Command Palette
Search for a command to run...
わずか3秒の音声で「ナレーションの自由」を実現:Mistralのオープンソース音声モデルVoxtral-4B-TTS-2603。データ品質の新たなベンチマークを設定:Sutra 10B事前学習。

現在、軽量音声モデルは、複雑な多言語環境や長尺の吹き替えを扱う際に、自然さと展開効率のバランスを取るのに苦労することが多い。実際のアプリケーションでは、音声エージェントやコンテンツ配信において、極めて高い言語理解能力が求められるだけでなく、ローカル環境で低遅延で動作し、複数の言語間のシームレスな切り替えをサポートすることも要求される。こうした要求の厳しいシナリオは、既存のオープンソースモデルのパラメータ規模とエンジニアリング能力にとって大きな課題となっている。
この文脈では、Mistral社は、Voxtral-4B-TTS-2603モデルを正式にリリースしました。 Voxtral TTSは、ハイブリッドモデリングフレームワークに基づいた多言語ゼロショットテキスト音声合成モデルです。Voxtral Codecを使用して音声を意味トークンと音響トークンにエンコードします。意味部分はASR蒸留によってテキストと整合されます。生成フェーズでは、デコーダのみを使用する自己回帰モデルが意味トークンを段階的に生成し、長距離の一貫性を確保します。同時に、フローマッチングモデルを導入して連続空間で音響トークンを効率的に生成し、生成品質と計算効率のバランスを取ります。この「意味自己回帰+音響フローマッチング」のハイブリッドアーキテクチャは、離散モデリングと連続モデリングの利点を効果的に統合し、わずか約3秒の参照音声で高品質の音声クローニングを実現し、多言語シナリオで優れた汎化能力を発揮します。
HyperAIのウェブサイトに「Voxtral 4B TTS 2603 多言語音声生成」が掲載されましたので、ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/AoY2t
hyper.aiの公式サイトにおける3月30日から4月5日までの更新内容の概要は以下のとおりです。
