Command Palette
Search for a command to run...
RL+OPDを用いて学習させたMiniCPM5-1Bは、複数の複雑なタスクにおいて最先端(SOTA)の性能を達成しました。また、複雑な医療プロセスの自動化を目的として設計された、医療薬剤の評価用データセットであるCHI-Benchが公開されました。

MiniCPM5-1Bは、10億個のパラメータを持つオープンソースの言語モデルで、エッジ環境への展開やリソース制約のあるシナリオ向けに設計されています。MiniCPM5シリーズの最初のモデルです。標準的なLlamaアーキテクチャをベースに、以下のような機能を導入しています。タグに基づくハイブリッド推論パラダイム。さらに、このモデルは高度なRL+OPDトレーニング技術を活用することで、コアパフォーマンスを大幅に向上させると同時に、出力の冗長性を効果的に排除します。最大131,000文字の超長文コンテキストをネイティブにサポートします。エージェント呼び出しやコード合成といった複雑なタスクにおいて、1Bレベルのオープンソース最先端技術(SOTA)レベルを達成している。このモデルは、クラウドベースの推論における遅延やプライバシーの問題を効果的に回避し、効率的なローカルAIプラットフォームを構築するための理想的なソリューションを提供する。
HyperAIのウェブサイトに「MiniCPM5-1B:エッジアプリケーション向け高効率1B LLM」が掲載されました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/OBlhv
より詳しい情報については、弊社の公式ウェブサイトをご覧ください。
5月30日から6月5日までのhyper.aiウェブサイトの更新内容の概要:
* 高品質の公開データセット: 6
* 厳選された高品質チュートリアル:5つ
* コミュニティ記事分析:1件
* 人気のある百科事典のエントリ: 5
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. chi-bench 医療インテリジェントエージェントベンチマーク評価データセット
