Command Palette
Search for a command to run...
テンセントがHy-MT1.5翻訳モデルをオープンソース化:440MBで最高レベルの翻訳能力を実現。MITがMathNetを共同リリース:27,000の実際のオリンピック数学問題を網羅したマルチモーダル数学推論ベンチマーク。

Hy-MT1.5-1.8B-1.25bitは、テンセントが開発した軽量機械翻訳モデルです。Hy-MT1.5-1.8Bをベースに、機械翻訳の事前学習、教師ありファインチューニング、蒸留、強化学習など、多段階のトレーニングによって最適化されています。このモデルは、33の言語、5つの方言および少数言語、そして1,056の翻訳方向をサポートしています。わずか18億個のパラメータで、その翻訳性能は、より大規模なオープンソースモデルや主流の商用翻訳APIの性能を凌駕している。
HyperAIのウェブサイトに「Hy-MT1.5-1.8B-1.25bit:軽量多言語翻訳モデル」が掲載されました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/PCK8X
より詳しい情報については、弊社の公式ウェブサイトをご覧ください。
hyper.aiの公式サイトにおける5月6日から5月15日までの更新内容の概要は以下のとおりです。
* 高品質な公開データセット:12件
* 厳選された高品質チュートリアル:7件
* コミュニティ記事の解釈:3件
* 人気のある百科事典のエントリ: 5
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. QCalEval 量子較正グラフの理解データセット
NVIDIAが2026年にリリースしたQCalEvalは、量子コンピューティング実験におけるグラフ理解のためのビジュアル言語データセットです。量子コンピューティングのキャリブレーション実験の結果を解釈、分類、推論するビジュアル言語モデル(VLM)の能力を評価することを目的としており、ビジュアル言語モデルや科学画像理解の研究で広く利用されています。このデータセットには、PNG形式の2次元科学画像309枚、ベンチマークエントリ243件、および少数のサンプルを用いたベンチマークエントリ236件が含まれており、22の実験シリーズと87のシーンタイプを網羅しています。
オンラインでの使用:https://go.hyper.ai/Ke7cu
2. Claw-Eval 実世界ベンチマークデータセット
