السيارات في طوكيو.
الاستخدام المباشر:https://go.hyper.ai/9DVTI
2. مجموعة بيانات صور رمز التحقق الحسابي MathCaptcha10k
MathCaptcha10K هي مجموعة بيانات لصور CAPTCHA حسابية، مصممة لاختبار وتدريب خوارزميات التعرف على CAPTCHA، خاصةً عند التعامل مع رموز CAPTCHA ذات الخلفيات المشتتة والنصوص المشوهة. تحتوي مجموعة البيانات على 10,000 مثال مُعلّم و11,766 مثالًا غير مُعلّم. يحتوي كل مثال مُعلّم على صورة CAPTCHA، والأحرف الدقيقة فيها، وإجابة العدد الصحيح.
الاستخدام المباشر:https://go.hyper.ai/QERJt

3. مجموعة بيانات الإجابة على الأسئلة الاصطناعية متعددة الوسائط CoSyn-400K
CoSyn-400K هي مجموعة بيانات متعددة الوسائط للإجابة على الأسئلة الاصطناعية، أصدرتها جامعة بنسلفانيا ومعهد ألين للذكاء الاصطناعي بشكل مشترك. تهدف إلى توفير موارد بيانات اصطناعية عالية الجودة وقابلة للتطوير لتدريب النماذج متعددة الوسائط. تحتوي مجموعة البيانات على أكثر من 400,000 زوج من الأسئلة والأجوبة المصورة والنصية، مما يدعم مهام الإجابة البصرية.
الاستخدام المباشر:https://go.hyper.ai/aNjiz
4. مجموعة بيانات توليد الصوت غير اللفظي NonverbalTTS
NonverbalTTS هي مجموعة بيانات لتوليد الصوت غير اللفظي، أصدرتها VK Lab وYandex. تهدف إلى تعزيز أبحاث تحويل النص إلى صوت (TTS) التعبيرية، ودعم نماذج لتوليد كلام طبيعي يحتوي على مشاعر وأصوات غير لفظية.
الاستخدام المباشر:https://go.hyper.ai/0Gz9V
5. GPT Image Edit-1.5M Image Generation Dataset
GPT Image Edit-1.5M هي مجموعة بيانات لتوليد الصور، أصدرتها جامعة كاليفورنيا، سانتا كروز، وجامعة إدنبرة. تهدف إلى توفير مورد بيانات شامل متعدد الوسائط لتدريب نماذج تحرير الصور وتقييمها. تحتوي مجموعة البيانات على أكثر من 1.5 مليون صورة ثلاثية عالية الجودة (التعليمات، والصورة المصدرية، والصورة المحررة).
الاستخدام المباشر:https://go.hyper.ai/ohpmD