chi-benchは、Actava AIが2026年にリリースした医療エージェント評価データセットです。このデータセットは、MCP(Model Context Protocol)オープンインターフェースを介して20の医療アプリケーションシステムを統合し、1,279件の医療業務文書を含む知識ベースを提供することで、高精度の医療業務シミュレーション環境を構築します。評価シナリオは、米国の医療制度における3つの主要分野、すなわち事前承認管理、健康保険/保険会社向けの請求管理、および集団ケア管理を網羅しています。
オンラインでの使用:https://go.hyper.ai/j8pCr
2. SMOL多言語翻訳並列データセット
SMOLは、Googleが2025年に公開したプロによる翻訳データセットです。このデータセットには、アムハラ語、スワヒリ語、アファール語を含む221言語のプロによる翻訳テキストに加え、データが少ない地域言語や、これまであまり注釈が付けられてこなかった言語も含まれています。プロによる翻訳とボランティアによるテキストの両方を含む幅広い言語ペアを網羅しており、一部の言語については医療分野に関連する専門的なデータや事実に基づいた注釈も追加されています。
オンラインでの使用:https://go.hyper.ai/84QS4
3. TACKターゲットキメラ知識ベースデータセット
TACKは、AI Laboratory for Molecular Engineeringが2026年に公開した、標準化された知識ベースデータセットおよびベンチマークセットです。既存のPROTAC機械学習ベンチマークにおけるデータ不足、厳密な評価の欠如、および対象範囲の限定といった問題に対処することを目的としています。PROTAC分解活性予測、標的タンパク質分解(TPD)研究、AI支援創薬(AIDD)、コンピュータ支援創薬(CADD)、仮想創薬スクリーニング、マルチタスク学習、分子特性予測、グラフニューラルネットワーク研究、機械学習ベンチマークテストなど、幅広い分野で活用されています。
オンラインでの使用:https://go.hyper.ai/7gDJu
4. EAVSD(電子商取引広告ビデオストーリーボードデータセット)
EAVSDは、北京大学の研究チームが2026年に公開した、eコマース広告動画のストーリーボードデータセットです。主題指向型の複数画像生成と物語構成のタスクを支援することを目的としています。このデータセットは、主題指向型の複数画像生成と物語構成のタスクで広く使用されており、特にeコマース広告動画のストーリーボード生成と、制御可能な長距離視覚的一貫性の研究に重点を置いています。
