HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

병목 없는 통합 멀티모달 모델을 위한 표현 강제

GrepSeek: 직접 코퍼스 상호작용을 위한 검색 Agents 학습


























병목 없는 통합 멀티모달 모델을 위한 표현 강제
GrepSeek: 직접 코퍼스 상호작용을 위한 검색 Agents 학습
COLLEAGUE.SKILL: 전문가 지식 증류를 통한 자동화된 AI 스킬 생성
에이전틱 시스템을 통한 약한 추론 모델의 성능 향상
YoCausal: 비디오 생성은 세계 모델과 얼마나 떨어져 있는가? 인과관계 관점
minWM: 실시간 상호작용 비디오 월드 모델을 위한 풀스택 오픈소스 프레임워크
CollectionLoRA: 다중 교사 온-폴리시 증류를 통해 1 LoRA에 50가지 효과 수집
OmniRetrieval: 이질적인 지식 출처 전반에 걸친 통합 검색
Qwen-VLA: 작업, 환경 및 로봇 구현체 전반에 걸친 시각-언어-행동 모델링 통합
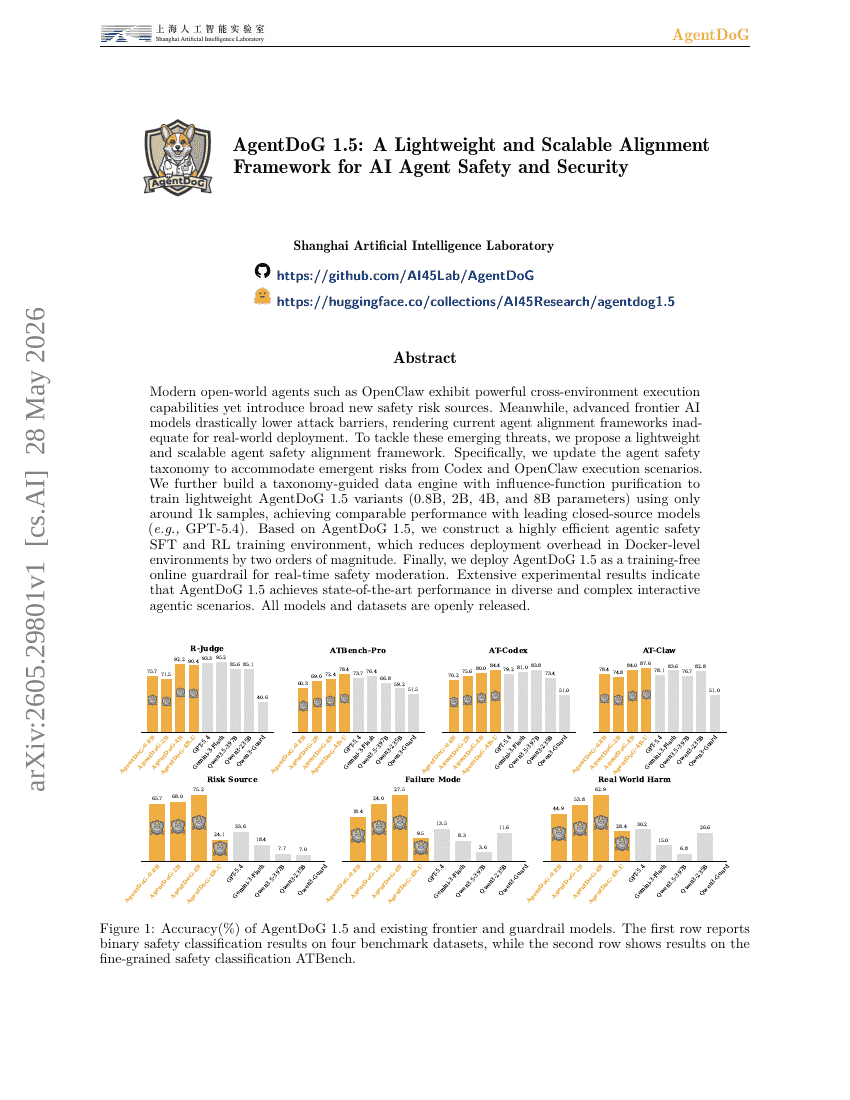
AgentDoG 1.5: AI Agent 안전성 및 보안을 위한 경량 및 확장 가능한 정렬 프레임워크
세계 행동 모델: 융합형 AI의 차세대 최전선
World Action Models는 제로샷 정책이다
ResearchMath-14K: Agents를 통한 연구 수준 수학의 확장