* 高品質の公開データセット: 8
* 厳選された高品質チュートリアル:10件
* コミュニティ記事の解釈:3件
* 人気のある百科事典のエントリ: 5
4月締切の主要カンファレンス:6件
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. 求人掲示板大学生の求人検索データセット
このデータセットは、大学卒業生の就職活動プロセスに関する合成データセットであり、10万件のレコードが含まれています。学生の人口統計情報(専攻、大学ランキング、地域など)、学業成績(GPA、インターンシップなど)、および就職活動プロセス(応募書類の提出、一次面接、二次面接、内定)の詳細が記録されています。内定を獲得した学生については、給与、企業規模、職務関連性などの目標変数も含まれています。
直接使用します:https://go.hyper.ai/Rj94B
2. 地上観測による世界洪水イベントデータセット
このデータセットは、世界中のニュースデータから自動的に構築された高解像度の過去の洪水イベントデータセットであり、150か国以上を網羅する260万件の洪水記録が含まれています。データ処理において、研究チームはGemini Large Language Models(LLM)を用いて、非構造化ニューステキストから洪水発生の日時や場所などの構造化情報を体系的に抽出し、大規模な過去の災害イベントの自動構築を実現しました。
直接使用します:https://go.hyper.ai/Aj8bq
3. スートラ10B事前学習および学習データセット
このデータセットは、大規模言語モデルの事前学習のための高品質な教育用データセットです。Sutraフレームワークによって生成され、構造化された教育コンテンツを作成し、言語モデルの事前学習を最適化します。Sutraシリーズの中で最大のデータセットであり、高密度で適切にキュレーションされたデータセットが、小規模言語モデルの事前学習においていかに最適なパフォーマンスを発揮できるかを示すように設計されています。
直接使用します:https://go.hyper.ai/okKgZ
4. zh-meme-sft-8k 中国インターネットミーム文化データセット
