HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

확산 모델의 일관성에 대한 랜덤 행렬 이론적 관점
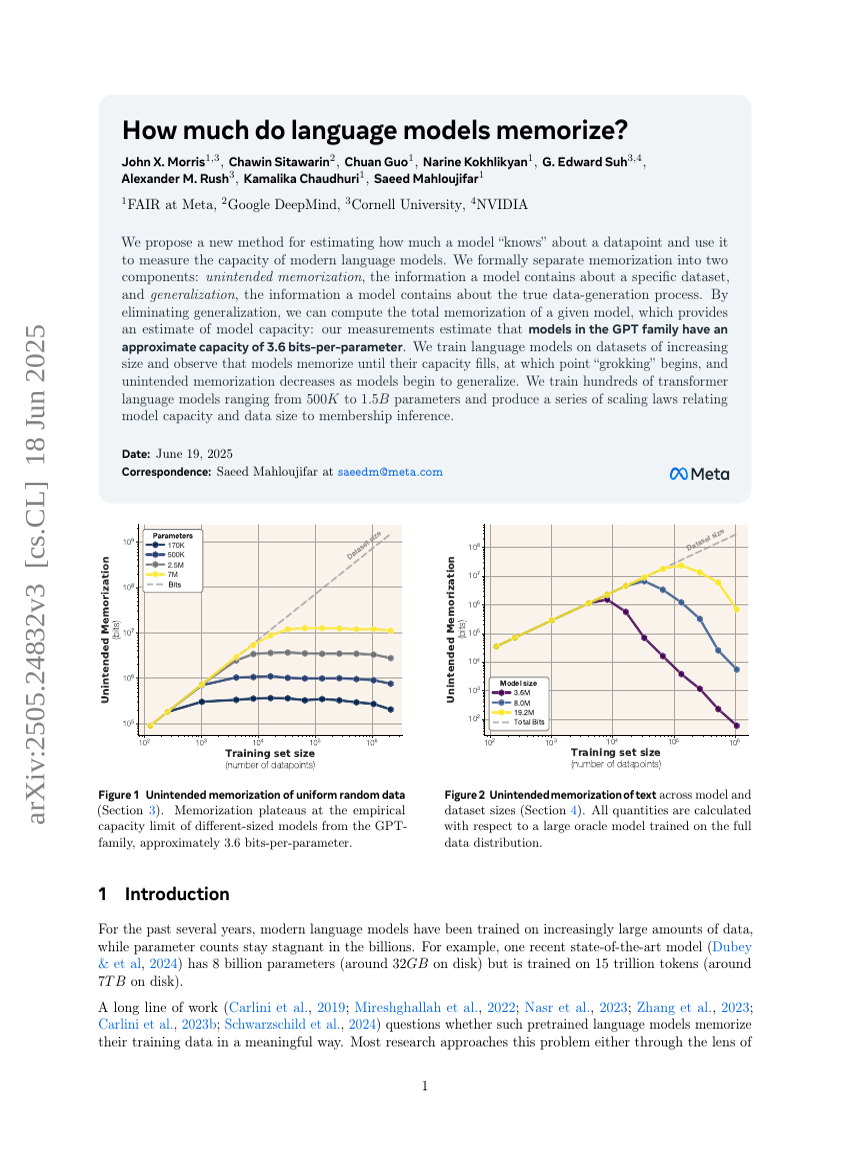
언어 모델은 얼마나 많은 것을 암기하는가?

























확산 모델의 일관성에 대한 랜덤 행렬 이론적 관점
언어 모델은 얼마나 많은 것을 암기하는가?
