Command Palette
Search for a command to run...
深度推定精度が0.9に達したことで、MetaはVLM³を提案し、視覚モデルが本質的に3Dを学習する能力を持ち、Qwen3-VL-4Bに基づいて複数のタスクの統一的なモデリングを実現できることを示した。

三次元空間認識は、自動運転、ロボット工学、3D再構成などの分野における中核的な基礎能力です。その目標は、二次元画像から現実世界の空間構造、スケール情報、幾何学的関係を復元することです。画像分類や物体検出などの二次元視覚タスクと比較すると、三次元知覚には、意味理解能力だけでなく、正確な空間推論能力と幾何学的モデリング能力も必要となる。そのため、これはコンピュータビジョン分野において最も困難な研究課題の一つとして長らく認識されてきた。
近年、ビジュアル言語モデル(VLM)は、統一されたアーキテクチャと大規模な事前学習のおかげで、分類、検出、セグメンテーションなどの2Dタスクにおいて大きな進歩を遂げてきました。しかし、深度推定、ピクセルマッチング、カメラ姿勢決定など、精密な空間推論を必要とするきめ細かいタスクでは、標準的なVLMの性能は依然として専用の3Dモデルに劣っています。現在、3Dビジョン分野では、2Dビジョンに見られるような普遍的な基本モデルはまだ確立されていない。主流の手法は依然として、特定のタスク向けに設計された専門家モデルに依存している。これには、特殊なネットワーク構造、損失関数、およびトレーニング戦略が含まれます。
近年の研究により、特定の3D修正を加えていない標準的なビジュアル言語モデル(VLM)でも、ピクセルレベルの奥行き知覚能力が既に備わっていることが明らかになった。この現象は、汎用ビジュアル言語モデルが予想以上に優れた3D表現能力を持つ可能性を示唆するとともに、さらに探求する価値のある疑問を提起する。すなわち、標準的なVLMは、追加のエンコーダ、視覚的手がかり、またはタスク固有のモジュールを導入することなく、より広範なきめ細かい3D知覚タスクに対応できるのだろうか?
この問題に対処するために、Metaはプリンストン大学と共同で、VLM³(VLMキューブ)フレームワークを提案した。本研究は、標準的な視覚言語モデルに基づき、統一されたデータ構成方法と学習パラダイムを通して、オブジェクトレベルの3D理解、メトリック深度推定、ピクセルマッチング、カメラ姿勢解決という4種類のタスクに対する統一的なモデリングを実現する。また、標準的なVLMのきめ細かい3D知覚における能力限界を体系的に評価する。
関連する研究成果は、「VLM3:ビジョン言語モデルはネイティブな3D学習者である」と題され、プレプリントプラットフォームarXivで公開されている。
