Command Palette
Search for a command to run...
بعد قراءة ورقة DALL-E، وجدنا أن مجموعات البيانات الكبيرة تحتوي أيضًا على إصدارات بديلة

لقد ظهر نموذج DALL-E الجديد لفريق OpenAI في كل مكان على الشاشة. يستخدم هذا النوع الجديد من الشبكات العصبية 12 مليار معلمة وتم "تدريبها بشكل خاص". يمكنه إنشاء صور مقابلة بعد إدخال أي نص وصفي. الآن، قام الفريق بإتاحة مصدر ورقة المشروع وبعض أكواد الوحدة مفتوحة المصدر، مما يسمح لنا بفهم المبادئ وراء هذه التحفة الفنية.
في بداية العام، أصدرت OpenAI نموذج توليد الصور DALL-E، والذي كسر تمامًا الجدار الأبعادي بين اللغة الطبيعية والصور.
بغض النظر عن مدى المبالغة أو عدم واقعية وصف النص، بمجرد إدخاله في DALL-E، يمكنه إنشاء صورة مقابلة، وقد أذهل التأثير دائرة التكنولوجيا بأكملها.

الجهد الكبير يجلب المعجزات: سقف التكلفة لصناعة الخيمياء
قوة الحوسبة: 1024 كتلة V 100
عندما خرج النموذج، تكهن المطورون حول عملية التنفيذ وراء النموذج وتطلعوا إلى الورقة الرسمية. في الآونة الأخيرة، تم نشر ورقة DALL-E وبعض أكواد التنفيذ أخيرًا:

عنوان الورقة: https://arxiv.org/abs/2102.12092
كما كان متوقعًا، أثبتت OpenAI مرة أخرى قوتها المالية القوية، كما توقع بعض المطورين من قبل.وكشفت الورقة البحثية أنهم استخدموا إجمالي 1024 وحدة معالجة رسومية NVIDIA V100 بسعة 16 جيجابايت طوال التدريب.
أما بالنسبة للكود، فإن الإصدار الرسمي حاليًا يفتح وحدة dVAE فقط لإعادة بناء الصورة.الغرض من هذه الوحدة هو تقليل استخدام الذاكرة للمحول المدرب في مهمة إنشاء النص والصورة. لم يتم الإعلان عن جزء كود المحول بعد، لذا لا يمكننا إلا أن نتطلع إلى التحديثات اللاحقة. ومع ذلك، حتى مع وجود الكود، ليس كل شخص قادرًا على إعادة إنتاج استخدام وحدة معالجة الرسوميات هذه.
مجموعة البيانات: 250 مليون زوج من الصور والنصوص + 12 مليار معلمة
وفي الورقة البحثية، أوضح فريق OpenAI أن البحث في استخدام أساليب توليف التعلم الآلي لتحقيق تحويل النص إلى صورة بدأ في عام 2015.
ومع ذلك، على الرغم من أن النماذج المقترحة في هذه الدراسات السابقة كانت قادرة على إجراء توليد النص إلى صورة، إلا أن نتائج توليدها لا تزال تعاني من العديد من المشاكل، مثل تشوه الكائن، أو وضع الكائن بشكل غير معقول، أو الاختلاط غير الطبيعي بين عناصر المقدمة والخلفية.

