HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

MUSE-Autoskill: 기술 생성, 기억, 관리 및 평가를 통한 자기 진화형 에이전트

Nemotron 3 Ultra: Agentic Reasoning을 위한 개방형 및 효율적인 Mixture-of-Experts 하이브리드 Mamba-Transformer 모델

























MUSE-Autoskill: 기술 생성, 기억, 관리 및 평가를 통한 자기 진화형 에이전트
Nemotron 3 Ultra: Agentic Reasoning을 위한 개방형 및 효율적인 Mixture-of-Experts 하이브리드 Mamba-Transformer 모델
Qwen-Image-Flash: 목적 설계를 넘어
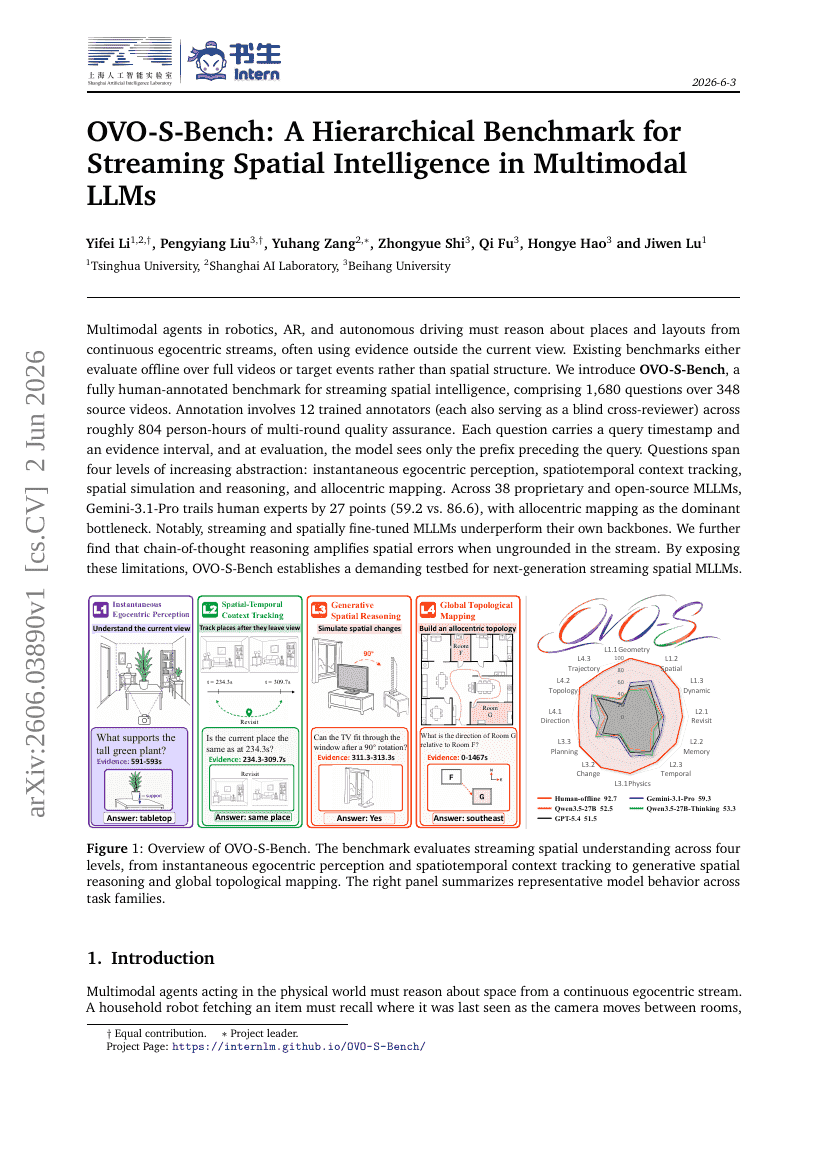
OVO-S-Bench: 멀티모달 LLMs에서의 스트리밍 공간 지능을 위한 계층적 벤치마크
기준 기반 강화 학습에서의 보상 해킹 재현, 분석 및 탐지
딥 리서치 Agents는 어디서 잘못되는가? Agent 궤적 내 스패너 수준 오류 국소화
오디오 상호작용 모델
Cosmos 3: 물리 AI를 위한 올모달 월드 모델
학습, 빠르고 느리게: 지속적 적응형 대규모 언어 모델로의 여정
LEAP: Agentic Frameworks를 활용한 대형 언어 모델의 공식 수학 수행 능력 강화
세계 모델과 언어 모델의 만남: 구체적 추론과 추상적 추론의 상호보완성에 관하여