北京大学と香港大学が2026年に発表したClaw-Evalは、実世界のタスクにおけるAIエージェントの評価を目的とした、エンドツーエンドで透過的なベンチマークデータセットです。実世界環境におけるタスク実行、ツール呼び出し、マルチモーダル理解、マルチターンインタラクションといった自律型エージェントの能力を評価することを目的としています。このデータセットは英語と中国語の両方に対応しており、一般、マルチモーダル、マルチターンの3つの主要タスクグループで構成され、コミュニケーション、金融、オフィスワーク、生産性向上ツールなど24のタスクカテゴリを網羅しています。
オンラインでの使用:https://go.hyper.ai/Tznpa
3. MathNetマルチモーダル数学ベンチマーク推論データセット
MathNetは、MITチームがキング・アブドラ科学技術大学をはじめとする複数の機関と共同で2026年に公開した、大規模かつ多言語・マルチモーダルな数学的推論データセットです。オリンピックレベルの数学的推論および構造化検索タスクにおける大規模モデルの能力を評価・向上させることを目的としており、数学的推論評価、RAG研究、マルチモーダルAIトレーニングなどで幅広く活用されています。
オンラインでの使用:https://go.hyper.ai/HLxNw
4. RSRCCリモートセンシング領域変化理解ベースラインデータセット
Google Researchが2026年に公開したRSRCCは、リモートセンシングにおける意味的変化を理解するためのベンチマークデータセットです。多時期の画像証拠と自然言語による質問応答を組み合わせることで、リモートセンシングシーンにおける時間的変化の深い理解を支援し、従来の二値変化検出を意味的変化記述の次元へと高めることを目指しています。このデータセットには、リモートセンシングの変化検出に関する12万6000件の質問と回答のサンプルが含まれており、新築、解体、道路変更、植生変化、住宅開発などのシナリオを網羅しています。
オンラインでの使用:https://go.hyper.ai/jtCaK
5. 医療廃棄物検出データセット
Medical Wasteは、医療廃棄物のインテリジェントな識別と対象物検出のために設計された高解像度画像データセットです。複雑な医療環境における医療廃棄物の自動検出と分類をコンピュータビジョンモデルが実現できるよう支援することを目的としており、スマートヘルスケア、公衆衛生、自動廃棄物選別、ロボットビジョンなどの研究分野で幅広く活用されています。
オンラインでの使用:https://go.hyper.ai/PrUKd