6. مجموعة بيانات تسلسل بروتين UniRef50
مجموعة بيانات تسلسل بروتين UniRef50 مستمدة من قاعدة بيانات UniProt المعرفية، ومن تسلسلات UniParc عبر التجميع التكراري. تضمن هذه العملية التكرارية أن تكون التسلسلات التمثيلية في UniRef50 عالية الجودة، وغير مكررة، ومتنوعة، مما يوفر تغطية شاملة لمساحة تسلسل البروتين لنماذج لغة البروتين.
الاستخدام المباشر:https://go.hyper.ai/EcUF5
7. مجموعة بيانات معيارية لإدراك الاختلاف والإنصاف المدرك للاختلاف
"الإنصاف المراعي للاختلاف" هي مجموعة بيانات مرجعية للاختلاف، أصدرتها جامعة ستانفورد. تهدف إلى قياس أداء النماذج في إدراك الاختلاف وإدراك السياق. نُشرت الورقة البحثية ذات الصلة في مؤتمر ACL 2025، وحصلت على جائزة أفضل ورقة بحثية.
الاستخدام المباشر:https://go.hyper.ai/wwBos
8. مجموعة بيانات SFT الروسية T-Wix
T-Wix عبارة عن مجموعة بيانات SFT تحتوي على 499,598 عينة باللغة الروسية، وهي مصممة لتعزيز قدرات النموذج من حل المشكلات الخوارزمية والرياضية إلى المحادثة والتفكير المنطقي وأنماط الاستدلال.
الاستخدام المباشر:https://go.hyper.ai/p0sgT
9. مجموعة بيانات الاستدلال متعدد المجالات المُتحقق منها بواسطة WebInstruct
WebInstruct-verified هي مجموعة بيانات استدلالية متعددة المجالات، أصدرتها جامعة واترلو ومعهد فيكتور بشكل مشترك. تهدف هذه المجموعة إلى تعزيز قدرات طلاب الماجستير في القانون على الاستدلال في مختلف المجالات مع الحفاظ على نقاط قوتهم في الرياضيات. تحتوي مجموعة البيانات على ما يقارب 230,000 سؤال استدلالي عبر صيغ إجابات متنوعة، بما في ذلك أسئلة الاختيار من متعدد ومجموعات بيانات التعبيرات العددية، بتوزيع متوازن بين المجالات.
الاستخدام المباشر:https://go.hyper.ai/oCgsZ
10. مجموعة بيانات الاستدلال المالي Finance-Instruct-500k
Finance-Instruct-500k هي مجموعة بيانات استدلال مالي مصممة لتدريب نماذج لغوية متقدمة للمهام المالية، والاستدلال، والحوار متعدد الأدوار. تحتوي مجموعة البيانات على أكثر من 500,000 سجل عالي الجودة من المجال المالي، تغطي الإجابة على الأسئلة المالية، والاستدلال، وتحليل المشاعر، وتصنيف المواضيع، والتعرف على الكيانات المسماة متعددة اللغات، والذكاء الاصطناعي التحادثي.
الاستخدام المباشر:https://go.hyper.ai/03UVH
دروس تعليمية عامة مختارة
1. Higgs Audio V2: إعادة تعريف القوة التعبيرية لتوليد الكلام
Higgs Audio V2 هو نموذج كلام ضخم، أصدره لي مو وفريقه في Boson AI. يحقق هذا النموذج أداءً متطورًا على معايير TTS التقليدية، بما في ذلك Seed-TTS Eval ومجموعة بيانات الكلام العاطفي (ESD). يُظهر النموذج قدرات نادرة في الأنظمة السابقة، بما في ذلك التكيف التلقائي للإيقاع أثناء السرد، والتوليد التلقائي لمحادثات متعددة المتحدثين بلغات متعددة.
تشغيل عبر الإنترنت:https://go.hyper.ai/BqZJD
2. Ovis-U1-3B: نموذج الفهم متعدد الوسائط والتوليد
Ovis-U1-3B هو نموذج موحد متعدد الوسائط، أصدره فريق Ovis التابع لمجموعة علي بابا. يدمج هذا النموذج ثلاث قدرات أساسية: الفهم متعدد الوسائط، وتوليد النص إلى صورة، وتحرير الصور. بفضل بنيته المتقدمة والتدريب التعاوني الموحد، يُمكّن النموذج من توليف صور عالية الدقة وتفاعل فعّال بين النص والصورة.
تشغيل عبر الإنترنت:https://go.hyper.ai/oSA7p

3. Neta Lumina: نموذج عالي الجودة لتوليد الصور ثنائية الأبعاد
نيتا لومينا هو نموذج توليد صور عالي الجودة بنمط الأنمي، أصدرته Neta.art. يعتمد النموذج على Lumina-Image-2.0، وهو مشروع مفتوح المصدر لفريق Alpha-VLLM في مختبر الذكاء الاصطناعي في شنغهاي. ويستفيد النموذج من كميات هائلة من صور الأنمي عالية الجودة وبيانات مُصنّفة متعددة اللغات، لتزويده بقدرات فعّالة على فهم وتفسير البيانات.
تشغيل عبر الإنترنت:https://go.hyper.ai/nxCwD

4. Qwen-Image: نموذج صورة مع إمكانيات متقدمة لعرض النص
Qwen-Image هو نموذج واسع النطاق لتوليد وتحرير صور عالية الجودة، طوّره فريق Alibaba Tongyi Qianwen. يُحقق هذا النموذج إنجازاتٍ ثورية في عرض النصوص، ويدعم إخراجًا عالي الدقة على مستوى الفقرات متعددة الأسطر باللغتين الصينية والإنجليزية، ويُعيد إنتاج المشاهد المعقدة بدقة وتفاصيل دقيقة.
تشغيل عبر الإنترنت:https://go.hyper.ai/8s00s

5. MediCLIP: اكتشاف الشذوذ في الصور الطبية ذات العينات الصغيرة باستخدام CLIP
MediCLIP، الذي نشرته جامعة بكين، هو طريقة فعّالة لكشف الشذوذ في الصور الطبية باستخدام عدد قليل من اللقطات، تُحقق أداءً متطورًا في كشف الشذوذ باستخدام عدد قليل جدًا من الصور الطبية الطبيعية. يدمج النموذج إشارات قابلة للتعلم، ومحولات، ومهام واقعية لتوليف الشذوذ في الصور الطبية.
تشغيل عبر الإنترنت:https://go.hyper.ai/3BnDy
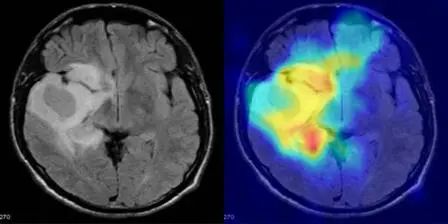
٦. نموذج إينياس: عرض توضيحي لترميم النقوش الرومانية القديمة
إينيس هي شبكة عصبية توليدية متعددة الوسائط، طورتها جوجل ديب مايند بالتعاون مع عدة جامعات. تُستخدم في ترميم النصوص، والإسناد الجغرافي، والإسناد الزمني للنقوش اللاتينية واليونانية القديمة. يُمثل إصدار هذا النموذج حقبة جديدة في علم النقوش الرقمية. فإمكاناته في مجالات مثل ترميم النصوص القديمة، والإسناد الجغرافي/الزمني، ودعم البحث التاريخي هائلة، ومن المتوقع أن يُسرّع الاكتشافات العلمية والتطبيقات متعددة التخصصات.
تشغيل عبر الإنترنت:https://go.hyper.ai/8ROfT