양방향 진화 탐색을 통한 자기 개선 언어 모델
픽셀에서 단어로 -- 대규모 네이티브 원비전 모델을 향해
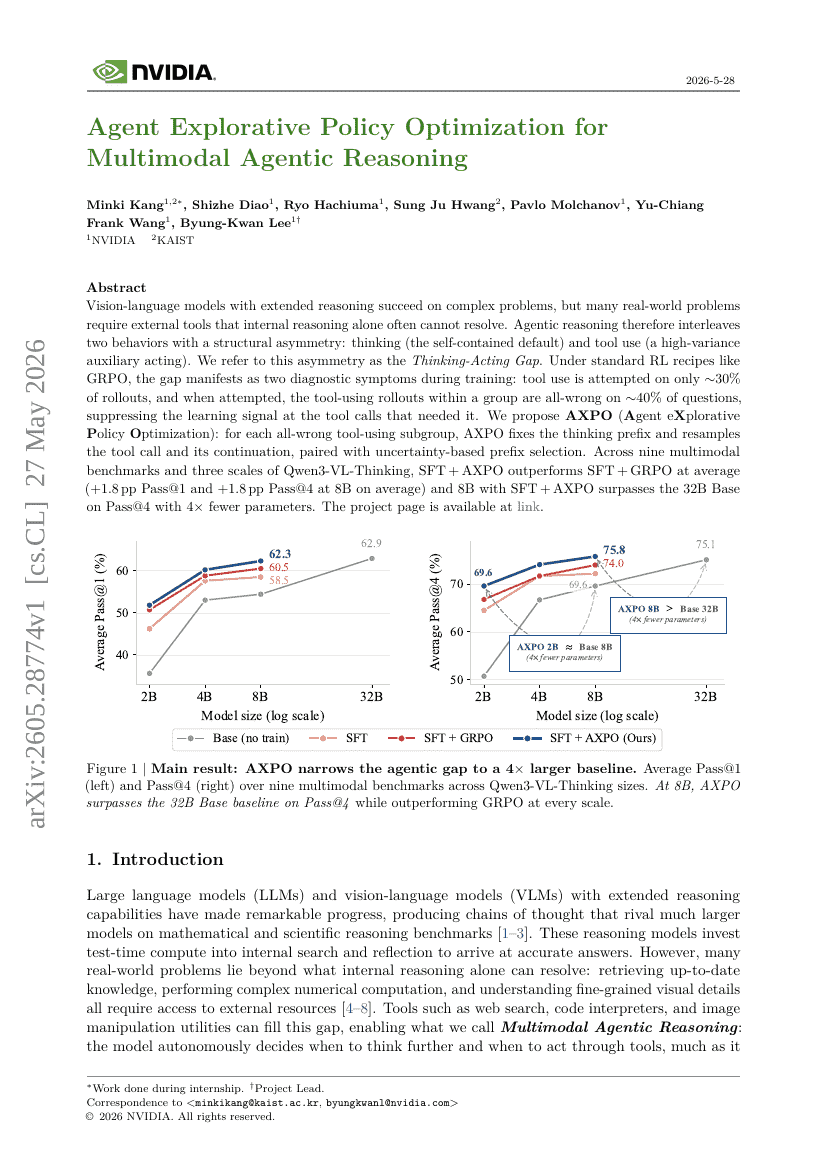
멀티모달 에이전트적 추론을 위한 Agent 탐색적 정책 최적화
ProRL: 보정된 정책 경사 추정을 통한 능동적 추천을 위한 효과적인 강화 학습
감마-월드: 두 플레이어를 넘어선 생성적 Multi-Agent 세계 모델링
AutoFigure: 출판 준비가 완료된 과학적 일러스트레이션 생성 및 개선
AutoResearch AI: 과학적 발견을 위한 AI 기반 연구 자동화 toward
에이전트 하니스 엔지니어링: 종합 조사
D^2-모니터: 주저 인식 라우팅을 통한 확산 LLM의 동적 안전 모니터링
강건한 다중 시점 3D 재구성을 위한 기하학적 인지 표현 잡음 제거
EvalVerse: 전문 시네마틱 영상 생성을 위한 파이프라인 인식 및 전문가 보정 기반 벤치마킹
MobileGym: 모바일 GUI Agent 연구를 위한 검증 가능하고 고도로 병렬화된 시뮬레이션 플랫폼
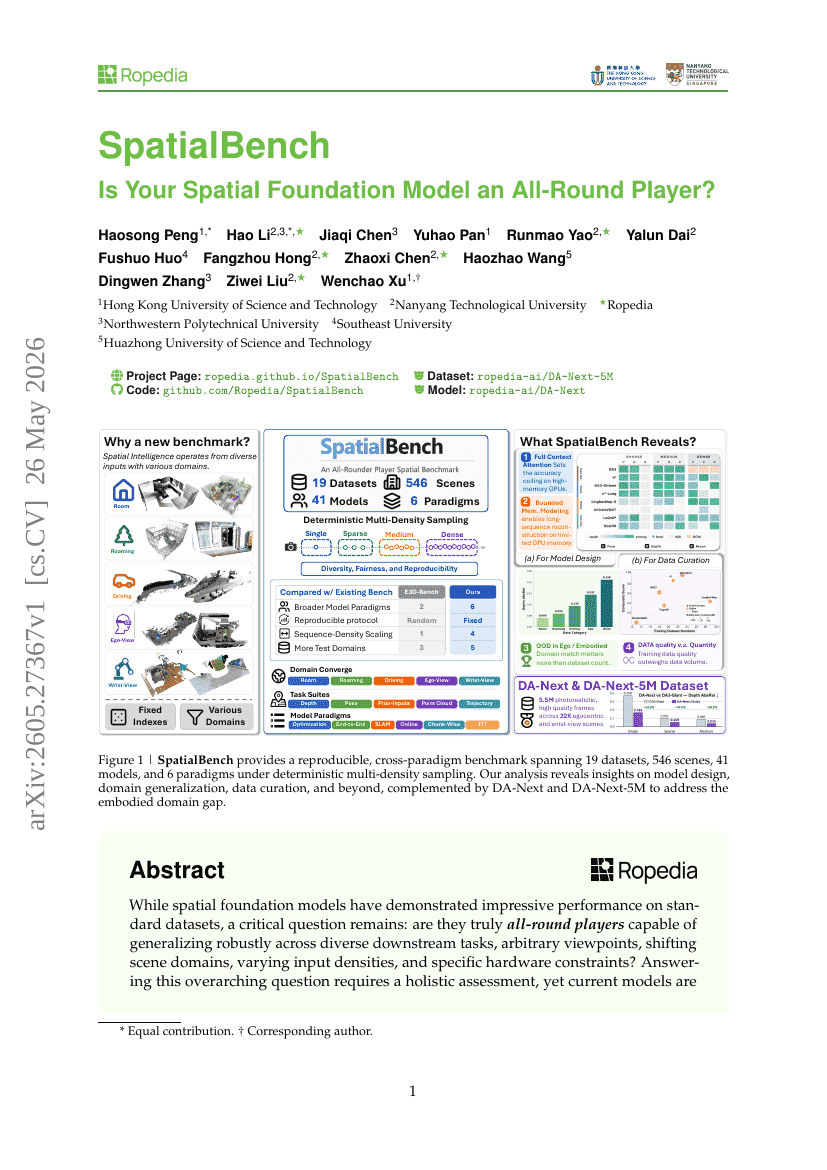
SpatialBench: 당신의 공간 파운데이션 모델은 올라운더인가?
LocateAnything: 병렬 박스 디코딩을 통한 빠르고 고품질의 비전-언어 그라운딩
Gemini Embedding 2: 제미니의 네이티브 멀티모달 임베딩 모델