このデータセットは、中国のインターネットミーム文化に関する指示をファインチューニングしたデータセットであり、主に、流行のインターネットミームを理解して使用する対話モデルを訓練するために使用されます。このデータセットは、Douyin、Xiaohongshu、Bilibiliなどのソーシャルメディアプラットフォーム上のコメントのやり取りから構築されており、複数回のクリーニングと強化を経ています。その特徴としては、信頼できる情報源からの対話構造、複数回のクリーニング後も高品質で維持された流行のミーム、そしてChatML形式を使用した標準化などが挙げられます。
直接使用します:https://go.hyper.ai/O0asZ
5. クリエイティブ専門家向けクリエイティブタスク指示データセット
このデータセットは、マルチモーダルAIエージェントのトレーニング、評価、および微調整のために設計された、大規模かつ高精度な合成タスクデータセットです。36種類のクリエイティブ、テクニカル、およびエンジニアリングソフトウェア環境を網羅する、1,070,917件のエージェントコマンド操作が含まれています。このデータセットは、複雑なソフトウェアの相互作用と多段階推論を探求することを目的としています。
直接使用します:https://go.hyper.ai/Da6qF
6. Nemotron Personas France(フランスの合成人物データセット)
NVIDIAがPleiasと共同で2026年に公開したこのデータセットは、フランスの合成キャラクターデータセットです。実際のフランスの人口統計、地理、性格特性に基づいて生成された合成キャラクターデータが含まれています。その目的は、フランスの地理的および人口統計的分布を反映することで、モデル開発を支援する多様な合成キャラクターデータを提供することです。
直接使用します:https://go.hyper.ai/8CmKo
7. 学生のメンタルヘルスデータセット(学生のメンタルヘルスと燃え尽き症候群)
