Command Palette
Search for a command to run...
الخبرة العملية | ممارسة تحسين أداء المشغلين على مستوى العناصر باستخدام منصة الحوسبة السحابية HyperAI
تم إطلاق منصة الحوسبة HyperAI رسميًا، مما يوفر للمطورين خدمات حوسبة مستقرة للغاية ويسرع من تحقيق أفكارهم من خلال بيئة جاهزة للاستخدام، وأسعار فعالة من حيث التكلفة لوحدات معالجة الرسومات، وموارد وفيرة في الموقع.
فيما يلي مشاركة لتجارب مستخدمي HyperAI في تحسين عوامل التشغيل Elementwise بناءً على المنصة ⬇️
إعلان سريع عن حدث ما!
لا يزال برنامج اختبار النسخة التجريبية من HyperAI يستقبل طلبات التوظيف، مع حافز أقصى قدره $200. انقر لمعرفة المزيد عن البرنامج:يمكن الحصول على ما يصل إلى $200! التسجيل في برنامج الاختبار التجريبي لـ HyperAI مفتوح الآن رسميًا!
الهدف الأساسي:تحسين عامل الجمع البسيط على مستوى العناصر (C = A + B) من تنفيذه الأساسي للوصول إلى الأداء الأصلي لـ PyTorch (أي الوصول إلى حد عرض النطاق الترددي للذاكرة للأجهزة).
التحديات الرئيسية:يُعدّ عامل التشغيل Elementwise عاملاً نموذجياً مرتبطاً بالذاكرة.
- لا تمثل قوة الحوسبة عنق الزجاجة (تقوم وحدات معالجة الرسومات بإجراء عمليات الجمع بسرعة فائقة).
- تكمن المشكلة في توازن العرض والطلب بين "طرف إصدار التعليمات" و "طرف نقل ذاكرة الفيديو".
- جوهر التحسين هو نقل أكبر قدر من البيانات (بايت) بأقل عدد من التعليمات.
تهيئة البيئة التجريبية وقوة الحوسبة
يُؤدي تحسين مُعامل Elementwise إلى تجاوز الحدود المادية لعرض نطاق ذاكرة وحدة معالجة الرسومات (GPU). وللحصول على أدق بيانات قياس الأداء، أُجريت هذه التجربة العملية على منصة الحوسبة السحابية HyperAI (hyper.ai). وقد اخترتُ تحديدًا جهازًا عالي المواصفات لتحقيق أقصى استفادة من أداء المُعامل.
- وحدة معالجة الرسومات: NVIDIA RTX 5090 (32GB VRAM)
- كبش: 40 جيجابايت
- بيئة: PyTorch 2.8 / CUDA 12.8
وقت إضافي: إذا كنت ترغب أيضًا في تجربة RTX 5090 وإعادة إنتاج الكود الموجود في هذه المقالة، فيمكنك استخدام رمز الاسترداد الحصري الخاص بي "EARLY_dnbyl" عند التسجيل في app.hyper.ai للحصول على ساعة واحدة من قوة الحوسبة 5090 مجانًا (صالحة لمدة شهر واحد).
قم بتشغيل نسخة RTX 5090 بسرعة
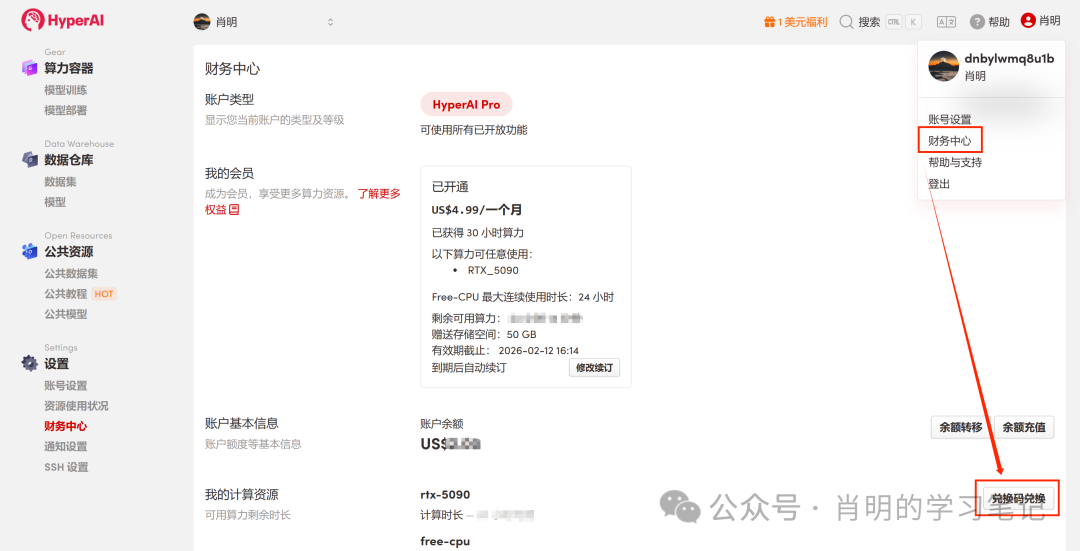
1. التسجيل وتسجيل الدخول: بعد تسجيل حساب على app.hyper.ai، انقر فوق "المركز المالي" في الزاوية اليمنى العليا، ثم انقر فوق "استرداد الرمز" وأدخل "EARLY_dnbyl" للحصول على قوة حوسبة مجانية.
