Command Palette
Search for a command to run...
オンラインチュートリアル | NVIDIAオープンソースLocateAnythingは、画像や動画のターゲットポインティング、オープンボキャブラリーオブジェクト検出、ターゲット位置特定、OCRテキスト位置特定などの機能を実現する3Bモデルです。

ビジュアル言語モデル(VLM)がエージェント、マルチモーダルなインタラクション、そして現実世界のタスクへと進化を続けるにつれ、「画像を理解すること」はもはや最終目標ではなくなり、より重要なのは「対象物を正確に特定すること」となっています。これは、オープンボキャブラリーの物体検出、GUIエージェントインターフェースの操作、文書理解、そしてロボット工学や自動運転システムにおける環境認識など、あらゆる分野に当てはまります。これらの要因すべてが、視覚的な接地能力に対する要求をますます高めている。
しかし、現在の主流のビジュアル言語モデルは、位置特定タスクを処理する際に一般的に「座標トークン生成」方式を採用しており、これは2次元の境界ボックスを複数の1次元座標トークンに分割し、それらを1つずつ生成およびデコードするというものです。このアプローチは、境界ボックスの内部形状の一貫性を維持するのに苦労するだけでなく、...さらに、厳密な逐次生成メカニズムは推論速度を制限する。モデルが多数のターゲットを同時に処理する必要がある場合、位置特定効率と精度とのバランスを取ることはしばしば困難である。
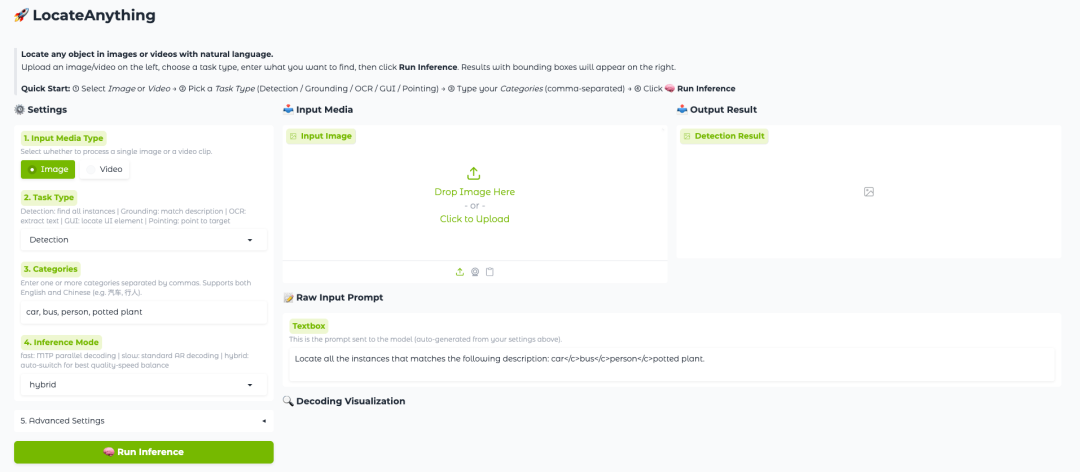
この長年のボトルネックに対応するため、NVIDIAは最近、Eagle VLMシリーズの新たなメンバーであるLocateAnything-3Bをオープンソース化した。これは30億個のパラメータを持つ視覚言語ローカライズモデルであり、オープンボキャブラリーオブジェクト検出、ポインタ表現ローカライズ、OCRテキストローカライズ、GUI要素ローカライズ、画像や動画におけるターゲットポインティングなど、さまざまなタスクをサポートし、統一された視覚的ローカライズおよび検出フレームワークの構築を目指しています。
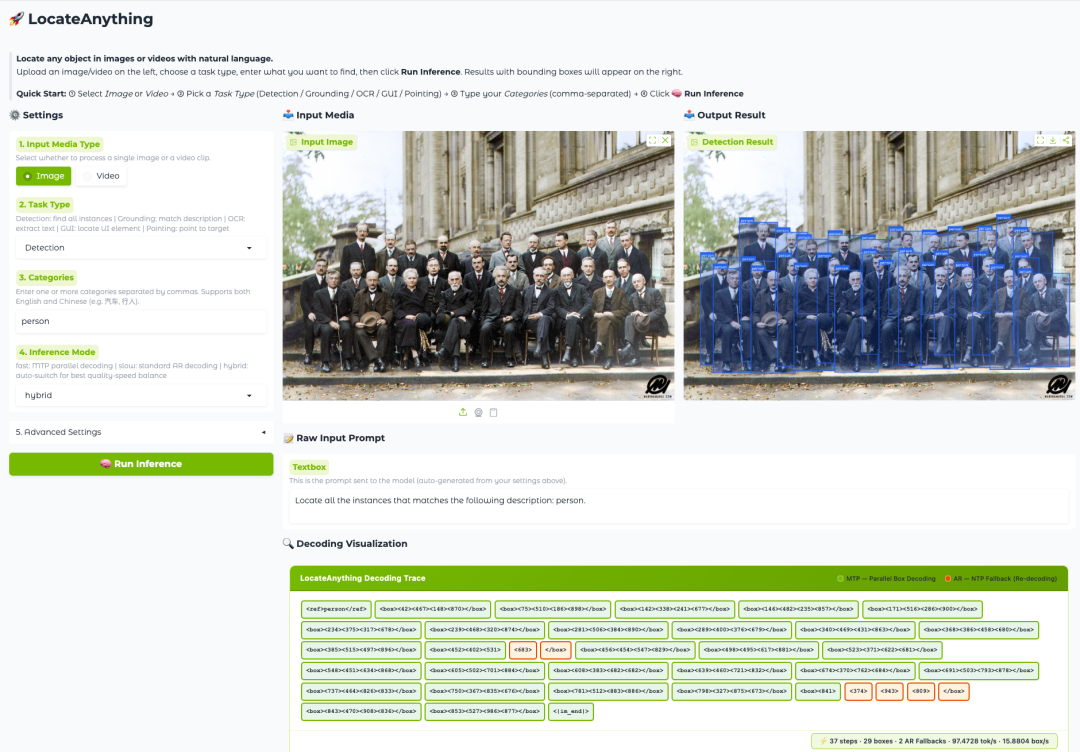