このデータセットは、学業、心理、生活習慣といった要因を通して学生の燃え尽き症候群のレベルを分析・予測するために設計された大規模な合成データセットです。15万件の学生記録を含み、数値データとカテゴリデータが混在しているため、機械学習、分類、データ分析などのタスクに適しています。
直接使用します:https://go.hyper.ai/YL24S
8. 歴史的なパンデミックとエピデミック:世界の歴史的エピデミックデータセット
このデータセットは、歴史上発生した主要な世界的パンデミックを網羅的に記録したもので、分析にすぐに利用できるリソースとして設計されています。西暦165年のアントニヌス疫病から2023年のCOVID-19やサル痘まで、あらゆる時代、地域、病原体タイプを網羅した50の主要なパンデミックが含まれています。
直接使用します:https://go.hyper.ai/AbhHY
選択された公開チュートリアル
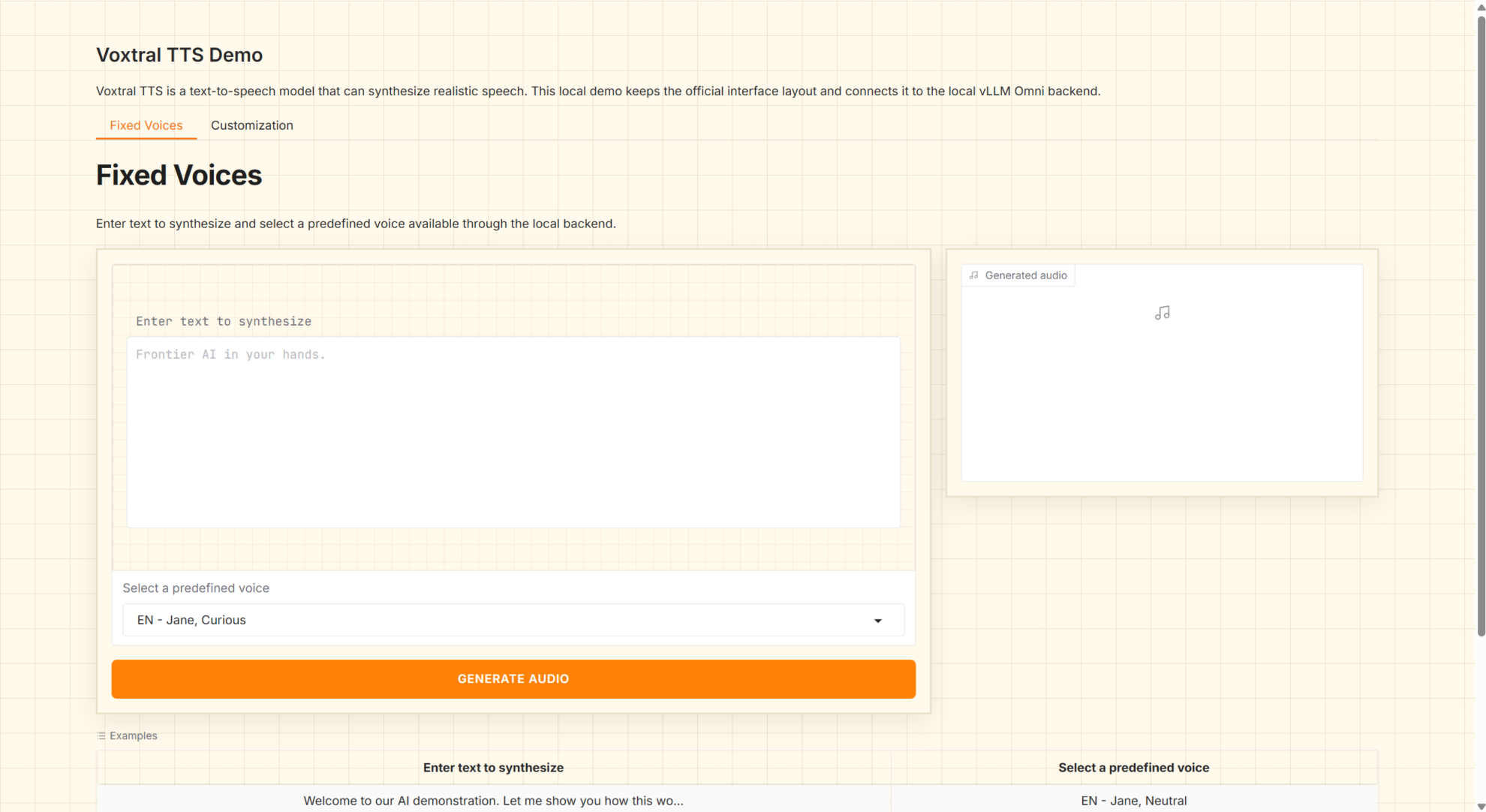
1. Voxtral 4B TTS 2603 多言語音声生成
Voxtral-4B-TTS-2603は、Mistral AIが2026年3月にリリースした4Bレベルのテキスト音声合成(TTS)モデルです。オープンウェイトと多言語音声生成機能を備え、自然言語テキストを再生可能な音声に直接合成できます。このモデルは、音声エージェント、音声放送、コンテンツの吹き替え、ローカライズされたTTSサービスなどのシナリオ向けに設計されており、標準化されたサービスインターフェースを使用したローカル展開と呼び出しに適しています。
オンラインで実行:https://go.hyper.ai/AoY2t
2. LingBot-World:オープンソースの世界モデル
LingBot-Worldは、ビデオ生成をベースとしたオープンソースの世界シミュレーターです。最高レベルの世界モデルとして、高精細な環境、長期記憶機能、リアルタイムのインタラクティブ性を誇ります。LingBot-Worldは高度なビデオ生成アーキテクチャを採用しており、入力画像、テキストプロンプト、カメラ姿勢信号に基づいて、時空間的に一貫性のある高品質なビデオを生成できます。
オンラインで実行:https://go.hyper.ai/fzF6R