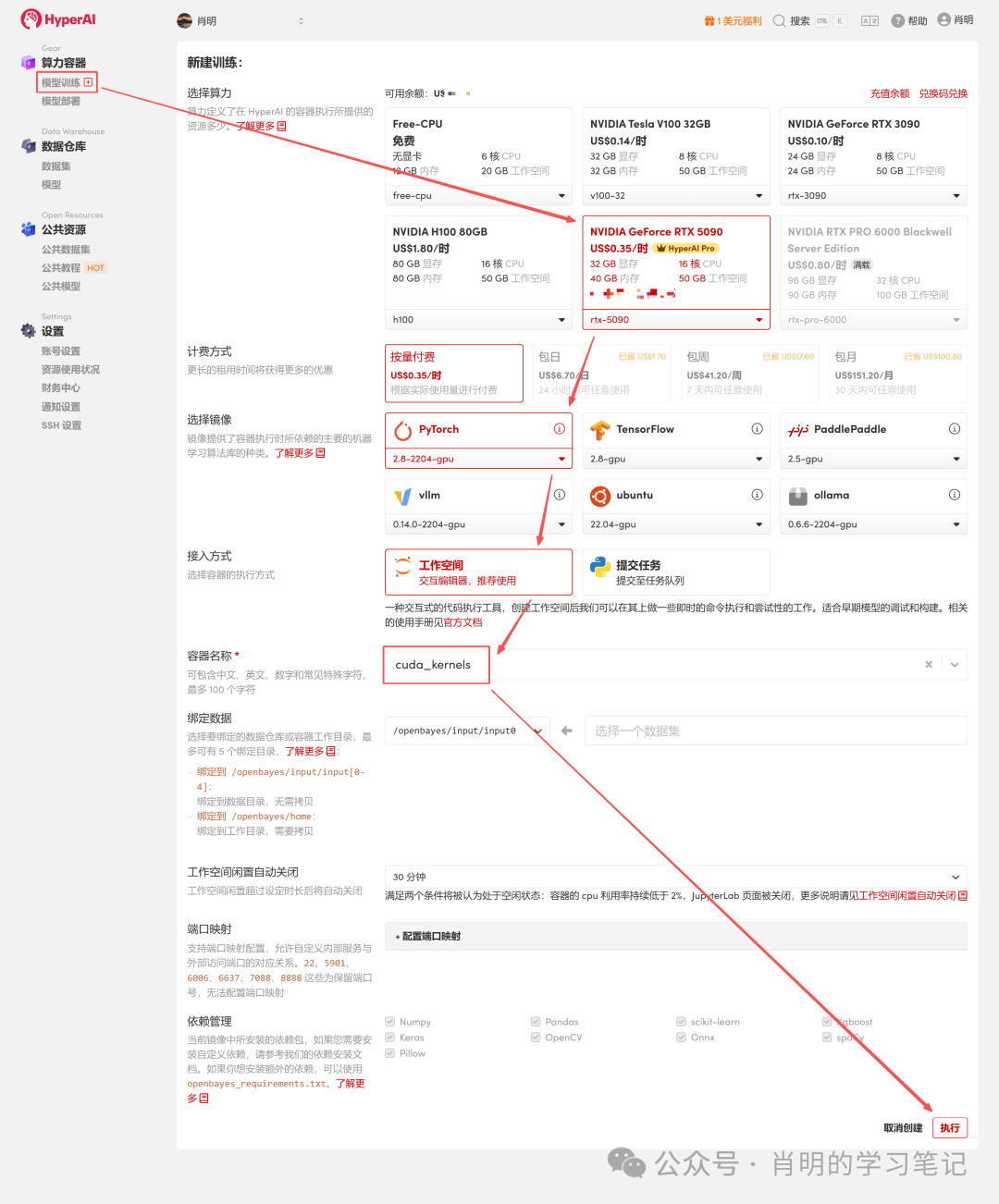
2. إنشاء حاوية: انقر فوق "تدريب النموذج" في الشريط الجانبي الأيسر -> "تحديد قوة الحوسبة: 5090" -> "تحديد الصورة: PyTorch 2.8" -> "طريقة الوصول: Jupyter" -> "اسم الحاوية: أدخل أي شيء، مثل cuda_kernels" -> "تنفيذ".
3. افتح Jupyter: بعد بدء تشغيل المثيل (يتغير حالته إلى "قيد التشغيل")، ما عليك سوى النقر فوق "فتح مساحة العمل" لاستخدامه على الفور.
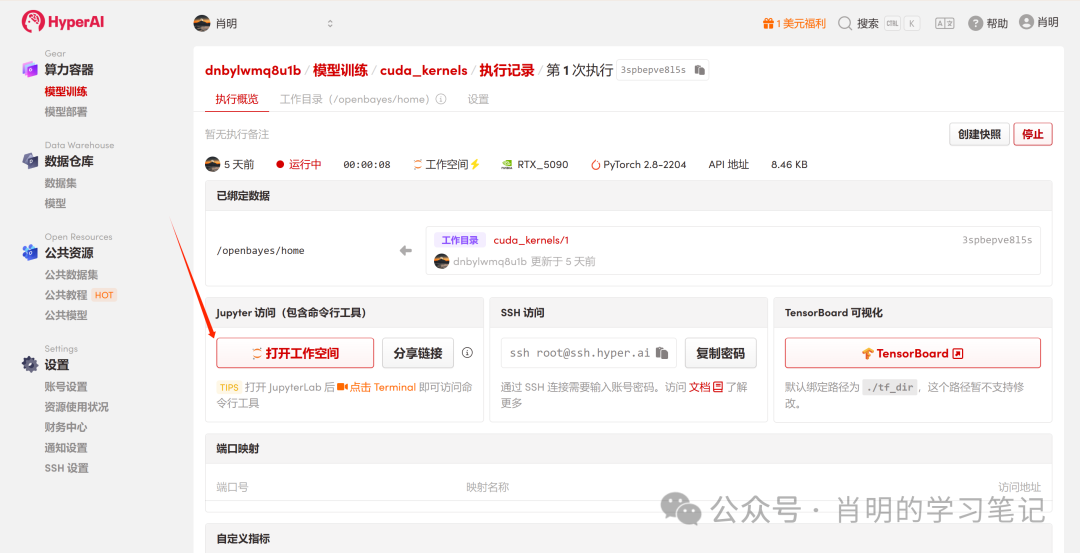
تدعم المنصة الاتصال باستخدام Jupyter أو VS Code SSH Remote. أنا أستخدم Jupyter، وقمت بتشغيل الأمر التالي في الخلية الأولى:
import os
import torch
from torch.utils.cpp_extension import loadالمرحلة الأولى: سلسلة تحسين FP32
الإصدار 1: FP32 الأساسي (الإصدار القياسي)
هذه هي الطريقة الأكثر بديهية لكتابتها، لكنها متوسطة فقط من حيث الكفاءة من منظور وحدة معالجة الرسومات.
