Command Palette
Search for a command to run...
実写/アニメーション/動物を主体とした動画生成をサポート。Meituanのオープンソースのマルチスタイル音声駆動型動画生成フレームワークLongCat 1.5は、百万レベルのチャート理解データセットChartNetを使用して、VLMのチャート再構築およびテーブル抽出機能を強化します。

Meituan LongCatチームが2026年5月にリリースしたLongCat-Video-Avatar 1.5は、全く新しいオープンソースの音声駆動型ビデオ生成(AI2V)フレームワークです。ユーザーは静止画の参照画像と音声クリップを提供するだけで、正確なリップシンクを備えた動的なアバター動画を生成できます。このモデルは、ウィスパー駆動型の音声特徴抽出を採用しています。ステップ蒸留技術により、DiT生成プロセスをわずか8ステップという極めて高速な処理に圧縮することで、高精細な映像だけでなく、長時間の動画コンテンツの生成も可能にします。実写ポートレート、2D/3Dアニメキャラクター、動物アバターなど、幅広い対象に対応できる汎用性を備え、マルチシーン動画生成のための効率的かつ信頼性の高いソリューションを提供します。
HyperAIのウェブサイトに「LongCat-Video-Avatar 1.5 デジタルヒューマンモデル」が登場しましたので、ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/NROTv
より詳しい情報については、弊社の公式ウェブサイトをご覧ください。
hyper.aiの公式サイトにおける6月6日から6月12日までの更新内容の概要は以下のとおりです。
* 高品質の公開データセット: 6
* 高品質なチュートリアルのセレクション: 3
* コミュニティ記事の解釈:3件
* 人気のある百科事典のエントリ: 5
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. ChartNetチャートによるマルチモーダルデータセットの理解
