Command Palette
Search for a command to run...
絵文字で音声生成を制御できますか? Irodori-TTS は RF-DiT アーキテクチャに基づく日本語 TTS です。湿疹と白癬の皮膚疾患データセット: 医用画像分類と転移学習をサポートします。

2026年に開発者Aratakoによって公開されたオープンソースプロジェクトであるIrodori-TTSは、高忠実度の音声品質と優れた操作性を兼ね備えた、新世代の日本語音声合成およびゼロショットクローニングモデルです。そのコアモデルであるIrodori-TTS-500M-v3は、5億個のパラメータを持ち、連続DACVAE潜在空間とRF-DiTアーキテクチャに基づいており、演算効率を確保しながら、48kHzでプログレードのオーディオを安定して出力できます。実用面では、このモデルは2つの大きなブレークスルーを達成しました。1つ目は、ユーザーが3~10秒の参照音声を提供するだけで、微調整なしでターゲットの音色を正確に再現できる、非常に高速な「ゼロサンプル音声クローニング」を実現したことです。2つ目は、革新的な絵文字注釈と自動的な持続時間予測を組み合わせることで、感情、トーン、微妙な非言語表現を微調整できる「多次元スタイル制御」を実現したことです。
HyperAIのウェブサイトに「Irodori-TTS-500M-v3:日本語音声合成と絵文字スタイル制御」が追加されました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/pFPM5
6月27日から7月3日までのhyper.aiウェブサイトの更新内容の概要:
* 高品質の公開データセット: 4
* 厳選された高品質チュートリアル:12
* コミュニティ記事分析:1件
* 人気のある百科事典のエントリ: 5
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
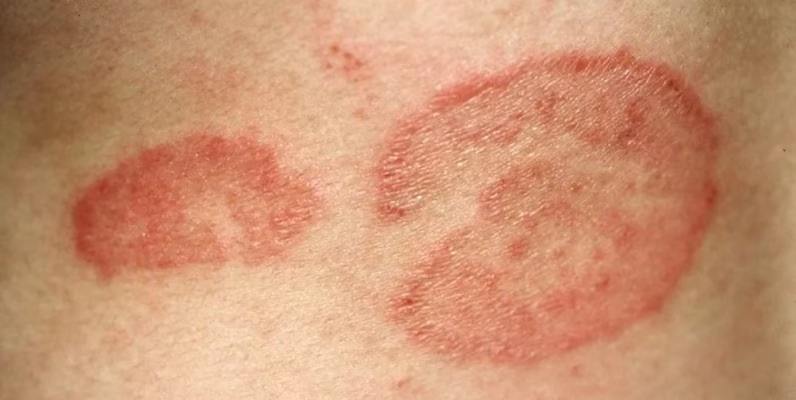
1. 湿疹および白癬皮膚疾患データセット
湿疹・白癬皮膚疾患データセットは、湿疹と白癬の皮膚疾患に関する医用画像データセットです。バイナリ画像分類タスクに対して、より簡潔で実用的なデータサポートを提供することを目的としており、皮膚疾患画像分類、深層学習モデルのトレーニングと評価、少数ショット学習と転移学習の研究、医用画像解析の教育と実験などに幅広く利用されています。このデータセットには、2,147枚の皮膚疾患画像が含まれています。