LocateAnything-3B の核となるイノベーションは、並列ボックスデコード (PBD) と呼ばれる新しいメカニズムから来ています。座標トークンを 1 つずつ生成する従来の方法とは異なり、PBDは、境界ボックスやキーポイントなどの幾何学的要素を、完全な構造として同時に並列に予測することができます。この設計は、境界ボックス内の幾何学的整合性を維持するだけでなく、デコード処理のスループットを大幅に向上させ、高精度な位置特定機能を維持しながら、モデルの推論速度を向上させることを可能にする。
NVIDIAは、アーキテクチャの革新にとどまらず、このモデルを基盤とした大規模なトレーニングシステムも構築しました。研究チームは拡張性の高いデータエンジンを開発し、LocateAnything-Dataデータセットを公開しました。このデータセットには、自然風景、ロボット工学、自動運転、GUI操作、文書理解、OCRなど、複数の分野を網羅した1億3800万を超えるトレーニングサンプルが含まれており、複雑なシナリオにおけるモデルの汎化能力を大幅に向上させています。
実験結果によると、LocateAnythingは複数の視覚位置特定ベンチマークにおいて、より高い位置特定精度とより速いデコード速度の両方を実現しており、統一された視覚位置特定モデルを従来の速度と精度のトレードオフの枠を超えて進化させています。