وبعد البحث، وجد الفريق أن الدراسات السابقة كانت تُقيّم عادةً على مجموعات بيانات أصغر (مثل MS-COCO وCUB-200). وبناء على ذلك اقترح الفريق الفكرة التالية:هل من الممكن أن يكون حجم مجموعة البيانات وحجم النموذج من العوامل المحددة للطرق الحالية؟
لذلك استخدم الفريق هذا الأمر كاختراقتم جمع مجموعة بيانات مكونة من 250 مليون زوج من الصور والنصوص من الإنترنت،يتم تدريب محول الانحدار التلقائي الذي يحتوي على 12 مليار معلمة على مجموعة البيانات هذه.
بالإضافة إلى ذلك، تقدم الورقة أن تدريب نموذج dVAE يستخدم 64 وحدة معالجة رسومية NVIDIA V100 بسعة 16 جيجابايت،النموذج التمييزي الذي يستخدمه CLIP تم تدريب 256 وحدة معالجة رسومية لمدة 14 سماء.
وبعد تدريب مكثف، تمكن الفريق أخيرًا من الحصول على DALL-E، وهو نموذج مرن وواقعي لتوليد الصور يمكن التحكم فيه باستخدام اللغة الطبيعية.
قام الفريق بمقارنة وتقييم النتائج التي تم إنشاؤها بواسطة نموذج DALL-E مع تلك التي تم إنشاؤها بواسطة نماذج أخرى. وكانت النتائج:وفي حالة 90%، كانت النتائج الناتجة عن DALL-E أكثر ملاءمة من تلك التي تم التوصل إليها في الدراسات السابقة.

مجموعة بيانات الصورة والنص عبارة عن بديل مسطح، جيد حقًا
ويثبت نجاح نموذج DALL-E أيضًا أهمية بيانات التدريب واسعة النطاق للنموذج.
قد يكون من الصعب على الكيميائيين العاديين الحصول على نفس مجموعة البيانات مثل DALL-E، ولكن العلامات التجارية الكبرى كلها لديها إصدارات بديلة (إصدارات بديلة بأسعار معقولة).
على الرغم من أن شركة OpenAI صرحت بأن مجموعة بيانات التدريب الخاصة بها لن يتم نشرها للعامة بعد،لكنهم كشفوا أن مجموعة البيانات تتضمن مجموعة بيانات العناوين المفاهيمية التي نشرتها جوجل.
مجموعة بيانات نصية مصورة كبيرة الحجم بديلة مصغرة
تم اقتراح مجموعة بيانات التسميات التوضيحية المفاهيمية بواسطة Google في الورقة البحثية "التسميات التوضيحية المفاهيمية: مجموعة بيانات نصية بديلة مُنظفة ومُسمّاة بشكل مفرط للتسميات التوضيحية التلقائية للصور" المنشورة في ACL 2018.