オンラインでの使用:https://go.hyper.ai/nheob
2. SASH-VPV皮下掌側静脈認識データセット
SASH-VPVは、生体認証およびコンピュータビジョン研究のための近赤外線掌静脈生体認証ベンチマークデータセットです。掌の皮下静脈構造による本人認証の研究を目的としており、生体認証システムの開発、深層学習モデルのトレーニング、セッション間ロバスト性の研究などに幅広く利用されています。
オンラインでの使用:https://go.hyper.ai/B9xrr

3. 究極のアニメ評価および分類データセット
2026年にリリースされたUltimate Animeは、アニメ推薦システムの構築、EDAデータ可視化、アニメ業界における長期的なトレンドと人気度比較分析を支援するために設計されたアニメ評価・分類データセットです。このデータセットには、アニメデータベースAniListとMyAnimeListから収集された3,994作品のアニメデータが含まれており、タイトル、ジャンル、AniListコミュニティ評価、総エピソード数、放送状況、年、あらすじ、制作会社、原作、人気度とランキング、カバー画像、放送時間など、多次元的な情報が網羅されています。
オンラインでの使用:https://go.hyper.ai/tXtT5
4. バラの葉の病気データセット
バラの葉の病気データセットは、バラの葉の病気を検出するためのモデルの開発とベンチマークに高品質の画像データを提供することを目的としており、植物モニタリングシステムの構築に広く利用されています。このデータセットのオリジナル版には、バングラデシュ産のバラの葉の画像2,458枚が含まれており、黒点病、べと病、葉枯病、健康な葉、虫食い穴の5種類に分類されています。
オンラインでの使用:https://go.hyper.ai/IuPUO

選択された公開チュートリアル
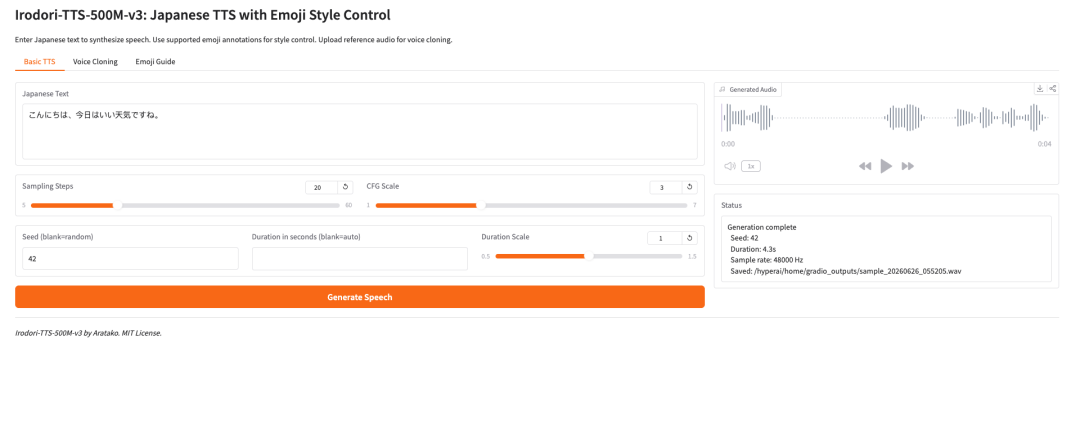
1. Irodori-TTS-500M-v3:日本語音声合成と絵文字スタイル制御