تحليل معمق للمبادئ:
- طبقة القيادة:يقوم المجدول بإصدار تعليمة واحدة من نوع LD.E (تحميل 32 بت).
- طبقة التنفيذ (الالتفاف)وفقًا لمبدأ SIMT، تقوم جميع الخيوط الـ 32 في Warp بتنفيذ هذه التعليمات في وقت واحد.
- حجم البيانات:ينقل كل خيط 4 بايتات. إجمالي حجم البيانات =32 خيطًا × 4 بايت = 128 بايت .
- عمليات الذاكرة:تقوم وحدة التحميل والتخزين (LSU) بدمج هذه البايتات الـ 128 في معاملة واحدة لذاكرة الفيديو.
- تحليل الاختناقات:على الرغم من استخدام دمج الذاكرة، إلا أن كفاءة تنفيذ التعليمات منخفضة. لنقل 128 بايت من البيانات، يجب على المعالج المتعدد المتدفق (SM) استهلاك دورة إصدار تعليمات واحدة. عند التعامل مع كميات هائلة من البيانات، يصبح معالج إصدار التعليمات مثقلاً بالأعباء ويتحول إلى عنق زجاجة.
شفرة (v1_f32.cu):
%%writefile v1_f32.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
__global__ void elementwise_add_f32_kernel(float *a, float *b, float *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = a[idx] + b[idx];
}
}
void elementwise_add_f32(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f32_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32, "FP32 Add");
}الإصدار 2: مُحوَّل إلى متجه FP32x4
طريقة التحسين: استخدم نوع float4 لفرض توليد تعليمات تحميل 128 بت.
تحليل معمق للمبادئ (نقاط التحسين الأساسية):
- طبقة القيادة:يقوم المجدول بإصدار تعليمة واحدة من نوع LD.E.128 (تحميل 128 بت).
- طبقة التنفيذ (الالتفاف):تحتوي الشبكة على 32 خيطًا تعمل في وقت واحد، ولكن هذه المرة يقوم كل خيط بنقل 16 بايت (float4).
- حجم البيانات:إجمالي حجم البيانات = 32 خيطًا × 16 بايت = 512 بايت.
- عمليات الذاكرة:عندما ترى وحدة معالجة الرسومات (LSU) طلبًا مستمرًا بحجم 512 بايت، فإنها ستبدأ أربع عمليات نقل متتالية لذاكرة الفيديو بحجم 128 بايت.
- مقارنة الكفاءة:في الوضع الأساسي: تعليمة واحدة = 128 بايت. في الوضع المتجهي: تعليمة واحدة = 512 بايت.
- ختاماً:تتحسن كفاءة التدريس بمقدار 4 أضعاف. لا يتطلب نظام SM سوى ربع عدد التعليمات الأصلية للاستفادة الكاملة من نفس عرض نطاق الذاكرة. وهذا يحرر وحدة إرسال التعليمات تمامًا، مما يحول عنق الزجاجة إلى عرض نطاق الذاكرة.
شفرة (v2_f32x4.cu):
%%writefile v2_f32x4.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
#define FLOAT4(value) (reinterpret_cast<float4 *>(&(value))[0])
__global__ void elementwise_add_f32x4_kernel(float *a, float *b, float *c, int N) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int idx = 4 * tid;
if (idx + 3 < N) {
float4 reg_a = FLOAT4(a[idx]);
float4 reg_b = FLOAT4(b[idx]);
float4 reg_c;
reg_c.x = reg_a.x + reg_b.x;
reg_c.y = reg_a.y + reg_b.y;
reg_c.z = reg_a.z + reg_b.z;
reg_c.w = reg_a.w + reg_b.w;
FLOAT4(c[idx]) = reg_c;
}
else if (idx < N){
for (int i = 0; i < 4; i++){
if (idx + i < N) {
c[idx + i] = a[idx + i] + b[idx + i];
}
}
}
}
void elementwise_add_f32x4(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 4;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f32x4_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32x4, "FP32x4 Add");المرحلة الثانية: سلسلة تحسين FP16
3. الإصدار 3: خط الأساس FP16 (عدد قياسي بنصف الدقة)
استخدم نصف (FP16) لتوفير ذاكرة الفيديو.
تحليل معمق للمبادئ الأساسية (لماذا هو بطيء للغاية؟):
- وضع الوصول إلى الذاكرة:في الكود، يكون الفهرس متسلسلاً، لذا يتم دمج الوصول بواسطة 32 خيطًا بشكل كامل.
- حجم البيانات:32 خيطًا × 2 بايت = 64 بايت (إجمالي الطلبات لحزمة واحدة).
- سلوك الأجهزة:يقوم متحكم الذاكرة (LSU) بإنشاء عمليتي نقل بيانات لقطاعات الذاكرة، كل منهما بحجم 32 بايت. ملاحظة: لا يتم إهدار أي عرض نطاق هنا؛ جميع البيانات المرسلة صالحة.