急速に発展しているGUIエージェント、自動アノテーションシステム、そして次世代のマルチモーダルエージェントにとって、この効率的かつ高精度な空間認識能力は、インフラレベルの重要な機能となりつつあります。
現在、HyperAIの公式サイト(hyper.ai)のチュートリアルセクションでは、ノートブック形式で導入のハードルを下げる「LocateAnything-3B:高速かつ高品質なビジュアル言語ローカライゼーションモデル」が公開されています。
オンラインで実行:https://go.hyper.ai/4l9jB
その他のオンラインチュートリアル:
より詳しい情報については、弊社の公式ウェブサイトをご覧ください。
デモの実行
1. hyper.ai のホームページにアクセスしたら、「チュートリアル」ページを選択するか、「その他のチュートリアルを表示」をクリックし、「LocateAnything-3B: 高速かつ高品質なビジュアル言語ローカライズモデル」を選択して、「このチュートリアルを実行」をクリックします。
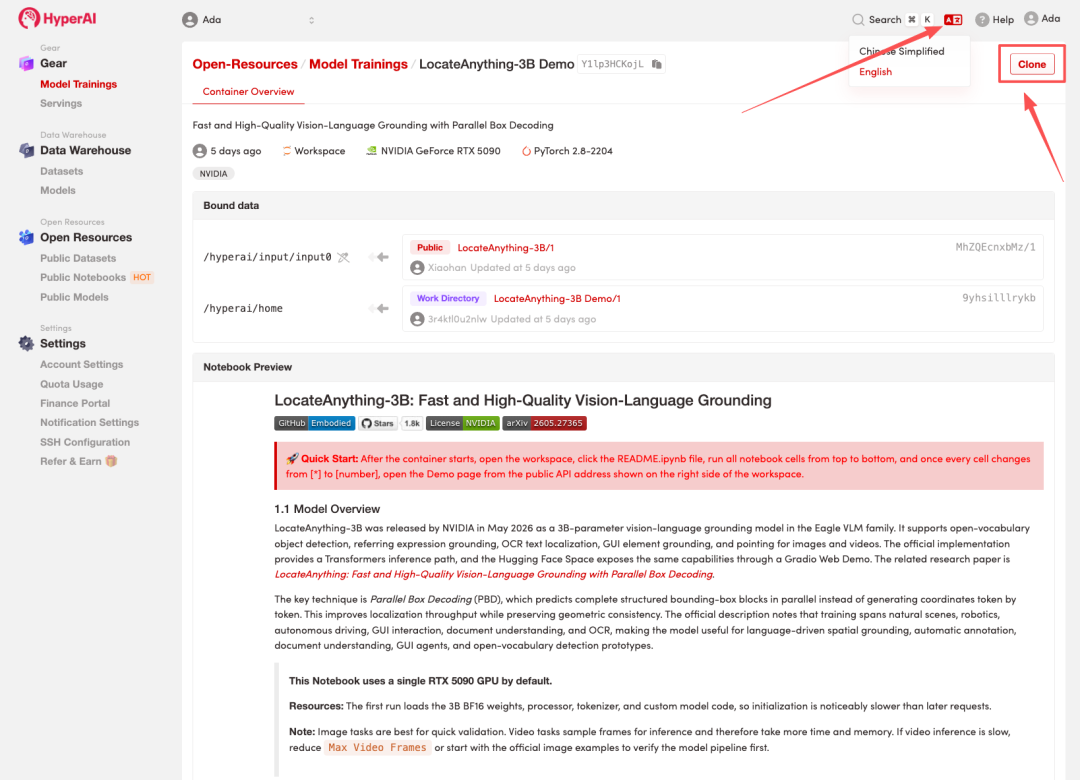