활성화에서 인과성으로: 인간 뇌에서의 인과적 시각 표현의 발견
다중 도메인 RL에서의 도메인 간 간섭 및 복원에 대한 국소 섭동 이론
Humanoid-GPT: 제로샷 모션 트래킹을 위한 데이터 및 구조 확장
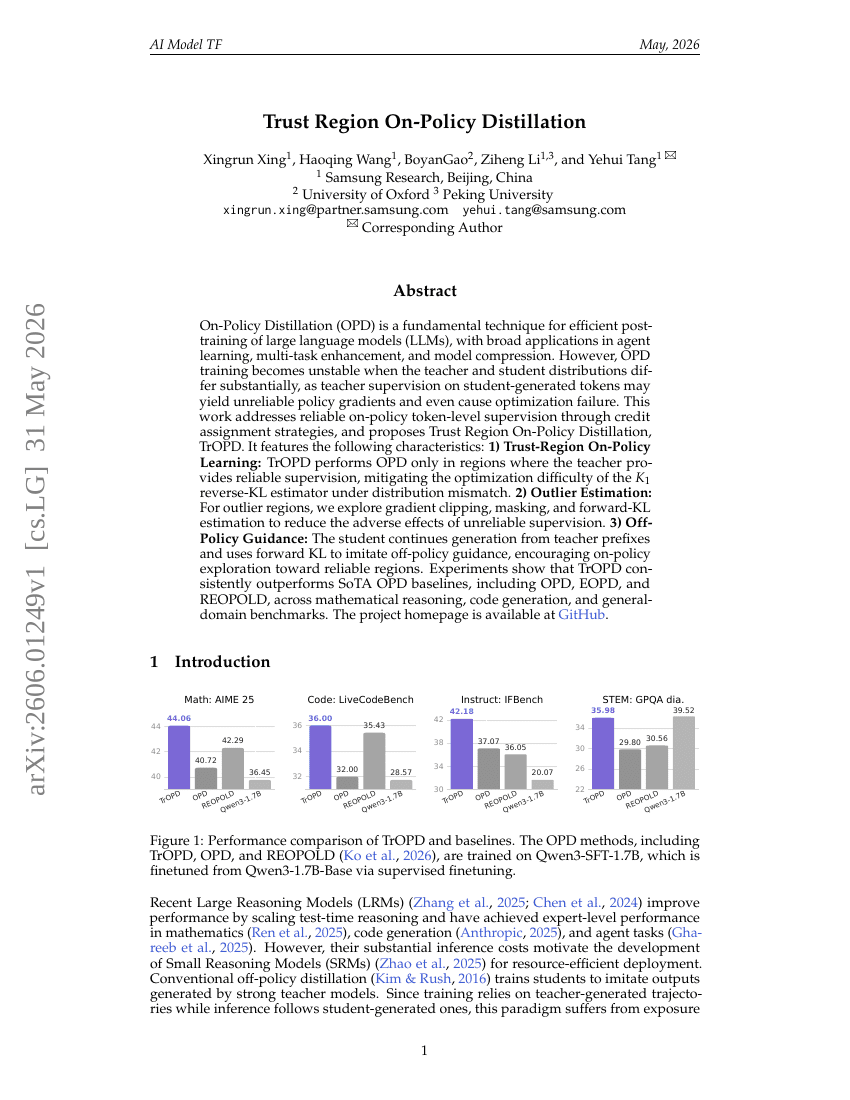
신뢰 영역 온-정책 증류
OCC-RAG: 충실한 질문 응답을 위한 최적의 인지 핵심
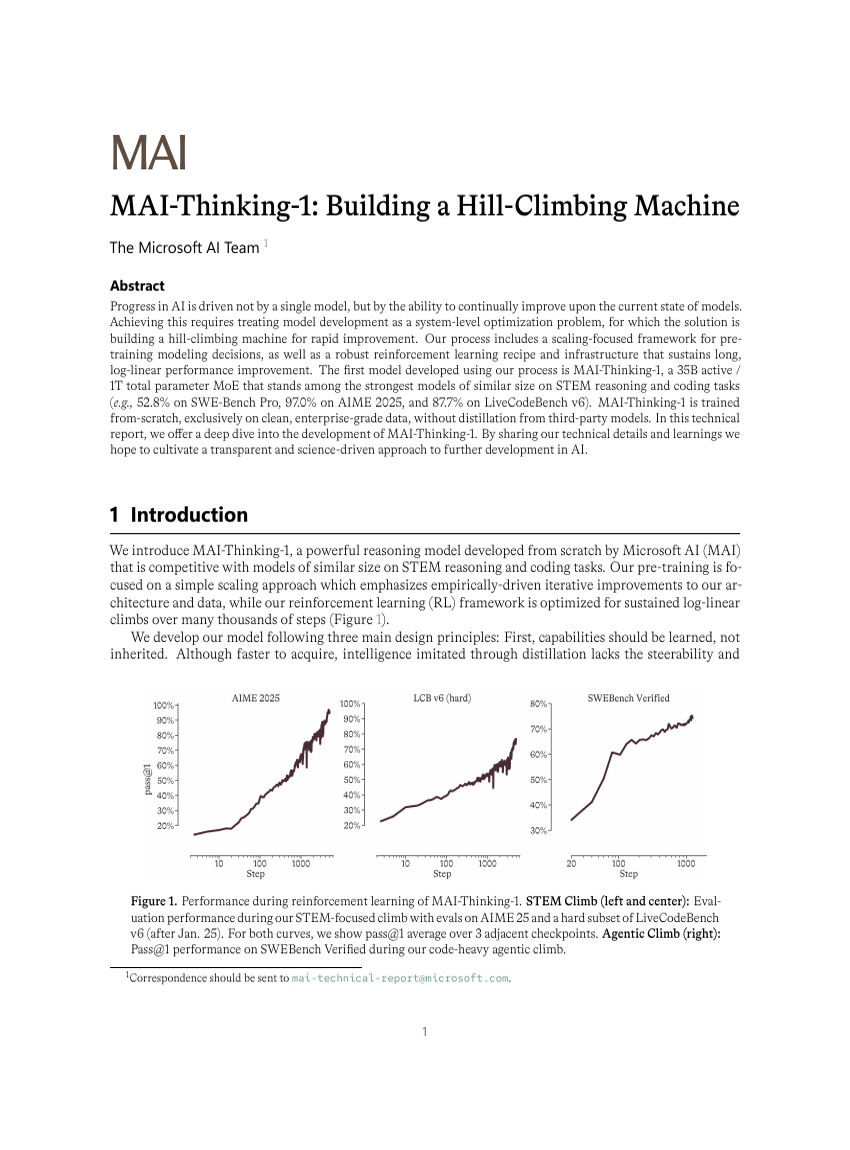
MAI-Thinking-1: Hill-Climbing 머신 구축
VLM3: 비전 언어 모델은 네이티브 3D 학습자입니다
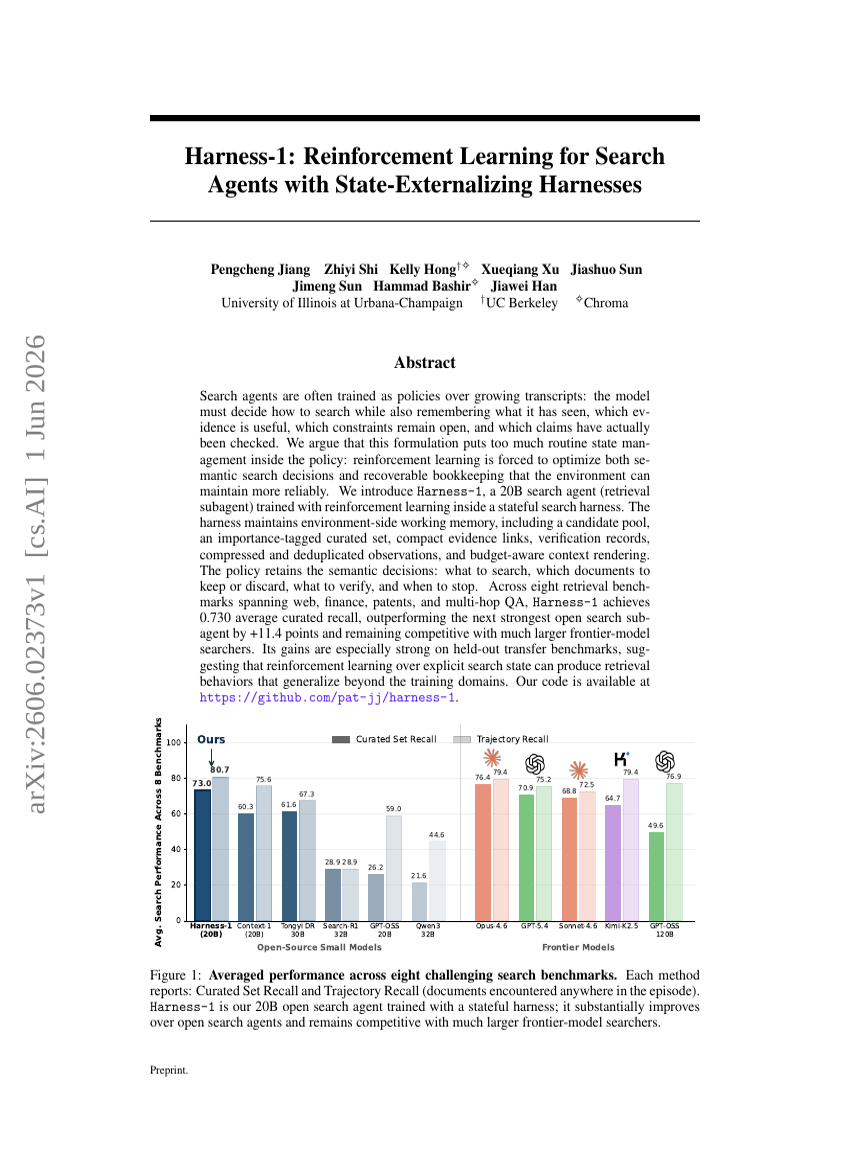
Harness-1: 상태 외부화 하네스를 활용한 검색 에이전트를 위한 강화 학습
DeepCrack: 균열 분할을 위한 심층 계층적 특징 학습 아키텍처
VideoMLA: 분 단위 자기회귀 비디오 디퓨전을 위한 저랭크 잠재 KV 캐시
Draft-OPD: 추론적 초안 모델을 위한 온-정책 증류
K-BrowseComp: 한국어 컨텍스트에 기반한 웹 브라우징 Agent 벤치마크
TASTE에 관한 문제: Agent Benchmarks의 커버리지와 난이도 향상
PEFT의 스케일링에 관하여: 조 파라미터를 갖춘 백만 개인 모델을 향해
Crafter: 다양한 입력으로부터 편집 가능한 과학적 도표 생성을 위한 Multi-Agent 하니스