2026年5月に開発者AratakoによってリリースされたIrodori-TTSプロジェクトは、日本語のテキスト読み上げ、ゼロサンプル音声クローン、および絵文字による音声スタイル制御を目的としています。その革新性は、整流電流拡散トランス(RF-DiT)を使用して連続DACVAE潜在空間で48kHzの音声を生成し、基準オーディオ条件、自動持続時間予測、および絵文字の微妙なニュアンスを組み合わせて音色、感情、および非言語的装飾を制御する点にあります。
オンラインで実行:https://go.hyper.ai/pFPM5
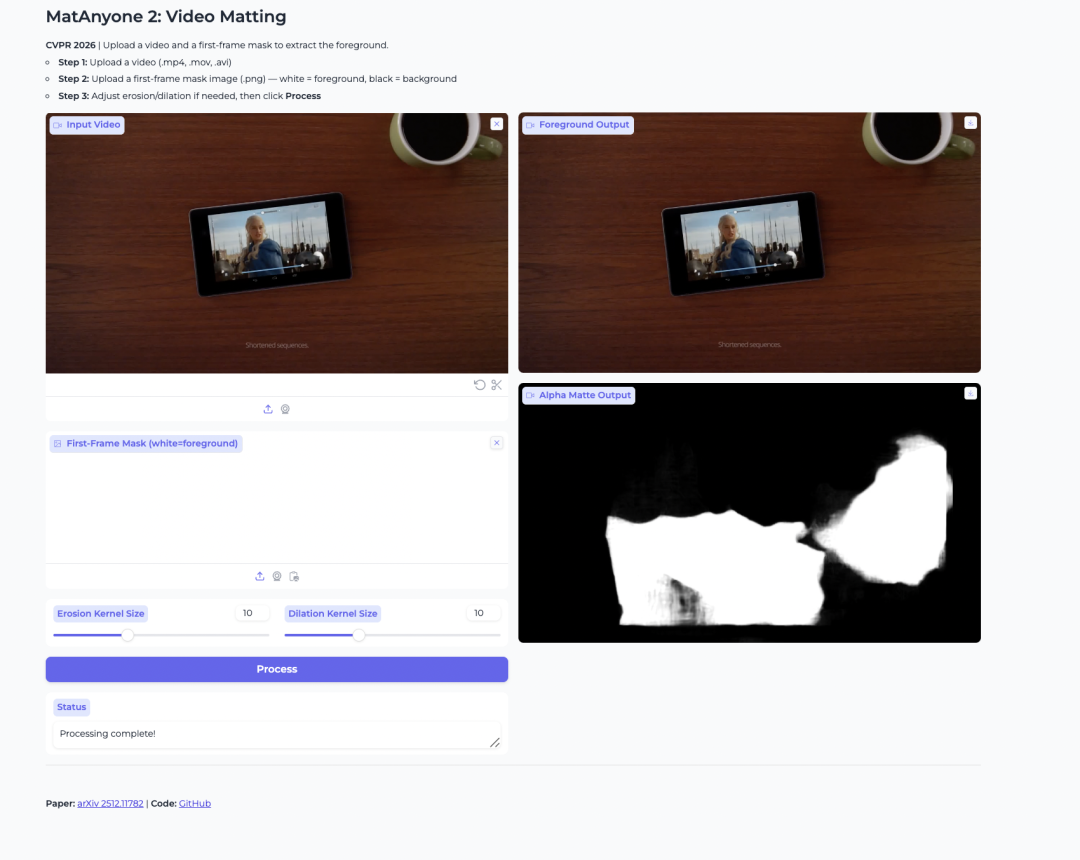
2. MatAnyone 2 ビデオキーイングモデル
南洋理工大学のS-LabとSenseTimeが2026年に発表したMatAnyone 2プロジェクトは、動画における人物の背景除去、前景抽出、アルファマスク処理に用いられます。その革新性は、独自開発の品質評価器によって、安定した背景除去、画像境界のアーティファクトの排除、髪の毛のディテールの正確な保持、そして複数の人物に対する特定の背景除去処理を実現している点にあります。
オンラインで実行:https://go.hyper.ai/yNeFK
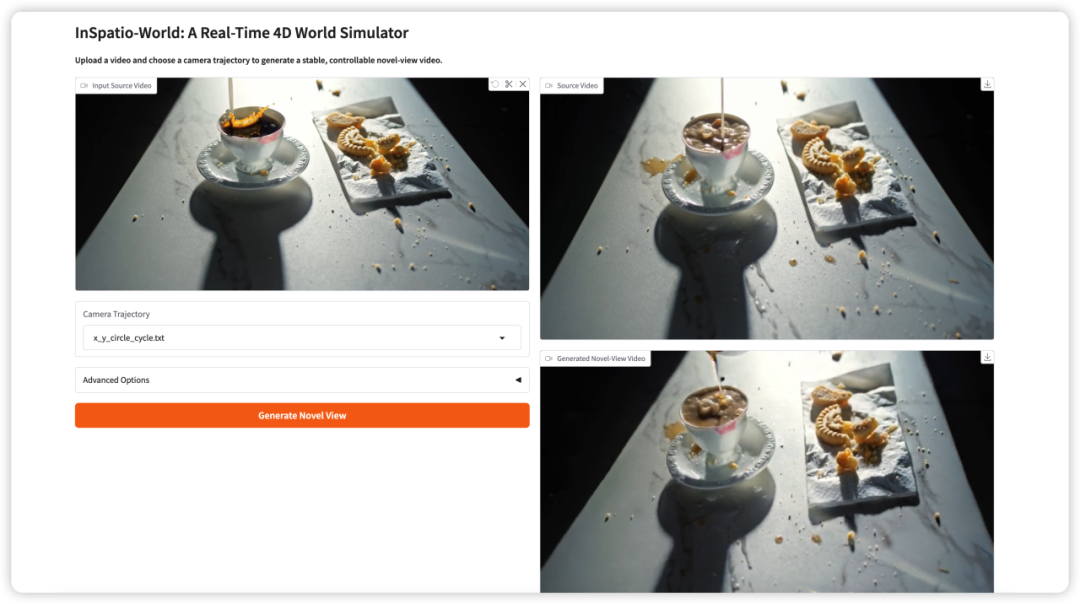
3. InSpatio-World:リアルタイム4Dワールドシミュレーター
InSpatio-Worldは、時空間自己回帰モデルに基づいたリアルタイム4Dワールドシミュレーターで、InSpatioチームによって2026年3月19日にリリースされました。入力ビデオと指定されたカメラ軌道に基づいて、安定かつ制御可能な新しい視点のビデオを生成し、カメラパスの自由な制御と時間的に一貫したワールドの進化を実現します。
オンラインで実行:https://go.hyper.ai/8FRRy
4. DiaMoE-TTS:IPAに基づく多言語音声合成に関するチュートリアル
Giant AI Labが2025年9月に立ち上げたDiaMoE-TTSプロジェクトは、国際音声記号(IPA)を統一されたフロントエンドとして使用し、多言語音声合成を実現するものです。その革新性は、方言固有の知識をMixture-of-Experts(MoE)エキスパートルーティングに落とし込み、LoRA/Conditioning Adapterなどの効率的なパラメータ手法によって、サンプルゼロで新しい方言に迅速に適応できる点にあります。
オンラインで実行:https://go.hyper.ai/wn9i5
5. SAM-Audio:自然言語処理を用いて、音声から任意の音を分離します。