オンラインでの使用:https://go.hyper.ai/hyzLx
5. DeepCrackインフラストラクチャ亀裂検出データセット
DeepCrackは、武漢大学コンピュータビジョン・リモートセンシング研究所が提供する、インフラひび割れ検出のためのベンチマークデータセットです。ひび割れ検出アルゴリズムの研究に対し、標準化された高精度な教師あり学習データを提供することを目的としています。U-Net、DeepLab、SegNetなどの深層学習モデルの学習や評価に直接使用でき、構造健全性モニタリング、道路検査、建物の欠陥識別といった研究分野で幅広く活用されています。
オンラインでの使用:https://go.hyper.ai/88zlH

6. 世界の大気汚染とAQIデータセット
世界大気汚染・大気質指数(AQI)は、研究およびデータ分析のためのグローバルな大気質データセットです。このデータセットには、2014年から2025年までの月ごとの都市レベルの観測データが含まれており、合計331,920件の記録があります。対象地域は、中国、米国、英国、フランス、ドイツ、日本、韓国を含む5大陸24か国です。データセットには、大気汚染物質濃度、大気質指数、気象変数、社会・環境指標など、24種類の特徴量が含まれています。
オンラインでの使用:https://go.hyper.ai/QL8VK
選択された公開チュートリアル
1. MiniCPM5-1B:エッジサイドアプリケーション向け高効率1B LLM
MiniCPM5-1Bは、OpenBMBチームがリリースしたMiniCPM5シリーズの最初のモデルです。エッジ環境への展開やリソース制約のあるシナリオ向けに設計されています。10億個のパラメータを持つTransformerアーキテクチャを採用し、同規模のオープンソースモデルの中で最先端のパフォーマンスを実現しています。特に、エージェントツールの呼び出し、コード生成、および難易度の高い推論タスクにおいて優れた性能を発揮します。
オンラインで実行:https://go.hyper.ai/OBlhv
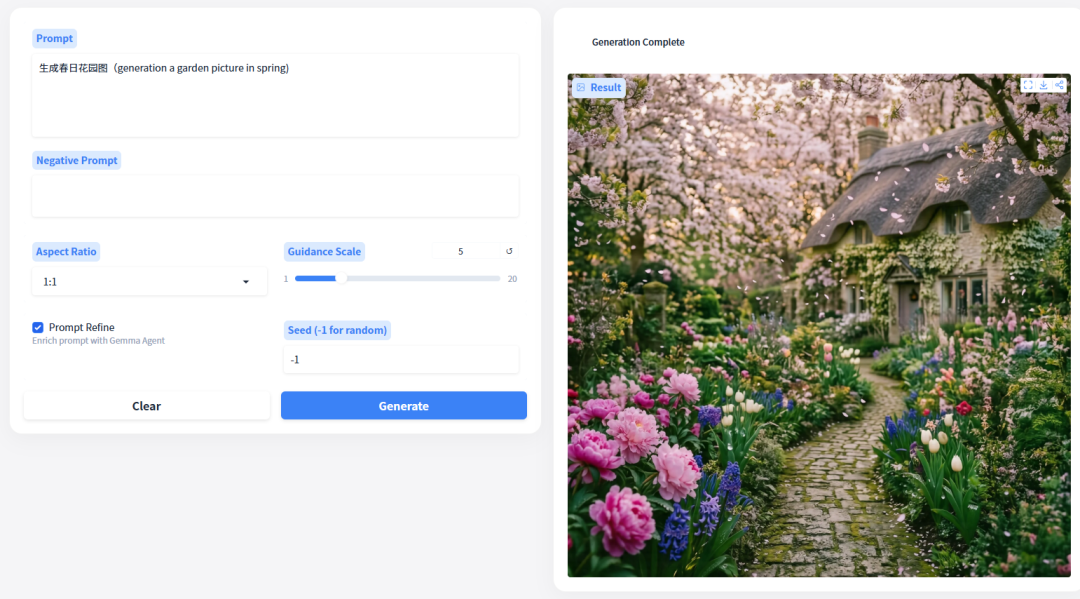
