HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

연성 중력 렌즈 효과를 위한 펼쳐진 Plug-and-Play ADMM을 활용한 은하 이미지 디컨볼루션

인공지능은 초인적 적응 능력을 바탕으로 특화되어 받아들여야 한다
























연성 중력 렌즈 효과를 위한 펼쳐진 Plug-and-Play ADMM을 활용한 은하 이미지 디컨볼루션
인공지능은 초인적 적응 능력을 바탕으로 특화되어 받아들여야 한다
순종형 챗봇이 이상적인 베이지안에서도 망상적 순환을 유발한다
혼돈의 대리인
HarnessX: 조립식, 적응형, 진화형 에이전트 해리스 파운드리
Orchestra-o1: 올모달 Agent 오케스트레이션
챗봇에서 디지털 동료로: 지속적 자율 AI로의 패러다임 전환
기억은 검색되는 것이 아니라 재구성된다: LLM Agents를 위한 그래프 메모리
APPO: 에이전틱 절차적 정책 최적화
OmniDirector: Cross-Paired Data 없이 일반화된 Multi-Shot 카메라 복제
InterleaveThinker: 에이전트 교차 생성을 강화하는 연구
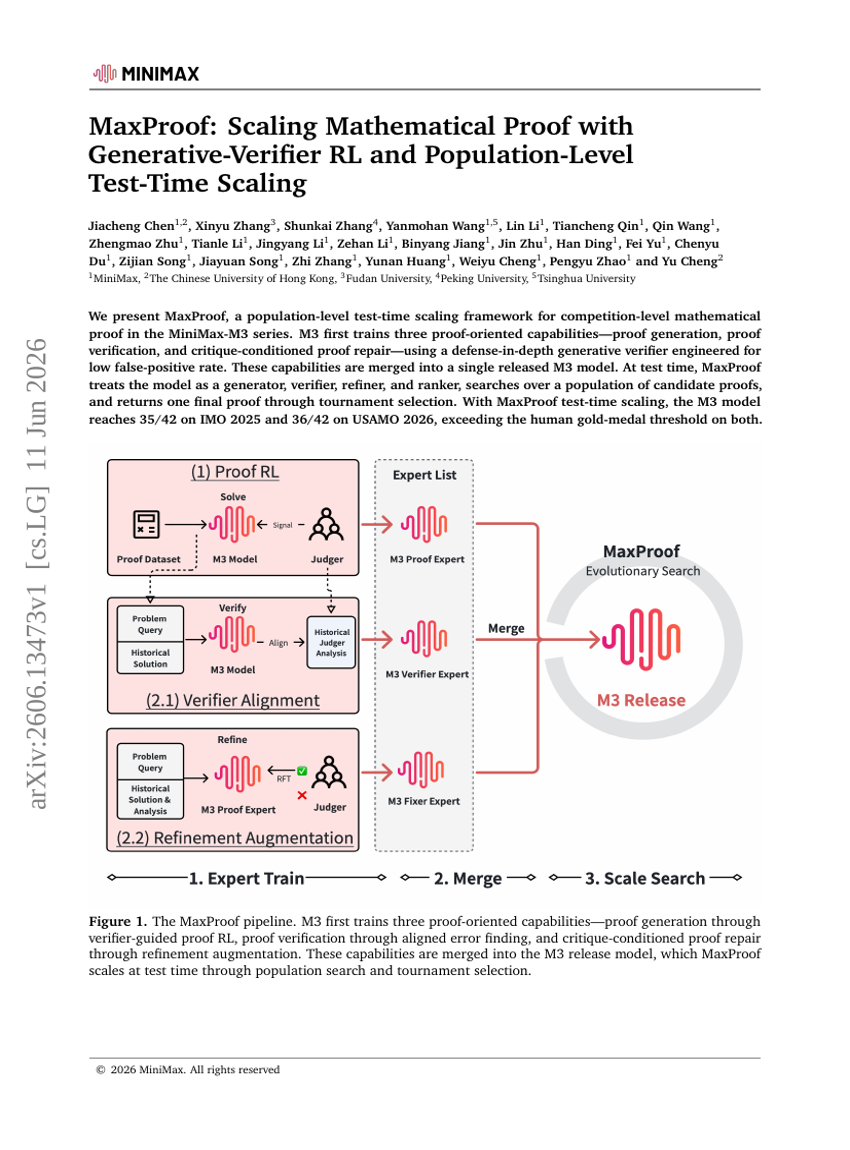
MaxProof: 생성-검증기 RL과 집단 수준 테스트 타임 스케일링을 통한 수학적 증명 확장
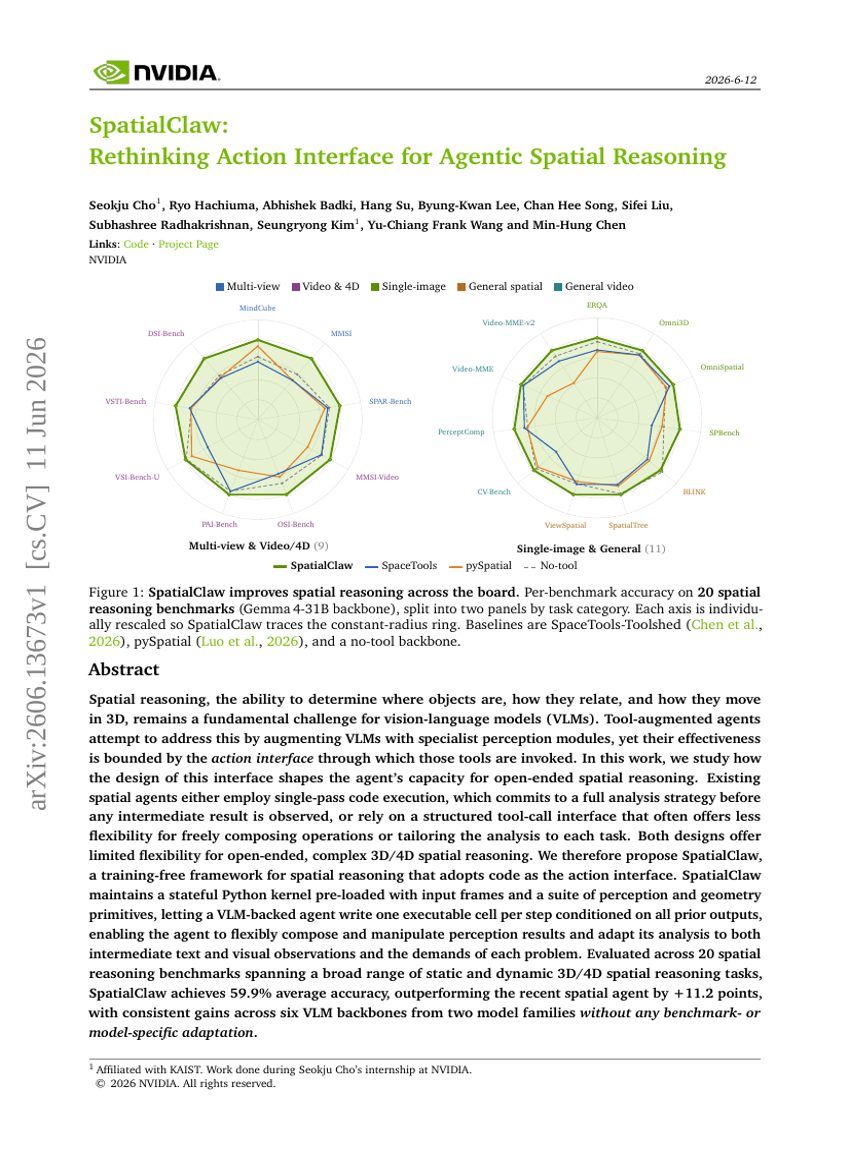
SpatialClaw: 에이전트 공간 추론을 위한 액션 인터페이스 재고찰
WEAVEBENCH: 하이브리드 인터페이스를 갖춘 컴퓨터 사용 에이전트를 위한 장기간, 현실 기반 벤치마크
MiniMax 희소 어텐션
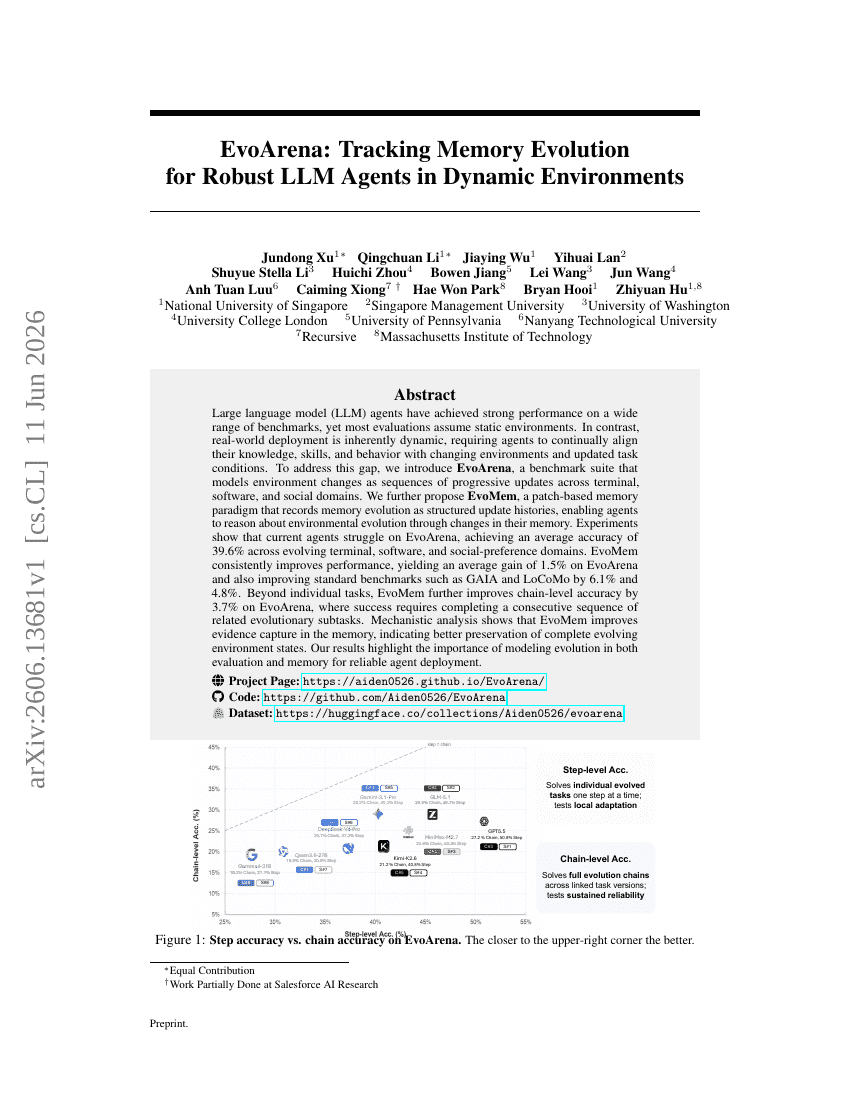
EvoArena: 동적 환경에서 강건한 LLM Agents를 위한 메모리 진화 추적