ChartNetは、MITがIBM Researchをはじめとする複数の研究機関と共同で2026年に公開した、大規模かつ高品質なマルチモーダルデータセットです。幾何学的な視覚パターン、構造化された数値データ、テキストによる説明を組み合わせた推論において、既存モデルの欠点を克服することを目的としています。このデータセットには、420万点の合成チャートサンプル、9万4643点の手動検証済みチャートサンプル、そして3万点の実世界のチャートが含まれており、24種類のチャートタイプと6種類のプロットライブラリを網羅しています。
オンラインでの使用:https://go.hyper.ai/0CNr7
2. OpenSAL360パノラマビデオ顕著性データセット
OpenSAL360は、視覚的注意、顕著性予測、マルチモーダルビデオ分析の研究を支援するために設計された、現在最大規模の包括的なビデオ顕著性データセットです。このデータセットには、YouTubeから収集された500本の多様なパノラマビデオが含まれており、平均再生時間は18.1秒、データ注釈は2,000人以上の観察者によって行われています。
オンラインでの使用:https://go.hyper.ai/u7NqD
3. 映画に対する感情データセット
Movie Feelingsは、映画が喚起するきめ細やかな感情を体系的に特徴づけるために設計された、映画の感情特徴量データセットです。これは、肯定的/否定的感情や基本的な感情のみに基づく従来の分類の限界を打破するものです。このデータセットには、1920年から2024年までの代表的かつ文化的に影響力のある映画1,500本が収録されており、50種類の感情状態を網羅しています。
オンラインでの使用:https://go.hyper.ai/b4m71
4. FigureBench: 科学イラスト用のベンチマークデータセットを生成する。
FigureBenchは、ウェストレイク大学のテキストインテリジェンスラボが2026年に公開した、科学イラスト生成のためのベンチマークデータセットです。長文の科学テキストから高品質な科学イラストを自動生成するという課題を解決することを目的としており、自動科学イラスト生成の研究にとって、挑戦的で多様なテストプラットフォームを提供します。