난독화 지도: 속임수 탐침으로 RLVR에서 정직이 출현하는 곳 지도화
입장: 정렬 커뮤니티가 의도치 않게 검열 도구 키트를 구축하고 있다
확산 모델 및 로그 오목 분포를 위한 고정밀 샘플링
AgenticDataBench: 데이터 에이전트를 위한 종합 벤치마크
다중 해상도 플로우 매칭: 단계적 샘플링을 통한 학습 없는 확산 가속
하이브리드 어텐션 모델로의 모핑
EvoPolicyGym: 대화형 환경에서의 자율 정책 진화 평가
AgenticSTS: 장기적 LLM 에이전트를 위한 제한된 메모리 테스트베드
Program-as-Weights: 퍼지 함수를 위한 프로그래밍 패러다임
MatAnyone 2: 학습된 품질 평가기를 통한 비디오 매팅의 확장
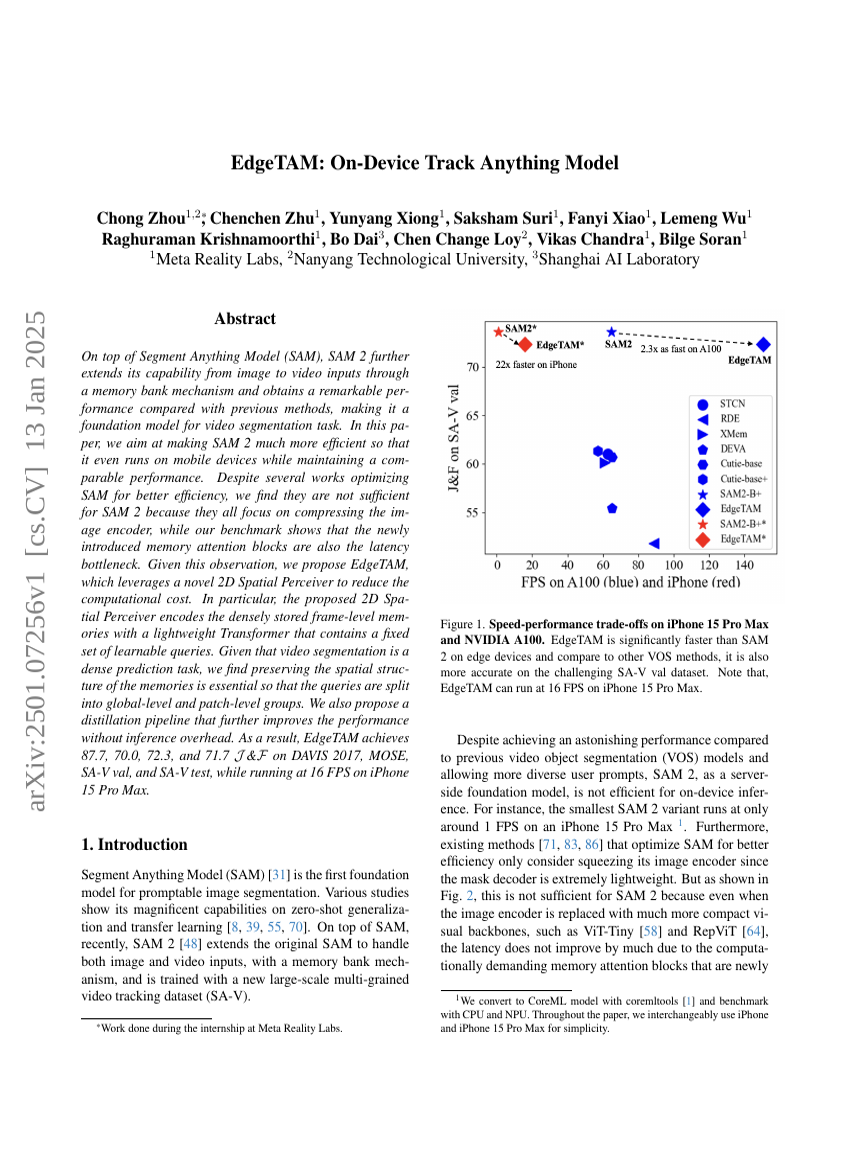
EdgeTAM: 온디바이스 무엇이든 추적 모델
PixelRefer: 임의 세분성의 시공간 객체 참조를 위한 통합 프레임워크
