HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

파운데이션 프로토콜: 에이전트 사회를 위한 조정 계층

WBench: 상호작용형 비디오 월드 모델 평가를 위한 포괄적인 다중 턴 벤치마크

























파운데이션 프로토콜: 에이전트 사회를 위한 조정 계층
WBench: 상호작용형 비디오 월드 모델 평가를 위한 포괄적인 다중 턴 벤치마크
Macaron-A2UI: 개인 에이전트에서의 생성형 UI를 위한 모델
DVAO: 다중 보상 강화 학습을 위한 동적 분산 적응형 이점 최적화
ViMU: 비디오 은유적 이해benchmarking
SMOL: 115개 미표현 언어를 위한 전문적으로 번역된 병렬 데이터
Chi-Bench: AI 에이전트가 종단적, 장기적, 정책 기반 의료 워크플로우를 자동화할 수 있는가?
대규모 언어 모델의 긴 맥락 추론을 위한 온-정책 최적화 및 증류 통합
단서의 시선: VLM에서의 자기 개선적 시각적 추론
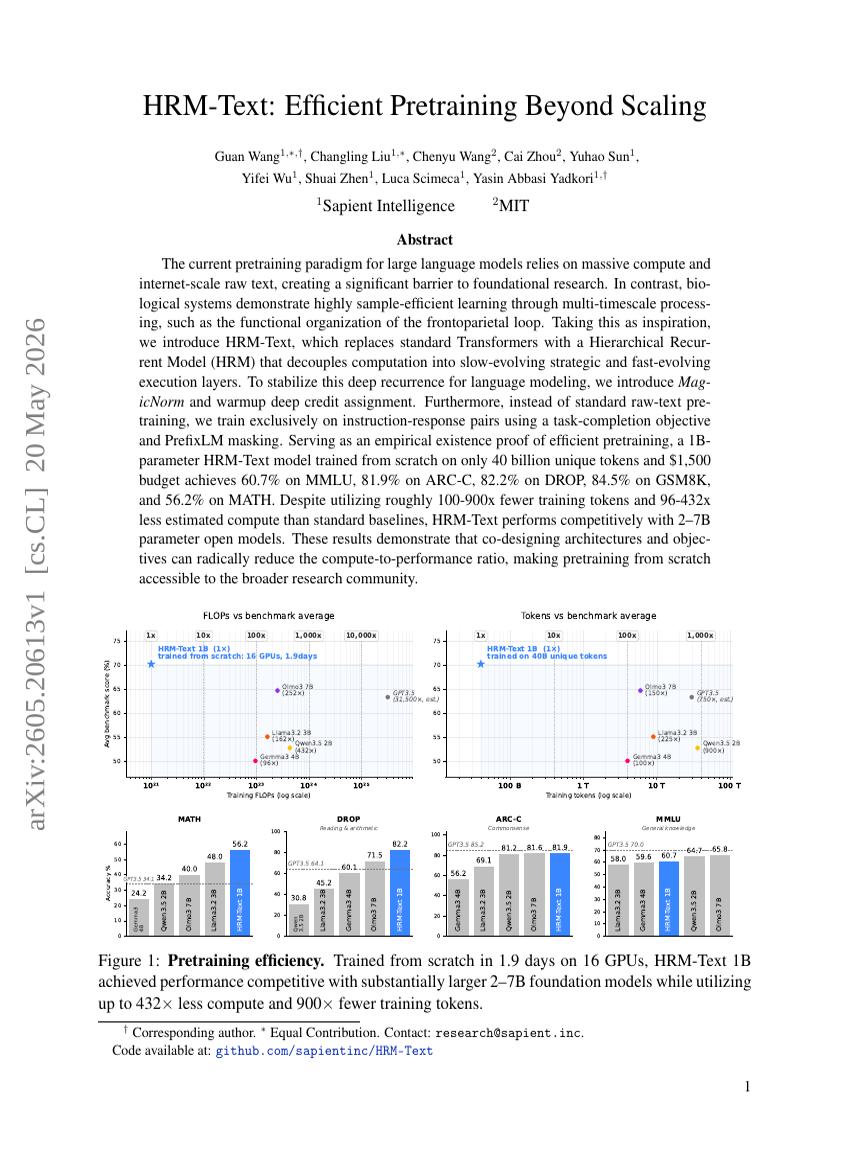
HRM-Text: 규모 확장 이상의 효율적 사전 학습