オンラインでの使用:https://go.hyper.ai/Agaku
5. AIによる学生への影響:AI支援学習はデータセットに影響を与える。
AI学生影響データセットは、高等教育における学習シナリオにおける生成型AIツールの現実世界への影響を体系的に分析するために設計された、複数の側面を網羅する大規模な教育行動データセットです。このデータセットには、50,000人の学生サンプルと16の構造化された特徴フィールドが含まれており、学生の学歴、AI利用行動、学習行動、所属機関、メンタルヘルス状態、アプリケーションシナリオなどのデータが網羅されています。
オンラインでの使用:https://go.hyper.ai/zWoGM
6. ノイズの多い医療文書画像データセット
Noisy Medical Documentは、OCRおよび医療文書理解タスク向けに設計された、ノイズを強調した医療文書画像のデータセットです。実際の医療現場で文書をスキャンする際に発生する複雑なノイズ干渉をシミュレートし、実環境におけるOCRおよび文書理解モデルの堅牢性と汎化能力を向上させることを目的としています。このデータセットには、病院の請求書500枚と退院サマリー500枚を含む、1,000枚の高精細な合成医療文書画像が含まれています。
オンラインでの使用:https://go.hyper.ai/kL7gc
選択された公開チュートリアル
1. LongCat-Video-Avatar 1.5 デジタルヒューマンモデル
Meituanチームが2026年5月にリリースしたLongCat-Video-Avatar 1.5は、新たにアップグレードされたオープンソースの音声駆動型動画生成(AI2V)フレームワークです。静止画の参照画像と音声クリップだけで、非常にリアルで完璧に口パクされたダイナミックなアバター動画を生成でき、複雑な現実世界のシーンはもちろん、アニメーションや動物などの様式化された被写体も容易に処理できます。
オンラインで実行:https://go.hyper.ai/NROTv
