HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
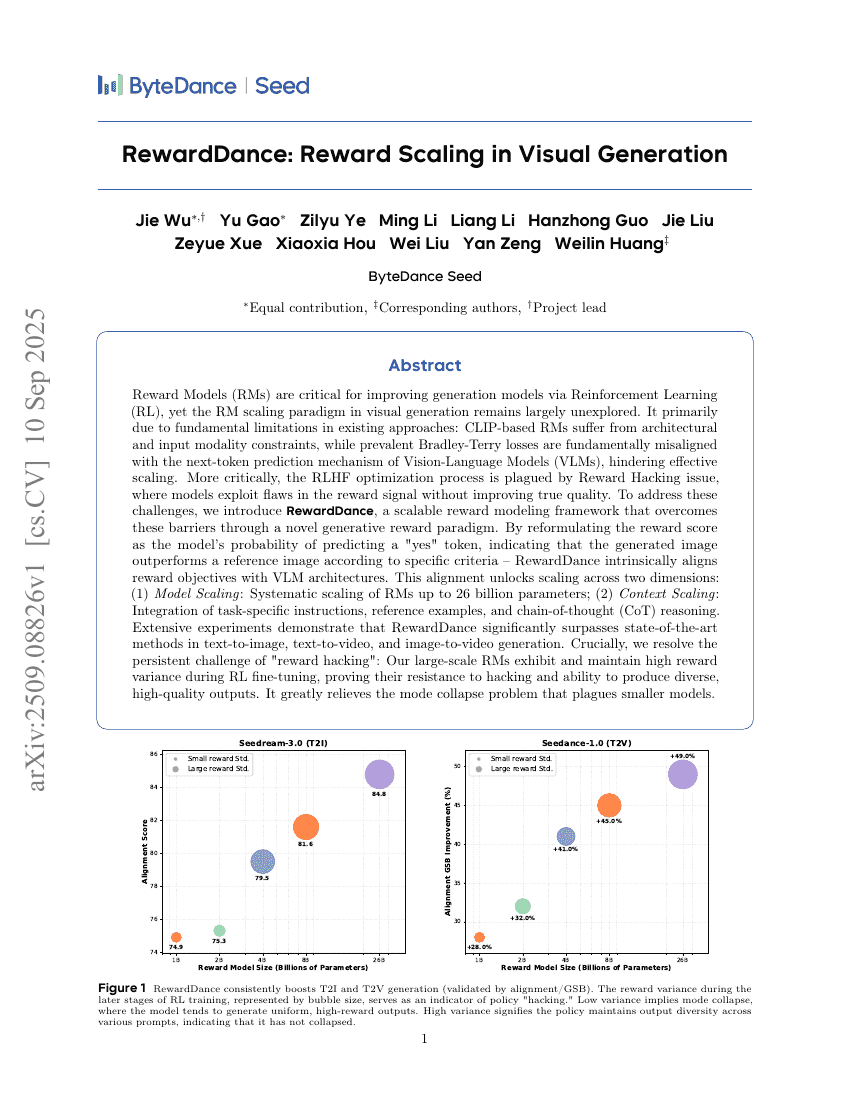
RewardDance:視覚生成におけるリワードスケーリング

共有はケアを生む:集団強化学習による効率的な言語モデル後期訓練















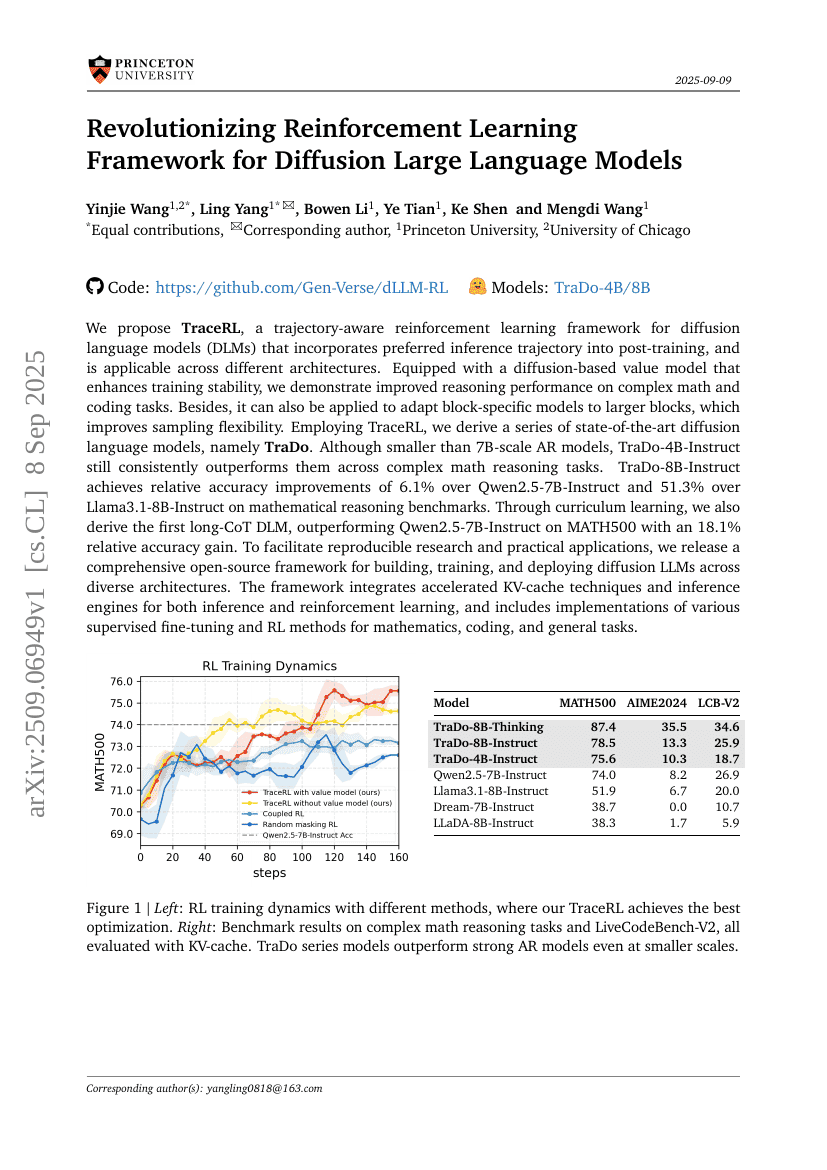













RewardDance:視覚生成におけるリワードスケーリング
共有はケアを生む:集団強化学習による効率的な言語モデル後期訓練
FinReflectKG:金融知識グラフのエージェント型構築と評価
大規模推論モデルにおける強化学習のサーベイ
過剰依存の測定と軽減は、人間と調和するAIを構築するために不可欠である
F1:理解と生成を行動へとつなぐ視覚言語行動モデル
UMO:マッチング報酬を用いた画像カスタマイズにおける多様なアイデンティティの一貫性拡張
再構成アライメントが統合型マルチモーダルモデルを改善する
Mini-o3:視覚検索における推論パターンおよび対話ターンのスケーリングアップ
マルチモーダル大規模言語モデルにおける視覚的表現のアライメント
Parallel-R1:強化学習を活用した並列的思考の実現へ
WenetSpeech-Yue:多次元アノテーションを備えた大規模広東語音声コーパス
SheetDesigner:ルールベースおよびビジョンベースのリフレクションを活用したMLLM駆動型スプレッドシートレイアウト生成
自律的コード進化がNP完全性に直面する
深層研究システムのための強化学習の基礎:サーベイ
ツールを用いた強化された視覚的認識
DINOv3は新たな医療分野のビジョン基準を設定するか?
拡散大規模言語モデル向け強化学習フレームワークの革新