2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。
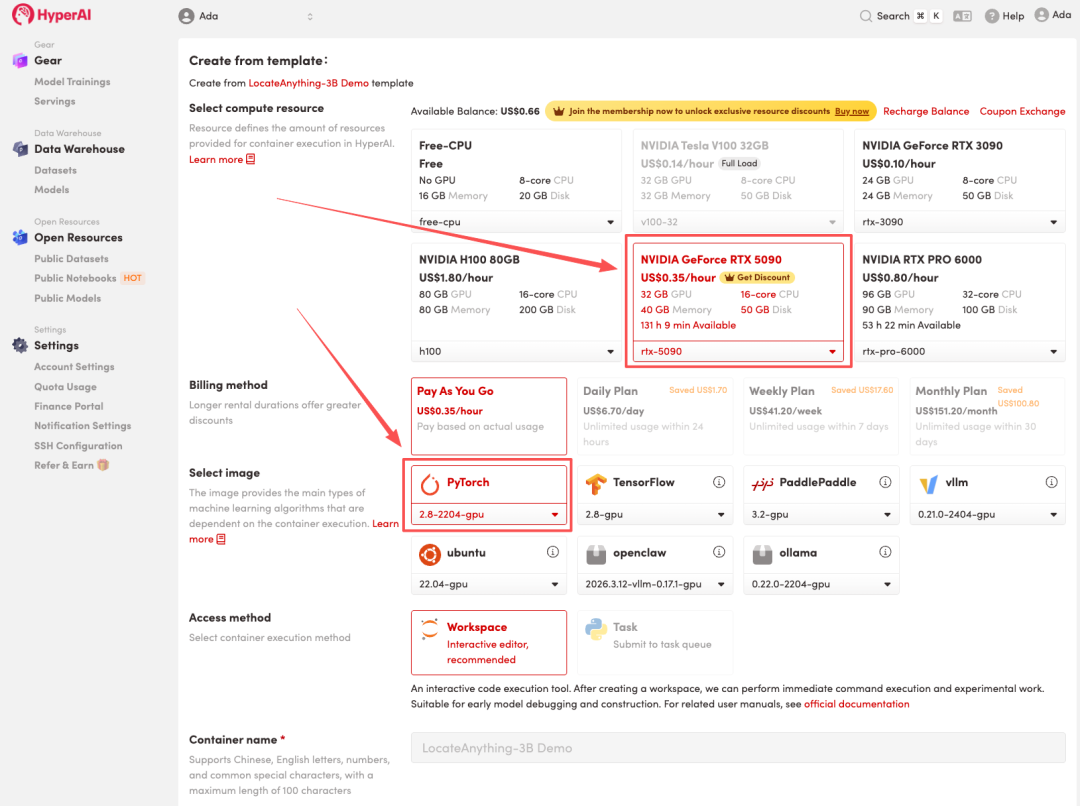
3. 「NVIDIA RTX 5090」と「PyTorch」の画像を選択し、「ジョブの実行を続行」をクリックします。
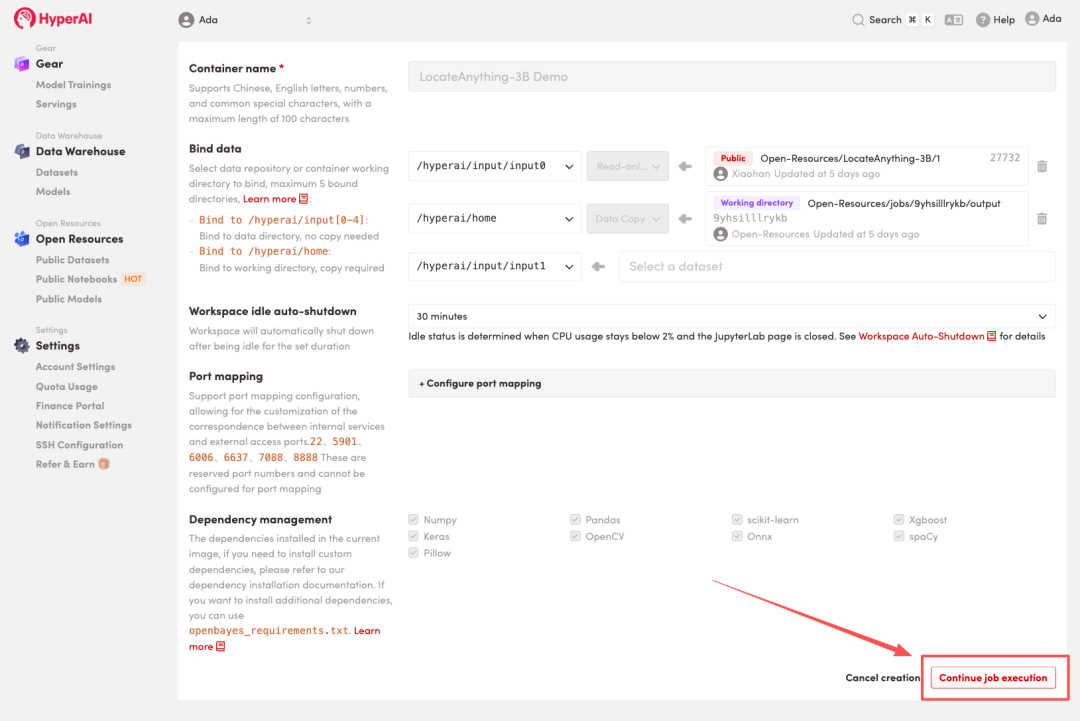
4. リソースが割り当てられるのを待ちます。ステータスが「実行中」に変わったら、「ワークスペースを開く」をクリックしてJupyterワークスペースに入ります。
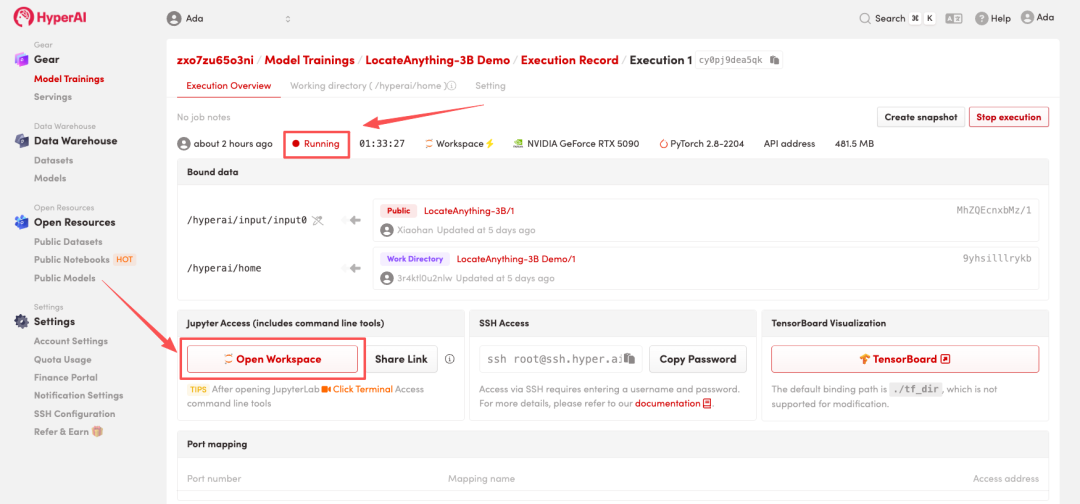
エフェクト表示
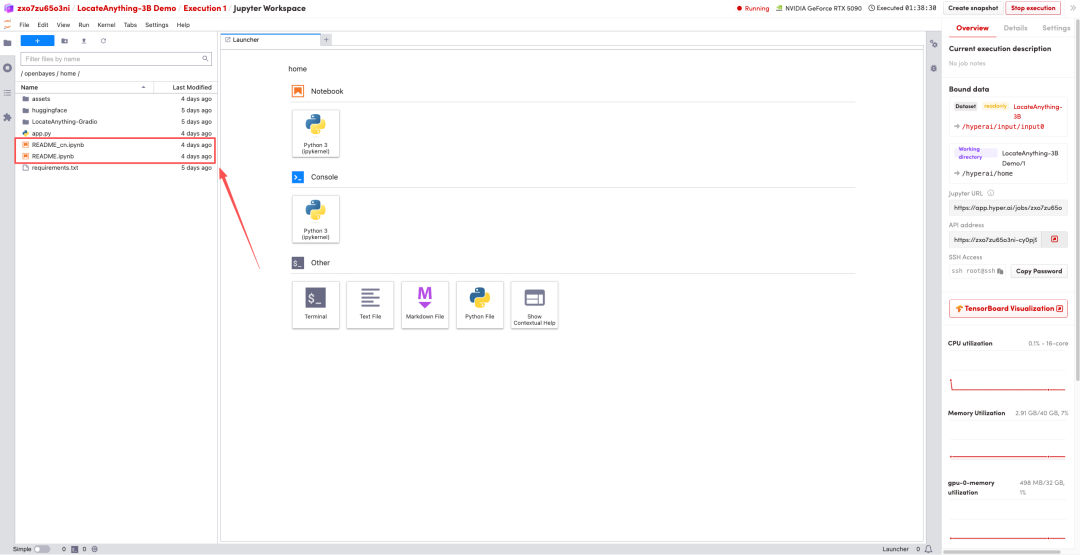
1. ページがリダイレクトされたら、左側のREADMEファイルをクリックし、上部の「実行」をクリックします。
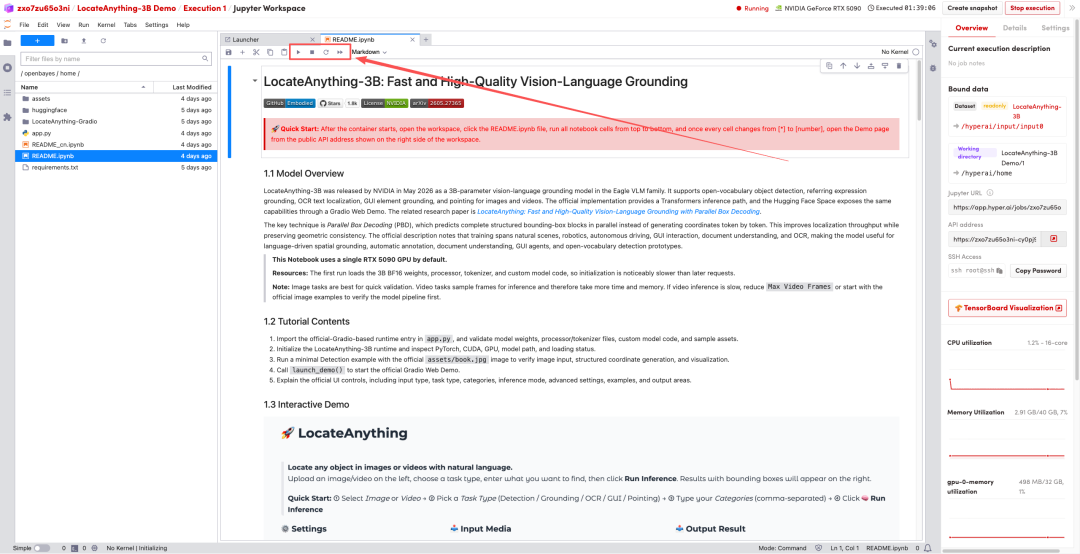
2. 処理が完了したら、右側のAPIアドレスをクリックしてデモページに移動します。