TACK: 새로운 TArgeting Chimeras Knowledge 데이터셋에 대한 저해 활동의 통계적 평가
네러티브 위버: 다중 모달 조건화를 통한 제어 가능한 장기 시각적 일관성 towards
후킹 업데이트는 후킹의 이점이 아니다: 자가 진화형 LLM 에이전트에서 진화 능력을 분리하다
LongTraceRL: 검색 Agent 궤적과 평가 기준 보상을 통한 긴 문맥 추론 학습
온폴리시 증류를 위한 신뢰 영역 행동 혼합
SwanVoice: 독백과 대화 모두를 위한 표현력 있는 장문 제로샷 음성 합성
Qwen-Image-Flash: 목적 설계를 넘어
OVO-S-Bench: 멀티모달 LLMs에서의 스트리밍 공간 지능을 위한 계층적 벤치마크
기준 기반 강화 학습에서의 보상 해킹 재현, 분석 및 탐지
딥 리서치 Agents는 어디서 잘못되는가? Agent 궤적 내 스패너 수준 오류 국소화
오디오 상호작용 모델
Cosmos 3: 물리 AI를 위한 올모달 월드 모델
학습, 빠르고 느리게: 지속적 적응형 대규모 언어 모델로의 여정
LEAP: Agentic Frameworks를 활용한 대형 언어 모델의 공식 수학 수행 능력 강화
세계 모델과 언어 모델의 만남: 구체적 추론과 추상적 추론의 상호보완성에 관하여
활성화에서 인과성으로: 인간 뇌에서의 인과적 시각 표현의 발견
다중 도메인 RL에서의 도메인 간 간섭 및 복원에 대한 국소 섭동 이론
Humanoid-GPT: 제로샷 모션 트래킹을 위한 데이터 및 구조 확장
신뢰 영역 온-정책 증류