WebExplorer:長期ホライズンWebエージェントの訓練のための探索と進化
逆工程的手法による開放型生成のための推論
OSC:マルチエージェントLLM協働における動的知識整合による認知オーケストレーション
CURE:ロバストな埋め込みのための制御された忘却――事前学習された言語モデルにおける概念的ショートカットの軽減
MedVista3D:3次元CT疾患検出、理解および報告における診断エラー低減のための視覚言語モデリング
LuxDiT:ビデオ拡散トランスフォーマーを用いた照明推定
WildScore:現実世界における記号音楽推論のためのMLLMsベンチマーク
セットブロックデコードは言語モデル推論を高速化するアクセラレータである。
大規模言語モデルを用いた記号的グラフィカルプログラミング
言語モデルが幻覚を生じる理由
LatticeWorld:マルチモーダル大規模言語モデルを活用したインタラクティブな複雑な世界生成フレームワーク
Recomposer:イベントロール誘導型の生成音声編集
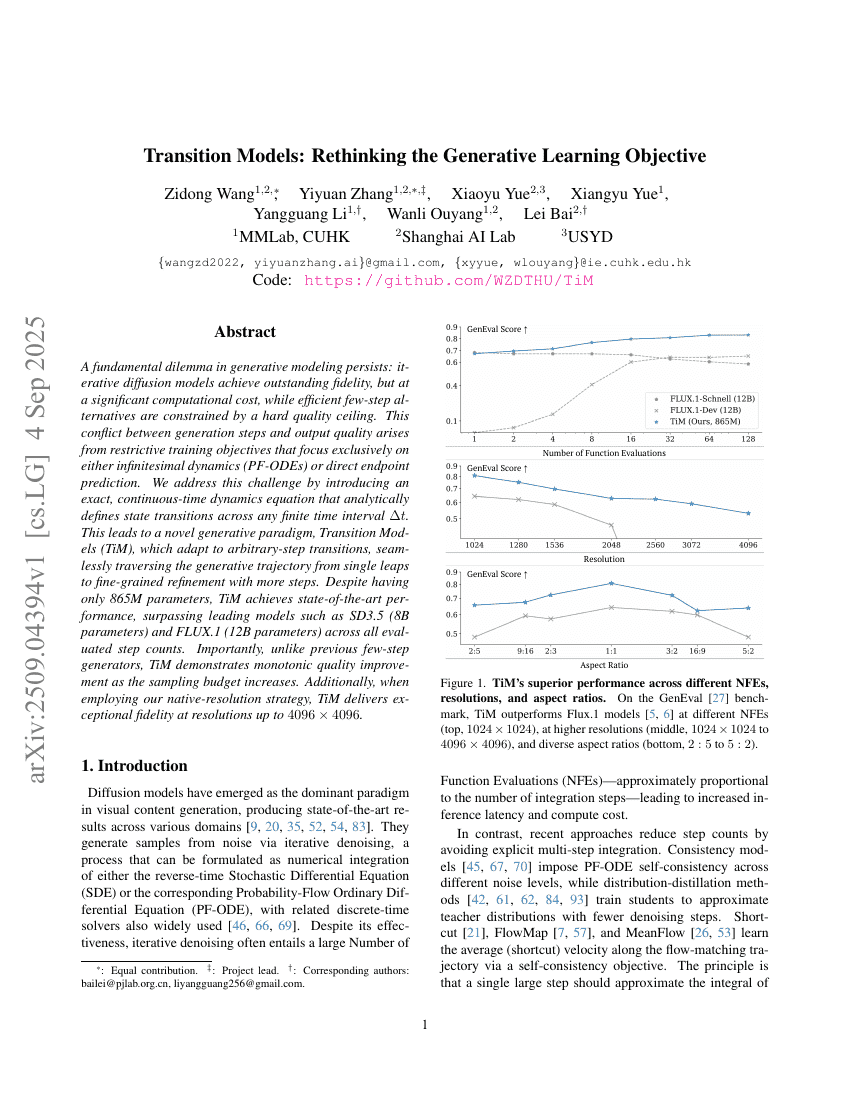
遷移モデル:生成学習目的の再考
逆IIFEval:大規模言語モデルは、根強い学習規則を忘れて本物の指示に従うことができるか?
FinReflectKG:金融知識グラフのエージェント型構築と評価
大規模推論モデルにおける強化学習のサーベイ
過剰依存の測定と軽減は、人間と調和するAIを構築するために不可欠である
F1:理解と生成を行動へとつなぐ視覚言語行動モデル
UMO:マッチング報酬を用いた画像カスタマイズにおける多様なアイデンティティの一貫性拡張
再構成アライメントが統合型マルチモーダルモデルを改善する
Mini-o3:視覚検索における推論パターンおよび対話ターンのスケーリングアップ