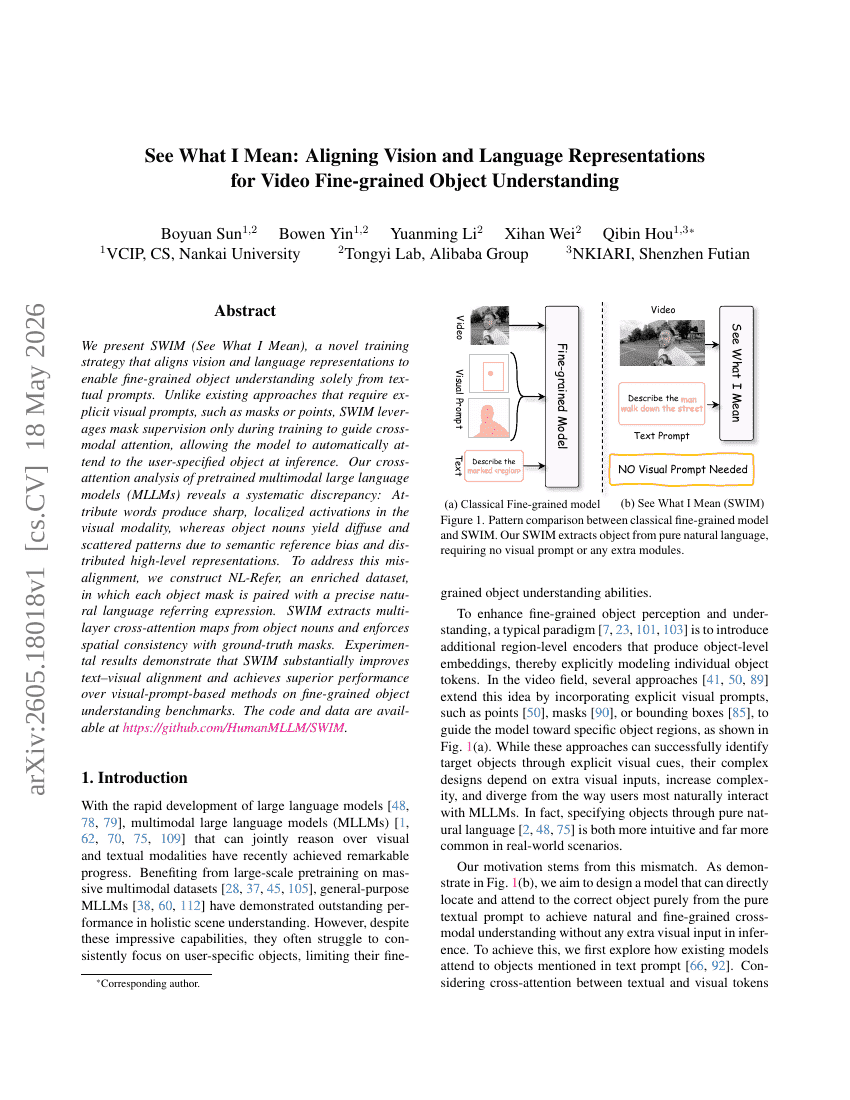
내가 무엇을 의미하는지 보라: 비디오의 세분화된 객체 이해를 위해 시각 및 언어 표현 정렬하기
StepAudio 2.5 기술 보고서
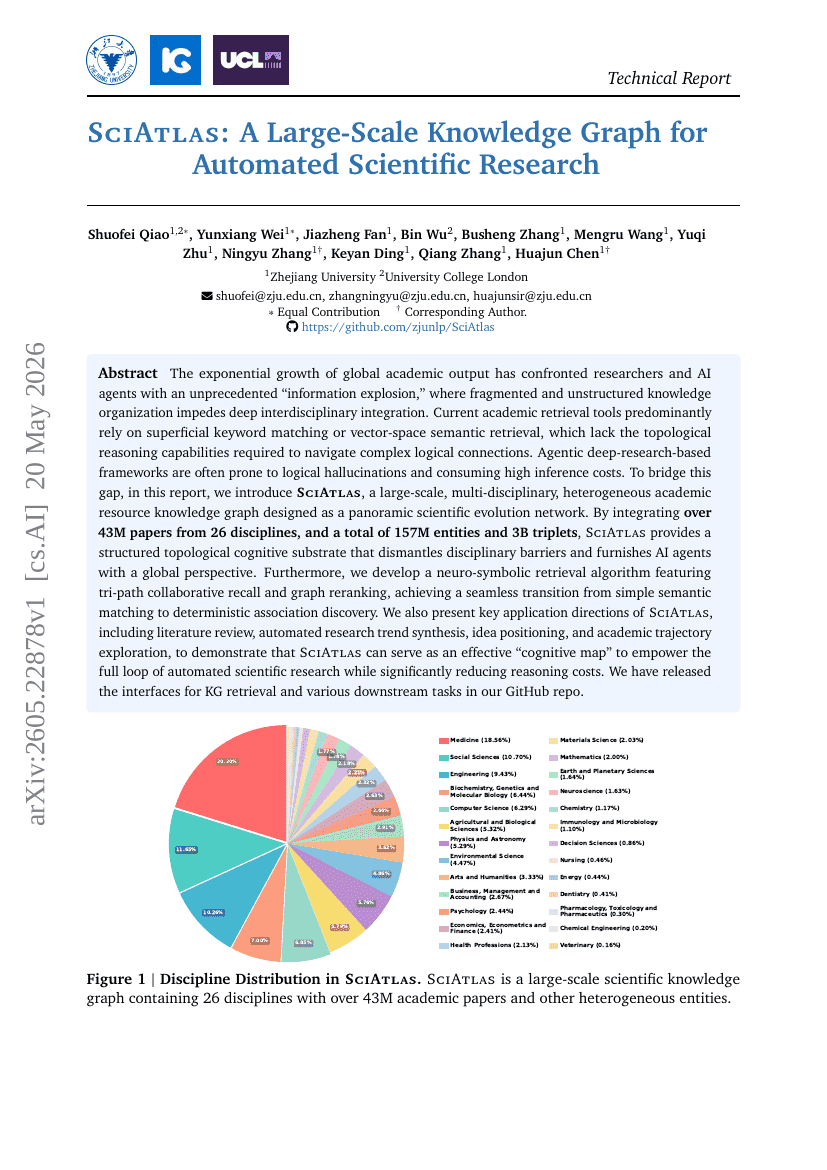
SciAtlas: 자동화된 과학 연구를 위한 대규모 지식 그래프
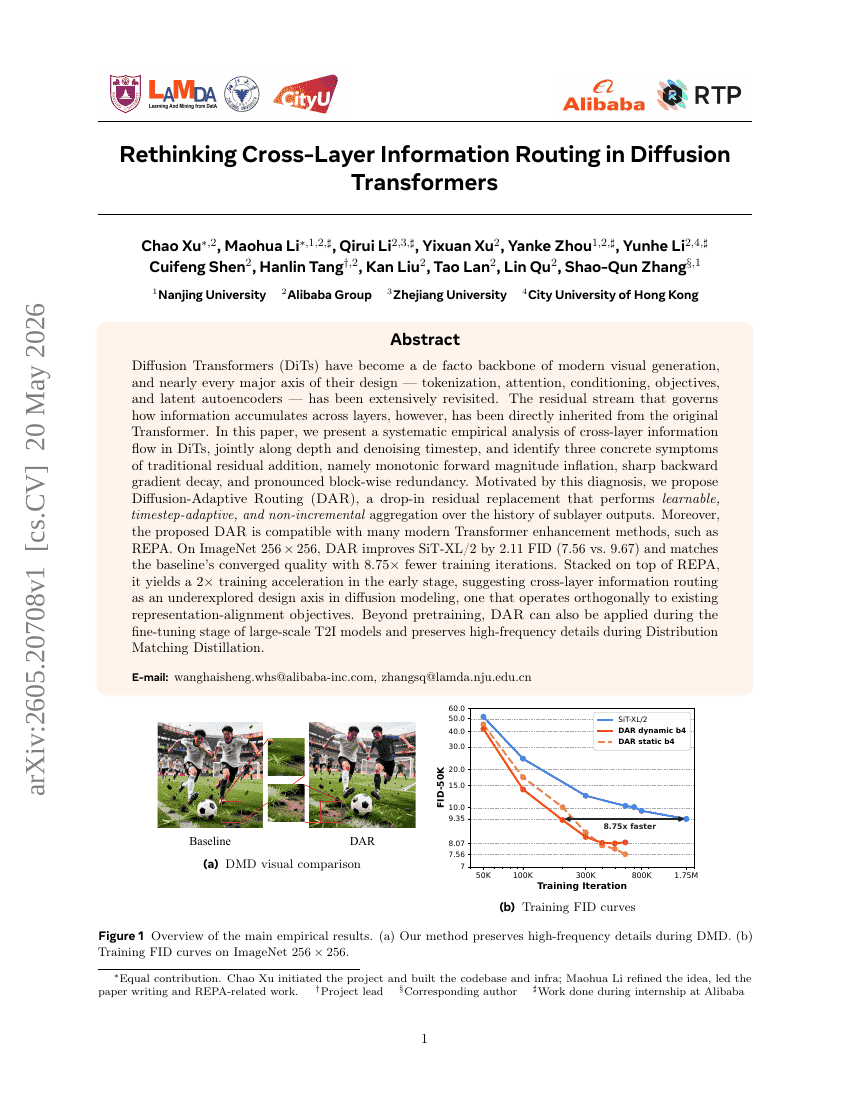
디퓨전 트랜스포머에서 크로스 레이어 정보 라우팅 재고찰
렌즈: 기반 텍스트-이미지 모델의 학습 효율성에 대한 재고찰