언어 모델은 수면이 필요하다
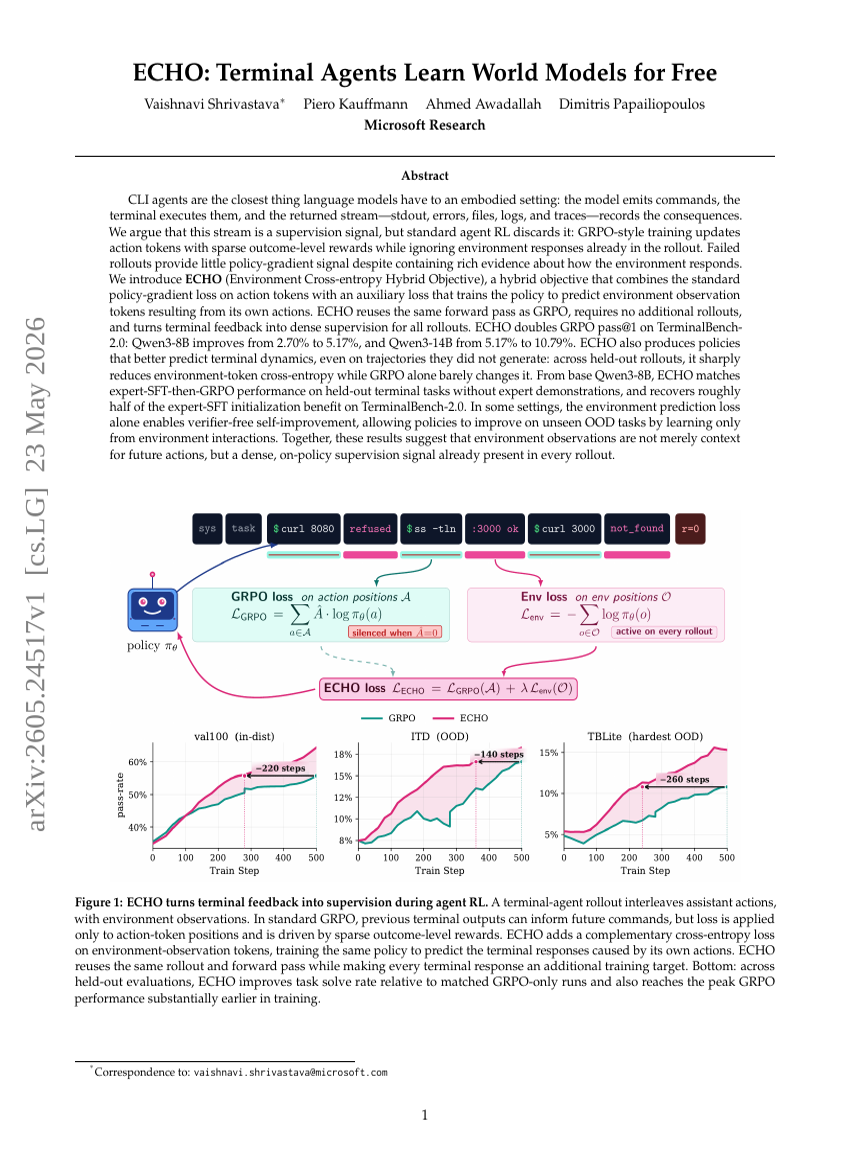
ECHO: 터미널 에이전트는 무료로 월드 모델을 학습한다
ParaVT: Agentic 비디오 강화 학습에서 병렬 도구 사용을 위한 도구 사전 역설의 통제
TriSplat: 시뮬레이션 준비가 된 순방향 3D 장면 재구성
COLLEAGUE.SKILL: 전문가 지식 증류를 통한 자동화된 AI 스킬 생성
에이전틱 시스템을 통한 약한 추론 모델의 성능 향상
YoCausal: 비디오 생성은 세계 모델과 얼마나 떨어져 있는가? 인과관계 관점
minWM: 실시간 상호작용 비디오 월드 모델을 위한 풀스택 오픈소스 프레임워크
CollectionLoRA: 다중 교사 온-폴리시 증류를 통해 1 LoRA에 50가지 효과 수집
OmniRetrieval: 이질적인 지식 출처 전반에 걸친 통합 검색
Qwen-VLA: 작업, 환경 및 로봇 구현체 전반에 걸친 시각-언어-행동 모델링 통합
AgentDoG 1.5: AI Agent 안전성 및 보안을 위한 경량 및 확장 가능한 정렬 프레임워크
세계 행동 모델: 융합형 AI의 차세대 최전선
World Action Models는 제로샷 정책이다
ResearchMath-14K: Agents를 통한 연구 수준 수학의 확장
양방향 진화 탐색을 통한 자기 개선 언어 모델
픽셀에서 단어로 -- 대규모 네이티브 원비전 모델을 향해