2. HiDream-O1-Image 画像生成システム
HiDream-O1-Imageは、HiDream.aiチームが2026年に発表した、ネイティブな統合画像生成基盤モデルです。このモデルは、ピクセルレベルの統合型Transformer(UiT)アーキテクチャに基づいて構築されています。従来のモデルとは異なり、外部のVAEや個別のテキストエンコーダーに依存せず、ピクセルとテキストを単一の共有トークン空間内でネイティブにエンコードします。
オンラインで実行:https://go.hyper.ai/XkyGK
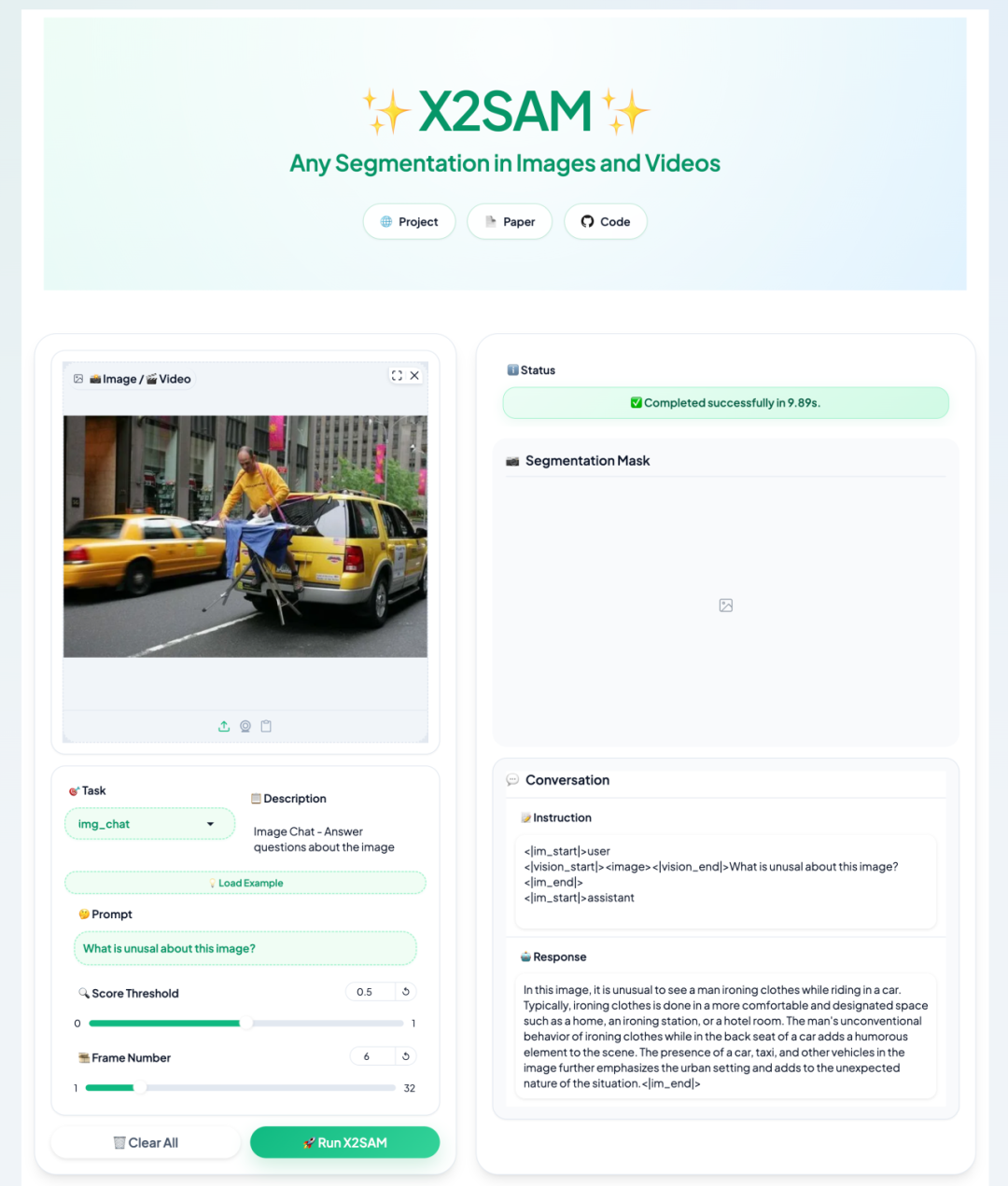
3. X2SAM:任意の画像および動画のセグメンテーションのための統一モデル
X2SAMは、中山大学、鵬城実験室、美団チームによって2026年4月にリリースされた、画像と動画のセグメンテーションを統合したマルチモーダル大規模モデルです。このプロジェクトの核となる特徴は、テキストプロンプト、ビジュアルプロンプト、画像/動画セグメンテーションを単一のインタラクティブなプロセスに統合している点です。
オンラインで実行:https://go.hyper.ai/OAndb
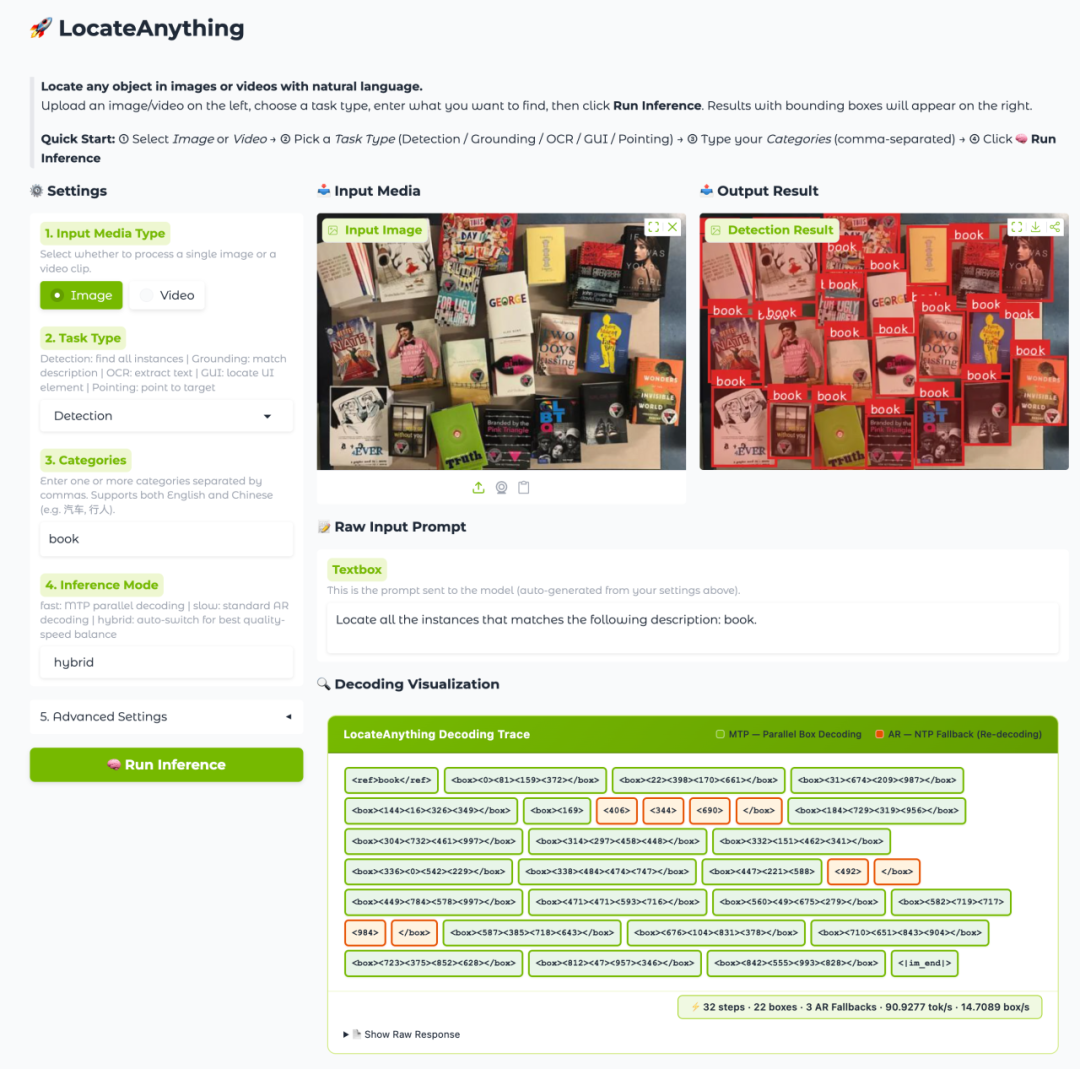
4. LocateAnything-3B:高速かつ高品質な視覚言語ローカライズモデル
NVIDIAが2026年にリリースしたLocateAnything-3Bは、Eagle VLMシリーズの3Bパラメータ視覚言語ローカリゼーションモデルで、オープンオブジェクト検出、ポイント表現ローカリゼーション、OCRテキストローカリゼーション、GUI要素ローカリゼーション、画像や動画内のポインティングなどのタスク向けに設計されています。このモデルのコア機能は並列ボックスデコードです。トークンごとの自己回帰によって座標を生成するのではなく、構造化されたブロックとして完全なバウンディングボックス座標を並列に予測することで、幾何学的一貫性を維持しながらローカリゼーションのスループットを向上させます。
オンラインで実行:https://go.hyper.ai/DxUFC
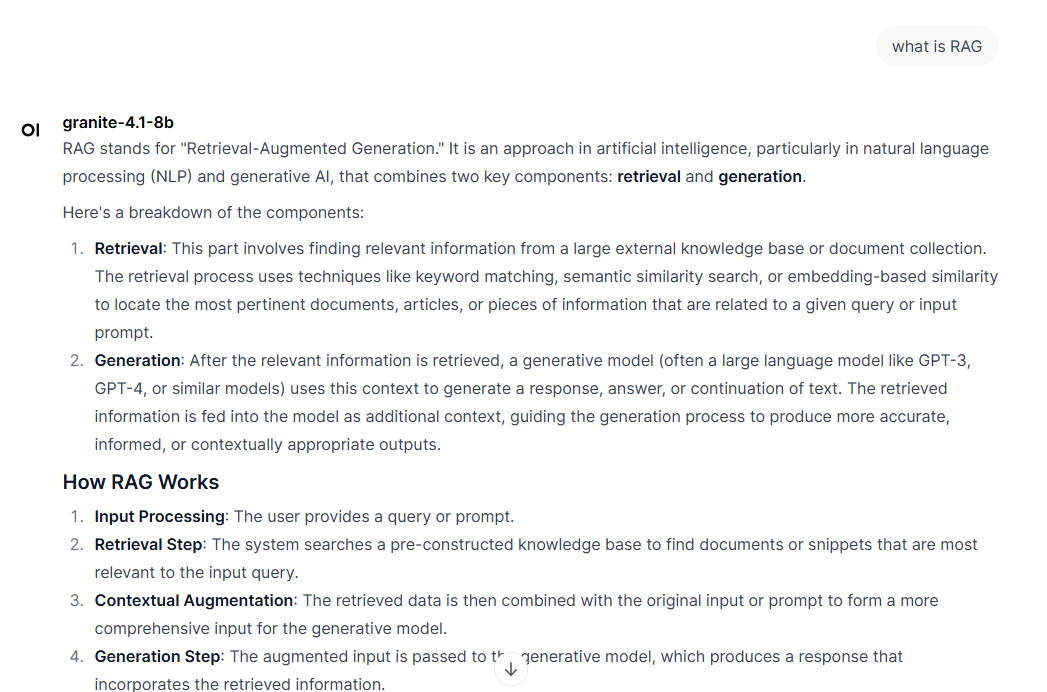
5. Granite 4.1 8B: ダイアログ、エンコーディング、RAG、およびツール呼び出しをサポートします。
