HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

IID를 넘어서: 표 형식 기반 모델은 실제로 얼마나 일반적인가?

ReFreeKV: 임계값 없는 KV 캐시 압축을 향하여


























IID를 넘어서: 표 형식 기반 모델은 실제로 얼마나 일반적인가?
ReFreeKV: 임계값 없는 KV 캐시 압축을 향하여
TUA-Bench: 범용 터미널 사용 에이전트를 위한 벤치마크
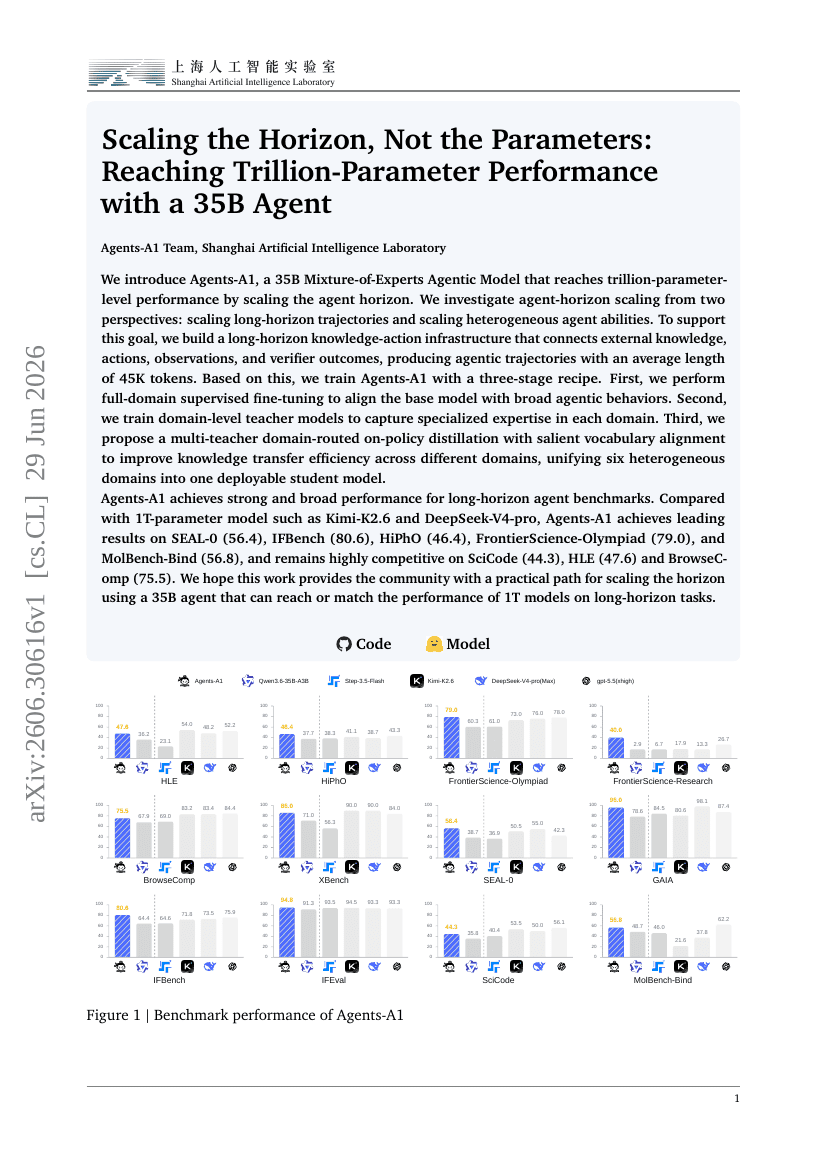
매개변수가 아닌 지평선 확장: 35B 에이전트로 1조 매개변수 성능 달성
LiveEdit: 실시간 확산 기반 스트리밍 비디오 편집을 향하여
에이전틱 절제: 에이전트는 행동 대신 멈출 때를 아는가?