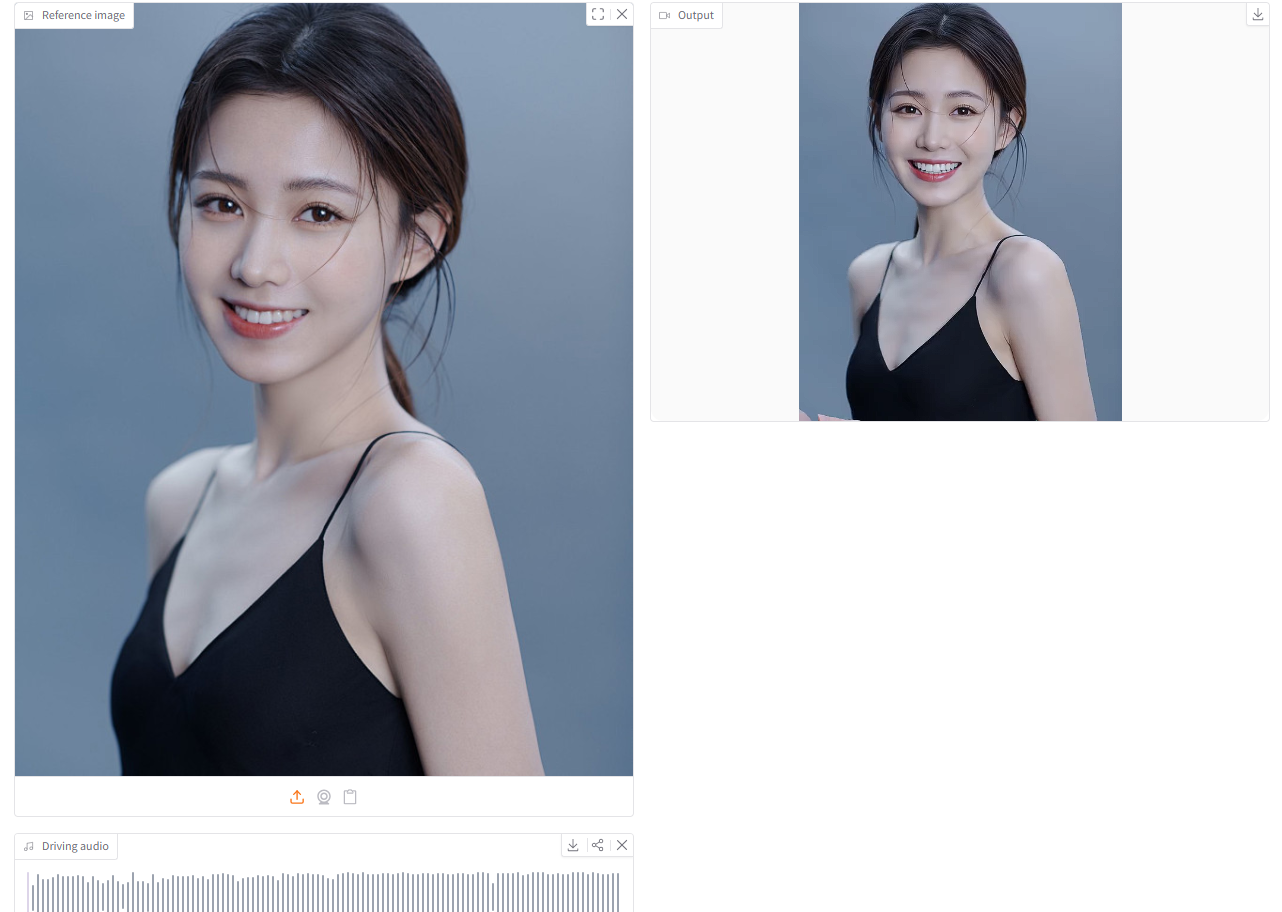
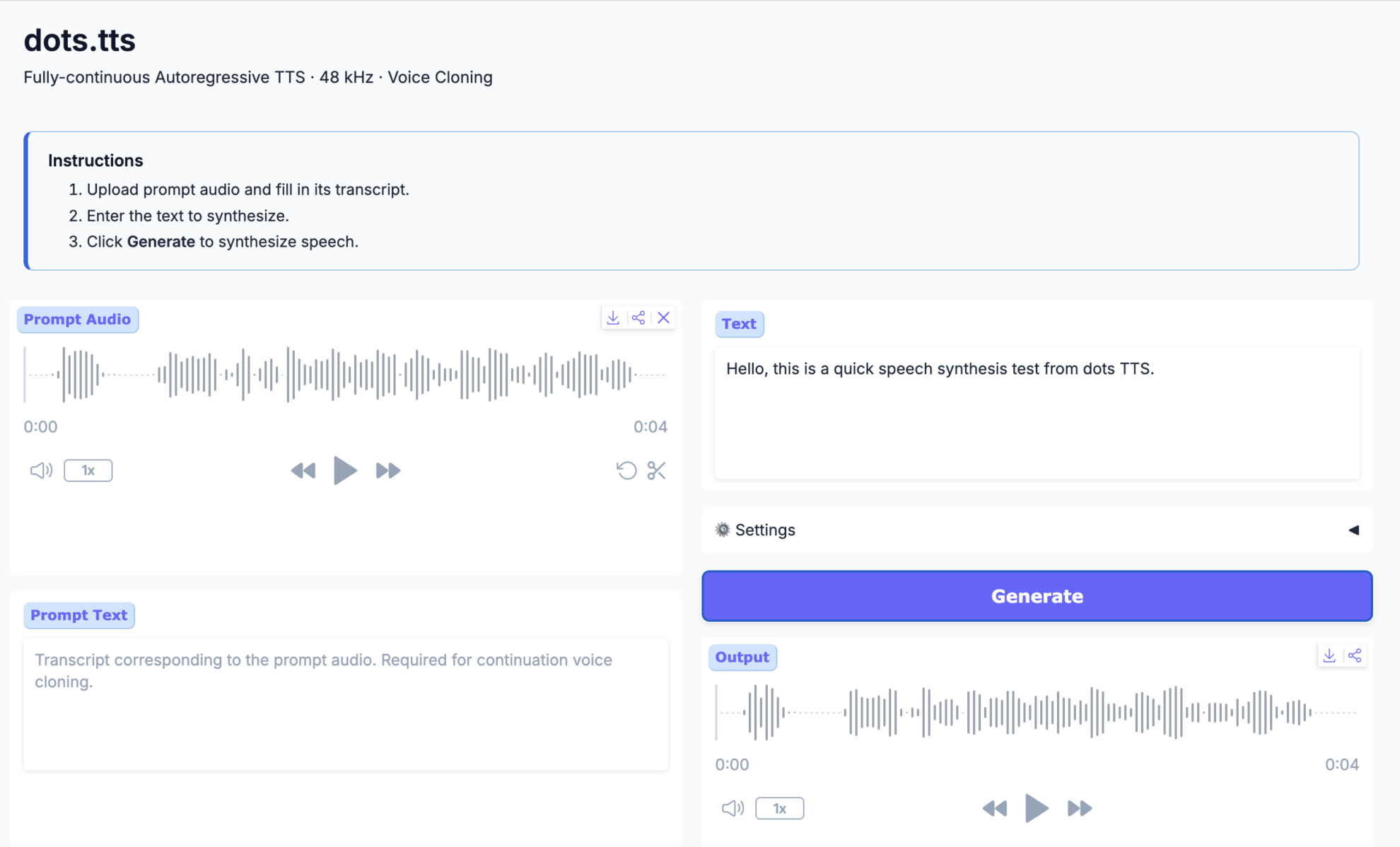
2. dots.tts: 完全連続型の自己回帰型テキスト音声合成システム
rednote-hilabが2026年6月にリリースしたdots.ttsは、2Bパラメータ、完全連続、エンドツーエンドの自己回帰型テキスト音声変換システムです。その基盤となるのは、セマンティックエンコーダ、LLM、および自己回帰型フローマッチング音響ヘッドです。離散的な音声トークンを使用せず、48kHz AudioVAEに基づいて連続的な音声表現を直接モデル化します。
オンラインで実行:https://go.hyper.ai/YT3g3
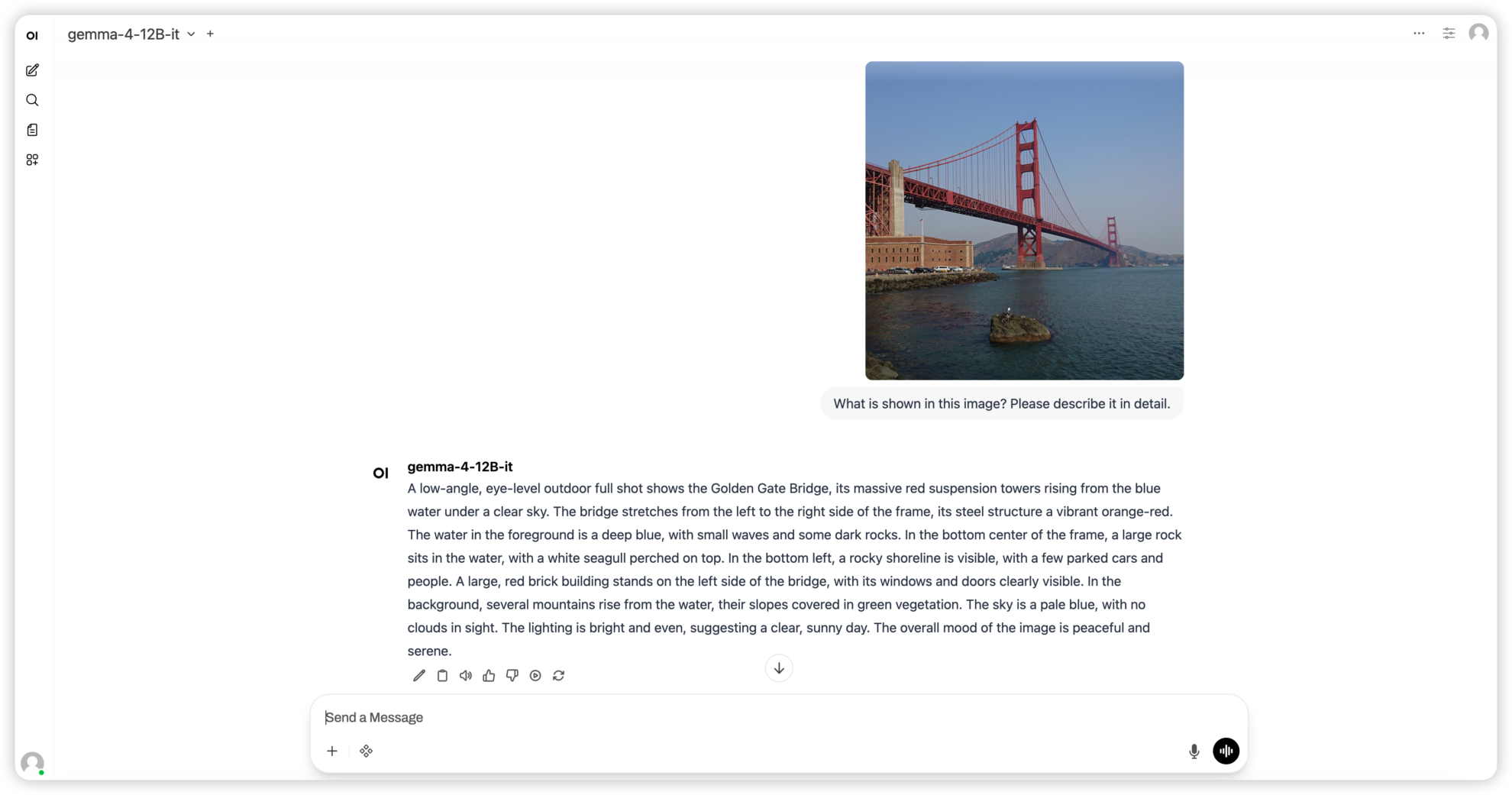
3. Gemma4 12B-it: グラフ、テキスト、音声の統合マルチモーダルモデル。
Gemma 4 12B-itは、Google DeepMindがリリースしたGemma 4シリーズの統合型マルチモーダルモデルです。エンコーダー不要のアーキテクチャを採用し、画像と音声をLLMの埋め込み空間に直接投影します。個別のエンコーダーなしでテキスト、画像、音声の各モダリティを処理でき、12Bパラメータレベルで強力な推論、符号化、マルチモーダル理解能力を実現します。
オンラインで実行:https://go.hyper.ai/0713z
コミュニティ記事の解釈
1. 科学者たちは、220種の海洋細菌に基づいて、ゲノム規模のモデルを用いて従属栄養微生物の分類体系を再構築し、8種類の代謝フローラを特定した。
南カリフォルニア大学が率いる研究チームは、世界的な海洋微生物データベースとゲノム規模の代謝モデルを用いて、膨大な量の海洋細菌ゲノムを分析した。11種類の有機基質の利用に対する微生物の感受性を定量化することで、8つの異なる代謝群集を特定した。
レポート全体を表示します。https://go.hyper.ai/dfq8T
2. 深度推定精度は0.9に達し、MetaはVLM³を提案し、視覚モデルが本質的に3Dを学習できることを示し、Qwen3-VL-4Bに基づいて複数のタスクの統一モデリングを実現しました。
