Command Palette
Search for a command to run...
オンラインチュートリアル | 数十ページにわたる文書を一度に32,000語のコンテキスト解析:Baiduオープンソース無制限OCR、長文文書を含む複雑なシナリオのリファクタリング

ここ数年、OCRは「画像内のテキスト認識」から、文書全体を理解するためのタスクへと徐々に進化してきました。企業や開発者は、テキストを抽出するだけでなく、複雑なページレイアウトの認識、表や数式の解析、複数列レイアウトの理解、そして最終的には下流のRAG、ナレッジベース、またはオフィスオートメーションに適した構造化された結果の出力が可能なモデルを求めています。しかし、スキャンされたレポート、論文、PPT、契約書、複数ページのPDFなどの長い文書を処理する場合…従来のOCRワークフローでは、ページごとの推論処理に続いて後処理と結合が必要となることが多く、これは非効率的であるだけでなく、文脈情報の断片化を引き起こしやすい。
DeepSeek OCRに代表される次世代エンドツーエンドOCRモデルは、デコーダーとして大規模な言語モデルを組み込み、言語の事前知識を最大限に活用することで、認識精度と複雑なレイアウト解析機能を大幅に向上させています。しかし、新たな課題が生じています。出力コンテンツが増加するにつれて、モデルのキーバリューキャッシュが蓄積され、メモリ使用量の増加と生成速度の低下につながります。言い換えれば、モデルが文書の末尾に近づくほど、推論コストは高くなります。
Baiduが最近オープンソース化したUnlimited OCRは、この業界の課題に対処します。DeepSeek OCRをベースにしたこのモデルは、デコーダーの従来の注意機構に代わる新しいReference Sliding Window Attention (R-SWA) 機構を導入しています。