7. نشر Qwen3-Coder-30B-A3B-Instruct بنقرة واحدة
Qwen3-Coder-30B-A3B-Instruct هو نموذج لغوي ضخم طوّره مختبر تونغي وانكسيانغ التابع لشركة علي بابا. يُظهر أداءً متميزًا في النماذج المفتوحة للترميز بالوكالة، واستخدام متصفحات الوكيل، ومهام الترميز الأساسية الأخرى، ويمكنه التعامل بكفاءة مع مهام الترميز بلغات برمجة متعددة. بفضل فهمه السياقي القوي وقدراته المنطقية، يُعدّ خيارًا ممتازًا لتطوير المشاريع المعقدة وتحسين الأكواد البرمجية.
تشغيل عبر الإنترنت:https://go.hyper.ai/vYf3s
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

توصيات الورقة البحثية لهذا الأسبوع
1. تقرير فني عن Qwen-Image
حقق Qwen-Image، وهو نموذج أساسي لتوليد الصور ضمن عائلة Qwen، تقدمًا ملحوظًا في معالجة النصوص المعقدة وتحرير الصور بدقة. ولمواجهة تحديات معالجة النصوص المعقدة، صمم الباحثون مسارًا شاملًا لمعالجة البيانات يشمل جمع البيانات على نطاق واسع، والترشيح، والتعليق التوضيحي، والتوليف، والموازنة. يحقق النموذج أداءً متطورًا عبر معايير أداء متعددة، مما يُظهر قدراته القوية في مهام توليد الصور وتحريرها.
رابط الورقة:https://go.hyper.ai/HWjVM
2. انتشار البذور: نموذج لغة انتشار واسع النطاق مع استدلال عالي السرعة
تقترح هذه الورقة البحثية نموذجًا لغويًا واسع النطاق يعتمد على آلية انتشار حالة منفصلة تتميز بسرعة استدلال فائقة. بفضل آلية التوليد المتوازي غير التسلسلي، يُحسّن نموذج الانتشار المنفصل كفاءة الاستدلال بشكل ملحوظ، ويُخفف بفعالية من زمن الوصول المتأصل المرتبط بفك التشفير التقليدي لكل رمز على حدة.
رابط الورقة:https://go.hyper.ai/NvrNm
3. Cognitive Kernel-Pro: إطار عمل لتدريب وكلاء البحث العميق ونماذج أساس الوكلاء
يُنظر بشكل متزايد إلى وكلاء الذكاء الاصطناعي العامين كإطار عمل أساسي للجيل القادم من الذكاء الاصطناعي، إذ يُمكّنون من التفكير المعقد، والتفاعل الشبكي، والبرمجة، والبحث المستقل. في هذه الدراسة، يقترح الباحثون Cognitive Kernel-Pro، وهو إطار عمل وكلاء ذكيين متعدد الوحدات، مفتوح المصدر بالكامل ومجاني إلى حد كبير، ومُصمم لتسهيل تطوير وتقييم وكلاء الذكاء الاصطناعي المتقدمين.
رابط الورقة:https://go.hyper.ai/65j3v
4. ما وراء الثبات: إزالة الضوضاء ذات الطول المتغير لنماذج اللغات الكبيرة المنتشرة
في هذه الورقة البحثية، يقترح الباحثون استراتيجية جديدة لإزالة الضوضاء دون تدريب، تُسمى DAEDAL، تُمكّن من توسيع أطوال DLLMs ديناميكيًا وتكيفيًا. وتُظهر التجارب المكثفة على مجموعة متنوعة من DLLMs أن DAEDAL يُضاهي، بل ويتفوق في بعض الحالات، على أداء نماذج خط الأساس ذات الطول الثابت المُعدّلة بعناية، مع تحسين الكفاءة الحسابية بشكل ملحوظ وتحقيق نسبة رمزية فعّالة أعلى.
رابط الورقة:https://go.hyper.ai/p7WxK
5. Skywork UniPic: نمذجة الانحدار التلقائي الموحدة للفهم البصري والتوليد
تقدم هذه الورقة البحثية نموذج Skywork UniPic، وهو نموذج انحدار ذاتي بمليار ونصف معلمة، يوحد فهم الصور، وتوليد النصوص إلى صور، وتحريرها ضمن بنية واحدة، دون الاعتماد على محولات خاصة بمهام محددة أو موصلات بين الوحدات. بإثبات إمكانية تحقيق دمج متعدد الوسائط عالي الدقة دون تكاليف موارد باهظة، يُرسي Skywork UniPic نموذجًا عمليًا للذكاء الاصطناعي متعدد الوسائط عالي الدقة والقابل للنشر.