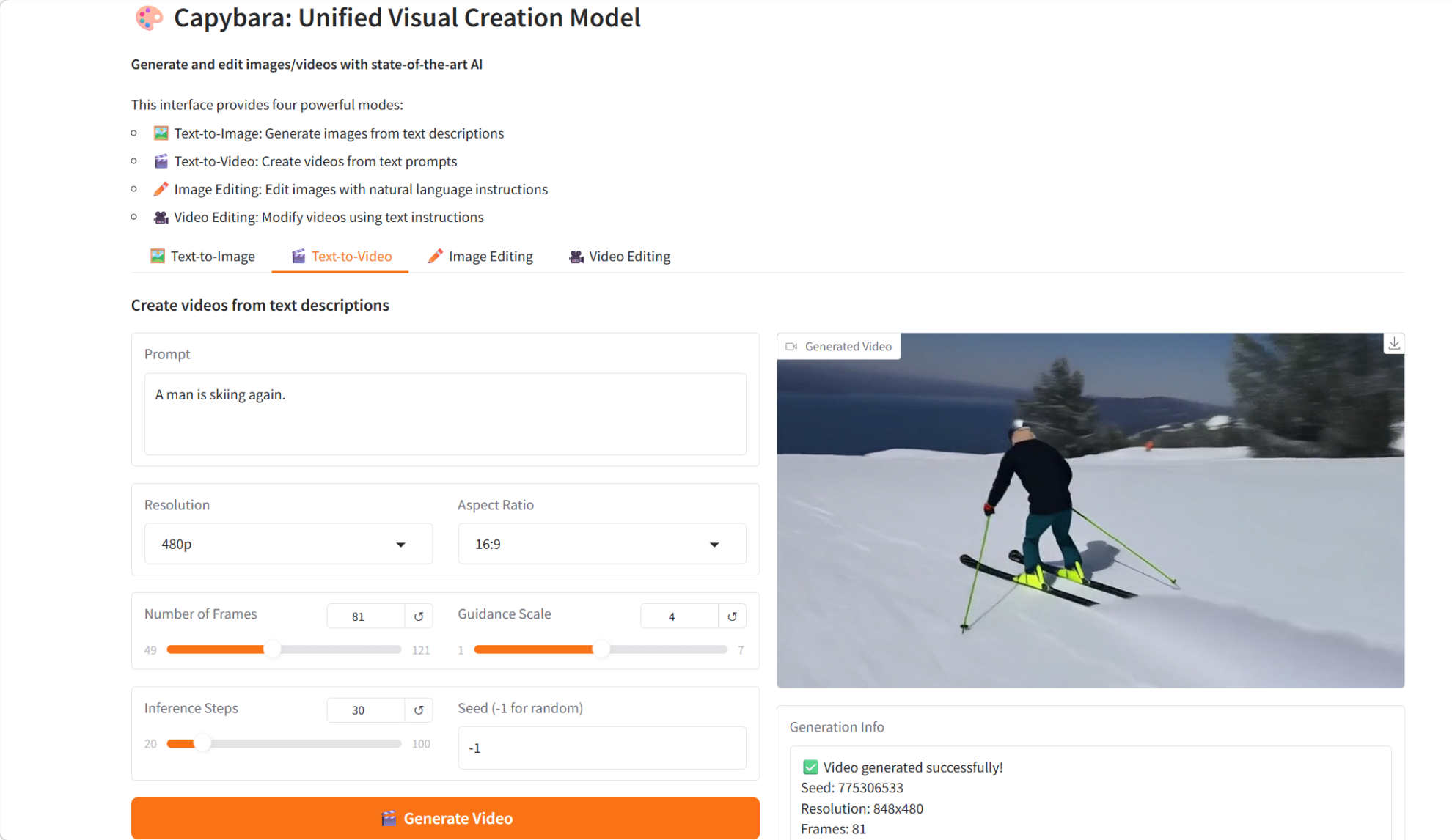
3. カピバラ:統一されたビジュアル作成モデル
2026年2月にxgen-universeチームによってリリースされたCapybaraは、テキストから画像への生成、テキストからビデオへの生成、指示に基づく画像編集、指示に基づくビデオ編集など、さまざまなビジュアル作成タスクを処理するように設計された統合ビジュアル作成モデルです。高度な拡散モデルとTransformerアーキテクチャに基づいて構築されたCapybaraは、ビジュアル生成と編集のための統一的かつ効率的なフレームワークを提供することを目指しています。
オンラインで実行:https://go.hyper.ai/yX0Pc
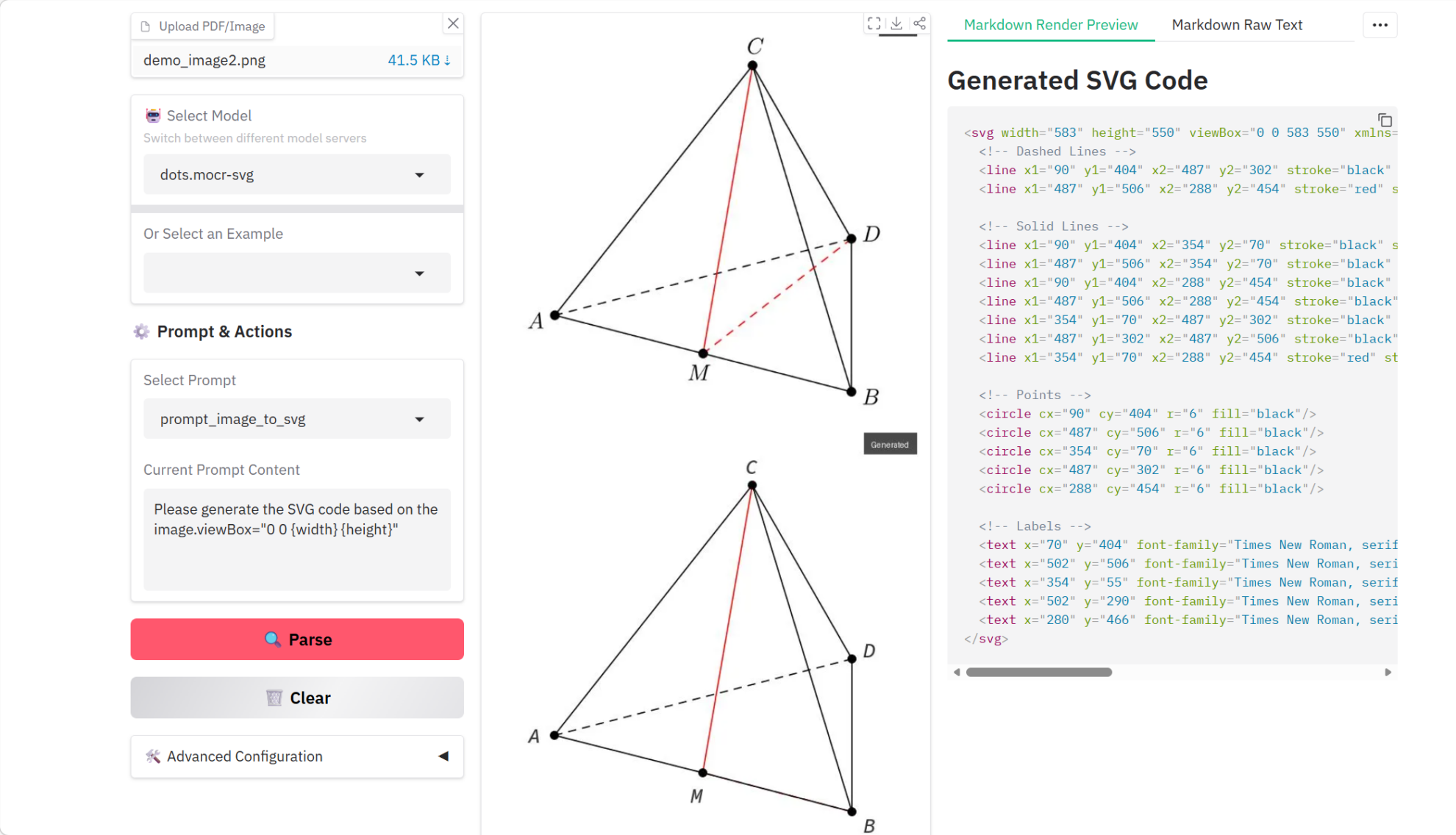
4. dots.mocr マルチモーダル文書解析チュートリアル
dots.mocrは、華中科技大学と小紅樹HI-Labが2026年3月に共同で発表したマルチモーダルOCR文書解析モデルです。同規模のモデルの中で、標準的な多言語文書解析タスクにおいて最先端(SOTA)の性能を実現しています。文書解析に加え、dots.mocrは構造化グラフィック(チャート、UIレイアウト、科学図など)をSVGコードに直接変換する機能にも優れています。
オンラインで実行:https://go.hyper.ai/g2oB3
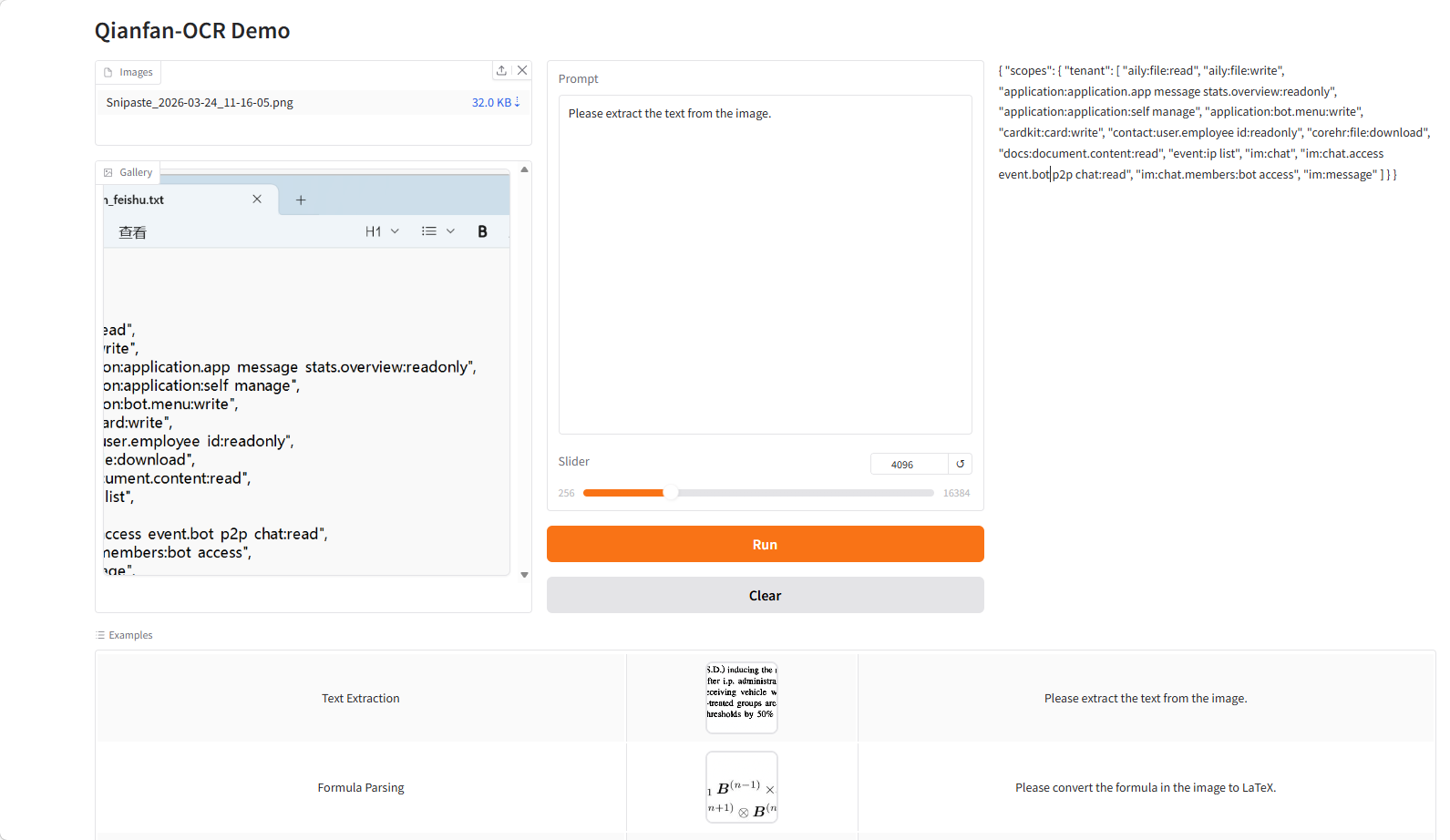
5. Qianfan-OCR:エンドツーエンドのインテリジェント文書モデル
Qianfan-OCRは、Baidu AI Cloud Qianfanが2026年3月にオープンソース化したエンドツーエンドの文書インテリジェンスモデルです。4Bパラメータのビジュアル言語アーキテクチャに基づいており、文書解析、レイアウト分析、テキスト認識、意味理解を統合しています。その核となるイノベーションは「レイアウト思考」メカニズムにあります。結果を生成する前に、モデルは「思考フェーズ」に入り、全体の解析を完了する前に、文書構造(要素の位置、種類、読み上げ順序など)を明示的にモデル化します。これにより、構造認識と意味理解のバランスが取れた統一フレームワークが実現し、複雑な文書シナリオにおける精度と安定性が向上します。