これにより、デコード処理全体を通して一定のKVキャッシュサイズを維持しながら、注意の計算コストが削減されます。DeepSeek OCRエンコーダーの高い情報圧縮機能と組み合わせることで、Unlimited OCRは、デフォルトの32Kコンテキスト長内で、数十ページにわたる文書のOCR処理とレイアウト解析を、1回の順方向推論で完了できます。これは、長文文書処理において、より工学的に価値のある新たなアプローチを提供する。さらに重要なことに、R-SWAはOCRに適用できるだけでなく、自動音声認識(ASR)や機械翻訳といった長文シーケンス解析タスクにも拡張できる可能性を秘めている。
現在、HyperAI(hyper.ai)は「Unlimited-OCR:長文ドキュメントOCRとレイアウト解析のワンクリック展開」チュートリアルを公開しており、展開のハードルを下げ、モデルの迅速な検証を支援しています。⬇️
オンラインで実行:https://go.hyper.ai/YfaB5
関連論文を見る:https://go.hyper.ai/PZsJo
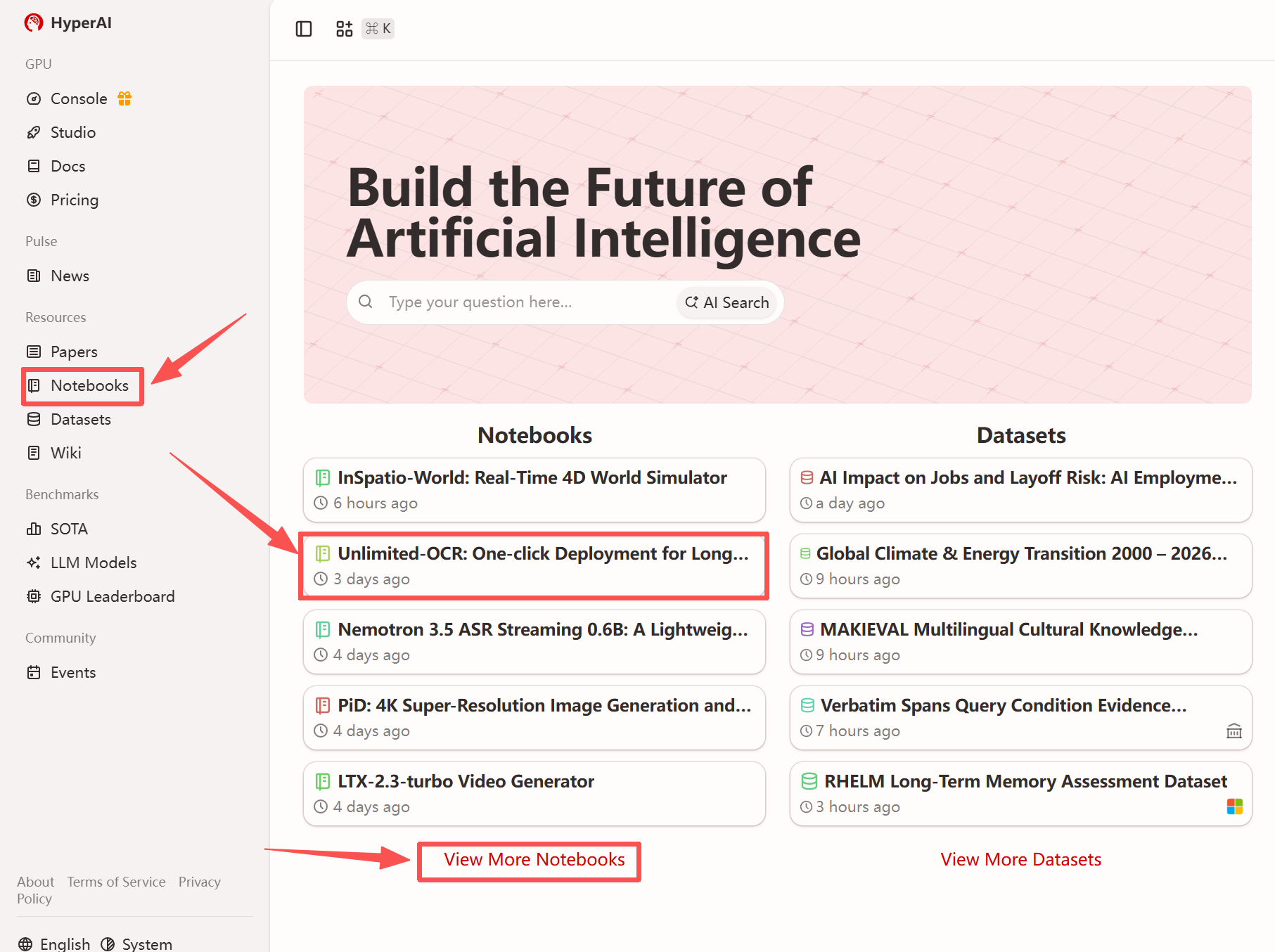
その他のオンラインチュートリアル:
デモの実行