رابط الورقة:https://go.hyper.ai/FiVaf
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
اقترح فريق بحثي من جامعة نيفادا، لاس فيغاس، طريقة تحليل متعددة المتغيرات تُسمى ICA-Var، وتعتمد على تصميم عملية تعلم آلي غير مُشرف. تستخرج هذه الطريقة التباين المشترك وأنماط الطفرات المتغيرة مع مرور الوقت من بيانات مياه الصرف الصحي من خلال تحليل المكونات المستقلة، مما يُمكّن من الكشف المُبكر والأكثر دقة عن المتغيرات.
شاهد التقرير الكامل:https://go.hyper.ai/z1vVo
قام فريق Qwen بإصدار Qwen3-Coder-Flash مفتوح المصدر، ويتميز بأداء متفوق بين نماذج المصدر المفتوح في ترميز البروكسي، واستخدام متصفح البروكسي، ومهام الترميز الأساسية الأخرى. يمكنه التعامل بكفاءة مع مهام الترميز بلغات برمجة متعددة. وفي الوقت نفسه، تُمكّنه قدراته القوية على فهم السياق والاستدلال المنطقي من الأداء الجيد في تطوير المشاريع المعقدة وتحسين الأكواد البرمجية.
شاهد التقرير الكامل:https://go.hyper.ai/FmOep
لمعالجة مشكلة استهداف البروتينات غير المنظمة طبيعيًا، اقترح ديفيد بيكر وفريقه استراتيجية تصميم بروتين تُسمى "لوجوس"، تسمح للبروتينات بالارتباط بالمناطق غير المنظمة طبيعيًا في تشكيلات ممتدة متنوعة، مع إدخال سلاسل جانبية في جيوب الارتباط التكميلية. تستفيد هذه الدراسة من نموذج انتشار الترددات الراديوية (RFdiffusion) لإعادة تنظيم الجيوب وتعميمها على نطاق واسع من التسلسلات، مما يتيح التعرف الشامل على مناطق البروتين غير المنظمة بناءً على قالب ببتيد مُصمم لربط البروتين بالهدف.
شاهد التقرير الكامل:https://go.hyper.ai/F0lti
اقترح فريق تشو هاو البحثي في معهد الصناعات الذكية بجامعة تسينغهوا، بالتعاون مع مختبر الذكاء الاصطناعي في شنغهاي، نموذج أساس البروتين AMix-1 القائم على شبكات التدفق البايزية. ولأول مرة، استخدموا المنهجية المنهجية المتمثلة في قانون التوسع قبل التدريب، والقدرة الناشئة، والتعلم في السياق، والتوسع في وقت الاختبار لبناء نموذج أساس البروتين، مُدخلين بذلك النموذج الناجح لنماذج اللغات الكبيرة في تصميم البروتينات. وقد تم التحقق من كفاءتها وتعدد استخداماتها من خلال التوسع في وقت الاختبار والتجارب الواقعية.
شاهد التقرير الكامل:https://go.hyper.ai/X9iMe
أصدرت OpenAI رسميًا نظام GPT-5، مما يُحسّن أداءه في أكثر ثلاث حالات استخدام شيوعًا لـ ChatGPT: الكتابة، والبرمجة، والصحة. GPT-5 هو نظام موحد يتكون من نموذج ذكي وفعال للإجابة على معظم الأسئلة (GPT-5-main)، ونموذج استدلال عميق للمشكلات الأكثر تعقيدًا (GPT-5-thinking)، وموجه آني يُحدد بسرعة النموذج المُستخدم بناءً على نوع المحادثة، وتعقيد السؤال، والأدوات المطلوبة، ونية المستخدم الصريحة.
شاهد التقرير الكامل:https://go.hyper.ai/gFHQg
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:https://go.hyper.ai/wiki
الموعد النهائي للقمة في أغسطس
21 أغسطس 11:59:59 أسبلوس 2026
27 أغسطس 7:59:59 ندوة أمن USENIX 2025
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