Granite 4.1 言語モデルは、IBM が 2026 年に発表した新世代のオープンソース基盤モデルであり、3B、8B、30B の 3 つのスケールで高密度デコーダ アーキテクチャを網羅しています。このシリーズの高性能バージョンである Granite 4.1 8B は、軽量なパラメータ スケールを維持しながら、エンタープライズ アプリケーションに必要な優れたパフォーマンスを実現します。このモデルは、多言語機能、幅広いエンコード タスク、検索強化生成 (RAG)、ツールの使用、構造化 JSON 出力などをネイティブにサポートし、実世界のアプリケーションに堅牢な技術サポートを提供します。
オンラインで実行:https://go.hyper.ai/Fpzl7
コミュニティ記事の解釈
1. シンガポール国立大学は、糖尿病性創傷治癒のための薬剤の用途転換を加速させるAIと計算化学の協働プロセスを提案しており、研究開発サイクルを701 TP3T以上短縮できるとしている。
シンガポール国立大学の研究チームは、人工知能と計算化学(AI-CC)を組み合わせた、共同的な計算ナノ医療研究プロセスを提案した。このプロセスは、大規模言語モデルによる文献マイニング(定性的洞察)と、計算化学を主体とした多段階分子シミュレーション(定量的検証)を密接に連携させ、薬剤とタンパク質のナノ相互作用に関する閉ループ研究システムを構築し、糖尿病性創傷治癒のための薬剤の用途変更と開発を加速させる。
レポート全体を表示します。https://go.hyper.ai/OXs3N
人気のある百科事典の項目を厳選
1. 世界行動モデル(WAM)
2. 視覚言語行動モデル(VLA)
3. 人間が関与するプロセス
4. 展開しながら学ぶ
5. 相互ランク融合
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 2100以上の公開データセット向けに、国内高速ダウンロードノードを提供
* 700以上の定番かつ人気のオンラインチュートリアルを収録
* 300件以上のAI4Science論文事例を分析
* 700以上の関連用語の検索に対応
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