研究のハイライト:
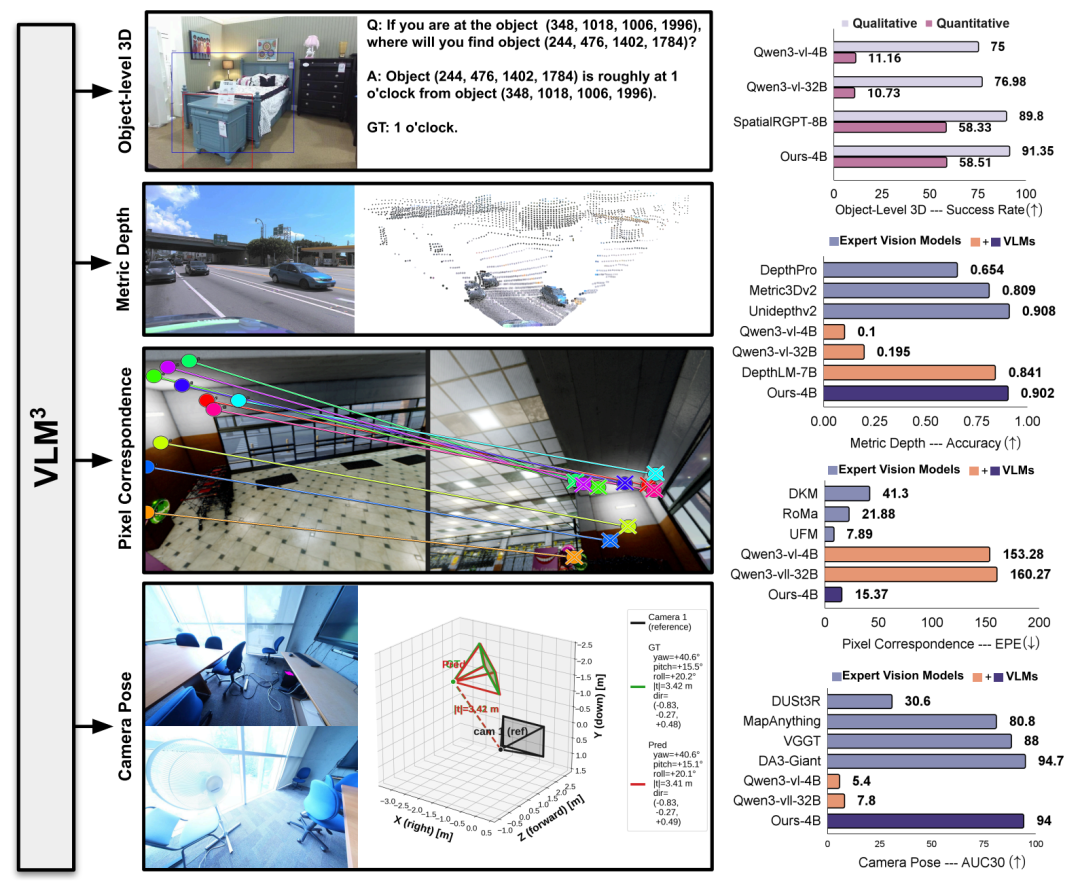
* SpatialRGPTベンチマークにおいて、VLM³-4Bは、より合理化されたアーキテクチャにより、追加のエンコーダーを必要としないため、より大型のSpatialRGPT-8Bを上回る性能を発揮します。
* 以前の最良の視覚言語モデルである DepthLM-7B と比較して、VLM³-4B は平均精度 δ₁ を 0.84 から 0.90 に向上させ、プロフェッショナルな深度推定モデル UnidepthV2 と同等の性能を達成しました。
* VLM³は、ベースラインの視覚言語モデルのエンドポイントエラー(EPE)を桁違いに削減し、DKMやRoMaなどの従来のエキスパートモデルを凌駕します。
* VLM³は、AUC₃₀°指標をほぼランダムなレベルである5%から94%へと大幅に改善し、VGGTを上回り、DA3-Giantに匹敵するレベルに達しました。
論文を見る:
https://hyper.ai/papers/2605.30561
マルチタスク3D知覚のためのハイブリッドデータセット
3D 知覚タスクには、シーンのスケール、視点の変化、カメラのパラメータ、幾何学的関係などさまざまな要素が関係するため、トレーニング データの品質と網羅性に高い要求があります。統一された 3D 表現機能の学習をサポートするために、本研究では、単一視点と複数視点のシーンを網羅するハイブリッドデータシステムを構築し、メトリック深度推定、オブジェクトレベルの3D理解、ピクセルマッチングおよびカメラ姿勢推定という3種類のタスクを包含する。
メトリック深度推定タスクにおいて研究者らは、大規模なマルチシーンハイブリッドデータセットを使用した。ベースデータはDepthLMから継承されており、Argoverse2、Waymo、NuScenes、ScanNet++、Taskonomy、HM3D、Matterport3Dといった主流の3Dシーンデータが含まれている。さらに、独自に作成した1,000万枚の屋外街路シーン画像が追加され、トレーニング規模は1,600万枚から2,600万枚に拡大された。最終的なモデルのトレーニングには、約3200万枚の画像と3億2000万個の深度アノテーションが使用されました。屋内、屋外、街路、複雑なオープン環境など、さまざまなシナリオに対応しています。
既存の研究とは異なり、VLM³は均一なサンプリング戦略を採用していません。代わりに、データセットのサイズ、学習の難易度、汎化値に基づいて、異なるトレーニング重みを設計します。実験によると、混合トレーニングではデータセットが小さいほど過学習を起こしやすく、データソースの数を増やすだけでは必ずしもパフォーマンスが向上するとは限りません。そのため、研究チームは、全体的な汎化能力を向上させるために、一部の小規模データセットのトレーニング重みを適切に削減しました。