EVA-Bench: 음성 에이전트 평가를 위한 새로운 엔드투엔드 프레임워크
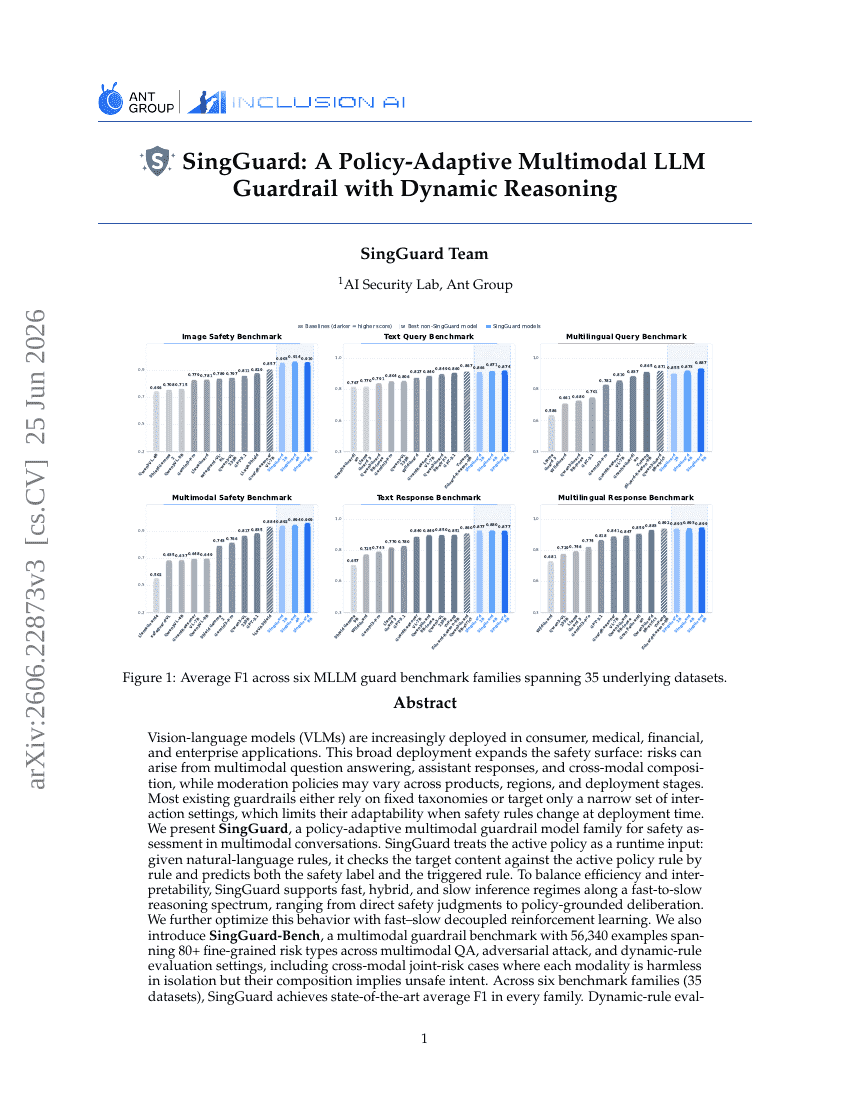
SingGuard: 동적 추론을 통한 정책 적응형 멀티모달 LLM 가드레일
잠재 사고의 형식화: LLM에서 사고 표현의 네 가지 공리
MultiHashFormer: 해시 기반 생성 언어 모델
Qwen-Image-2.0-RL 기술 보고서
연결 동작으로서의 변위: 인간에서 로봇으로 조작 기술 이전하기
PhysisForcing: 로봇 조작을 위한 물리 강화 세계 시뮬레이터
OpenTME: TCGA 기반 AI 활용 H&E 종양 미세환경 프로필의 공개 데이터셋
FlashAttention-4: 비대칭 하드웨어 확장성을 위한 알고리즘 및 커널 파이프라이닝 공동 설계
DSpark: 준자가생적 생성과 함께 신뢰도 계획적 추측 디코딩
ViQ: 임의의 해상도에서 텍스트와 정렬된 시각적 양자화 표현
검증의 지평: 코딩 agent 보상에 대한 만능 해결책은 없다
Qwen-Image-Agent: 실제 세계 이미지 생성에서 문맥 격차 해소
OPID: 에이전트 강화 학습을 위한 온-정책 스킬 증류
로봇 제어를 위한 문맥 내 월드 모델링
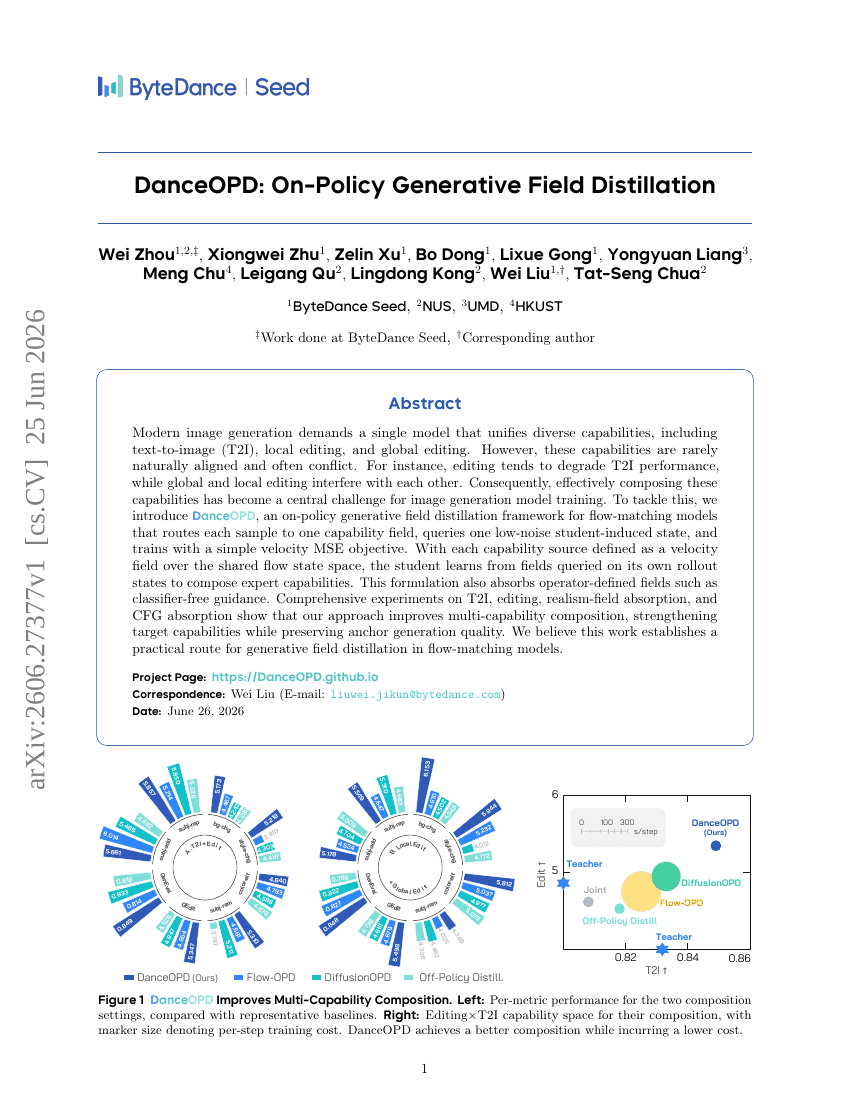
DanceOPD: 온-정책 생성 필드 증류
Autodata: 고품질 합성 데이터 생성을 위한 에이전트형 데이터 과학자
향상된 대규모 언어 확산 모델