OCC-RAG: 충실한 질문 응답을 위한 최적의 인지 핵심
MAI-Thinking-1: Hill-Climbing 머신 구축
VLM3: 비전 언어 모델은 네이티브 3D 학습자입니다
Harness-1: 상태 외부화 하네스를 활용한 검색 에이전트를 위한 강화 학습
DeepCrack: 균열 분할을 위한 심층 계층적 특징 학습 아키텍처
VideoMLA: 분 단위 자기회귀 비디오 디퓨전을 위한 저랭크 잠재 KV 캐시
Draft-OPD: 추론적 초안 모델을 위한 온-정책 증류
K-BrowseComp: 한국어 컨텍스트에 기반한 웹 브라우징 Agent 벤치마크
TASTE에 관한 문제: Agent Benchmarks의 커버리지와 난이도 향상
PEFT의 스케일링에 관하여: 조 파라미터를 갖춘 백만 개인 모델을 향해
Crafter: 다양한 입력으로부터 편집 가능한 과학적 도표 생성을 위한 Multi-Agent 하니스
TACK: 새로운 TArgeting Chimeras Knowledge 데이터셋에 대한 저해 활동의 통계적 평가
네러티브 위버: 다중 모달 조건화를 통한 제어 가능한 장기 시각적 일관성 towards
후킹 업데이트는 후킹의 이점이 아니다: 자가 진화형 LLM 에이전트에서 진화 능력을 분리하다
LongTraceRL: 검색 Agent 궤적과 평가 기준 보상을 통한 긴 문맥 추론 학습
온폴리시 증류를 위한 신뢰 영역 행동 혼합
SwanVoice: 독백과 대화 모두를 위한 표현력 있는 장문 제로샷 음성 합성