1. hyper.ai のホームページにアクセスしたら、「チュートリアル」ページを選択するか、「その他のチュートリアルを表示」をクリックし、「Unlimited-OCR: 長文ドキュメントの OCR とレイアウト解析のワンクリック展開」を選択して、「このチュートリアルを実行」をクリックします。
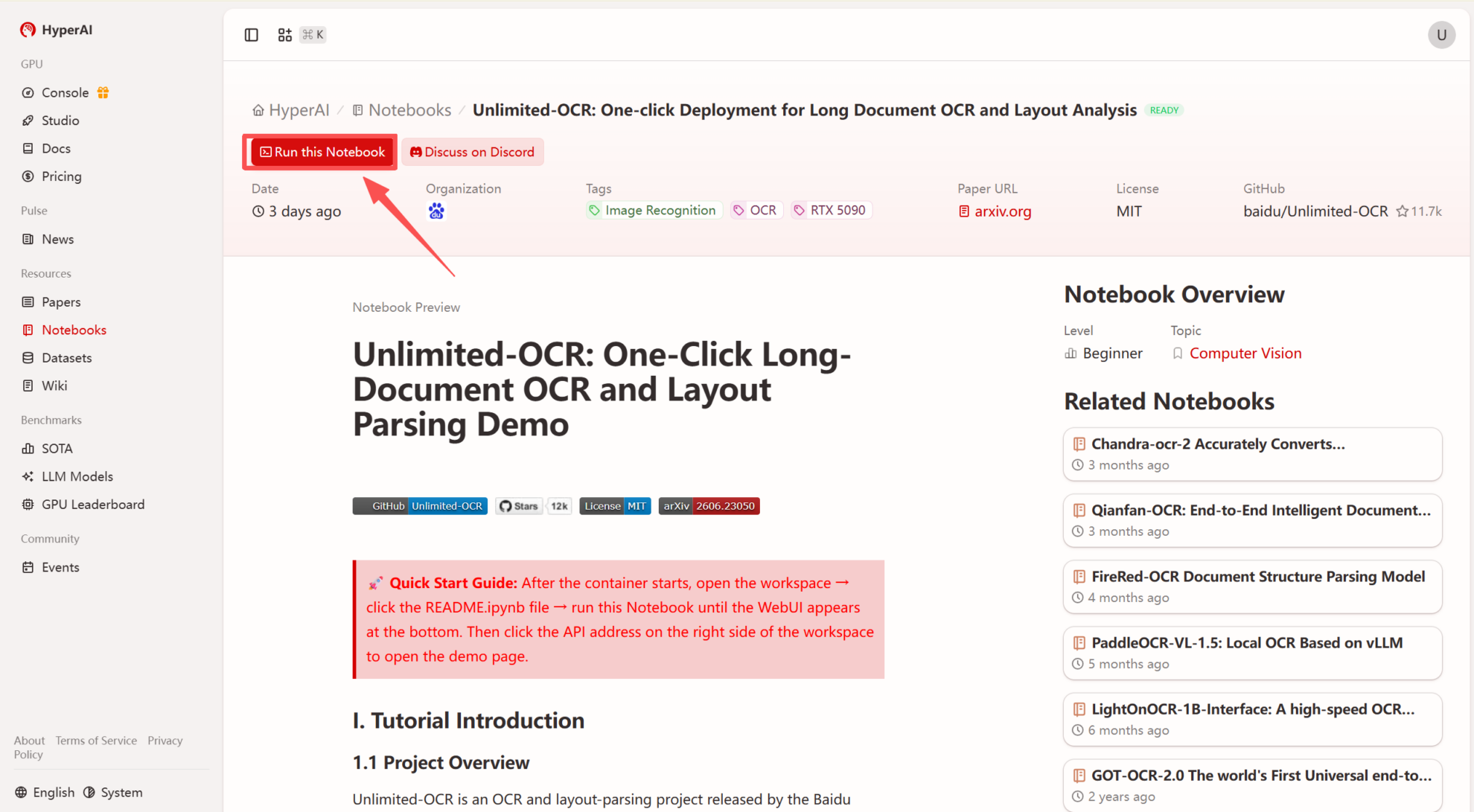
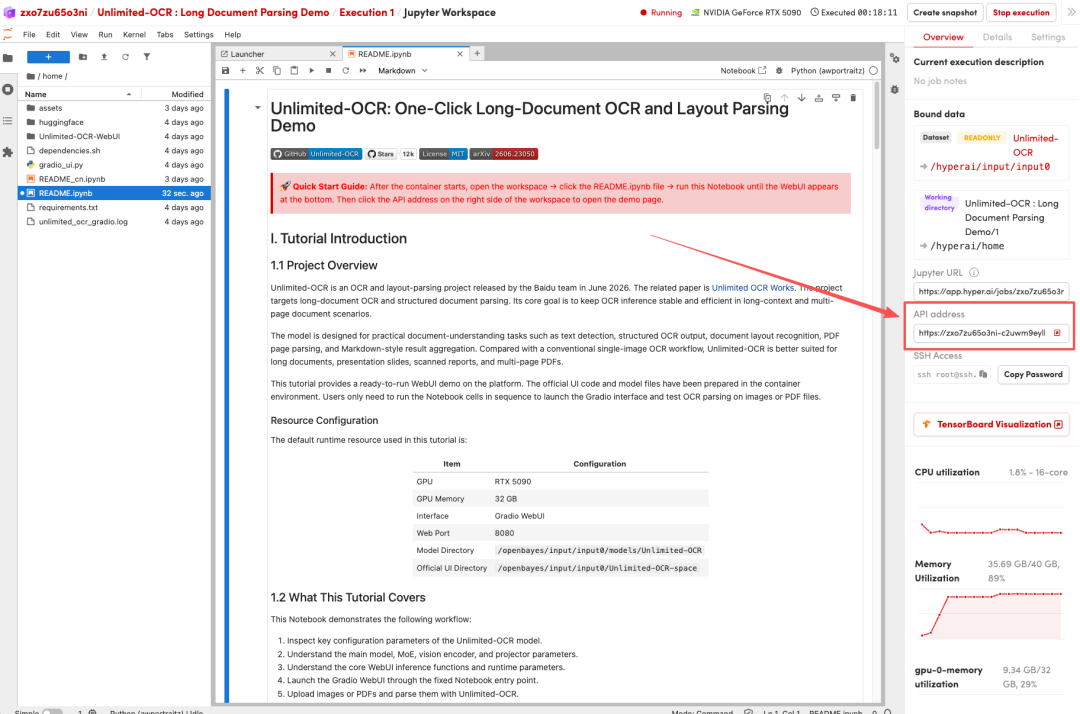
2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。