العائق الحقيقي:
1. التعليمات المرفقة:
هذا هو السبب الرئيسي. فمن أجل ملء عرض نطاق ذاكرة الفيديو، نحتاج إلى نقل البيانات باستمرار.في هذا الإصدار، لا يمكن للتعليمات الواحدة نقل سوى 64 بايت.بالمقارنة مع إصدار float4 (الذي ينقل 512 بايت لكل تعليمة)، فإن كفاءة التعليمات في هذا الإصدار هي 1/8 فقط.
نتيجة لـحتى عندما يعمل مُوزِّع التعليمات في وحدة المعالجة المتعددة بأقصى سرعة، فإن كمية البيانات التي تحملها التعليمات الصادرة لا تستطيع الاستفادة الكاملة من عرض النطاق الترددي الهائل لذاكرة الفيديو. الأمر أشبه برئيس العمال الذي يصرخ بصوت عالٍ (يصدر التعليمات)، لكن العمال لا يزالون غير قادرين على نقل ما يكفي من الطوب (البيانات).
2. دقة عمليات نقل البيانات في الذاكرة صغيرة جدًا:
* الطبقة المادية:أصغر وحدة لنقل ذاكرة الفيديو هي قطاع 32 بايت؛ تتم إدارة طبقات ذاكرة التخزين المؤقت عادةً بوحدات من خطوط ذاكرة التخزين المؤقت 128 بايت.
* الوضع الراهن:على الرغم من أن البيانات التي طلبها Warp بحجم 64 بايت ملأت قطاعين، إلا أنها استخدمت نصف خط ذاكرة التخزين المؤقت البالغ 128 بايت فقط.
* نتيجة لـ:يُعدّ نقل البيانات هذا، الذي يُشبه أسلوب البيع بالتجزئة، على شكل حزم صغيرة، غير فعّال للغاية عند هذا المعدل مقارنةً بنقل البيانات "الجملة" لأربعة أسطر ذاكرة تخزين مؤقت كاملة (512 بايت) دفعةً واحدة، كما هو الحال مع نوع البيانات float4، ولا يُمكنه إخفاء زمن الاستجابة العالي لذاكرة الفيديو. ولاستغلال عرض نطاق ذاكرة الفيديو بالكامل، نحتاج إلى نقل البيانات بشكل مستمر.
شفرة (v3_f16.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) { int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>( reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}4. الإصدار 4: FP16 المتجه (النصف 2)
أدخل النصف الثاني.
تحليل معمق للمبادئ:
- بيانات:half2 (4 بايت).
- طبقة الأوامر:أصدر أمر تحميل 32 بت.
- طبقة الحوسبة:باستخدام __hadd2 (SIMD)، يمكن لتعليمات واحدة أن تقوم بعمليتي جمع في وقت واحد.
- الوضع الراهن:كفاءة الوصول إلى الذاكرة تعادل خط الأساس FP32(التعليمات الواحدة = 128 بايت). على الرغم من أنها أسرع من الإصدار الثالث، إلا أنها لا تزال لا تصل إلى ذروة 512 بايت/التعليمات في عدد الفاصلة العائمة من النوع الرابع.
شفرة (v4_f16x2.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}انظر الملحق للاطلاع على مثال لتشغيل برنامج هايبر جوبيتر.
5. الإصدار 5: FP16x8 فك اللفائف (فك اللفائف يدويًا)
لمزيد من استكشاف الأداء، حاولنا جعل خيط واحد يتعامل مع ثمانية أنصاف (أي أربعة أنصاف 2).
تحليل معمق للمبادئ الأساسية (أين تكمن التحسينات مقارنة بالإصدار الرابع؟):
- يمارس:اكتب يدويًا أربعة أسطر متتالية من عمليات قراءة half2 في الكود.
- تأثير:سيقوم المجدول بإصدار أربعة أوامر تحميل 32 بت على التوالي.
- دخل:ILP (التوازي على مستوى التعليمات) وإخفاء زمن الاستجابة. مشاكل مع الإصدار الرابع (FP16x2):إصدار تعليمة واحدة -> انتظار عودة البيانات (توقف) -> إجراء العملية الحسابية. خلال فترة الانتظار، لا يقوم معالج الرسوميات بأي شيء. التحسينات في الإصدار الخامس:يُصدر المعالج أربع تعليمات متتالية بسرعة. وبينما لا يزال ينتظر عودة البيانات الأولى من الذاكرة، يكون قد أصدر بالفعل التعليمات الثانية والثالثة والرابعة. هذا يُتيح الاستفادة الكاملة من الفجوات في مسار التعليمات، مُخفيًا بذلك زمن استجابة الذاكرة المُكلف.
- القيود:لا تزال كثافة التعليمات عالية جدًا.على الرغم من استخدام بروتوكول ILP، إلا أنه في جوهره كان يُفعّل أربع عمليات نقل بيانات (عربة) بحجم 32 بت. لنقل 128 بت من البيانات، استهلكت وحدة المعالجة المتعددة (SM) أربع دورات لإصدار التعليمات. وظل مُصدر التعليمات مشغولاً للغاية، مما حال دون تحقيق النتيجة المرجوة.
شفرة (v5_f16x8.cu):
%%writefile v5_f16x8.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
if (idx + 7 < N) {
half2 ra0 = HALF2(a[idx + 0]);
half2 ra1 = HALF2(a[idx + 2]);
half2 ra2 = HALF2(a[idx + 4]);
half2 ra3 = HALF2(a[idx + 6]);
half2 rb0 = HALF2(b[idx + 0]);
half2 rb1 = HALF2(b[idx + 2]);
half2 rb2 = HALF2(b[idx + 4]);
half2 rb3 = HALF2(b[idx + 6]);
HALF2(c[idx + 0]) = __hadd2(ra0, rb0);
HALF2(c[idx + 2]) = __hadd2(ra1, rb1);
HALF2(c[idx + 4]) = __hadd2(ra2, rb2);
HALF2(c[idx + 6]) = __hadd2(ra3, rb3);
}
else if (idx < N) {
for(int i = 0; i < 8; i++){
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8, "FP16x8 Add");
}انظر الملحق للاطلاع على مثال لتشغيل برنامج هايبر جوبيتر.
الإصدار 6: حزمة FP16x8 (التحسين الأمثل)
هذا هو الحد الأقصى لتحسين عامل التشغيل على مستوى العنصر. نجمع بين "نقل النطاق الترددي العالي" للإصدار الثاني و"التوازي على مستوى التعليمات" للإصدار الخامس، ونقدم تقنية التخزين المؤقت للسجلات.
تحليل معمق للسحر الأساسي:
1. انتحال العناوين:
* سؤال:بياناتنا من النوع half، ووحدة معالجة الرسومات (GPU) لا تحتوي على تعليمة load_8_halfs أصلية.
* التدابير المضادة: يشغل نوع float4 بالضبط 128 بت (16 بايت)، كما تشغل 8 أنصاف 128 بت.
* تشغيل:نقوم بتحويل عنوان نصف المصفوفة قسراً (reinterpret_cast) إلى float4*.
* تأثير:عندما يرى المترجم `float4*`، فإنه سيقوم بإنشاء سطر واحد. LD.E.128 التعليمات. لا يهم وحدة التحكم في ذاكرة الفيديو ما تقوم بنقله؛ فهي تنقل فقط تدفقات ثنائية 128 بت في كل مرة.
2. سجل المصفوفة:
half pack_a[8]: على الرغم من تعريف هذه المصفوفة في نواة النظام، إلا أنها ذات حجم ثابت وصغير جدًا، لذا يقوم المترجم بربطها مباشرةً بملف سجلات وحدة معالجة الرسومات بدلاً من الذاكرة المحلية البطيئة. وهذا يُعادل فتح ذاكرة تخزين مؤقتة عالية السرعة "متاحة".
3. إعادة تفسير الذاكرة:
تعريف الماكرو LDST128BITS:هذا هو جوهر الكود. فهو يحول عنوان أي متغير إلى نوع float4* ويسترجع قيمته.
LDST128BITS(pack_a[0])=LDST128BITS(a[idx]);
* الجانب الأيمن:انتقل إلى الذاكرة العامة a[idx] واسترجع 128 بت من البيانات.
* غادراكتب هذه البيانات ذات 128 بت مباشرة في مصفوفة pack_a (بدءًا من العنصر 0، وملء جميع العناصر الثمانية على الفور).
* نتيجة:تُكمل تعليمات واحدة على الفور نقل 8 عناصر بيانات.
شفرة (v6_f16x8_pack.cu):
%%writefile v6_f16x8_pack.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define LDST128BITS(value) (reinterpret_cast<float4 *>(&(value))[0])
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_pack_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
half pack_a[8], pack_b[8], pack_c[8];
if ((idx + 7) < N) {
LDST128BITS(pack_a[0]) = LDST128BITS(a[idx]);
LDST128BITS(pack_b[0]) = LDST128BITS(b[idx]);
#pragma unroll
for (int i = 0; i < 8; i += 2) {
HALF2(pack_c[i]) = __hadd2(HALF2(pack_a[i]), HALF2(pack_b[i]));
}
LDST128BITS(c[idx]) = LDST128BITS(pack_c[0]);
}
else if (idx < N) {
for (int i = 0; i < 8; i++) {
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8_pack(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_pack_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8_pack, "FP16x8 Pack Add");
}المرحلة الثالثة: دمج المعايير والتحليل المرئي
لتقييم تأثير التحسين بشكل شامل، قمنا بتصميم خطة اختبار سيناريوهات كاملة تغطي سيناريوهات حساسة لزمن الاستجابة (بيانات صغيرة) إلى سيناريوهات حساسة لعرض النطاق الترددي (بيانات ضخمة).
1. تصميم استراتيجية الاختبار
اخترنا ثلاث مجموعات بيانات تمثيلية، كل منها يتوافق مع اختناقات مختلفة على مستوى ذاكرة وحدة معالجة الرسومات:
- زمن استجابة ذاكرة التخزين المؤقت (مليون عنصر):حجم البيانات صغير للغاية (4 ميجابايت)، وذاكرة التخزين المؤقت L2 ممتلئة بالكامل.جوهر الاختبار هو الحمل الزائد لتشغيل النواة وكفاءة إصدار الأوامر.
- معدل نقل البيانات من الطبقة الثانية (16 مليون عنصر):حجم البيانات متوسط (64 ميجابايت)، وهو قريب من الحد الأقصى لسعة ذاكرة التخزين المؤقت L2.جوهر الاختبار هو معدل نقل البيانات للقراءة والكتابة في ذاكرة التخزين المؤقت من المستوى الثاني (L2).
- عرض نطاق ذاكرة الفيديو (256 مليون عنصر):حجم البيانات هائل (1 جيجابايت)، ويتجاوز بكثير ذاكرة التخزين المؤقت من المستوى الثاني. يجب نقل البيانات من ذاكرة الفيديو (VRAM).هذا هو ساحة المعركة الحقيقية للمشغلين على نطاق واسع؛ ويكمن الاختبار الأساسي في ما إذا كان يتم استخدام عرض النطاق الترددي للذاكرة الفعلية بشكل كامل.
2. برنامج قياس الأداء (بايثون)
يقوم البرنامج النصي بتحميل ملف .cu المحدد أعلاه مباشرةً ويحسب تلقائيًا عرض النطاق الترددي (جيجابايت/ثانية) وزمن الوصول (مللي ثانية).
import torch
from torch.utils.cpp_extension import load
import time
import os
# ==========================================
# 0. 准备工作
# ==========================================
# 确保你的文件路径和笔记里写的一致
kernel_dir = "."
flags = ["-O3", "--use_fast_math", "-U__CUDA_NO_HALF_OPERATORS__"]
print(f"Loading kernels from {kernel_dir}...")
# ==========================================
# 1. 分别加载 6 个模块
# ==========================================
# 我们分别编译加载,确保每个模块有独立的命名空间,避免符号冲突
try:
mod_v1 = load(name="v1_lib", sources=[os.path.join(kernel_dir, "v1_f32.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v2 = load(name="v2_lib", sources=[os.path.join(kernel_dir, "v2_f32x4.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v3 = load(name="v3_lib", sources=[os.path.join(kernel_dir, "v3_f16.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v4 = load(name="v4_lib", sources=[os.path.join(kernel_dir, "v4_f16x2.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v5 = load(name="v5_lib", sources=[os.path.join(kernel_dir, "v5_f16x8.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v6 = load(name="v6_lib", sources=[os.path.join(kernel_dir, "v6_f16x8_pack.cu")], extra_cuda_cflags=flags, verbose=False)
print("All Kernels Loaded Successfully!\n")
except Exception as e:
print("\n[Error] 加载失败!请检查目录下是否有这 6 个 .cu 文件,且代码已修正语法错误。")
print(f"详细报错: {e}")
raise e
# ==========================================
# 2. Benchmark 工具函数
# ==========================================
def run_benchmark(func, a, b, tag, out, warmup=10, iters=1000):
# 重置输出
out.fill_(0)
# Warmup (预热,让 GPU 进入高性能状态)
for _ in range(warmup):
func(a, b, out)
torch.cuda.synchronize()
# Timing (计时)
start = time.time()
for _ in range(iters):
func(a, b, out)
torch.cuda.synchronize()
end = time.time()
# Metrics (指标计算)
avg_time_ms = (end - start) * 1000 / iters
# Bandwidth Calculation: (Read A + Read B + Write C)
element_size = a.element_size() # float=4, half=2
total_bytes = 3 * a.numel() * element_size
bandwidth_gbs = total_bytes / (avg_time_ms / 1000) / 1e9
# Check Result (打印前 2 个元素用于验证正确性)
# 取数据回 CPU 检查
out_val = out.flatten()[:2].cpu().float().tolist()
out_val = [round(v, 4) for v in out_val]
print(f"{tag:<20} | Time: {avg_time_ms:.4f} ms | BW: {bandwidth_gbs:>7.1f} GB/s | Check: {out_val}")
# ==========================================
# 3. 运行测试 (从小到大)
# ==========================================
# 1M = 2^20
shapes = [
(1024, 1024), # 1M elems (Cache Latency)
(4096, 4096), # 16M elems (L2 Cache 吞吐)
(16384, 16384), # 256M elems (显存带宽压测)
]
print(f"{'='*90}")
print(f"Running Benchmark on {torch.cuda.get_device_name(0)}")
print(f"{'='*90}\n")
for S, K in shapes:
N = S * K
print(f"--- Data Size: {N/1e6:.1f} M Elements ({N*4/1024/1024:.0f} MB FP32) ---")
# --- FP32 测试 ---
a_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
b_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
c_f32 = torch.empty_like(a_f32)
# 注意:这里调用的是 .add 方法,因为你在 PYBIND11 里面定义的名字是 "add"
run_benchmark(mod_v1.add, a_f32, b_f32, "V1 (FP32 Base)", c_f32)
run_benchmark(mod_v2.add, a_f32, b_f32, "V2 (FP32 Vec)", c_f32)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f32, b_f32, "PyTorch (FP32)", c_f32)
# --- FP16 测试 ---
print("-" * 60)
a_f16 = a_f32.half()
b_f16 = b_f32.half()
c_f16 = c_f32.half()
run_benchmark(mod_v3.add, a_f16, b_f16, "V3 (FP16 Base)", c_f16)
run_benchmark(mod_v4.add, a_f16, b_f16, "V4 (FP16 Half2)", c_f16)
run_benchmark(mod_v5.add, a_f16, b_f16, "V5 (FP16 Unroll)", c_f16)
run_benchmark(mod_v6.add, a_f16, b_f16, "V6 (FP16 Pack)", c_f16)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f16, b_f16, "PyTorch (FP16)", c_f16)
print("\n")
3. بيانات من واقع الاستخدام: أداء بطاقة RTX 5090
فيما يلي البيانات الفعلية التي تم الحصول عليها من خلال تشغيل الكود المذكور أعلاه على بطاقة رسومات NVIDIA GeForce RTX 5090:
==========================================================================================
Running Benchmark on NVIDIA GeForce RTX 5090
==========================================================================================---
Data Size: 1.0 M Elements (4 MB FP32) ---
V1 (FP32 Base) | Time: 0.0041 ms | BW: 3063.1 GB/s | Check: [0.8656, 1.9516]
V2 (FP32 Vec) | Time: 0.0041 ms | BW: 3066.1 GB/s | Check: [0.8656, 1.9516]
PyTorch (FP32) | Time: 0.0044 ms | BW: 2868.9 GB/s | Check: [0.8656, 1.9516]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V4 (FP16 Half2) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V5 (FP16 Unroll) | Time: 0.0041 ms | BW: 1533.5 GB/s | Check: [0.8657, 1.9512]
V6 (FP16 Pack) | Time: 0.0041 ms | BW: 1533.6 GB/s | Check: [0.8657, 1.9512]
PyTorch (FP16) | Time: 0.0044 ms | BW: 1431.6 GB/s | Check: [0.8657, 1.9512]
--- Data Size: 16.8 M Elements (64 MB FP32) ---
V1 (FP32 Base) | Time: 0.1183 ms | BW: 1702.2 GB/s | Check: [-3.2359, -0.1663]
V2 (FP32 Vec) | Time: 0.1186 ms | BW: 1698.1 GB/s | Check: [-3.2359, -0.1663]
PyTorch (FP32) | Time: 0.1176 ms | BW: 1711.8 GB/s | Check: [-3.2359, -0.1663]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V4 (FP16 Half2) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V5 (FP16 Unroll) | Time: 0.0348 ms | BW: 2892.8 GB/s | Check: [-3.2363, -0.1664]
V6 (FP16 Pack) | Time: 0.0348 ms | BW: 2892.6 GB/s | Check: [-3.2363, -0.1664]
PyTorch (FP16) | Time: 0.0148 ms | BW: 6815.7 GB/s | Check: [-3.2363, -0.1664]
--- Data Size: 268.4 M Elements (1024 MB FP32) ---
V1 (FP32 Base) | Time: 2.0432 ms | BW: 1576.5 GB/s | Check: [0.4839, -2.6795]
V2 (FP32 Vec) | Time: 2.0450 ms | BW: 1575.2 GB/s | Check: [0.4839, -2.6795]
PyTorch (FP32) | Time: 2.0462 ms | BW: 1574.3 GB/s | Check: [0.4839, -2.6795]
------------------------------------------------------------
V3 (FP16 Base) | Time: 1.0173 ms | BW: 1583.2 GB/s | Check: [0.4839, -2.6797]
V4 (FP16 Half2) | Time: 1.0249 ms | BW: 1571.5 GB/s | Check: [0.4839, -2.6797]
V5 (FP16 Unroll) | Time: 1.0235 ms | BW: 1573.6 GB/s | Check: [0.4839, -2.6797]
V6 (FP16 Pack) | Time: 1.0236 ms | BW: 1573.4 GB/s | Check: [0.4839, -2.6797]
PyTorch (FP16) | Time: 1.0251 ms | BW: 1571.2 GB/s | Check: [0.4839, -2.6797]
4. تفسير البيانات
توضح هذه البيانات بوضوح الخصائص الفيزيائية لبطاقة RTX 5090 تحت أحمال مختلفة:
المرحلة 1: نطاق صغير جدًا (1 مليون عنصر / 4 ميجابايت)
- ظاهرة:جميع الإصدارات كان لها وقت تنفيذ متسق بشكل ملحوظ يبلغ 0.0041 مللي ثانية.
- الحقيقة:هذا وضعٌ مرتبطٌ بزمن الاستجابة. بغض النظر عن حجم البيانات، فإنّ زمن بدء تشغيل النواة الثابت لوحدة معالجة الرسومات يبلغ حوالي 4 ميكروثانية. وبسبب هذا القيد الزمني، فإنّ حجم البيانات في FP16 هو نصف حجمها في FP32، وبالتالي فإنّ عرض النطاق الترددي المحسوب هو النصف أيضاً. ما يتم قياسه هنا ليس سرعة الإرسال، بل "سرعة بدء التشغيل".
المرحلة الثانية: الحجم المتوسط (16 مليون عنصر / 64 ميجابايت مقابل 32 ميجابايت)
هذا هو المجال الذي يوضح وظيفة ذاكرة التخزين المؤقت من المستوى الثاني (L2) على أفضل وجه:
- FP32 (64 ميجابايت):يبلغ إجمالي حجم البيانات A+B+C حوالي 192 ميجابايت. وهذا يتجاوز سعة ذاكرة التخزين المؤقت L2 لبطاقة RTX 5090 (حوالي 128 ميجابايت). وقد أجبر فائض البيانات النظام على القراءة والكتابة إلى ذاكرة الوصول العشوائي للفيديو (VRAM)، مما أدى إلى انخفاض عرض النطاق الترددي إلى 1700 جيجابايت/ثانية (قريب من عرض النطاق الترددي الفعلي لذاكرة الفيديو).
- FP16 (32 ميجابايت):إجمالي حجم البيانات.إنها تتناسب تمامًا مع ذاكرة التخزين المؤقت من المستوى الثاني! تتداول البيانات داخل ذاكرة التخزين المؤقت، مما يتسبب في ارتفاع عرض النطاق الترددي إلى 2890 جيجابايت/ثانية.
- السحر المظلم لـ PyTorch:تجدر الإشارة إلى أن PyTorch حقق سرعة 6815 جيجابايت/ثانية في FP16. وهذا يدل على أنه في سيناريو ذاكرة التخزين المؤقت البحتة، لا يزال تحسين خط أنابيب التعليمات لمترجم JIT متفوقًا على نواة مكتوبة يدويًا بسيطة.
المرحلة 3: واسعة النطاق (268 مليون عنصر / 1024 ميجابايت)
هذا سيناريو واقعي للتدريب/الاستدلال باستخدام نموذج كبير (حدود الذاكرة):
- جميع الكائنات متساوية:سواء كان FP32 أو FP16، وسواء كان Baseline أو Optimized، فإن عرض النطاق الترددي كله ثابت عند 1570-1580 جيجابايت/ثانية.
- جدار مادي:لقد وصلنا بنجاح إلى الحد الأقصى لنطاق تردد ذاكرة GDDR7 الخاصة ببطاقة RTX 5090. النطاق الترددي محدود، ولا يمكن زيادته.
- قيمة التحسين:على الرغم من أن عرض النطاق الترددي ظل كما هو.ومع ذلك، فقد تبين أن وقت FP16 (1.02 مللي ثانية) كان نصف وقت FP32 (2.04 مللي ثانية).من خلال تقليل حجم البيانات إلى النصف مع زيادة عرض النطاق الترددي إلى أقصى حد، هناك تسارع من طرف إلى طرف بمقدار الضعف. V6 مقابل V3على الرغم من أن الإصدار الثالث (V3) يبدو أنه يعمل بكامل طاقته، إلا أن ذلك يعود إلى التحسين التلقائي بواسطة مُصرّف NVCC وتقنية إخفاء زمن استجابة وحدة معالجة الرسومات (GPU). مع ذلك، في العمليات الأكثر تعقيدًا (مثل FlashAttention)، يضمن الإصدار السادس (V6) الأداء الأمثل.
الأسئلة الشائعة الأساسية: الاشتقاق المتعمق لتصميم المعلمات
في جميع نوى هذه التجربة، قمنا بالإجماع بتعيين المعلمة: threads_per_block = 256. لم يتم اختيار هذا الرقم عشوائيًا، بل كان حلاً رياضيًا مثاليًا بين قيود الأجهزة وكفاءة الجدولة.
س: لماذا يتم دائمًا ضبط threads_per_block على 128 أو 256؟
ج: هذا "نطاق ذهبي" يتم الحصول عليه من خلال أربع طبقات من الفرز.
نحن ننظر إلى عملية اختيار حجم الكتلة على أنها قمع، حيث يتم التصفية طبقة تلو الأخرى:
1. محاذاة الالتواء -> يجب أن تكون من مضاعفات العدد 32
أصغر وحدة تنفيذ في وحدة معالجة الرسومات هي مجموعة الخيوط (warp)، والتي تتكون من 32 خيطًا متتاليًا (بنية SIMT، تعدد الخيوط بتعليمات واحدة).
- القيود الصارمة:إذا طلبت 31 خيطًا، فسيظل الجهاز يُجدول دورة معالجة كاملة واحدة. على الرغم من أن موضع الخيط المتبقي يكون خاملاً، إلا أنه لا يزال يشغل نفس موارد الجهاز.
- ختاماً: من الأفضل أن يكون حجم الكتلة من مضاعفات العدد 32 لتجنب إهدار قوة الحوسبة.
2. طابق الإشغال -> يجب أن يكون ≥ 96
نسبة الإشغال = عدد الخيوط المتزامنة التي يتم تنفيذها حاليًا على SM / الحد الأقصى لعدد الخيوط التي يدعمها SM.
- خلفية:لإخفاء زمن استجابة الذاكرة، نحتاج إلى عدد كافٍ من الالتفافات النشطة. إذا كان حجم الكتلة صغيرًا جدًا، فسيتم الوصول إلى حد "الحد الأقصى للكتل" الخاص بوحدة المعالجة المتعددة قبل الوصول إلى حد "الحد الأقصى للخيوط".
- تقدير:تتطلب البنى المعمارية الشائعة (مثل تورينج/أمبير/آدا) عادةً أن يكون حجم الكتلة أكبر من (الحد الأقصى لعدد الخيوط في وحدة المعالجة المتعددة / الحد الأقصى لعدد الكتل في وحدة المعالجة المتعددة). وتتراوح النسب الشائعة بين 64 و96.
- ختاماً:لتحقيق نسبة إشغال 100% نظرياً، يجب ألا يقل حجم الكتلة عن 96.
3. جدولة الذرية -> تأمين 128، 256، 512
الكتلة هي أصغر وحدة ذرية مُجدولة لوحدة المعالجة المتعددة (SM). يجب أن تكون وحدة المعالجة المتعددة قادرة على استهلاك عدد صحيح من الكتل بشكل كامل.
- قابلية القسمة:لتجنب إهدار سعة SM، يجب أن يكون حجم الكتلة قابلاً للقسمة على الحد الأقصى لسعة مؤشر الترابط في SM.
- فلتر:تبلغ السعة القصوى لوحدات المعالجة المركزية ذات البنية السائدة عادةً 1024، 1536، 2048، إلخ. وقاسمها المشترك عادةً هو 512. وبدمج الخطوتين السابقتين (≥96 ومضاعفات 32)، يتم تضييق قائمة المرشحين لدينا إلى: 128، 192، 256، 384، 512.
4. تسجيل الضغط -> استبعاد 512+
هذا هو "السقف" النهائي.
- القيود الصارمة:إن العدد الإجمالي للسجلات المتاحة لكل كتلة محدود (يبلغ العدد الإجمالي للسجلات في SM عادةً 64K 32 بت).
- مخاطرة:إذا كان حجم الكتلة كبيرًا (على سبيل المثال، 512)، وكانت النواة أكثر تعقيدًا قليلاً (يستخدم كل مؤشر ترابط عدة سجلات)، فسيحدث الوضع حيث 512 * السجلات / مؤشر الترابط > الحد الأقصى للسجلات لكل كتلة.
- نتيجة لـ:فشل بدء التشغيل: رسالة خطأ مباشرة. تجاوز سعة السجلات: تتجاوز سعة السجلات الذاكرة المحلية البطيئة، مما يتسبب في سلسلة من المشاكل في الأداء.
- ختاماً:لأسباب تتعلق بالسلامة، نتجنب عمومًا استخدام 512 أو 1024. 128 و 256 هما أكثر "المناطق الصحراوية" أمانًا.
تلخيص
بعد أربع جولات من الإقصاء، لم يتبق سوى متسابقين اثنين:
- 128يتميز بأعلى مستويات التنوع.حتى مع وجود نواة معقدة (تستخدم العديد من السجلات)، لا يزال بإمكانها ضمان بدء التشغيل الناجح والاستخدام الجيد.
- 256:يفضل استخدام عامل التشغيل العنصريبالنسبة للعمليات البسيطة مثل معالجة العناصر، يكون ضغط السجلات ضئيلاً. يوفر حجم 256 إمكانية دمج ذاكرة أفضل من حجم 128 ويقلل من عبء جدولة الكتل.
وهذا يفسر أيضًا لماذا، في التنفيذ البسيط، بمجرد أن نحدد threads_per_block = 256، يتم تحديد grid_size أيضًا (طالما أن المبلغ الإجمالي يغطي N).
الملحق: أمثلة تشغيل Jupyter