オブジェクトレベルの3D理解タスクでは、SpatialRGPTと同じ標準データセットを使用します。このデータセットには、約100万枚のトレーニング画像と、それに付随する定性的および定量的な質問応答サンプルが含まれています。このデータセットは、現在のオブジェクトレベルの3D理解タスクにおける重要なベンチマークとなっています。画像の多くはカメラの内部情報が欠落しているため、現実世界のアプリケーションシナリオに近く、モデルの空間推論能力をより現実的に反映しています。
ピクセルマッチングとカメラ姿勢推定のタスクのために、研究チームは統一されたマルチビュー訓練データセットを構築した。このデータセットは、BlendedMVS、DynamicReplica、SailVOS3D、ScanNet++など、約990万組の画像ペアを含む14の主要なデータソースを統合しています。トレーニングの品質を確保するため、研究者らは画像間の視覚的な重なりが251 TP3Tを超えるサンプルのみを保持し、ScanNet++から30の独立したシーンを専用のテストセットとして確保することで、トレーニングセットとテストセット間のデータ漏洩を回避しました。データセットの重みは、各データソースの元の画像ペア数に基づいて構成されており、トレーニングプロセスの安定性と適応性をさらに向上させています。
VLM³モデル:最小限の変更の原則に基づく統合3D学習
VLM³の設計目標は、新しい3Dビジョンアーキテクチャを構築することではなく、標準的な視覚言語モデルの元の構造を維持しながら、きめ細かな3Dタスクにおけるその潜在的な能力を評価することです。そのため、フレームワーク全体は「最小限の変更の原則」に従い、追加のエンコーダ、独自の損失関数、またはタスクに特化したモジュールを導入していません。その代わりに、入力表現、空間位置決め方法、データ整理戦略という3つの側面を最適化することに重点が置かれています。
本研究では、ベースモデルとしてQwen3-VL-4Bを使用し、トレーニングプロセス全体を通して標準的な教師ありファインチューニング(SFT)パラダイムを採用することで、既存の視覚言語モデルの事前トレーニングおよびファインチューニングワークフローとの一貫性を維持しています。この設計により、追加の専用トレーニングパイプラインを構築することなく、フレームワークが主流のVLMシステムと直接互換性を持つことが保証されます。
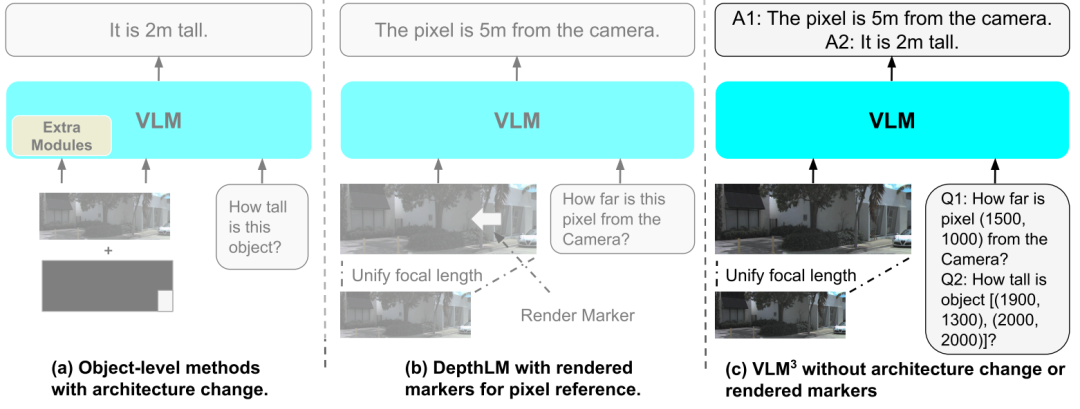