SkillOpt: 자기 진화형 에이전트 스킬을 위한 실행 전략
CVEvolve: 구조화되지 않은 과학적 데이터 처리를 위한 자율적 알고리즘 발견
Poly-EPO: 탐색적 추론 모델 학습
요약
ACC: 장기 컨텍스트 학습을 위한 에이전트 궤적 컴파일링
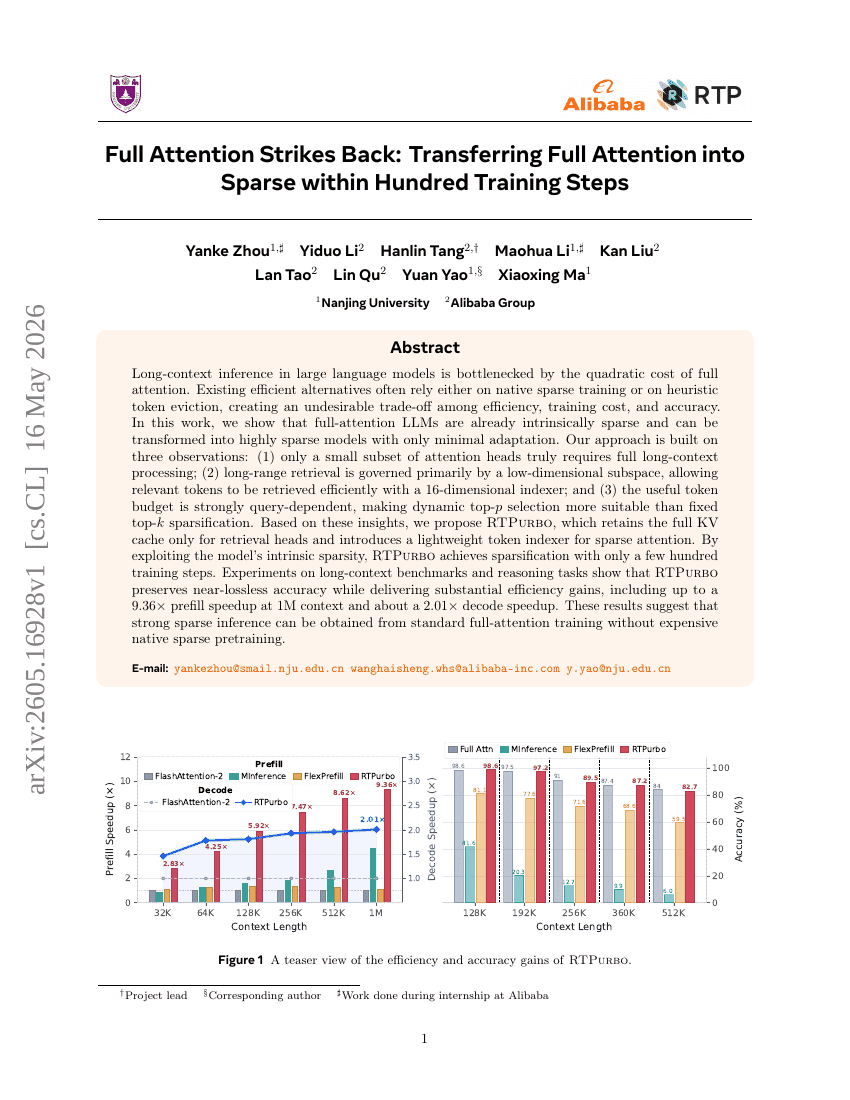
풀 어텐션이 다시 돌아온다: 수백 개의 학습 단계 내에서 풀 어텐션을 스파스 어텐션으로 이전하기
π-Bench: 장기 워크플로우에서 능동적 개인 비서 에이전트 평가
지각인지 편견인지: MLLM은 성격에 대한 첫인상을 넘어설 수 있는가?