تساهم هذه الورقة في تصنيف البيانات والنمذجة. أولاً،واقترح الفريق مجموعة بيانات جديدة لتعليقات الصور، تسمى "التسميات التوضيحية المفاهيمية"، والتي تحتوي على عدد من الصور أكبر بكثير من مجموعة بيانات MS-COCO، بما في ذلك ما مجموعه حوالي 3.3 مليون زوج من الصور والوصف.
التسميات التوضيحية المفاهيمية(العنوان المفاهيمي) تفاصيل مجموعة البيانات
مصدر البيانات:جوجل الذكاء الاصطناعي
وقت الإصدار:2018
الكمية المتضمنة:3.3 مليون زوج من الصور والنصوص
تنسيق البيانات:.tsv حجم البيانات:1.7 جيجابايت
عنوان التنزيل:https://orion.hyper.ai/datasets/14682
استخدام ResNet+RNN+Transformer لبناء DALL-E عكسي
من حيث النمذجة، واستنادا إلى نتائج البحوث السابقة،استخدم الفريق Inception-ResNet-v2 لاستخراج ميزات الصورة، ثم استخدم نموذجًا يعتمد على RNN وTransformer لتوليد تعليقات توضيحية للصور (DALL-E يولد صورًا من أوصاف نصية، ويقوم Conceptual Captions بتوليد تعليقات توضيحية نصية من الصور).
لتوليد مجموعة البيانات، بدأ الفريق بخط أنابيب Flume الذي عالج حوالي مليار صفحة ويب بالتوازي، واستخراج وتصفية ومعالجة أزواج الصور والتعليقات التوضيحية المرشحة من تلك الصفحات، والاحتفاظ بتلك التي مرت بالعديد من المرشحات.
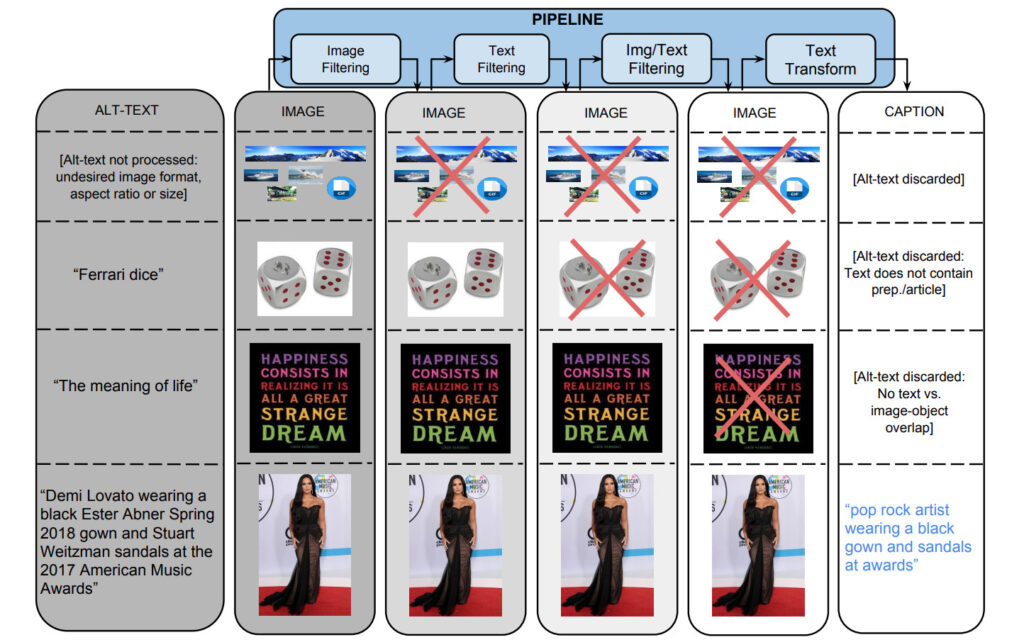
1: التصفية القائمة على الصور
تقوم الخوارزميات بتصفية الصور استنادًا إلى تنسيق الترميز والحجم ونسبة العرض إلى الارتفاع والمحتوى غير المقبول. إنه يحفظ فقط صور JPEG التي يزيد حجمها عن 400 بكسل في كلا البعدين، حيث لا تتجاوز نسبة أبعاد الحجم 2. ويستبعد الصور التي تؤدي إلى اكتشاف المواد الإباحية أو البذيئة. في النهاية، قامت هذه المرشحات باستبعاد أكثر من بيانات المرشح 65%.
2. التصفية النصية
تحصل الخوارزمية على نص وصفي (نص بديل) من صفحات الويب HTML، وتزيل العناوين التي تحتوي على نص غير وصفي (مثل علامات تحسين محركات البحث أو علامات التصنيف)، وتصفي التعليقات التوضيحية بناءً على مؤشرات محددة مسبقًا مثل تلك التي تحتوي على مواد إباحية، أو كلمات بذيئة، أو ألفاظ نابية، أو صور شخصية، وما إلى ذلك. وأخيرًا، اجتازت 3% فقط نصوص المرشحين عملية الفحص.
بالإضافة إلى التصفية المنفصلة استنادًا إلى محتوى الصورة والنص، يتم أيضًا تصفية البيانات حيث لا يمكن تعيين أي من علامات النص لمحتوى الصورة.
قم بتعيين تسميات الفئات للصور باستخدام المصنفات المقدمة من خلال واجهات برمجة تطبيقات Google Cloud Vision.
3. تحويل النصوص والترجمة المعجمية
أثناء عملية جمع مجموعة البيانات، تمت معالجة أكثر من 5 مليارات صورة من حوالي مليار صفحة ويب باللغة الإنجليزية. وبموجب معيار التصفية عالي الدقة، نجح 0.2% فقط من أزواج الصور والعناوين في اجتياز الفحص، وغالبًا ما تم استبعاد العناوين المتبقية لأنها تحتوي على أسماء علم (أشخاص، أماكن، مواقع، وما إلى ذلك).
قام المؤلفون بتدريب نموذج الترجمة الفرعية المستند إلى RNN على بيانات النص البديل غير المتزامنة ويقدمون مثالاً للإخراج في الشكل أدناه.