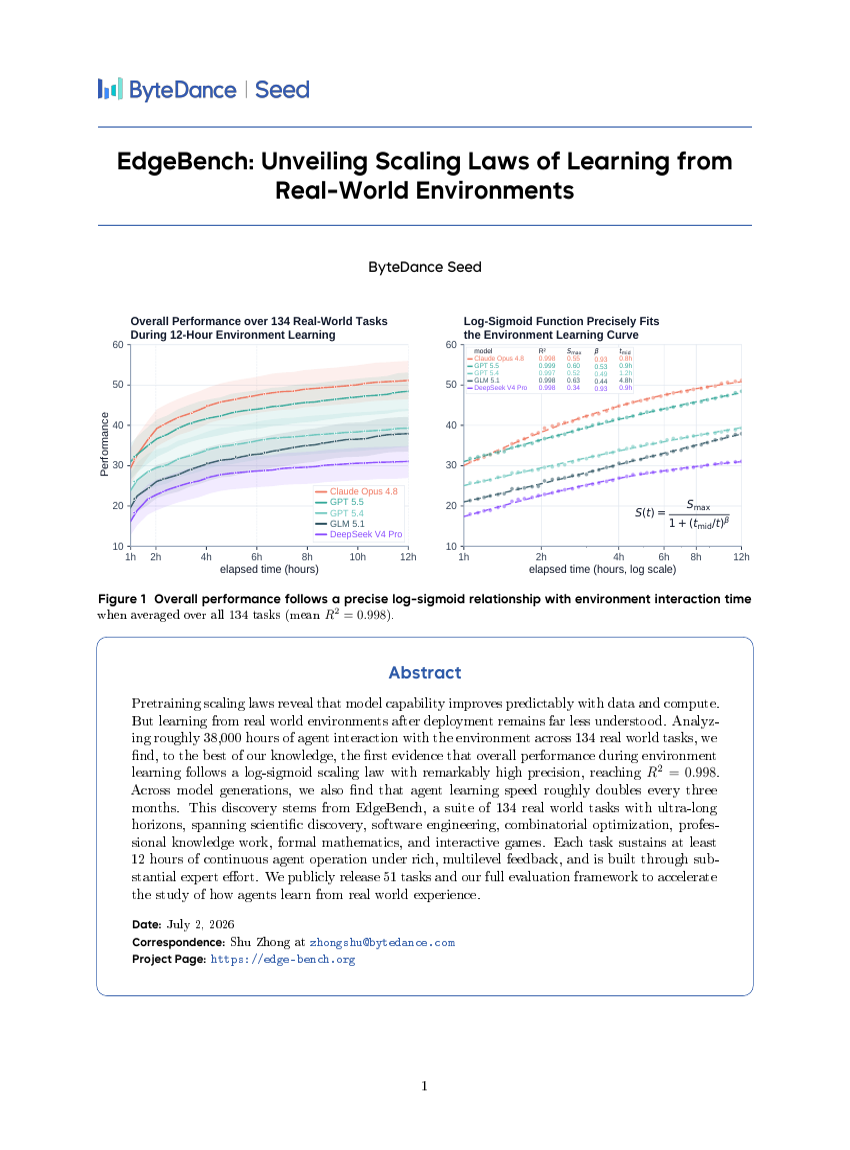
EdgeBench: 실제 환경에서의 학습 스케일링 법칙 규명
ASPIRE: 로봇을 위한 에이전트 기반 기술 발견
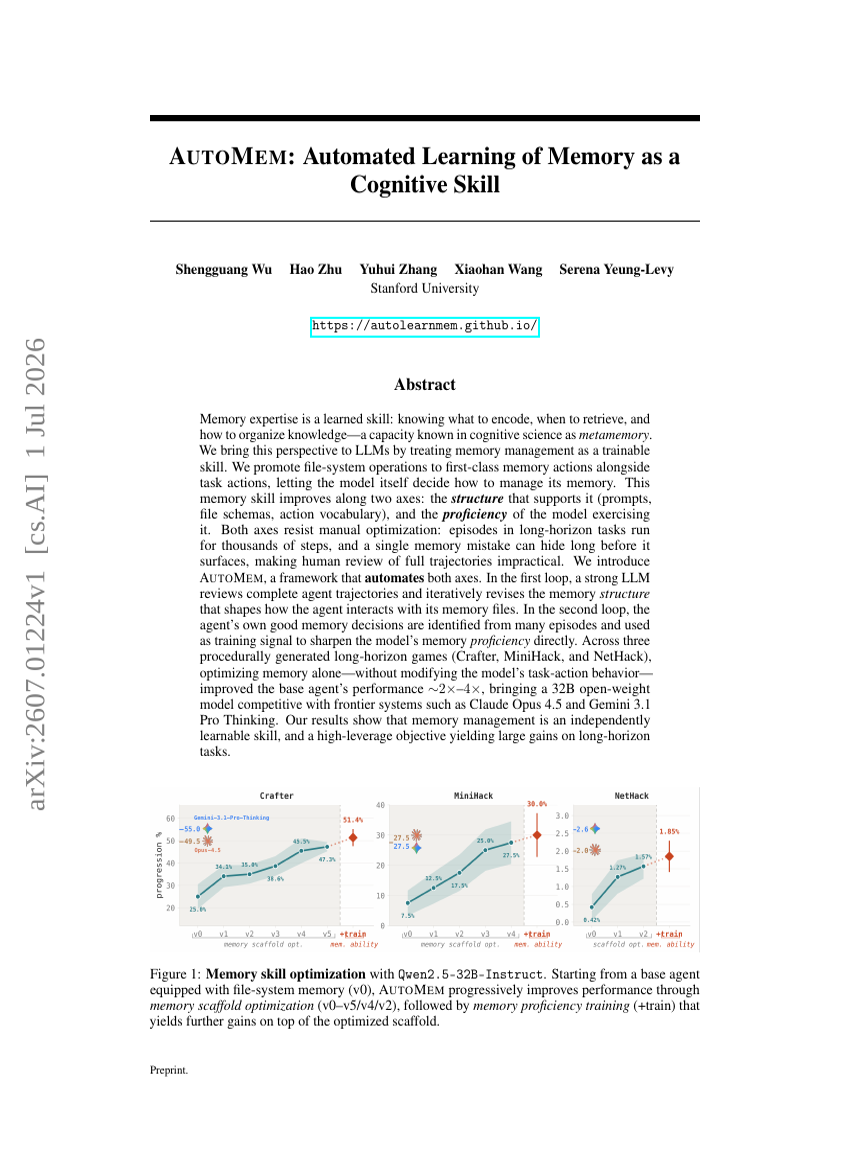
AUTOMEM: 인지 기술로서의 기억에 대한 자동화된 학습
디코드 작업 법칙: 압축된 지오메트리 상에서 마진에 의해 지배되고 증명 가능하게 정확한 공간 조인
조합 최적화 문제를 위한 신경망 인증서 가격 책정
자율 실험실 오케스트레이터를 위한 최적 자원 활용
TERA: 통합 테일러 모델 기반 도달 가능성 분석 프레임워크
Perceive-to-Reason: 세밀한 시각 추론을 위한 인식과 추론의 분리
효율적인 IR 파이프라인 실험을 위한 트라이 기반 실험 계획
대규모 언어 모델 학습을 위한 학습률 스케일링의 비선형성에 관하여
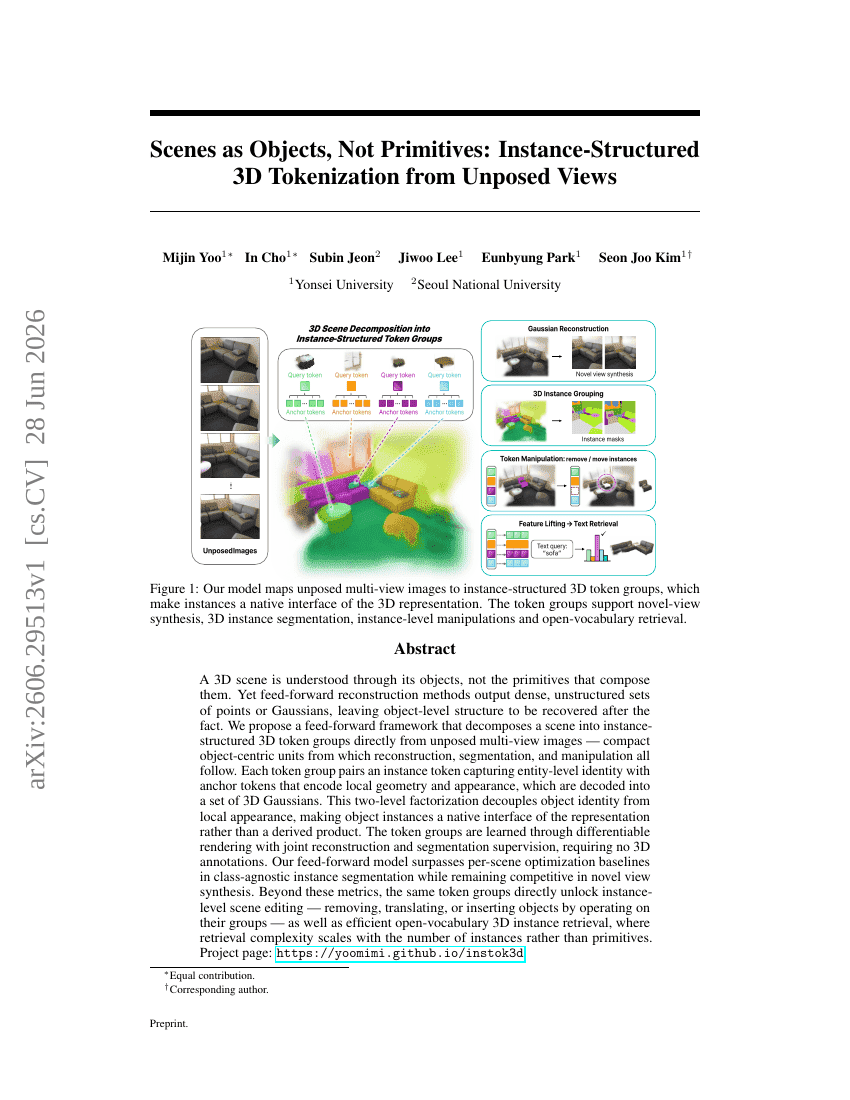