まず、異なるデータソース間でカメラパラメータに一貫性がないという問題について、VLM³は、統一された画像標準化戦略を提案する。研究によると、マルチソース3Dデータセット間ではカメラの内部パラメータに大きな違いが存在することが多く、ネットワーク画像の中にはカメラパラメータ情報が欠落しているものもある。これは、モデルが空間幾何学的関係を学習する能力に直接影響を与える。したがって、このフレームワークは、すべての入力画像を標準焦点距離空間にマッピングし、既存の単一画像較正モデルを使用して不足している固有パラメータを推定します。これにより、画像撮影条件の違いによって生じる分布のずれが軽減される。
第二に、VLM³は、統一されたテキスト空間配置パラダイムを採用している。従来の 3D ビジョン モデルは、ピクセル レベルのローカリゼーションを実現するために、追加の視覚的手がかり、レンダリングされたマーカー、または特別に設計された位置エンコーディング モジュールに依存しています。しかし、VLM³ は、画像座標を統一された座標空間に正規化し、位置関係をテキスト形式で表現します。このようにして、モデルはネイティブ言語モデリング機能を活用して、追加の視覚モジュールを導入することなく、ピクセル レベルのローカリゼーション、領域ローカリゼーション、およびクロス ビュー対応学習を実行できます。同時に、1 つの画像に複数のローカリゼーション質問応答サンプルを含めることができ、トレーニング効率が大幅に向上します。深度推定タスクでは、単一のサンプルから得られる監視信号の量は、従来の方式の約10倍である一方、計算コストはほとんど変わらない。
3つ目の主要設計は、高度なデータ混合戦略である。複雑なネットワーク構造に依存して性能を向上させる多くの手法とは異なり、VLM³はデータ編成レベルに最適化の取り組みを集中させています。研究チームは広範な実験を通して、データサイズを無闇に拡大したり、均等重み付けの混合学習を使用したりすると、性能が飽和したり、場合によっては低下したりすることが多いことを発見しました。これに対し、データサイズとタスク特性に基づいて差別化されたサンプリング戦略を設計することで、モデルの3次元表現能力をより効果的に向上させることができます。したがって、データ割り当ては、トレーニングプロセスにおける単なる補助的な要素ではなく、フレームワーク全体の重要な構成要素とみなされています。