OCR 추론은 얼마나 강건한가? 시각적 교란 하에서 시각-언어 모델의 OCR 추론 강건성 평가
RoboAtlas: 맥락적 능동 SLAM
의도 인지 장면 표현을 통한 군중 내 로봇 시각 탐색 학습
3D 케이블 구동 소프트 로봇 팔을 위한 심층 강화학습 기반 이벤트 트리거형 데이터 기반 예측 제어
자연적 언그로킹: 사전 학습에서 어떤 규칙이 생존하는지에 대한 비대칭적 제어
모든 음이 아닌 정수는 삼각수, 오각수, 칠각수의 합이다.
루프 엔지니어링: 에이전트에 프롬프트를 설계하기 위한 앤스로피의プレイ북
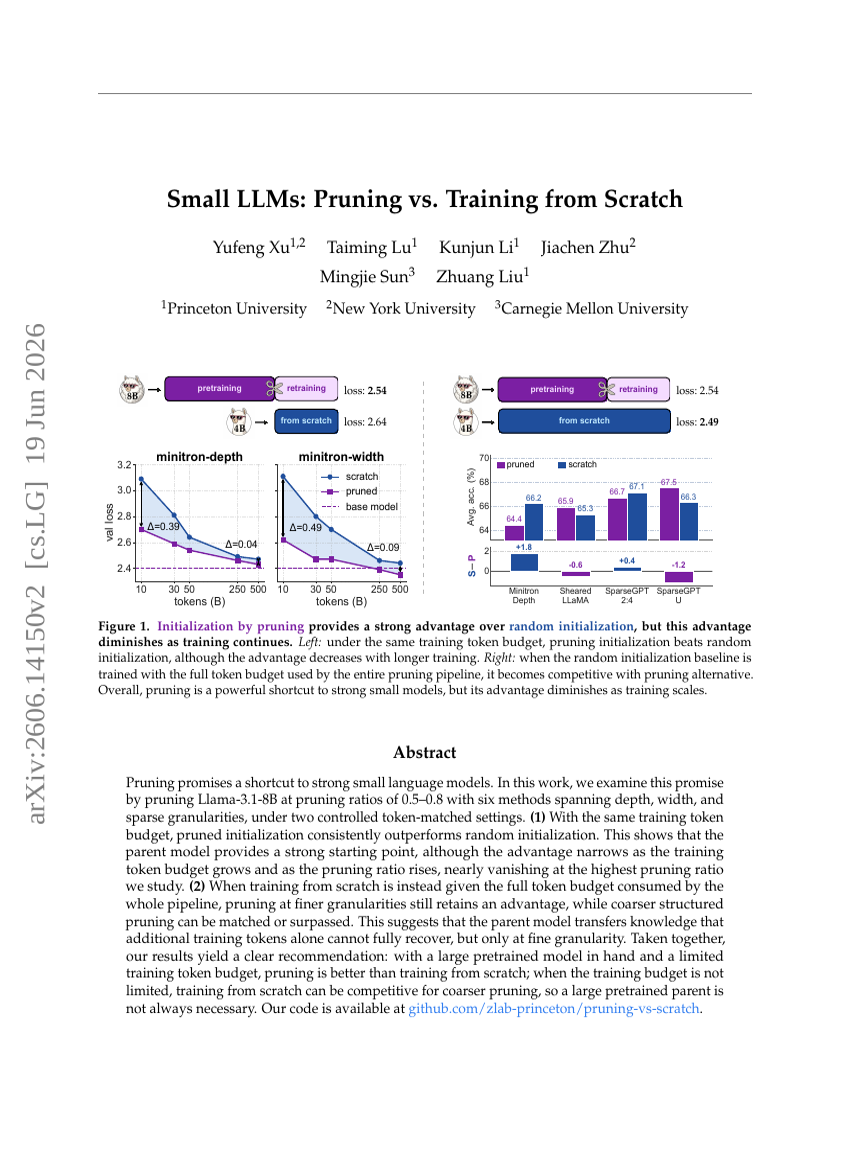
작은 LLMs: Pruning 대 Scratch부터의 Training
TUA-Bench: 범용 터미널 사용 에이전트를 위한 벤치마크
매개변수가 아닌 지평선 확장: 35B 에이전트로 1조 매개변수 성능 달성
LiveEdit: 실시간 확산 기반 스트리밍 비디오 편집을 향하여
에이전틱 절제: 에이전트는 행동 대신 멈출 때를 아는가?
EVA-Bench: 음성 에이전트 평가를 위한 새로운 엔드투엔드 프레임워크
SingGuard: 동적 추론을 통한 정책 적응형 멀티모달 LLM 가드레일
잠재 사고의 형식화: LLM에서 사고 표현의 네 가지 공리
MultiHashFormer: 해시 기반 생성 언어 모델
Qwen-Image-2.0-RL 기술 보고서
연결 동작으로서의 변위: 인간에서 로봇으로 조작 기술 이전하기
PhysisForcing: 로봇 조작을 위한 물리 강화 세계 시뮬레이터