TransitLM: 지도 없는 대중교통 경로 생성을 위한 대규모 데이터셋 및 벤치마크
DelTA: 검증 가능한 보상으로부터의 강화학습을 위한 판별적 토큰 크레딧 할당
상호작용적 평가에는 디자인 과학이 필요하다
ESI-BENCH: 지각-행동 루프를 완성하는 embodied 공간 지능을 향해
다중 시각 스펙트럼을 통한 드론 영상을 활용한 군사 목표물 탐지의 비교 분석
정신과 진단의 자동화된 ICD 분류: 고전적 NLP에서 대규모 언어 모델까지
커뮤니티 IBR의 잔여 용량을 활용한 배전 시스템에서의 조정된 최적 전력 품질 관리
EllipseLIO: 타원체 표현을 활용한 적응형 라이다 관성 오도메트리
SMoA: 파라미터 효율적 파인튜닝을 위한 스펙트럼 변조 어댑터
Macaron-A2UI: 개인 에이전트에서의 생성형 UI를 위한 모델
DVAO: 다중 보상 강화 학습을 위한 동적 분산 적응형 이점 최적화
ViMU: 비디오 은유적 이해benchmarking
SMOL: 115개 미표현 언어를 위한 전문적으로 번역된 병렬 데이터
Chi-Bench: AI 에이전트가 종단적, 장기적, 정책 기반 의료 워크플로우를 자동화할 수 있는가?
대규모 언어 모델의 긴 맥락 추론을 위한 온-정책 최적화 및 증류 통합
단서의 시선: VLM에서의 자기 개선적 시각적 추론
HRM-Text: 규모 확장 이상의 효율적 사전 학습
내가 무엇을 의미하는지 보라: 비디오의 세분화된 객체 이해를 위해 시각 및 언어 표현 정렬하기
StepAudio 2.5 기술 보고서
SciAtlas: 자동화된 과학 연구를 위한 대규모 지식 그래프
디퓨전 트랜스포머에서 크로스 레이어 정보 라우팅 재고찰
렌즈: 기반 텍스트-이미지 모델의 학습 효율성에 대한 재고찰
SkillOpt: 자기 진화형 에이전트 스킬을 위한 실행 전략
CVEvolve: 구조화되지 않은 과학적 데이터 처리를 위한 자율적 알고리즘 발견
Poly-EPO: 탐색적 추론 모델 학습
요약
ACC: 장기 컨텍스트 학습을 위한 에이전트 궤적 컴파일링
풀 어텐션이 다시 돌아온다: 수백 개의 학습 단계 내에서 풀 어텐션을 스파스 어텐션으로 이전하기
π-Bench: 장기 워크플로우에서 능동적 개인 비서 에이전트 평가
지각인지 편견인지: MLLM은 성격에 대한 첫인상을 넘어설 수 있는가?
TransitLM: 지도 없는 대중교통 경로 생성을 위한 대규모 데이터셋 및 벤치마크
DelTA: 검증 가능한 보상으로부터의 강화학습을 위한 판별적 토큰 크레딧 할당
상호작용적 평가에는 디자인 과학이 필요하다
ESI-BENCH: 지각-행동 루프를 완성하는 embodied 공간 지능을 향해
다중 시각 스펙트럼을 통한 드론 영상을 활용한 군사 목표물 탐지의 비교 분석
정신과 진단의 자동화된 ICD 분류: 고전적 NLP에서 대규모 언어 모델까지
커뮤니티 IBR의 잔여 용량을 활용한 배전 시스템에서의 조정된 최적 전력 품질 관리
EllipseLIO: 타원체 표현을 활용한 적응형 라이다 관성 오도메트리
SMoA: 파라미터 효율적 파인튜닝을 위한 스펙트럼 변조 어댑터