オンラインで実行:https://go.hyper.ai/WZIRF
6. vLLM + Open WebUI を使用した sarvam-30b の導入
Sarvam-30Bは、Sarvam AIが2026年3月にリリースしたオープンソースの大規模言語モデルです。Sarvamの最新オープンソースモデルシリーズの30Bバージョンとして、Mixture-of-Experts(MoE)アーキテクチャを採用し、パラメータ総数は30B、トークンあたり約24Bのパラメータが有効化されています。多言語対話、推論、エンコーディング、および実用的な展開シナリオ向けに体系的に最適化されています。
オンラインで実行:https://go.hyper.ai/UUJWe
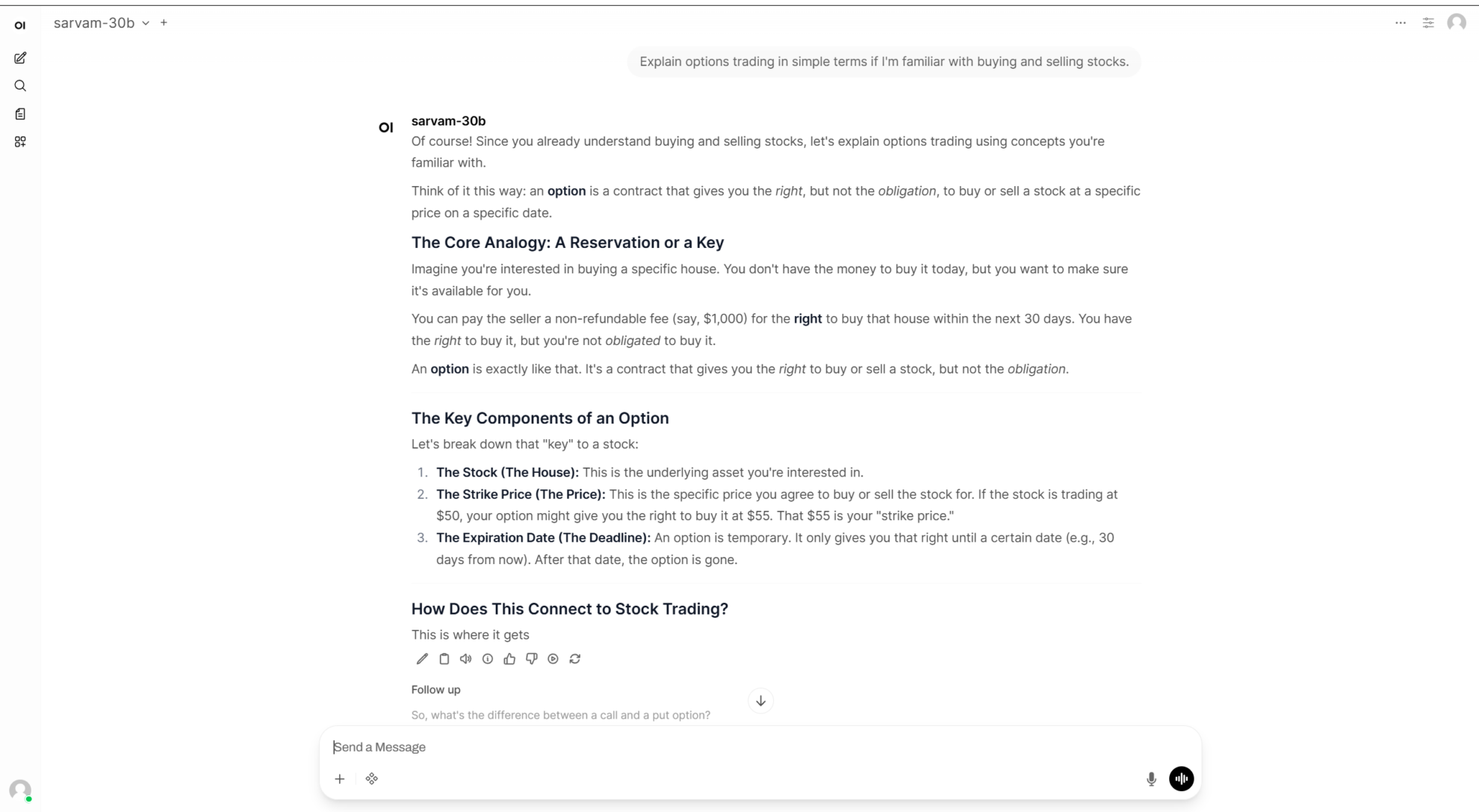
7. Phi-4-reasoning-vision-15B マルチモーダル推論ビジュアルモデルデモ
Phi-4-reasoning-vision-15Bは、2026年3月にマイクロソフトがリリースした、150億個のパラメータを持つマルチモーダル推論ビジュアル言語モデルです。Phi-4アーキテクチャをベースとしたこのモデルは、強力なテキスト推論機能と視覚理解機能を組み合わせることで、複雑なテキストと画像の推論タスクを処理できます。
オンラインで実行:https://go.hyper.ai/JQlDE
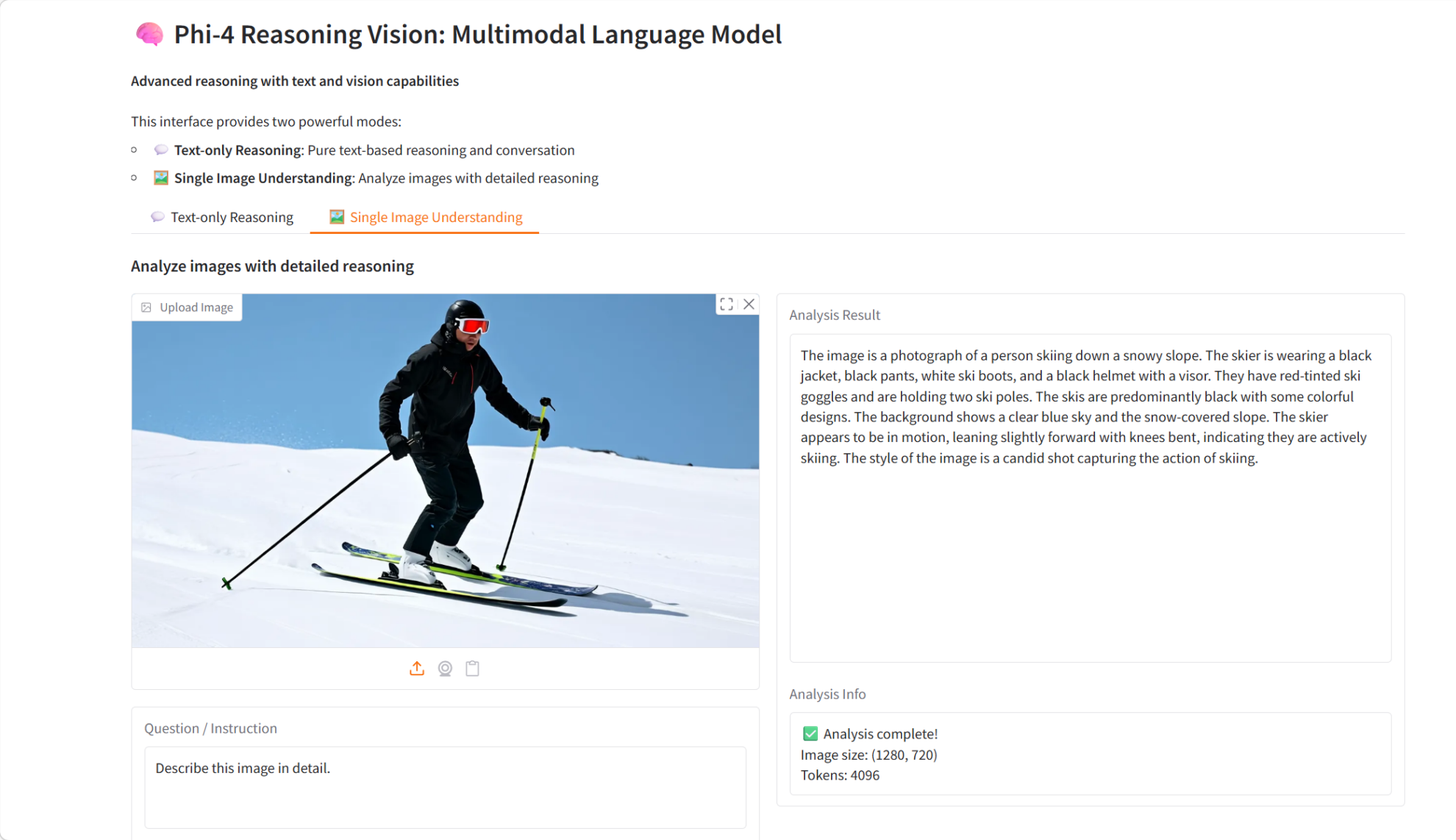
8. Slime: RLスケーリング向けに設計されたSGLangネイティブのポストトレーニングフレームワーク
Slimeは、清華大学知識工学研究所(THUDM)が開発したLLM(学習後学習)フレームワークで、強化学習の拡張を目的として設計されています。このフレームワークは、MegatronとSGLangを連携させることで、高性能な学習と柔軟なデータ生成を完璧に両立させています。
オンラインで実行:https://go.hyper.ai/Xrxev
9. NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 のワンクリック展開
NVIDIA Nemotron 3 Super NVFP4は、NVIDIA Corporationによって2026年3月にリリースされました。このモデルは、合計120個のパラメータと12個のアクティベーションパラメータを持つ大規模な言語モデルで、LatentMoEハイブリッドアーキテクチャを採用し、最大100万トークンのコンテキストをサポートしています。長文コンテキスト推論、エージェントワークフロー、ツール呼び出し、RAG、高スループットの質問応答などのシナリオ向けに設計されています。インタラクションに関しては、推論モードの有効化と無効化の両方をサポートし、標準化されたチャットテンプレートパラメータを介して、通常の質問応答モードと拡張推論モードを切り替えることができます。
オンラインで実行:https://go.hyper.ai/WJmbe
10. Qwen 3.5-27B-Claude-4.6-Opus-Reasoning-Distilled のワンクリック展開
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilledは、Jackrongが2026年3月に開発した高性能対話モデルです。Qwen3.5-27Bプラットフォームモデルをベースとし、知識抽出のためのClaude-4.6およびOpus推論機能を組み込んでいます。このモデルは、元の言語理解能力を維持しながら、複雑な推論能力と対話型対話体験を大幅に向上させます。
オンラインで実行:https://go.hyper.ai/SNlOk
コミュニティ記事の解釈
1. MITの研究チームは、2,000種類の半導体材料のシミュレーションスペクトルデータに基づいて、6種類の共存する置換欠陥を分析できるDefectNetを提案した。
マサチューセッツ工科大学(MIT)の研究チームは、複数の元素が共存する場合でも、振動スペクトルから置換点欠陥の化学種と濃度を直接予測できる、基礎的な機械学習モデル「DefectNet」を提案した。このモデルは、56種類の元素を含む未知の結晶に対して優れた汎化能力を示し、実験データを用いて微調整することも可能だ。