OpenTME: TCGA 기반 AI 활용 H&E 종양 미세환경 프로필의 공개 데이터셋
FlashAttention-4: 비대칭 하드웨어 확장성을 위한 알고리즘 및 커널 파이프라이닝 공동 설계
DSpark: 준자가생적 생성과 함께 신뢰도 계획적 추측 디코딩
ViQ: 임의의 해상도에서 텍스트와 정렬된 시각적 양자화 표현
검증의 지평: 코딩 agent 보상에 대한 만능 해결책은 없다
Qwen-Image-Agent: 실제 세계 이미지 생성에서 문맥 격차 해소
OPID: 에이전트 강화 학습을 위한 온-정책 스킬 증류
로봇 제어를 위한 문맥 내 월드 모델링
DanceOPD: 온-정책 생성 필드 증류
Autodata: 고품질 합성 데이터 생성을 위한 에이전트형 데이터 과학자
향상된 대규모 언어 확산 모델
OCR 추론은 얼마나 강건한가? 시각적 교란 하에서 시각-언어 모델의 OCR 추론 강건성 평가
RoboAtlas: 맥락적 능동 SLAM
의도 인지 장면 표현을 통한 군중 내 로봇 시각 탐색 학습
3D 케이블 구동 소프트 로봇 팔을 위한 심층 강화학습 기반 이벤트 트리거형 데이터 기반 예측 제어
자연적 언그로킹: 사전 학습에서 어떤 규칙이 생존하는지에 대한 비대칭적 제어
모든 음이 아닌 정수는 삼각수, 오각수, 칠각수의 합이다.
루프 엔지니어링: 에이전트에 프롬프트를 설계하기 위한 앤스로피의プレイ북
작은 LLMs: Pruning 대 Scratch부터의 Training