SAM-Audioは、Meta社が2025年12月にリリースした、オーディオソース分離の基礎となるモデルです。このモデルは、自然言語による説明、ビデオ映像の手がかり、時間セグメントなどの手法を用いて、複雑なオーディオミックスから特定の音を分離することができます。
オンラインで実行:https://go.hyper.ai/svjXe
6. PrismAudio:CoT分解と多次元報酬に基づくV2A
PrismAudioは、Tongyi Labsが2025年11月にリリースしたビデオ・トゥ・オーディオ(V2A)生成モデルです。このモデルは、ThinkSoundのChain of Thought(CoT)プランニングメカニズムをベースに、V2A生成に強化学習を導入した初のフレームワークです。このモデルは、単一の推論プロセスを意味的、時間的、美的、空間的という4つの専門的なCoTモジュールに分解し、各モジュールに目標報酬関数を付与することで、多次元的な強化学習最適化を実現し、あらゆる知覚次元における推論品質を包括的に向上させます。
オンラインで実行:https://go.hyper.ai/BRGSk
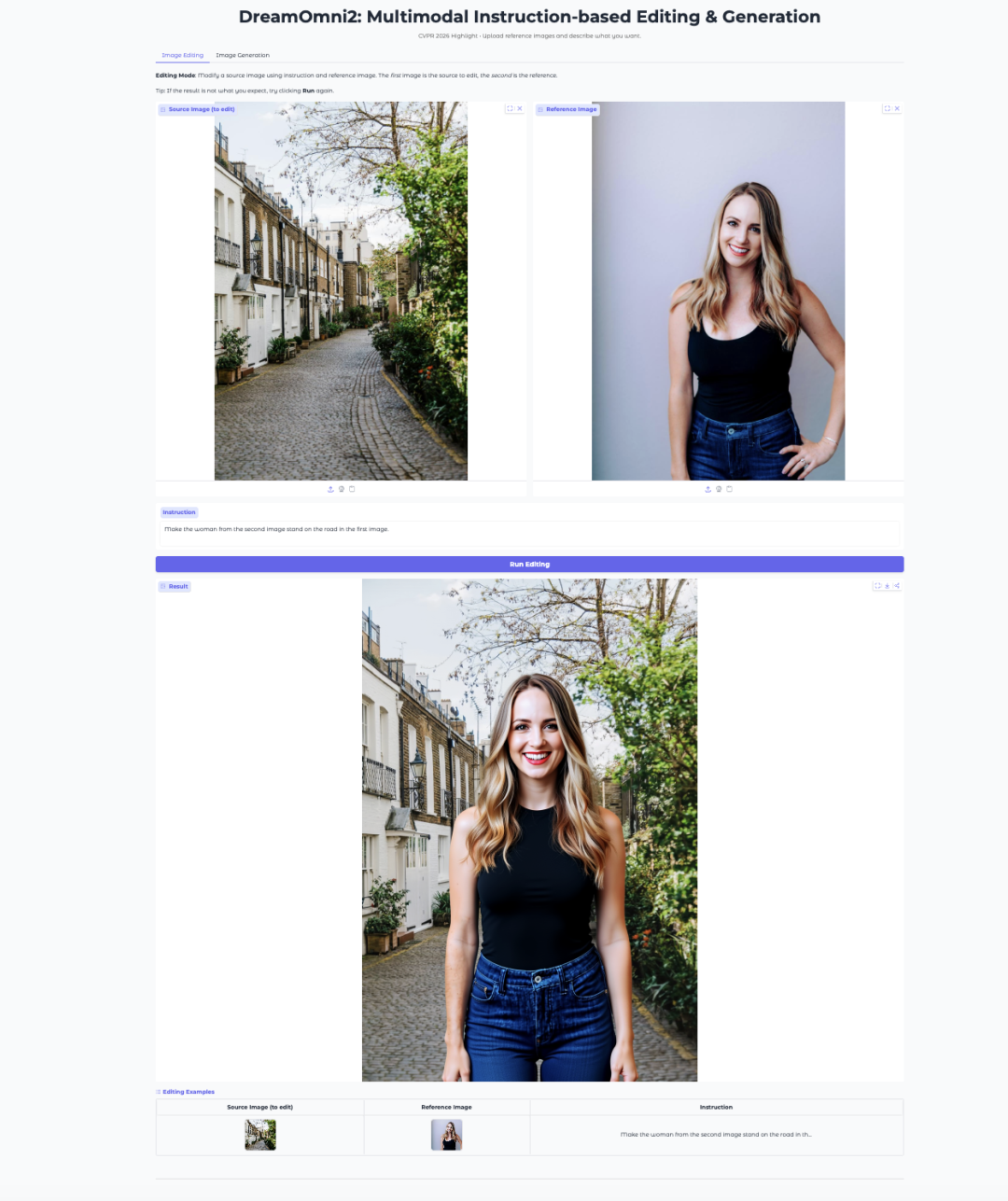
7. DreamOmni2:マルチモーダルな指示駆動型画像編集および生成
DreamOmni2は、香港中文大学のJIA Labが2025年10月に発表した、マルチモーダルな指示駆動型画像編集・生成モデルです。この論文はCVPR 2026の注目論文として採択されました。このモデルはFLUX.1-Kontext-devベースモデルをベースに、精緻に調整されたQwen2.5-VL-7B視覚言語モデルを組み合わせることで、自然言語による指示と参照画像を組み合わせた画像編集・生成をサポートします。
オンラインで実行:https://go.hyper.ai/1iqNO
8. PixelRefer:画像や動画のきめ細かなオブジェクト理解のための統一フレームワーク。
2025年10月にアリババDAMOアカデミーからリリースされたPixelReferは、画像や動画におけるきめ細かなオブジェクト中心の識別、キャプション生成、および質問応答を実現することを目的としています。その革新性は、統一された領域レベルのマルチレベル線形モデルフレームワーク(MLLM)を採用し、スケール適応型オブジェクトセグメンテーション(SAOT)と効率的なPixelRefer-Liteオブジェクト固有フレームワークを組み合わせることで、コンパクトなオブジェクト表現を構築している点にあります。