レポート全体を表示します。https://go.hyper.ai/4qtAH
2. AIが118個の新たな系外惑星を発見!ウォーリック大学の研究チームが提案したRAVENは、惑星のシナリオと偽陽性のシナリオを1対1で比較することを可能にする。
ウォーリック大学の研究チームは、TESS候補のスクリーニングと検証のための新しいプロセスであるRAVENを提案しました。このプロセスでは、合成トレーニングデータセットを導入することで、タスク自体によって生成される閾値外(TCE)データのみに依存する従来の手法を打破しています。この改良により、機械学習モデルがカバーする惑星および偽陽性シナリオのパラメータ空間が大幅に拡大・強化されます。1361個の事前分類済みTESS候補を含む独立した外部テストセットにおいて、このプロセスは91%という総合精度を達成し、TESS候補の自動ランキングにおける有効性を実証しました。
レポート全体を表示します。https://go.hyper.ai/phEO5
3. MITは、配列と振動の双方向マッピングを実現する、初のエンドツーエンドの動的タンパク質生成モデルであるVibeGenを提案した。
マサチューセッツ工科大学(MIT)とカーネギーメロン大学の研究チームは、配列生成と振動ダイナミクス予測を組み合わせることで、新規タンパク質設計を可能にするタンパク質生成インテリジェントエージェントモデル「VibeGen」を提案した。その結果、この生成エージェントによって設計されたタンパク質は、安定した新規構造に折り畳まれるだけでなく、主鎖レベルでの標的振動振幅の分布特性を再現できることが示された。
レポート全体を表示します。https://go.hyper.ai/jDaSW
人気のある百科事典の項目を厳選
1. RRFと組み合わせた逆ソート
2. 人工ニューラルネットワーク(NN)
3. 視覚言語モデル(VLM)
4. 回転位置符号化(RoPE)
5. 双方向長短期記憶(Bi-LSTM)
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