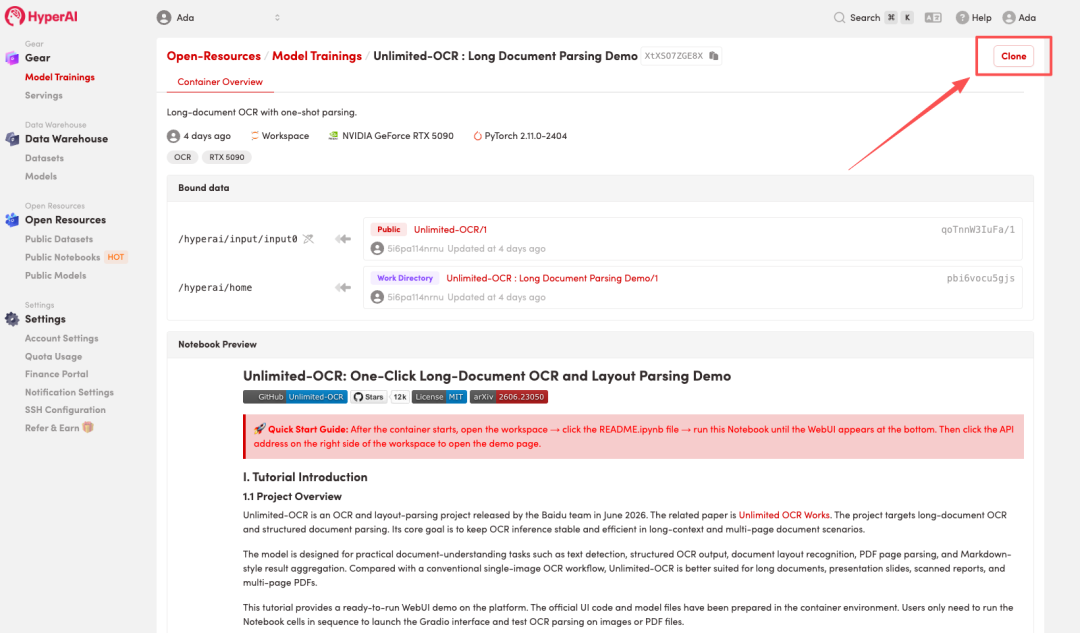
3. 「NVIDIA RTX 5090」と「PyTorch」の画像を選択し、「ジョブの実行を続行」をクリックします。
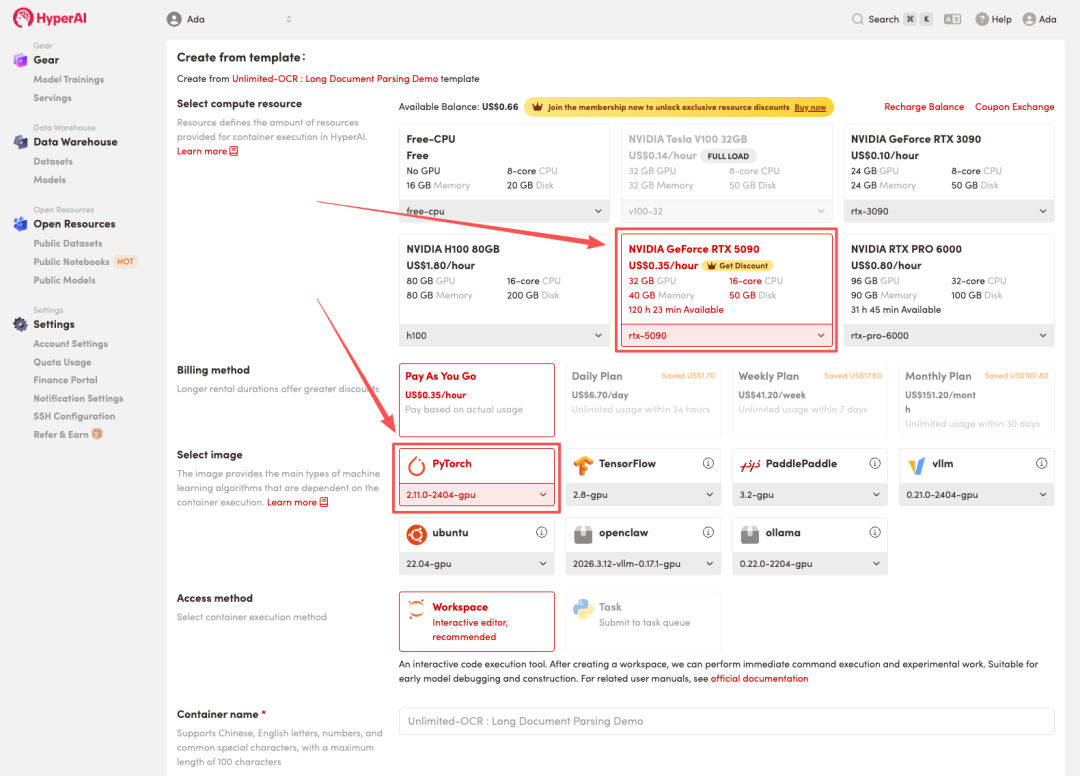
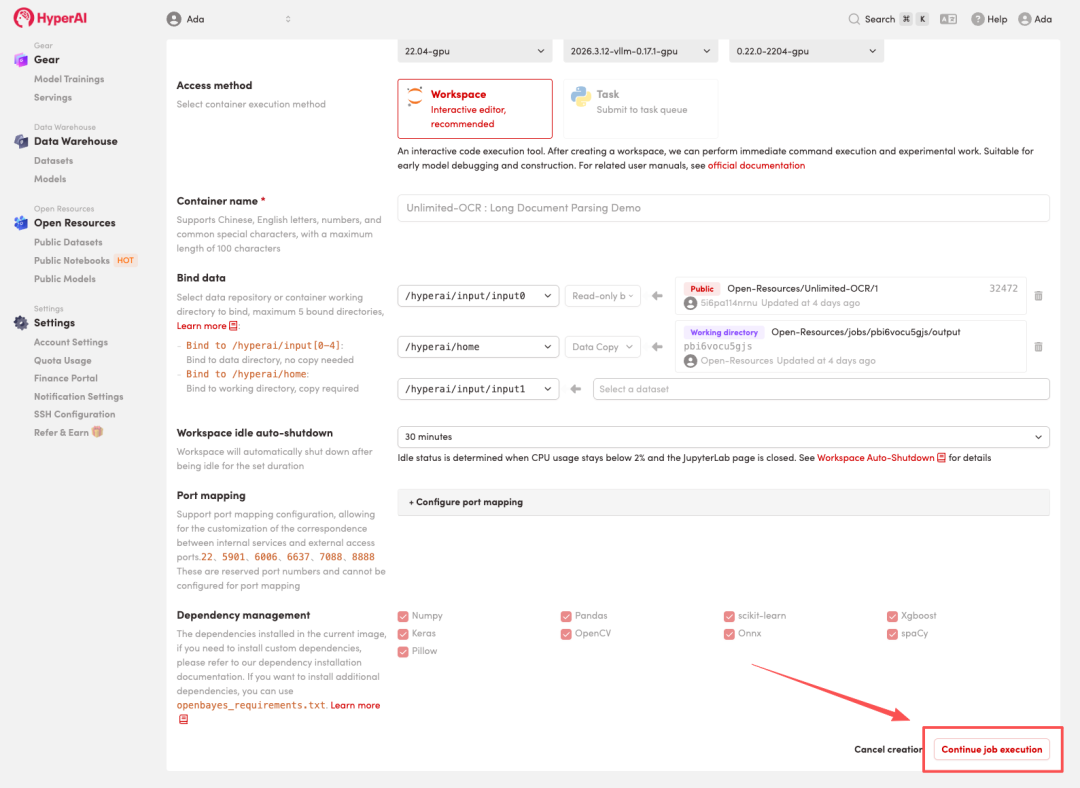
4. リソースが割り当てられるのを待ちます。ステータスが「実行中」に変わったら、「ワークスペースを開く」をクリックしてJupyterワークスペースに入ります。