オンラインで実行:https://go.hyper.ai/ETjjw
9. 無制限OCR:長文ドキュメントのOCRとレイアウト解析をワンクリックで展開
Unlimited-OCRプロジェクトは、Baiduチームによって2026年6月にリリースされました。このプロジェクトは、長文ドキュメントのOCRおよびレイアウト解析シナリオを対象としており、より長いコンテキスト内で安定した解析効率を維持し、ワンショットで長期解析を実現することを主な目標としています。このモデルは、単一ドキュメント画像、複数ページ画像、およびPDFから変換されたページ画像を処理できるため、論文、レポート、スキャンされたドキュメント、長い表、および複数ページドキュメントのテキスト認識と構造化解析に適しています。
オンラインで実行:https://go.hyper.ai/Bp69q
10. EdgeTAM: エッジデバイス向けのキュー対応画像およびビデオセグメンテーションモデル。
Meta Reality Labsと南洋理工大学のS-Labが2025年1月に共同で立ち上げたEdgeTAMプロジェクトは、リソース制約のあるデバイス上で、キュー対応の画像セグメンテーションとビデオオブジェクトトラッキングタスクを実現するために設計されています。その中核となるイノベーションは、2D空間パーセプトロンと蒸留プロセスを組み合わせることで、セグメンテーション品質を維持しながらSAM 2のメモリアテンションのボトルネックを軽減し、デバイス上での効率的な「何でも追跡」インタラクションを可能にすることです。
オンラインで実行:https://go.hyper.ai/yZoqO
11. Step-Audio-EditX:3B LLMに基づくゼロショット音声クローニングと表情ベースの音声編集
StepFunが2025年11月に発表したStep-Audio-EditXプロジェクトは、ゼロショット音声クローン作成と反復的で表現力豊かな音声編集タスクを対象としています。その革新性は、30億個のパラメータを持つ大規模な言語モデルと強化学習を組み合わせることで、感情、話し方、および非言語的イベントを個別の制御項として構成できる点にあります。このモデルは、北京語、英語、四川語、広東語、日本語、韓国語に対応しています。
オンラインで実行:https://go.hyper.ai/UL7Hg