6. ブドウの葉の病気に関するデータセット
GRAPE Leaf Diseasesは、精密農業における対象物の検出タスク向けに特別に設計されたブドウの葉の画像データセットであり、実際の農業環境における病害の検出、分類、および位置特定におけるコンピュータビジョンモデルの能力向上を目的としています。このデータセットには、健康なブドウの葉と、黒腐病、エスカフェフルバ病、葉枯病という3つの一般的な病害の4つのカテゴリを網羅した4,195枚のブドウの葉の画像が含まれています。
オンラインでの使用:https://go.hyper.ai/tJrkm
7. 水生生物アトラス:水生生物に関する世界的なデータセット。
「水生野生生物アトラス:世界種記録」は、水生生態学研究および生物多様性分析のために設計された、大規模な水生動物観察データセットです。研究者、学生、データサイエンティストに、質の高い水生生態データリソースを提供することを目的としています。このデータセットには、100種以上の水生動物を網羅し、サンゴ礁、熱帯河川、北極海、水深7,000メートルまでの深海域など、世界中の主要な水生生態系を網羅する、20万件の水生動物観察記録が含まれています。
オンラインでの使用:https://go.hyper.ai/calNa
8. 世界の地震-M4.5:マグニチュード4.5以上の地震の世界的なデータセット。
「世界の地震イベント – M4.5+」は、地震活動分析および地理空間研究のために設計された、世界の地震イベントデータセットです。研究者が長期的な地震活動の頻度、分布、および規模の変動を分析するのに役立つことを目的としています。このデータセットには、1900年から2026年までのマグニチュード4.5以上の世界の地震を網羅した、230,608件の地震記録が含まれています。
オンラインでの使用:https://go.hyper.ai/D7j95
9. 合成薬の有効性データセット
合成薬有効性データセットは、医薬品の安全性分析および臨床リスク評価を支援するために作成された合成薬のデータセットであり、データ分析、モデル構築、および実験的研究に適しています。このデータセットには、医薬品の使用および副作用モニタリングに関する構造化された医療情報が含まれています。各レコードは固有のレポート番号でインデックス付けされており、患者の年齢や性別などの基本情報に加え、薬剤名、投与量、使用期間、併用薬などの治療の詳細が含まれています。
オンラインでの使用:https://go.hyper.ai/1ZaA0