Flex4DHuman: 4D 인간 재구성을 위한 유연한 다중 뷰 비디오 확산 모델
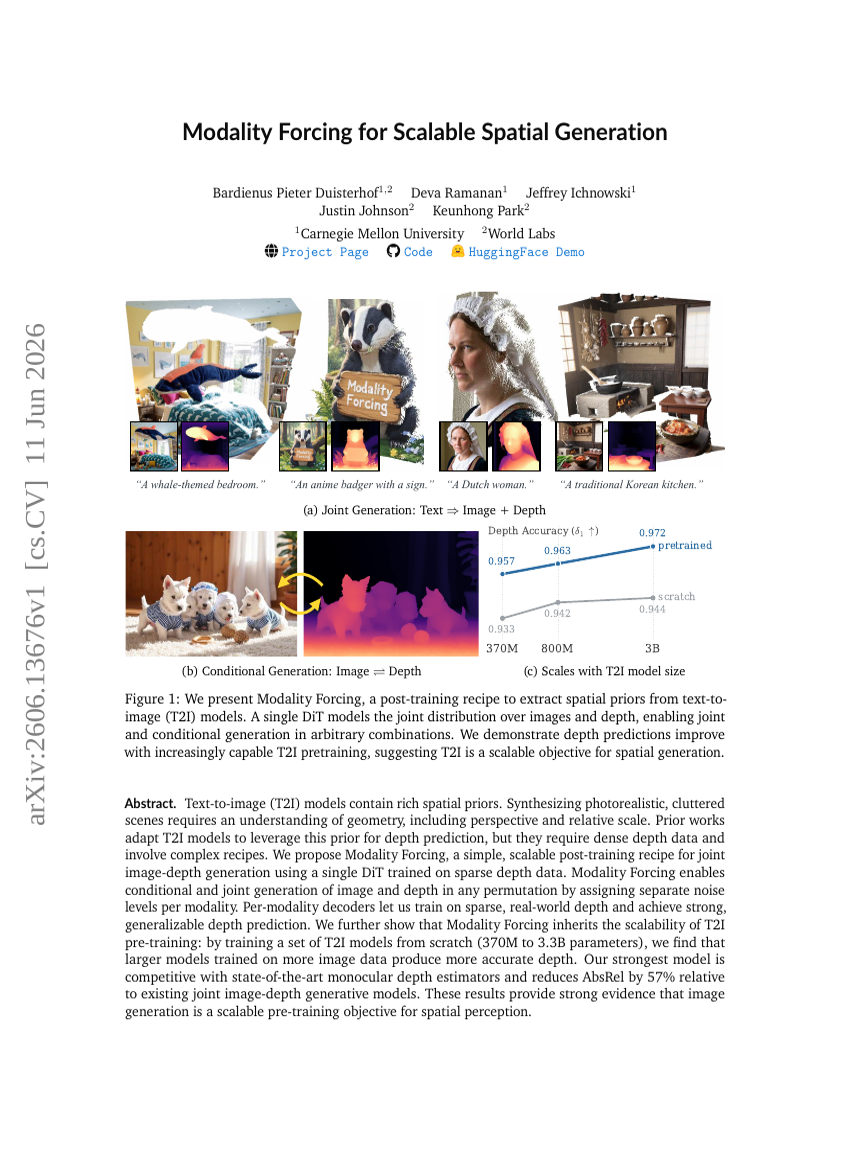
확장 가능한 공간적 생성을 위한 모달리티 강제화
AGI에서 ASI로
World Tracing: 가시 영역을 넘어선 생성형 픽셀 정합 기하학
정규화된 f-발산 커널 검정
순환 없는 순환 신경망 사전학습
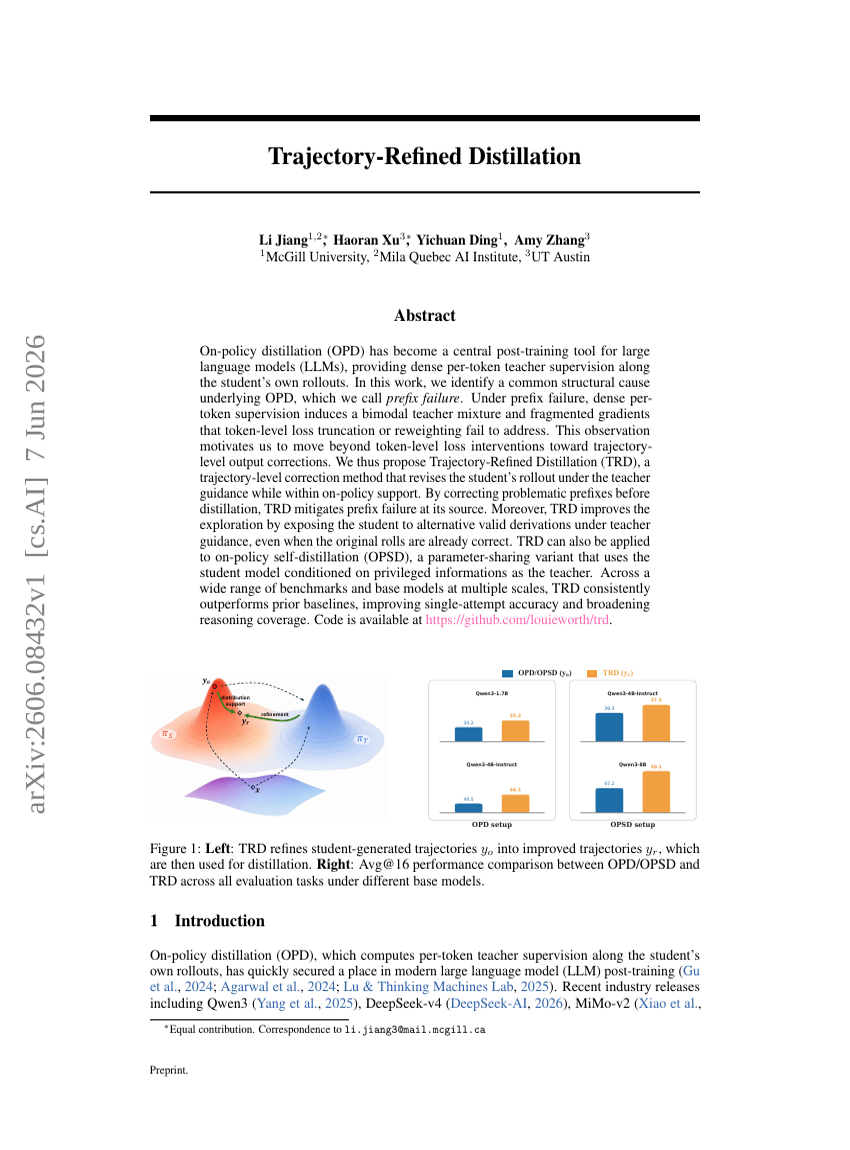
궤적 기반 정제蒸馏
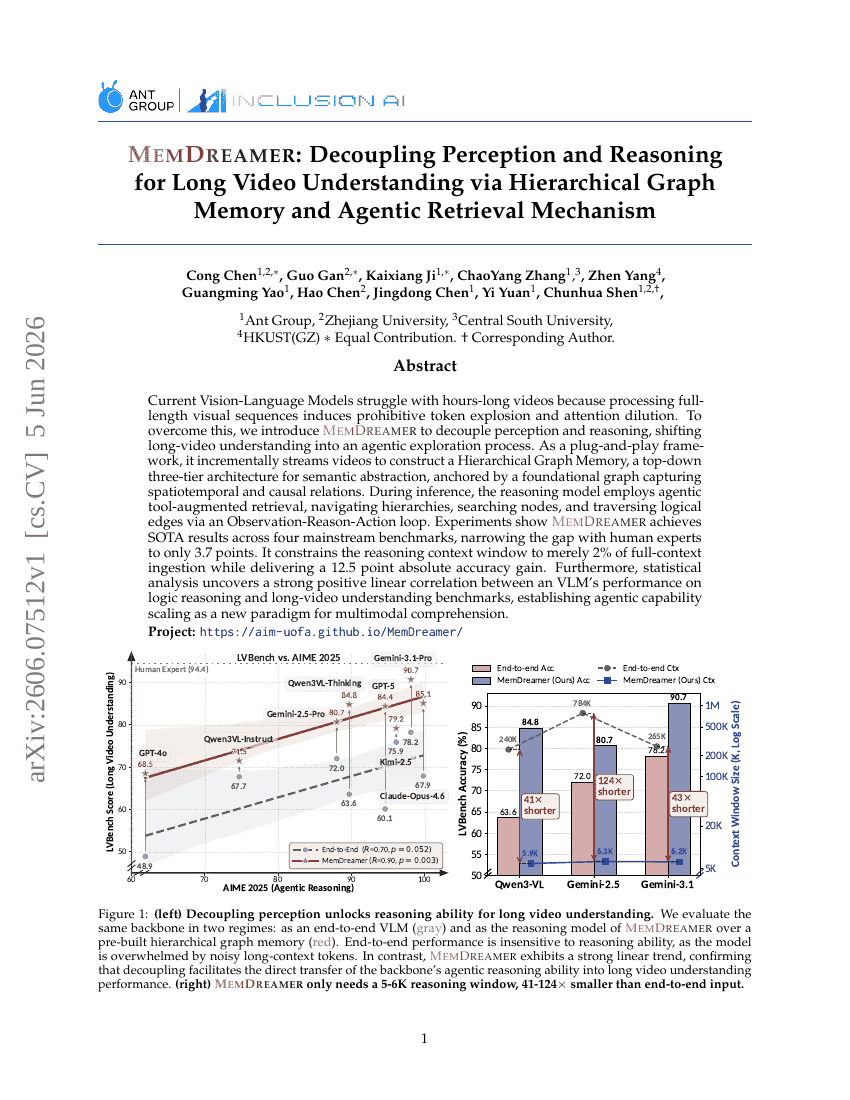
MemDreamer: 계층적 그래프 메모리 및 에이전트 검색 메커니즘을 통한 장기 비디오 이해를 위한 지각과 추론의 분리
SearchSwarm: 장기 심층 연구를 위한 에이전트 LLMs의 위임 지능을 향해