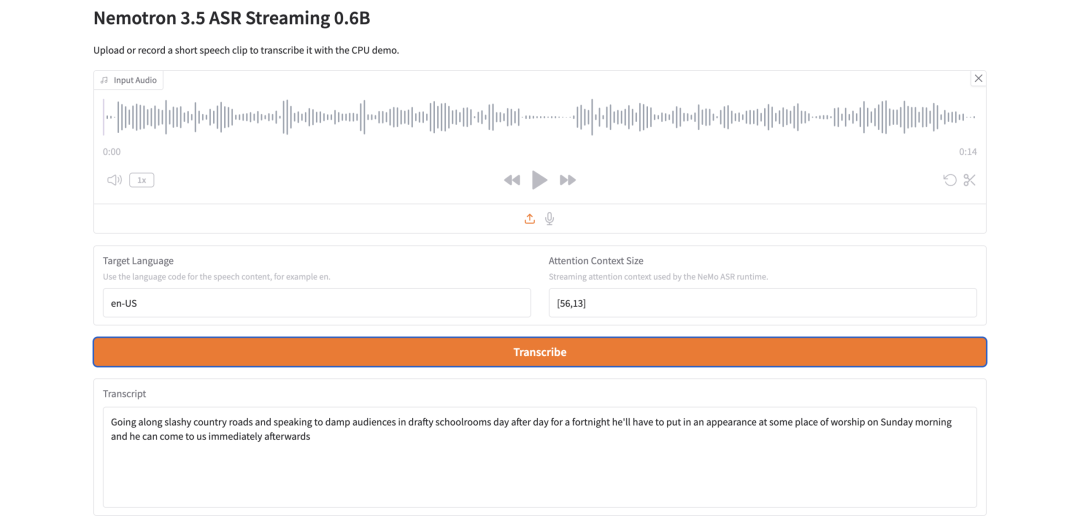
12. Nemotron 3.5 ASR Streaming 0.6B: ストリーミング音声認識用の軽量ASRモデル
Nemotron 3.5 ASR Streaming 0.6Bは、NVIDIAが2026年6月にリリースした、6,000万個のパラメータを持つ自動音声認識および低遅延ストリーミング文字起こしモデルです。このモデルは、キャッシュ対応のFastConformer-RNNTアーキテクチャを採用しており、ストリーミング推論中にエンコーダのコンテキストを再利用することで、冗長な計算を削減します。また、言語IDキューイング条件をサポートしており、複数の言語地域にわたる文字起こしを可能にします。
オンラインで実行:https://go.hyper.ai/mFejg
コミュニティ記事の解釈
1. MetaはAIデータサイエンティストを提案し、Autodataは高品質なトレーニング/評価データセットを構築する。
Meta Basic人工知能研究チームは、Autodataと呼ばれる汎用的な手法を提案しました。この手法では、「データサイエンティスト」として機能するインテリジェントエージェントが、データの構築と整理を担当します。その動作は、人間のデータサイエンティストが高品質なデータを生成するプロセスを模倣しています。このプロセスには、初期データ生成だけでなく、データ分析フェーズ、パフォーマンスの評価、経験の要約、そしてこれらの経験に基づいたより良いデータソリューションの反復的な生成も含まれます。
レポート全体を表示します。https://go.hyper.ai/UThkc
人気のある百科事典の項目を厳選
1. 大規模言語モデル(LLM)
2. 世界行動モデル(WAM)
3. 調和平均
4. バーチャル上映
5. AIフィードバックに基づく強化学習(RLAIF)
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 2100以上の公開データセット向けに、国内高速ダウンロードノードを提供
* 700以上の定番かつ人気のオンラインチュートリアルを収録
* 300件以上のAI4Science論文事例を分析
* 700以上の関連用語の検索に対応
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