وصف مخرجات النموذج: المغني جاستن بيبر يؤدي في حفل توزيع جوائز بيلبورد الموسيقية في MGM
باستخدام واجهة برمجة تطبيقات Google Cloud Natural Language، حصل الفريق على تعليقات توضيحية للكيانات المسماة والاعتماد النحوي. بعد ذلك، يتم استخدام واجهة برمجة تطبيقات البحث في Google Knowledge Graph (KG) لمطابقة الكيانات المسماة مع إدخالات KG واستغلال مصطلحات التشعبات ذات الصلة.
على سبيل المثال، تم تحديد كل من "Harrison Ford" و"Calista Flockhart" ككيانات مسماة، وبالتالي يتم مطابقتهما مع إدخالات KG المقابلة. تحتوي إدخالات KG هذه على "فاعل" كرابط لها، ثم تحل محل رموز السطح الأصلية بهذا الاقتران.
تقييم النتائج
قام الفريق بأخذ مجموعة الاختبار من مجموعة البيانات وتم استخراج عينة مكونة من 4000 مثال بشكل عشوائي وتقييمها يدويًا. من بين التعليقات الثلاثة، حصلت التعليقات أعلاه 90% على معظم التقييمات الجيدة.
قام الفريق بمقارنة الاختلافات بين النموذج المدرب على COCO والنموذج المدرب على Conceptual.
في،الفرق الأول هو أن نتائج التدريب المبنية على المفاهيم أكثر اجتماعية من نتائج تدريب COCO المبنية على الصور الطبيعية.
على سبيل المثال، في الصورة الموجودة في أقصى اليسار أدناه، يستخدم النموذج المدرب على COCO مصطلح "مجموعة من الرجال" للإشارة إلى الأشخاص الموجودين في الصورة، بينما يستخدم النموذج المدرب على المفاهيم المصطلح الأكثر ملاءمة والأكثر إفادة "الخريجين".

الفرق الثاني هو أن النماذج المدربة على COCO غالبًا ما تبدو وكأنها "ترتبط من تلقاء نفسها" و"تصنع" بعض الأوصاف من الهواء.على سبيل المثال، كان لديه هلوسة كونه "أمام مبنى" في الصورة الأولى؛ الوهم بأنه "ساعة وبابين" للصورة الثانية؛ والهلوسة بأنها "كعكة عيد ميلاد" للصورة الثالثة. وعلى النقيض من ذلك، لم يجد نموذج الفريق هذه المشكلة.
الفرق الثالث هو أنواع الصور التي يمكن استخدامها.نظرًا لأن COCO يحتوي فقط على صور طبيعية، فإن صور الرسوم المتحركة مثل الصورة الرابعة في الشكل أعلاه سوف تتسبب في حدوث تداخل "ترابطي" في نموذج COCO المدرب، مثل "لعبة محشوة"، و"سمكة"، و"جانب السيارة" وأشياء أخرى غير موجودة. وعلى النقيض من ذلك، فإن النموذج المدرب مفاهيميًا قادر على التعامل مع هذه الصور بسهولة.
كما أن إطلاق نموذج DALL-E جعل العديد من الباحثين في هذا المجال يتنهدون: فالبيانات هي في الواقع حجر الزاوية في الذكاء الاصطناعي. هل تريد أيضًا أن تحاول تحقيق المعجزات بقوة كبيرة؟ لنبدأ بمجموعة بيانات العناوين المفاهيمية!
وصول https://orion.hyper.ai/datasets أو انقراقرأ المقال الأصلي، واحصل على المزيد من مجموعات البيانات!
مصدر الخبر:
https://openai.com/blog/dall-e/
عنوان ورقة DALL-E:
https://arxiv.org/abs/2102.12092
عنوان مشروع DALL-E على GitHub:
https://github.com/openai/dall-e
عنوان ورقة العناوين المفاهيمية:








