HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

MemSlides: 다중 턴 로컬 수정을 통한 개인화된 슬라이드 생성을 위한 계층적 메모리 구동 Agent 프레임워크

PerceptionDLM: 멀티모달 확산 언어 모델을 이용한 병렬 영역 지각


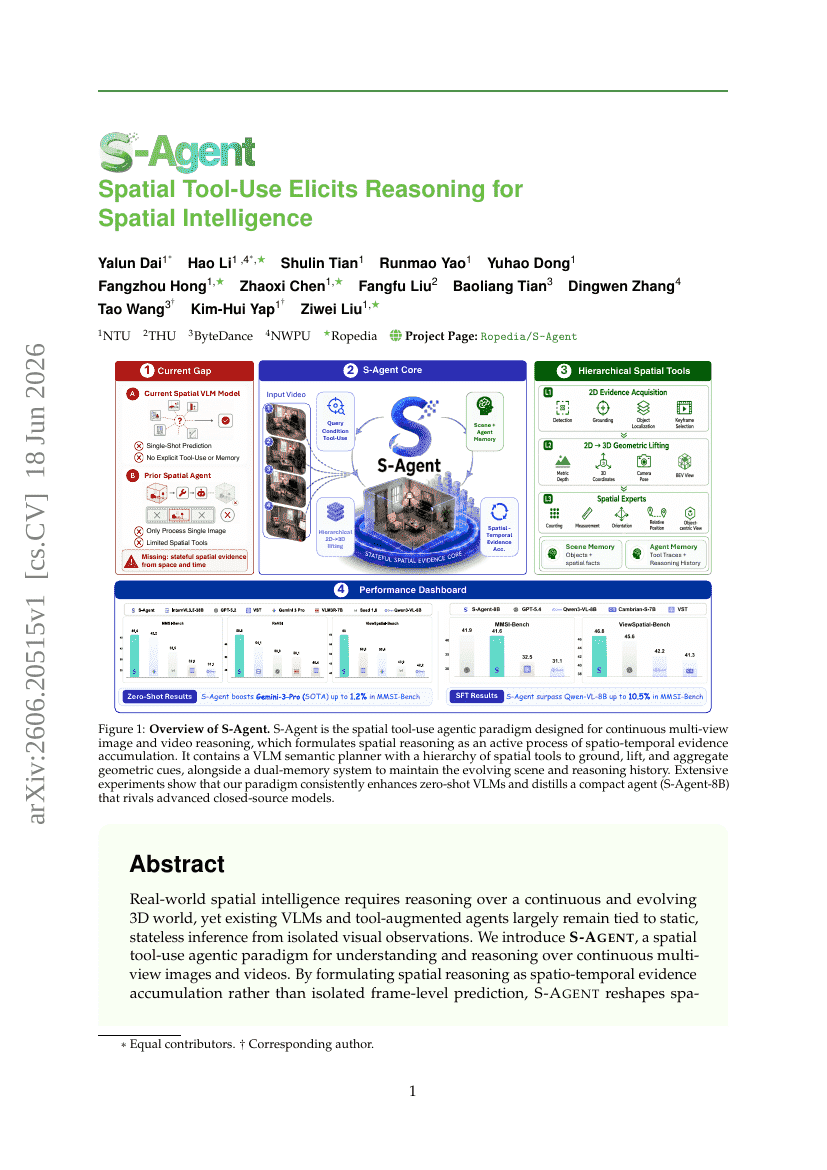















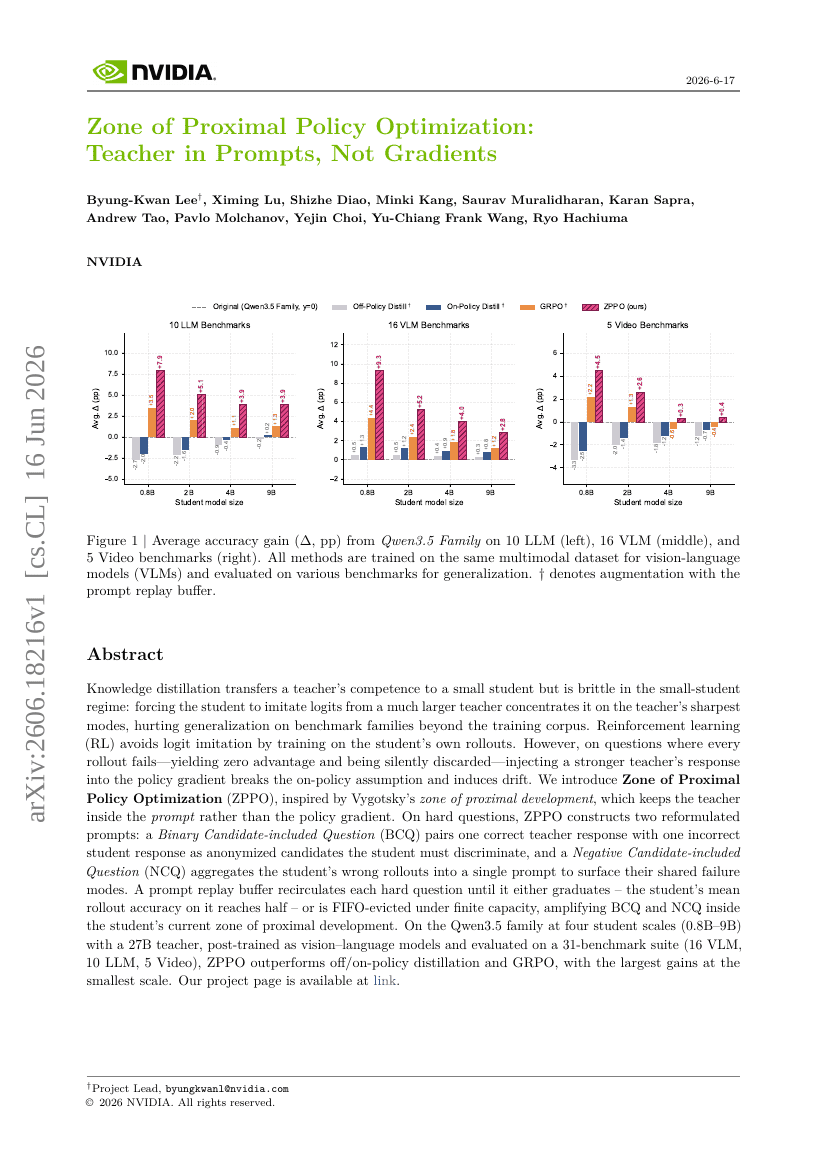


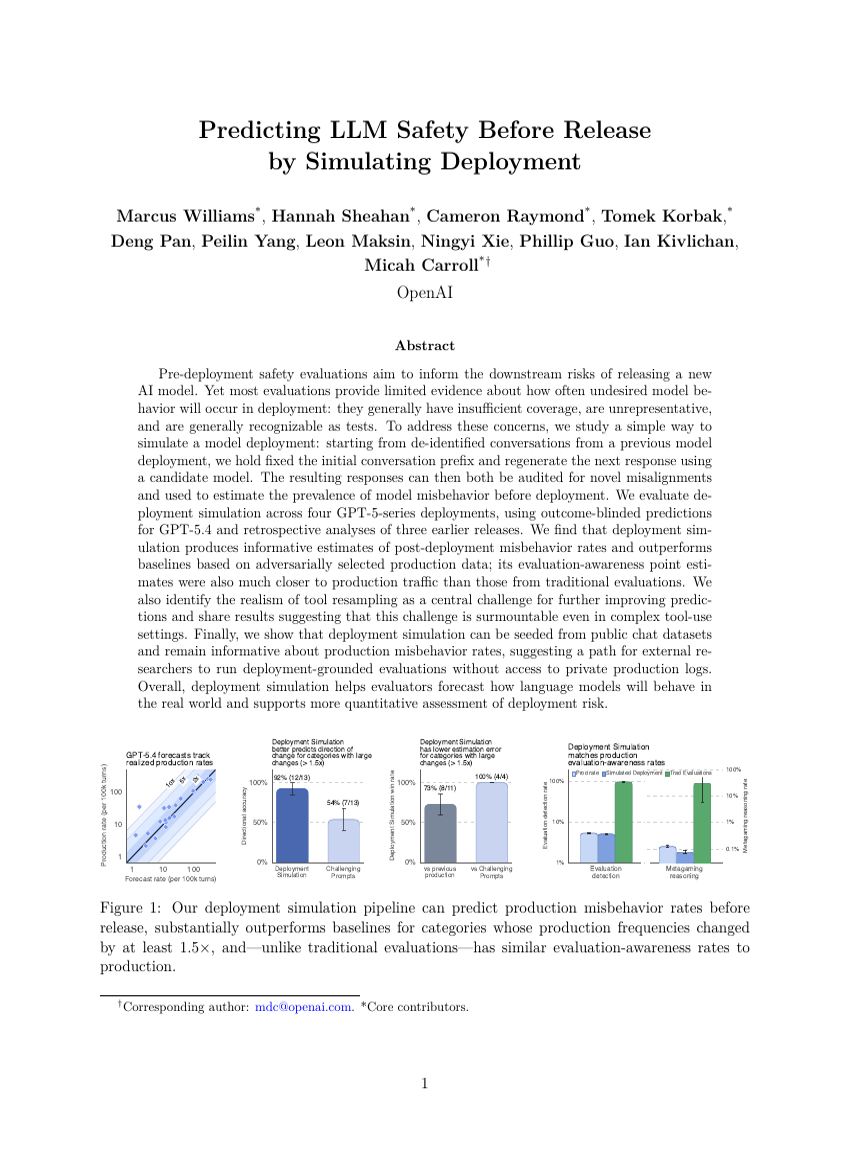



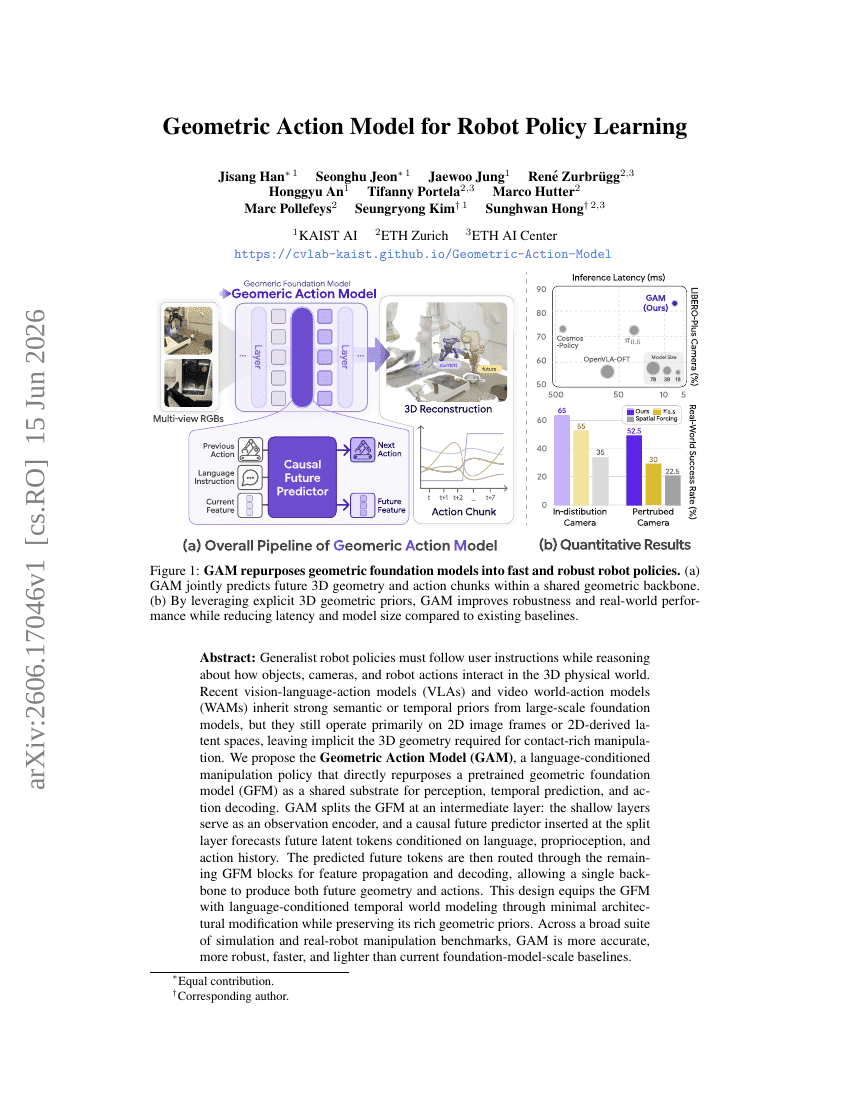




MemSlides: 다중 턴 로컬 수정을 통한 개인화된 슬라이드 생성을 위한 계층적 메모리 구동 Agent 프레임워크
PerceptionDLM: 멀티모달 확산 언어 모델을 이용한 병렬 영역 지각
일반 게임 플레이를 위한 코드 월드 모델
정적 리더보드를 넘어: LLM agents 평가를 위한 예측 타당도
S-Agent: 공간적 도구 사용이 공간 지능을 위한 추론을 이끌어낸다
Multi-LCB: LiveCodeBench를 여러 프로그래밍 언어로 확장
장난기 있는 에이전트 기반 로봇 학습
DragMesh-2: 관절형 물체와의 물리적으로 타당한 정교한 손-물체 상호작용
Moebius: 10B급 성능을 갖춘 0.2B 경량 이미지 인페인팅 프레임워크
EfficientRollout: RL 롤아웃을 위한 시스템 인지형 자기 예측 디코딩
올바른 교사를 신뢰하라: GUI 그라운딩을 위한 품질 인식 자기 증류
공간 시각 언어 모델에서의 이중 경로 추론 강화
SAE 개입은 신뢰할 수 없다: 개입 후 억제된 행동의 회복
Kairos: 물리 AI를 위한 네이티브 월드 모델 스택
Guava: 구체적 조작을 위한 효과적이고 범용적인 하네스
현재 관측을 넘어: 제어 가능한 비마르코프 게임에서 다중 모달 대규모 언어 모델 평가
LifeSciBench: 생명과학 분야에서의 현실적이고 전문가 수준의 과제를 수행하는 데 있어 언어 모델(LLM) 평가
TRIAGE: LLM을 사용하여 불규칙하게 샘플링된 의료 시계열에 대한 설명 가능한 위험 예측을 위한 변증법적 추론
LectūraAgents: 적응형 개인화 AI 보조 학습 및 신체화 교수를 위한 다중 Agent 프레임워크
GameCraft-Bench: Agents가 실제 게임 엔진에서 플레이 가능한 게임을 엔드투엔드로 구축할 수 있는가?
근접 정책 최적화의 영역: 프롬프트에는 교사를, 그래디언트에는 아님
ACE-Ego-0: VLA 사전 학습을 위한 시점 중심 인간 및 로봇 데이터 통합
LoopCoder-v2: 효율적인 테스트 타임 계산 확장을 위해 단 한 번만 루프를 돌다
배포 시뮬레이션을 통한 LLM 안전성 사전 예측
FastContext: 코딩 Agents를 위한 효율적인 저장소 탐색기 학습
VibeThinker-3B: 소형 언어 모델에서 검증 가능한 추론의 최전선을 탐구하다
DreamX-World 1.0: 범용 상호작용형 월드 모델
로봇 정책 학습을 위한 기하학적 동작 모델
데이터 저널리스트 Agent: 데이터를 검증 가능한 다중 모달 스토리로 변환
JoyAI-VL-Interaction: 실시간 시각-언어 상호작용 지능
dots.tts 기술 보고서
Generative Priors를 활용한 결정론적 비디오 깊이 추정을 위한 방법
일반 게임 플레이를 위한 코드 월드 모델
정적 리더보드를 넘어: LLM agents 평가를 위한 예측 타당도
S-Agent: 공간적 도구 사용이 공간 지능을 위한 추론을 이끌어낸다
Multi-LCB: LiveCodeBench를 여러 프로그래밍 언어로 확장
장난기 있는 에이전트 기반 로봇 학습
DragMesh-2: 관절형 물체와의 물리적으로 타당한 정교한 손-물체 상호작용
Moebius: 10B급 성능을 갖춘 0.2B 경량 이미지 인페인팅 프레임워크
EfficientRollout: RL 롤아웃을 위한 시스템 인지형 자기 예측 디코딩
올바른 교사를 신뢰하라: GUI 그라운딩을 위한 품질 인식 자기 증류
공간 시각 언어 모델에서의 이중 경로 추론 강화
SAE 개입은 신뢰할 수 없다: 개입 후 억제된 행동의 회복
Kairos: 물리 AI를 위한 네이티브 월드 모델 스택
Guava: 구체적 조작을 위한 효과적이고 범용적인 하네스
현재 관측을 넘어: 제어 가능한 비마르코프 게임에서 다중 모달 대규모 언어 모델 평가
LifeSciBench: 생명과학 분야에서의 현실적이고 전문가 수준의 과제를 수행하는 데 있어 언어 모델(LLM) 평가
TRIAGE: LLM을 사용하여 불규칙하게 샘플링된 의료 시계열에 대한 설명 가능한 위험 예측을 위한 변증법적 추론
LectūraAgents: 적응형 개인화 AI 보조 학습 및 신체화 교수를 위한 다중 Agent 프레임워크
GameCraft-Bench: Agents가 실제 게임 엔진에서 플레이 가능한 게임을 엔드투엔드로 구축할 수 있는가?
근접 정책 최적화의 영역: 프롬프트에는 교사를, 그래디언트에는 아님
ACE-Ego-0: VLA 사전 학습을 위한 시점 중심 인간 및 로봇 데이터 통합
LoopCoder-v2: 효율적인 테스트 타임 계산 확장을 위해 단 한 번만 루프를 돌다
배포 시뮬레이션을 통한 LLM 안전성 사전 예측
FastContext: 코딩 Agents를 위한 효율적인 저장소 탐색기 학습
VibeThinker-3B: 소형 언어 모델에서 검증 가능한 추론의 최전선을 탐구하다
DreamX-World 1.0: 범용 상호작용형 월드 모델
로봇 정책 학습을 위한 기하학적 동작 모델
데이터 저널리스트 Agent: 데이터를 검증 가능한 다중 모달 스토리로 변환
JoyAI-VL-Interaction: 실시간 시각-언어 상호작용 지능
dots.tts 기술 보고서
Generative Priors를 활용한 결정론적 비디오 깊이 추정을 위한 방법