10. 眼底疾患分類データセット
眼疾患分類用眼底データセットは、眼底画像分類タスク向けに設計された医療用ビジョンデータセットであり、眼疾患の識別および診断支援シナリオにおけるコンピュータビジョンモデルの分類能力の向上を目的としています。このデータセットには、白内障、糖尿病網膜症、緑内障、正常眼底の4つのカテゴリの眼底画像を含む、6,086枚の画像が含まれています。
オンラインでの使用:https://go.hyper.ai/FFFE7
11. 乳がん:マルチモーダル融合データセット
乳がん:マルチモーダル融合は、浸潤性乳がん(BRCA)患者向けに構築された前処理済みのマルチモーダルデータセットであり、マルチモーダル融合ネットワークを構築するためのプラグアンドプレイの基盤を提供するように設計されています。このデータセットは、122人のBRCA患者からのマルチソースデータを厳密に整合させ、すべてのサンプルをTCGAケースIDを使用してモダリティ間でマッピングし、肉眼的医用画像(MRI)、顕微鏡的デジタル病理(組織病理学)、分子オミクス(マルチオミクス)、および臨床治療情報の間で1対1の対応関係を実現しています。
オンラインでの使用:https://go.hyper.ai/199WV
12. 長距離山火事・煙検知データセット
長距離森林火災・煙検知は、森林火災の早期警報および環境モニタリングを目的としたコンピュータビジョンデータセットです。このデータセットは、長距離森林モニタリングシナリオにおける煙と森林火災の検知能力を向上させることを目的としています。このデータセットは、森林火災監視塔や尾根監視カメラなどの高角度・長距離モニタリングシナリオをシミュレートする完全合成アプローチを用いて生成され、火災の初期段階でより容易に観測できる森林火災の煙の検出に重点を置いています。
オンラインでの使用:https://go.hyper.ai/LnuXC
選択された公開チュートリアル
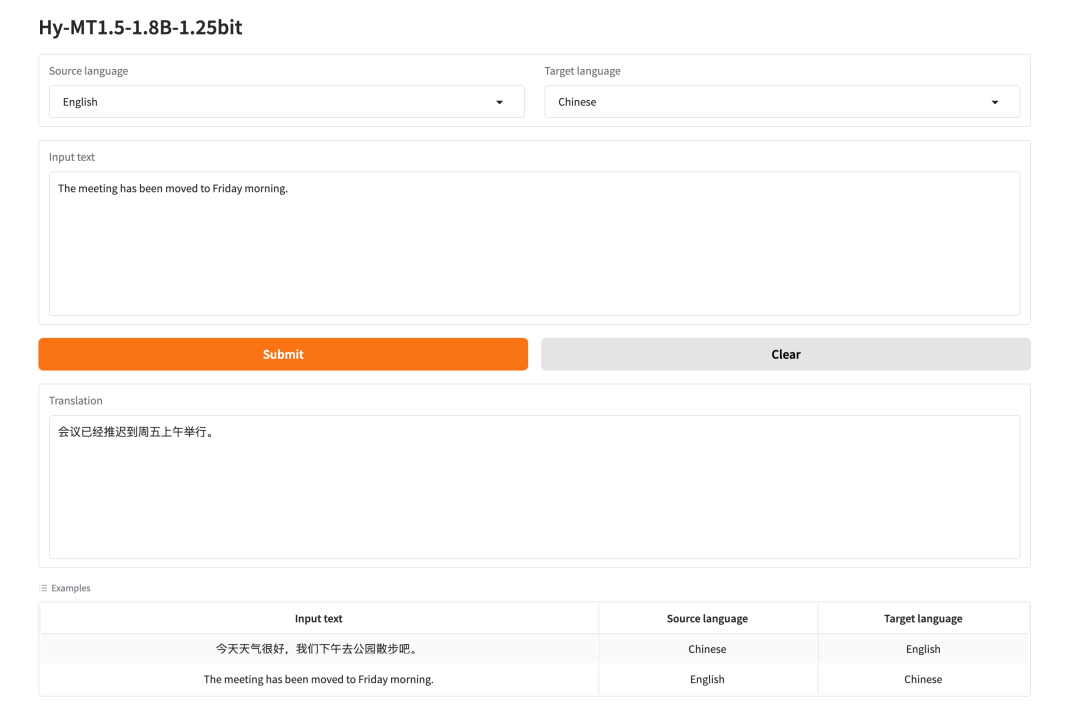
1. Hy-MT1.5-1.8B-1.25bit: 軽量多言語翻訳モデル
テンセントが2026年4月にリリースしたHy-MT1.5-1.8B-1.25bitは、Hy-MT1.5-1.8Bをベースとした1.25ビット量子化多言語翻訳モデルです。このモデルの核心的な価値は、高品質な多言語翻訳機能をより軽量な形で実現できる点にあります。
オンラインで実行:https://go.hyper.ai/PCK8X
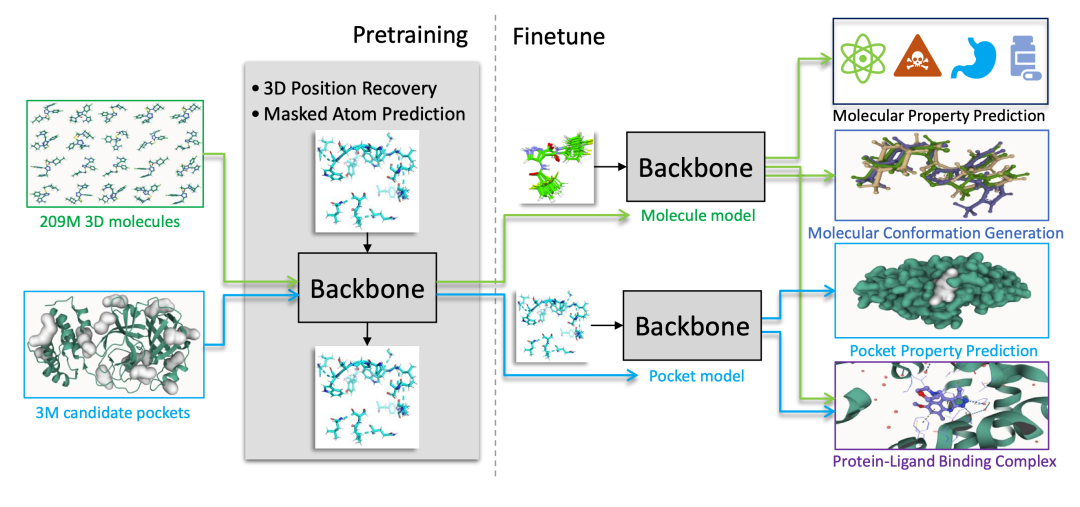