マルチモーダル大規模言語モデルにおける視覚的表現のアライメント
Parallel-R1:強化学習を活用した並列的思考の実現へ
WenetSpeech-Yue:多次元アノテーションを備えた大規模広東語音声コーパス
SheetDesigner:ルールベースおよびビジョンベースのリフレクションを活用したMLLM駆動型スプレッドシートレイアウト生成
自律的コード進化がNP完全性に直面する
深層研究システムのための強化学習の基礎:サーベイ
ツールを用いた強化された視覚的認識
DINOv3は新たな医療分野のビジョン基準を設定するか?
拡散大規模言語モデル向け強化学習フレームワークの革新
WebExplorer:長期ホライズンWebエージェントの訓練のための探索と進化
逆工程的手法による開放型生成のための推論
OSC:マルチエージェントLLM協働における動的知識整合による認知オーケストレーション
CURE:ロバストな埋め込みのための制御された忘却――事前学習された言語モデルにおける概念的ショートカットの軽減
MedVista3D:3次元CT疾患検出、理解および報告における診断エラー低減のための視覚言語モデリング
LuxDiT:ビデオ拡散トランスフォーマーを用いた照明推定
WildScore:現実世界における記号音楽推論のためのMLLMsベンチマーク
セットブロックデコードは言語モデル推論を高速化するアクセラレータである。
大規模言語モデルを用いた記号的グラフィカルプログラミング
言語モデルが幻覚を生じる理由
LatticeWorld:マルチモーダル大規模言語モデルを活用したインタラクティブな複雑な世界生成フレームワーク
Recomposer:イベントロール誘導型の生成音声編集
遷移モデル:生成学習目的の再考
逆IIFEval:大規模言語モデルは、根強い学習規則を忘れて本物の指示に従うことができるか?