Metaはプリンストン大学と共同で、標準的な視覚言語モデルに基づき、統一されたデータ構成方法とトレーニングパラダイムを通して、オブジェクトレベルの3D理解、メトリック深度推定、ピクセルマッチング、カメラ姿勢解決という4種類のタスクに対して統一的なモデリングを実現するVLM³を提案した。また、標準的なVLMのきめ細かい3D知覚における能力限界を体系的に評価した。
レポート全体を表示します。https://go.hyper.ai/NihJA
3. ケンブリッジ大学などが地球観測ミッションのためのピクセルレベルの基本モデルを提案し、複数のミッションで最先端の精度を達成した。
ケンブリッジ大学、アールト大学、ブリストル大学の共同研究チームは、バーロウ・ツインズ・アルゴリズムに基づいた新しい時間的特徴学習パラダイムを開発しました。このパラダイムにより、モデルは地球表面の安定した時空間変動を自律的に学習し、時間的サンプリング不変性を備えたリモートセンシング特徴表現を形成することが可能になります。この基盤の上に、研究チームはさらに、Sentinel-1/Sentinel-2マルチモーダル時系列データのためのピクセルレベルのリモートセンシング基盤モデルであるTESSERAを提案しました。
レポート全体を表示します。https://go.hyper.ai/S3KBr
人気のある百科事典の項目を厳選
1. 世界行動モデル(WAM)
2. 説明可能な人工知能(XAI)
3. 視覚言語行動モデル(VLA)
4. ルールベースシステム
5. 相互ランク融合
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 2100以上の公開データセット向けに、国内高速ダウンロードノードを提供
* 700以上の定番かつ人気のオンラインチュートリアルを収録
* 300件以上のAI4Science論文事例を分析
* 700以上の関連用語の検索に対応
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