객체로서의 장면, 기본 요소가 아닌: 미정렬 뷰로부터의 인스턴스 구조화 3D 토큰화
BlockPilot: 확산 기반 추론적 디코딩을 위한 인스턴스 적응형 정책 학습
DOPD: 이중 온폴리시 증류
Dockerless: 코딩 에이전트를 위한 환경 독립형 프로그램 검증기
Orca: 세상은 마음속에 있다
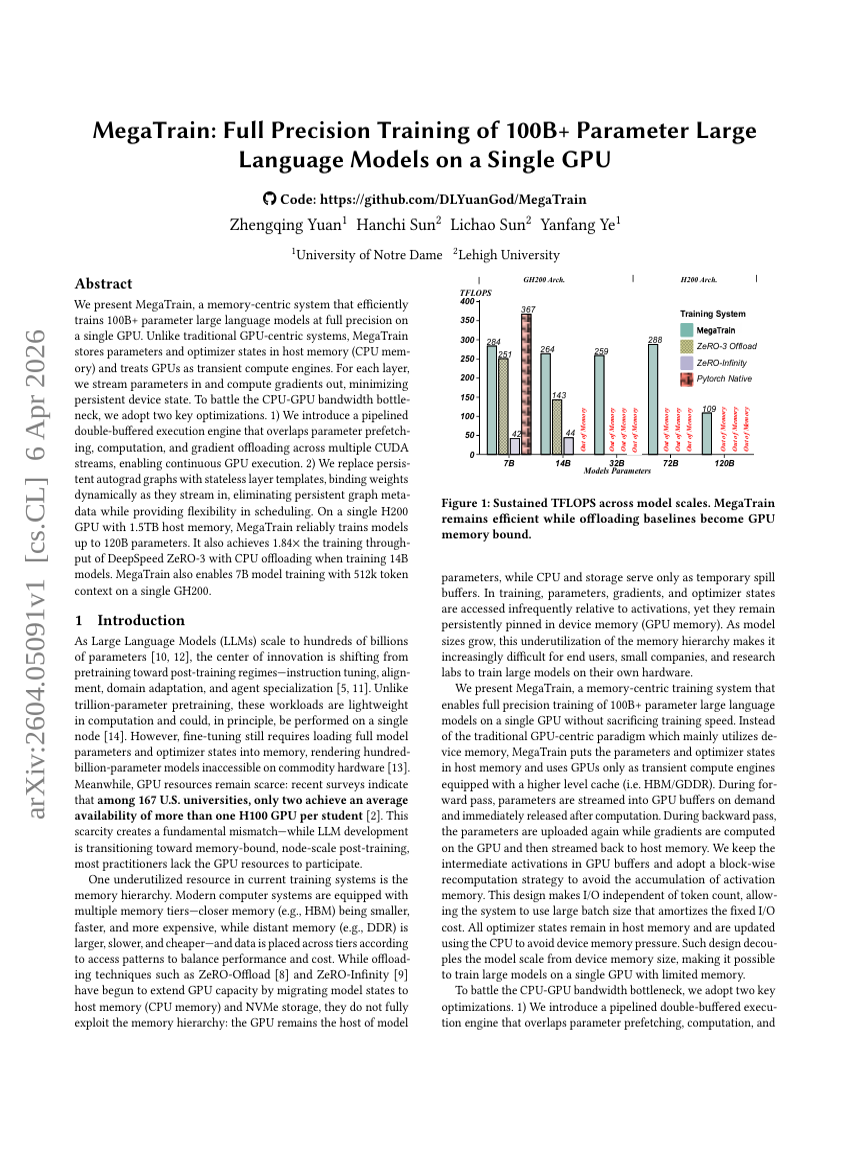
MegaTrain: 단일 GPU에서 100B 이상 파라미터 대규모 언어 모델의 전체 정밀도 학습
생각할 시간 찾기: 실시간 강화학습에서 계획 예산 학습
거의 최적에 가까운 학습률 스케줄은 어떤 모습일까?
난독화 지도: 속임수 탐침으로 RLVR에서 정직이 출현하는 곳 지도화
입장: 정렬 커뮤니티가 의도치 않게 검열 도구 키트를 구축하고 있다
확산 모델 및 로그 오목 분포를 위한 고정밀 샘플링
AgenticDataBench: 데이터 에이전트를 위한 종합 벤치마크