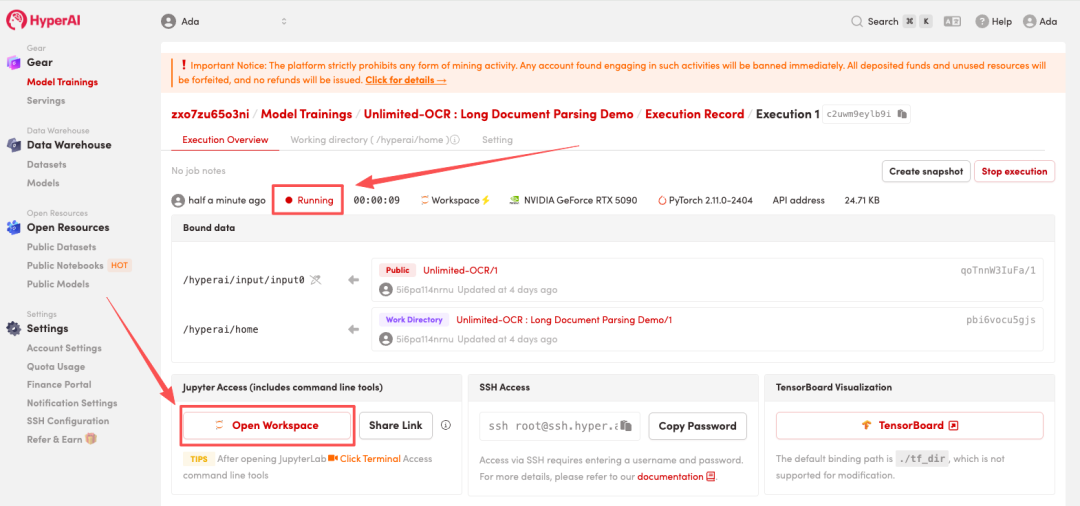
エフェクト表示
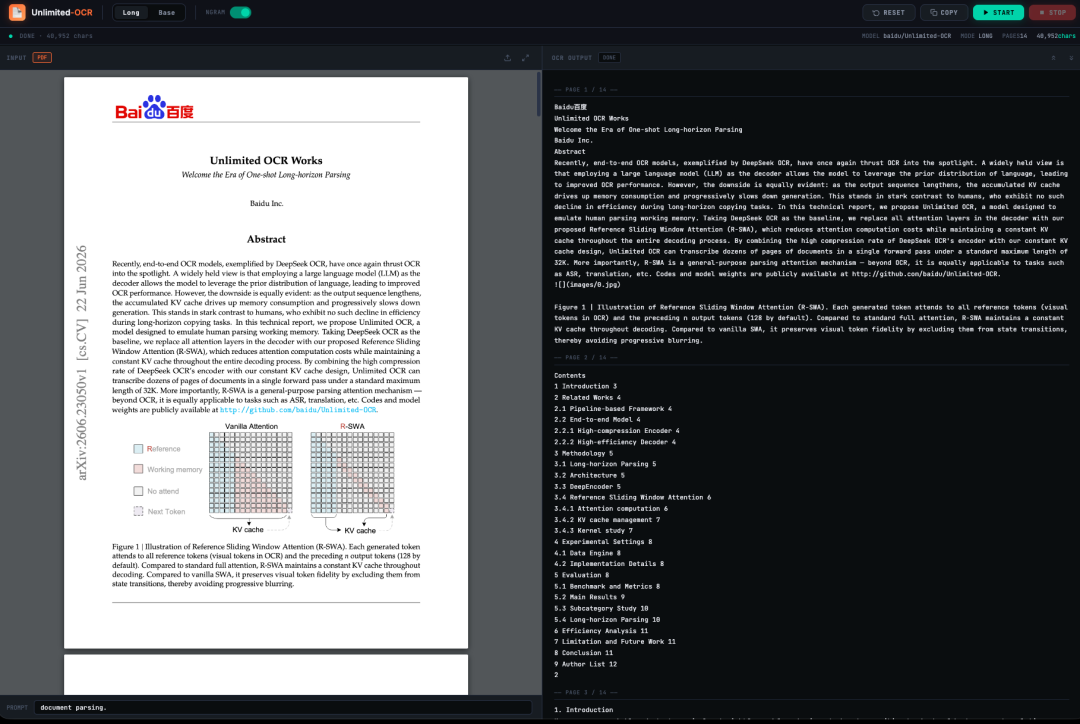
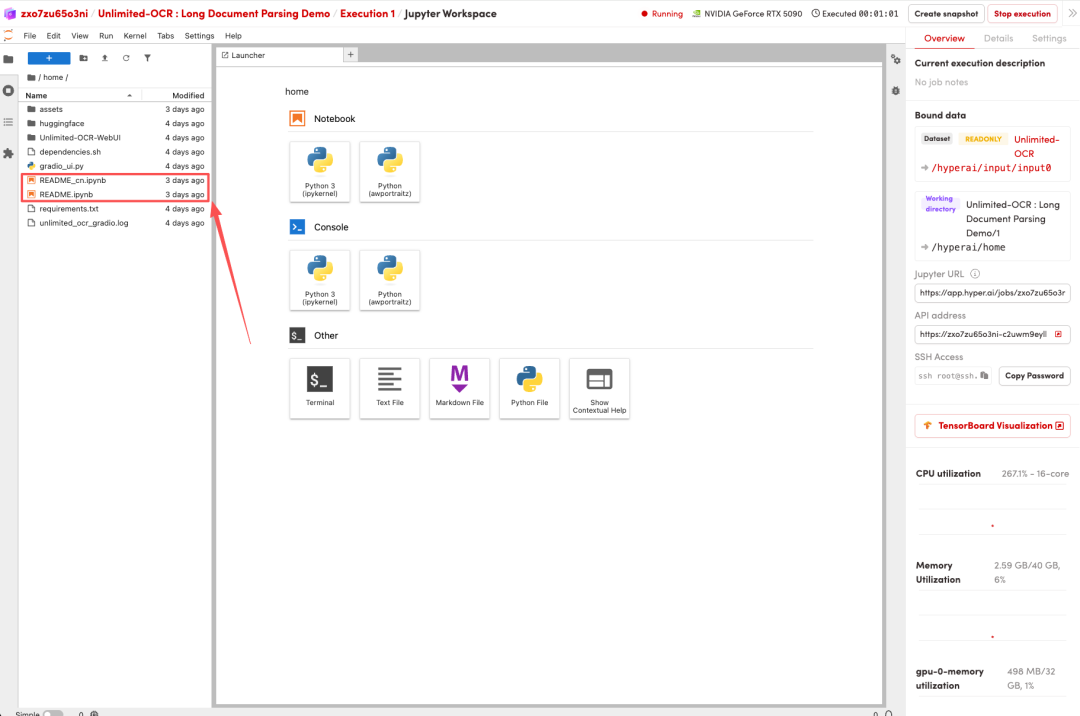
1. ページがリダイレクトされたら、左側のREADMEファイルをクリックし、上部の「実行」をクリックします。
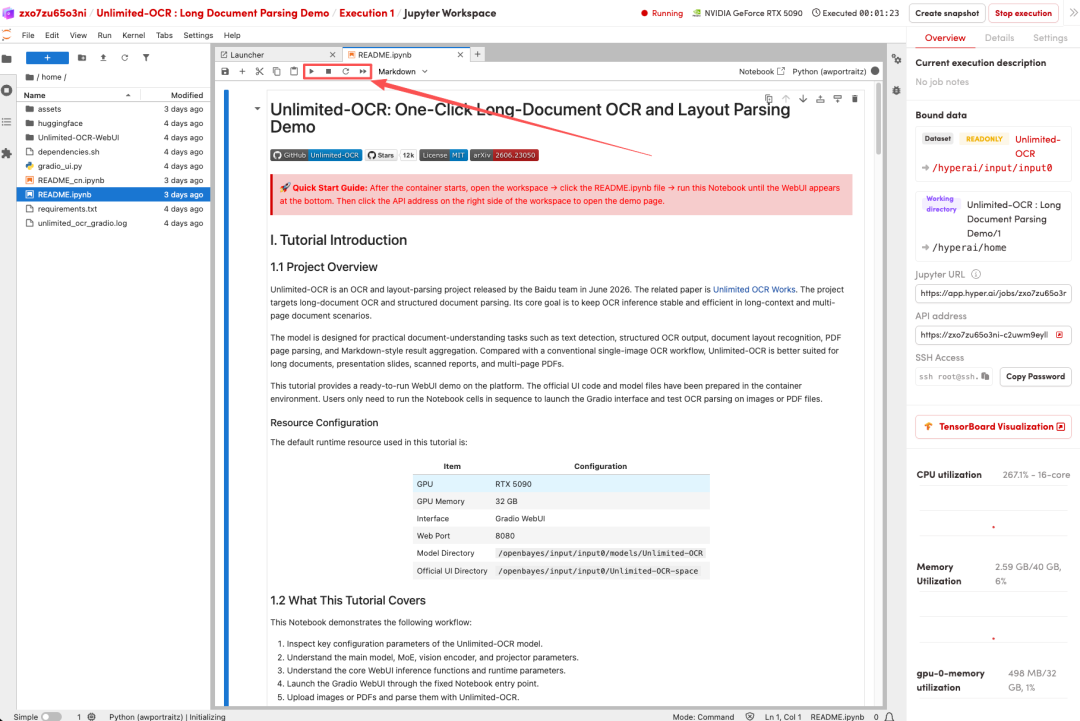
2. 処理が完了したら、右側のAPIアドレスをクリックしてデモインターフェースを開きます。