2. Uni-Mol:汎用的な3D分子表現学習フレームワーク
Uni-Molは、DP Technology社が2022年にリリースした汎用3D分子事前学習フレームワークです。Uni-Molは、大規模な3D分子構造の事前学習を通じて分子表現能力を拡張し、創薬、分子特性予測、タンパク質-リガンド相互作用モデリングなどのタスクに利用できます。
オンラインで実行:https://go.hyper.ai/RukIx
3. Mistral-Medium-3.5-128B のワンクリック展開
Mistral AIが2025年にリリースしたMistral Medium 3.5は、1280億(128B)のパラメータと25万6千個のコンテキストウィンドウを備えたフラッグシップの融合モデルであり、単一の重みセット内で命令準拠、推論、プログラミング機能を統合しています。このモデルは、以前のMistral Medium 3.1およびMagistralモデルに取って代わり、VibeプログラミングエージェントのDevstral 2も置き換えました。
オンラインで実行:https://go.hyper.ai/PXiHc
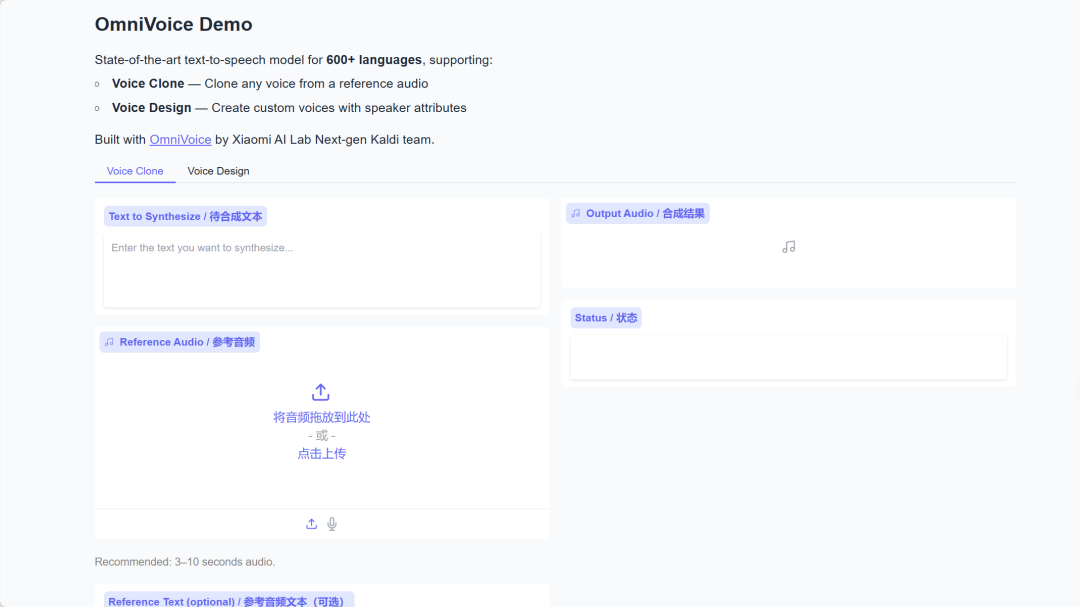
4. OmniVoice:600以上の言語で高品質なTTS(テキスト音声合成)をサポートします。
OmniVoiceは、Xiaomi AI Labの次世代Kaldiチームが開発した多言語対応のテキスト音声合成(TTS)モデルで、600以上の言語で高品質な音声合成をサポートしています。反復型マスク解除デコードアーキテクチャに基づき、音声クローン、音声デザイン、自動音声生成という3つの主要機能を実装しています。
オンラインで実行:https://go.hyper.ai/7F7IR
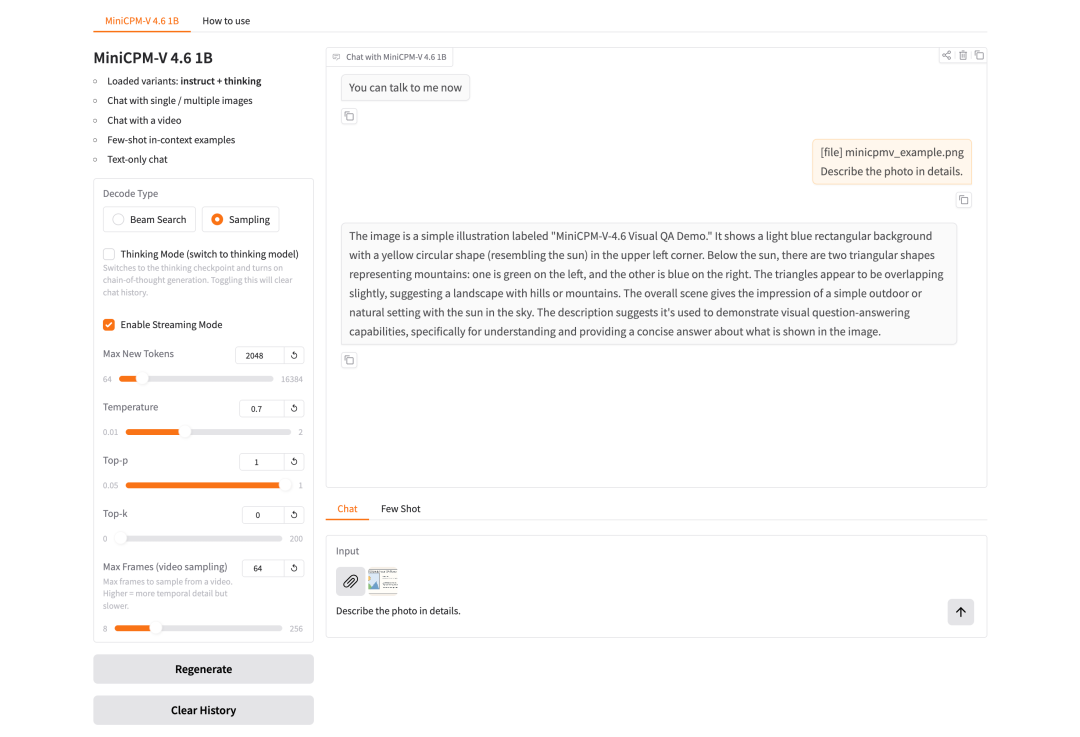
5. MiniCPM-V-4.6:エッジデバイス向け高効率マルチモーダル視覚言語モデル
MiniCPM-V-4.6は、OpenBMBチームと清華大学自然言語処理研究所によって2026年5月にリリースされた、画像理解、動画理解、視覚的質問応答、OCR、および複数ターンのマルチモーダル対話シナリオに対応する効率的なエッジサイドマルチモーダル視覚言語モデルです。その核心的な価値は、比較的小さなモデルサイズで一般的なマルチモーダル理解タスクを網羅している点にあり、リソース制約のある環境における画像質問応答、ショートビデオ要約、スクリーンショット理解、文書画像OCR、および複数ターンのマルチモーダル対話検証に最適です。