다중 해상도 플로우 매칭: 단계적 샘플링을 통한 학습 없는 확산 가속
하이브리드 어텐션 모델로의 모핑
EvoPolicyGym: 대화형 환경에서의 자율 정책 진화 평가
AgenticSTS: 장기적 LLM 에이전트를 위한 제한된 메모리 테스트베드
Program-as-Weights: 퍼지 함수를 위한 프로그래밍 패러다임
MatAnyone 2: 학습된 품질 평가기를 통한 비디오 매팅의 확장
EdgeTAM: 온디바이스 무엇이든 추적 모델
PixelRefer: 임의 세분성의 시공간 객체 참조를 위한 통합 프레임워크
EdgeBench: 실제 환경에서의 학습 스케일링 법칙 규명
ASPIRE: 로봇을 위한 에이전트 기반 기술 발견
AUTOMEM: 인지 기술로서의 기억에 대한 자동화된 학습
디코드 작업 법칙: 압축된 지오메트리 상에서 마진에 의해 지배되고 증명 가능하게 정확한 공간 조인
조합 최적화 문제를 위한 신경망 인증서 가격 책정
자율 실험실 오케스트레이터를 위한 최적 자원 활용
TERA: 통합 테일러 모델 기반 도달 가능성 분석 프레임워크
Perceive-to-Reason: 세밀한 시각 추론을 위한 인식과 추론의 분리
효율적인 IR 파이프라인 실험을 위한 트라이 기반 실험 계획
대규모 언어 모델 학습을 위한 학습률 스케일링의 비선형성에 관하여
객체로서의 장면, 기본 요소가 아닌: 미정렬 뷰로부터의 인스턴스 구조화 3D 토큰화
BlockPilot: 확산 기반 추론적 디코딩을 위한 인스턴스 적응형 정책 학습
DOPD: 이중 온폴리시 증류
Dockerless: 코딩 에이전트를 위한 환경 독립형 프로그램 검증기
Orca: 세상은 마음속에 있다
MegaTrain: 단일 GPU에서 100B 이상 파라미터 대규모 언어 모델의 전체 정밀도 학습
생각할 시간 찾기: 실시간 강화학습에서 계획 예산 학습
거의 최적에 가까운 학습률 스케줄은 어떤 모습일까?