사후 하니스 최적화: 궤적 롤아웃에 대한 자기 선호를 통한 LLM Agents 개선
역할-Agents: 이중 역할 진화를 통한 LLM Agents 부트스트래핑
ABot-Earth 0.5: 생성형 3D 지구 모델
Kwai Keye-VL-2.0 기술 보고서
TESSERA: 지구 표현 및 분석을 위한 표면 스펙트럼의 시적 임베딩
만약 대형 언어 모델(LLMs)이 인간과 유사한 속성을 지닌다면, ‘에이지 오브 임파이어스 II’도 마찬가지이다.
마지막 인간이 작성한 논문: 에이전트 네이티브 연구 산출물
순종형 챗봇이 이상적인 베이지안에서도 망상적 순환을 유발한다
혼돈의 대리인
HarnessX: 조립식, 적응형, 진화형 에이전트 해리스 파운드리
Orchestra-o1: 올모달 Agent 오케스트레이션
챗봇에서 디지털 동료로: 지속적 자율 AI로의 패러다임 전환
기억은 검색되는 것이 아니라 재구성된다: LLM Agents를 위한 그래프 메모리
APPO: 에이전틱 절차적 정책 최적화
OmniDirector: Cross-Paired Data 없이 일반화된 Multi-Shot 카메라 복제
InterleaveThinker: 에이전트 교차 생성을 강화하는 연구
MaxProof: 생성-검증기 RL과 집단 수준 테스트 타임 스케일링을 통한 수학적 증명 확장
SpatialClaw: 에이전트 공간 추론을 위한 액션 인터페이스 재고찰
WEAVEBENCH: 하이브리드 인터페이스를 갖춘 컴퓨터 사용 에이전트를 위한 장기간, 현실 기반 벤치마크
MiniMax 희소 어텐션
EvoArena: 동적 환경에서 강건한 LLM Agents를 위한 메모리 진화 추적
Flex4DHuman: 4D 인간 재구성을 위한 유연한 다중 뷰 비디오 확산 모델
확장 가능한 공간적 생성을 위한 모달리티 강제화
AGI에서 ASI로
World Tracing: 가시 영역을 넘어선 생성형 픽셀 정합 기하학
정규화된 f-발산 커널 검정
순환 없는 순환 신경망 사전학습
궤적 기반 정제蒸馏
MemDreamer: 계층적 그래프 메모리 및 에이전트 검색 메커니즘을 통한 장기 비디오 이해를 위한 지각과 추론의 분리
SearchSwarm: 장기 심층 연구를 위한 에이전트 LLMs의 위임 지능을 향해
사후 하니스 최적화: 궤적 롤아웃에 대한 자기 선호를 통한 LLM Agents 개선
역할-Agents: 이중 역할 진화를 통한 LLM Agents 부트스트래핑
ABot-Earth 0.5: 생성형 3D 지구 모델
Kwai Keye-VL-2.0 기술 보고서
TESSERA: 지구 표현 및 분석을 위한 표면 스펙트럼의 시적 임베딩
만약 대형 언어 모델(LLMs)이 인간과 유사한 속성을 지닌다면, ‘에이지 오브 임파이어스 II’도 마찬가지이다.
마지막 인간이 작성한 논문: 에이전트 네이티브 연구 산출물