オンラインで実行:https://go.hyper.ai/azdHU
6. LingBot-Map:ストリーミング3D再構成のための幾何学的コンテキスト変換ツール
LingBot-Mapは、Robbyantチームが2026年4月にリリースしたストリーミング3D再構築プロジェクトです。このプロジェクトは、画像シーケンスまたはビデオフレームを入力として受け取り、フィードフォワード方式でオンライン3Dシーン再構築を実行できます。点群、カメラ軌跡、フレームごとの結果は、ブラウザ上の3Dビューアで表示できます。
オンラインで実行:https://go.hyper.ai/BR4me

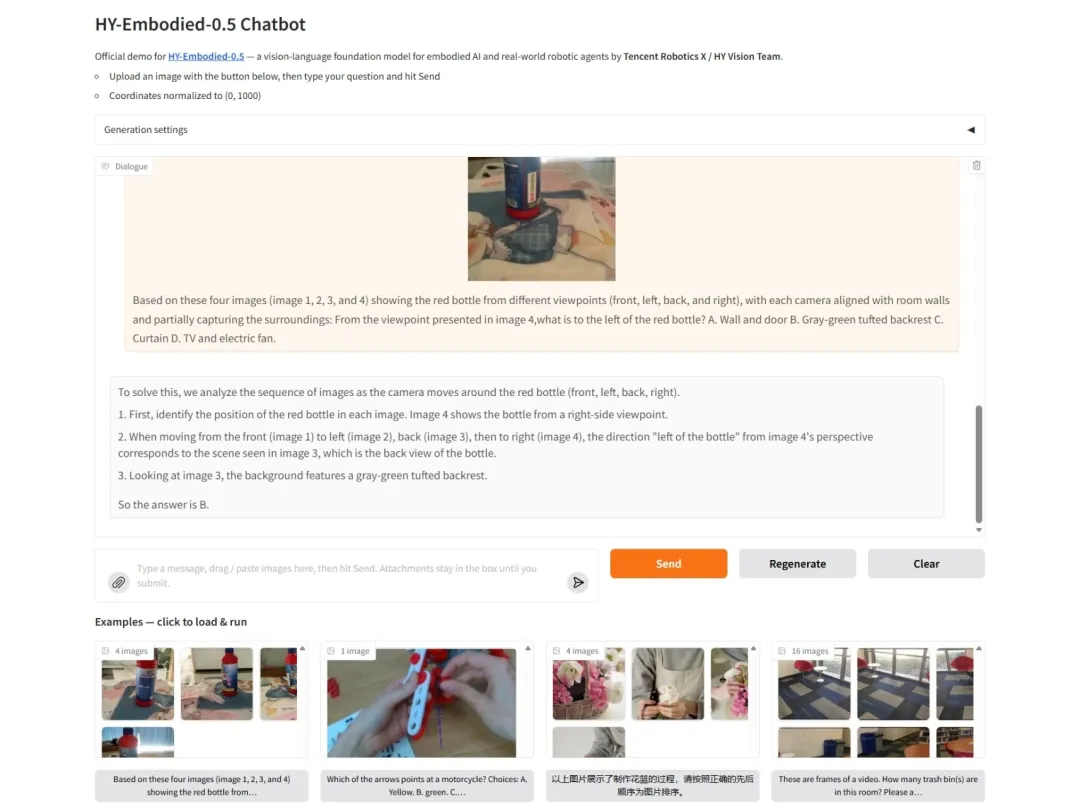
7. HY-Embodied-0.5:実世界のインテリジェントエージェントのための具現化された基盤モデル
HY-Embodied-0.5 は、身体化された知能のために特別に設計された基盤モデルであり、2026 年 4 月に Tencent の Hunyuan チームと Tencent Robotics X Lab が共同でオープンソース化しました。この一連のモデルは、汎用ベースの単純な微調整ではなく、アーキテクチャからトレーニング パラダイムまで完全に再構築されています。チームは同時に 2 つの主要モデルをリリースしました。リアルタイムのエッジサイド応答に焦点を当てた MoT-2B (合計パラメータ 40 億、アクティベーション 20 億) と、究極の推論性能を追求する MoE-32B (合計パラメータ 407 億、アクティベーション 320 億) です。
オンラインで実行:https://go.hyper.ai/u8lJk
コミュニティ記事の解釈
1. MITなどが開発したGPU電力推定フレームワークであるEnergAIzerは、平均1.8秒で予測を完了し、誤差は約81 TP3Tです。
MITとMIT-IBMワトソンAIラボの研究者らは、AIワークロード向けの高速GPU電力推定フレームワークであるEnergAIzerを開発しました。EnergAIzerは、高価なシミュレーションや性能分析を必要とせずに、ハードウェア使用率情報を電力モデルに直接提供します。この新しいフレームワークは、エンドツーエンドの電力推定を平均わずか1.8秒で完了します。NVIDIA Ampere GPUでは、EnergAIzerは81 TP3T程度の電力誤差を実現しており、複雑な周期的シミュレーションやハードウェア性能分析に依存する従来のモデルと遜色ありません。