멀티모달 에이전트적 추론을 위한 Agent 탐색적 정책 최적화
ProRL: 보정된 정책 경사 추정을 통한 능동적 추천을 위한 효과적인 강화 학습
감마-월드: 두 플레이어를 넘어선 생성적 Multi-Agent 세계 모델링
AutoFigure: 출판 준비가 완료된 과학적 일러스트레이션 생성 및 개선
AutoResearch AI: 과학적 발견을 위한 AI 기반 연구 자동화 toward
에이전트 하니스 엔지니어링: 종합 조사
D^2-모니터: 주저 인식 라우팅을 통한 확산 LLM의 동적 안전 모니터링
강건한 다중 시점 3D 재구성을 위한 기하학적 인지 표현 잡음 제거
EvalVerse: 전문 시네마틱 영상 생성을 위한 파이프라인 인식 및 전문가 보정 기반 벤치마킹
MobileGym: 모바일 GUI Agent 연구를 위한 검증 가능하고 고도로 병렬화된 시뮬레이션 플랫폼
SpatialBench: 당신의 공간 파운데이션 모델은 올라운더인가?
LocateAnything: 병렬 박스 디코딩을 통한 빠르고 고품질의 비전-언어 그라운딩
Gemini Embedding 2: 제미니의 네이티브 멀티모달 임베딩 모델
언어 모델은 수면이 필요하다
ECHO: 터미널 에이전트는 무료로 월드 모델을 학습한다
ParaVT: Agentic 비디오 강화 학습에서 병렬 도구 사용을 위한 도구 사전 역설의 통제
TriSplat: 시뮬레이션 준비가 된 순방향 3D 장면 재구성