レポート全体を表示します。https://go.hyper.ai/1PeMV
2. トークンの使用量は30%減少しました。「アバター」に触発された異種インテリジェントエージェントフレームワークであるEywaは、言語モデルとドメイン固有の基本モデルを効率的に組み合わせます。
イリノイ大学アーバナ・シャンペーン校(UIUC)の研究チームは、言語エージェントとドメイン固有の基盤モデルを接続するための異種エージェントフレームワークであるEywaを提案した。研究者らは、ドメイン固有の基盤モデルと言語モデルを組み合わせることで、新しいEywaAgentを構築した。この設計により、言語エージェントは、基盤モデルの推論、計画、および意思決定プロセスを、その専門的なタスクにおいて誘導することができる。
レポート全体を表示します。https://go.hyper.ai/CzRL4
3. 100の大学が、世界最大規模の複数コホートを対象としたプロテオゲノミクス研究を開始した。この研究は、約8万人の参加者から得られたデータに基づいて、病気の原因となる遺伝子を解明し、既存の薬剤の用途転換を図るものである。
ロンドン大学クイーン・メアリー校やケンブリッジ大学を含む100以上の大学および研究機関からなるチームが、これまでで世界最大規模のマルチコホート・プロテオゲノミクス研究を発表しました。38の独立した研究コホートと合計78,664人の参加者を対象としたプロテオグリフィックスの大規模なメタ解析に基づき、この研究では24,738個のタンパク質の量的形質遺伝子座を体系的に特定し、それらを1,116個の循環タンパク質と関連付け、タンパク質レベルでの広範な近接および距離遺伝子制御特性を包括的に明らかにしました。
レポート全体を表示します。https://go.hyper.ai/lGD68
人気のある百科事典の項目を厳選
1. 世界モデル
2. 校正曲線
3. ゲート型注意
4. 人間が関与するプロセス
5. 相互ランク融合
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 2100以上の公開データセット向けに、国内高速ダウンロードノードを提供
* 700以上の定番かつ人気のオンラインチュートリアルを収録
* 300件以上のAI4Science論文事例を分析
* 700以上の関連用語の検索に対応
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