上記の設計に基づいてVLM³はさらに、4種類の3Dタスクに対応した統一的なモデリングを可能にする。深度推定では、テキストによるピクセル位置特定を通して教師ありサンプルを構築します。オブジェクトレベルの3D理解では、専用のマスクエンコーダーの代わりにテキスト座標ボックスを使用します。ピクセルマッチングでは、視点間の対応関係を座標予測問題に変換します。カメラ姿勢推定では、複雑な幾何学的パラメータを、並進距離、並進方向、回転角度などのテキストベースの質疑応答形式に分解します。処理に異なるモデルを使用していたこれらのタスクは、最終的に標準VLMの自己回帰生成フレームワークに統合されます。
今回初めて、標準的な視覚言語モデルが、複数のきめ細かい3Dタスクにおいて、高精度な3D理解を実現した。
VLM³の有効性を体系的に評価するために、研究チームは、メトリック深度推定、オブジェクトレベルの3D理解、ピクセルマッチング、カメラ姿勢推定という4種類のタスクについて実験を行った。これは、一般的な視覚言語モデルおよび現在の主流の専門家モデルと比較される。
メトリック深度推定タスクにおいて本研究では、一般的なVLMと比較するために9つの公開データセットを選択し、5つの代表的なベンチマークにおいて、現在の最先端の専門家モデルと比較評価を行った。δ₁を主要な評価指標として用いた結果を以下の表に示す。VLM³-4Bは、従来代表的な手法であったDepthLM-7Bを総合的に上回る性能を示した。平均精度は0.84から0.90に向上し、複数のデータセットで新記録を樹立した。同時に、その総合的な性能は、UnidepthV2やMoGe-2といったプロ仕様の深度推定モデルと同等のレベルに達している。
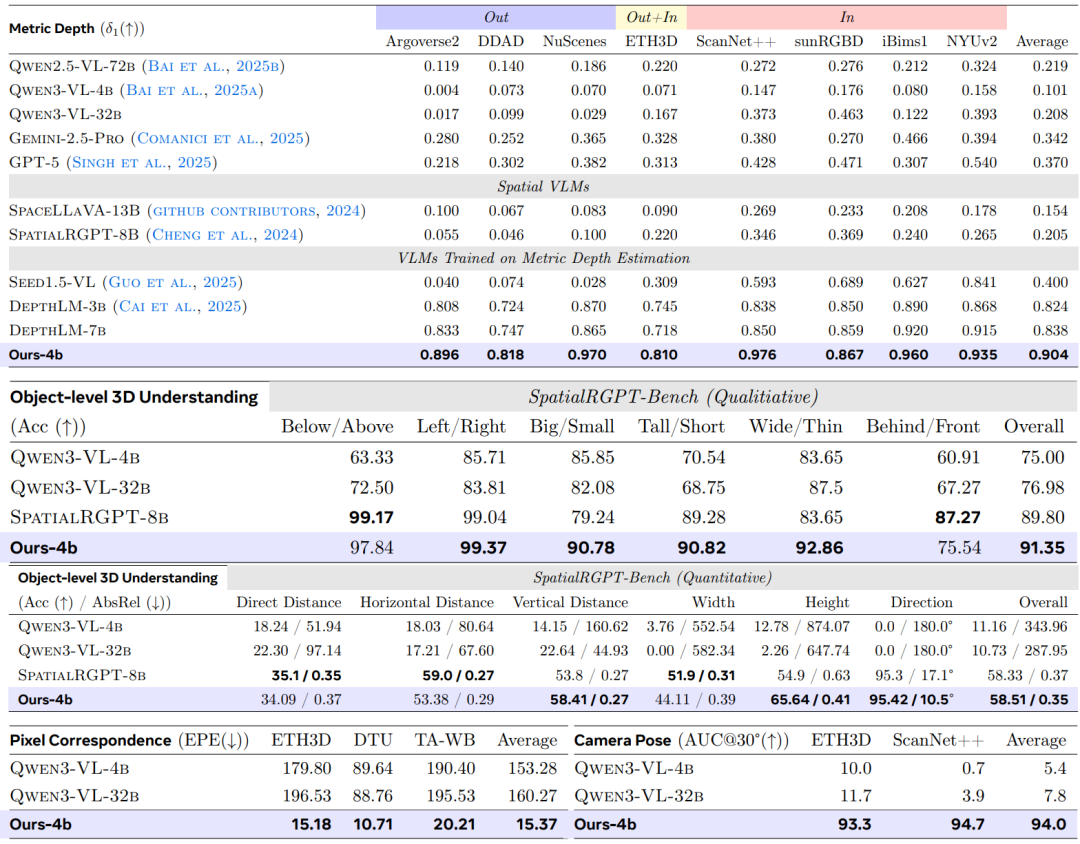
オブジェクトレベルの3D理解タスクにおいて、本研究ではSpatialRGPTの評価フレームワークを全面的に再利用した。その結果、…パラメータサイズがわずか4BのVLM³は、サイズが8BのSpatialRGPTを、定性的評価と定量的評価の両方で上回る性能を発揮する。後者は空間位置特定を完了するために追加のマスクエンコーダに依存しているのに対し、VLM³は統一されたテキスト位置特定メカニズムのみに依存することでより良い結果を得ることができ、統一されたテキストモデリングが空間推論タスクにおいて高い有効性を持つことを示している。
ピクセルマッチングタスクでは、エンドポイントエラー(EPE)をコアメトリックとするUFM評価システムを採用しています。実験結果によると、VLM³は基本VLMと比較してエラーを1桁削減し、DKMやRoMaなどの古典的なエキスパートモデルを凌駕し、現在の最先端手法であるUFMにわずかに劣る程度であることが示されています。これは、…統一されたテキストベースのモデリング手法は、単一視点のシーンに適用できるだけでなく、複数の視点間の幾何学的対応関係を効果的に学習することもできる。
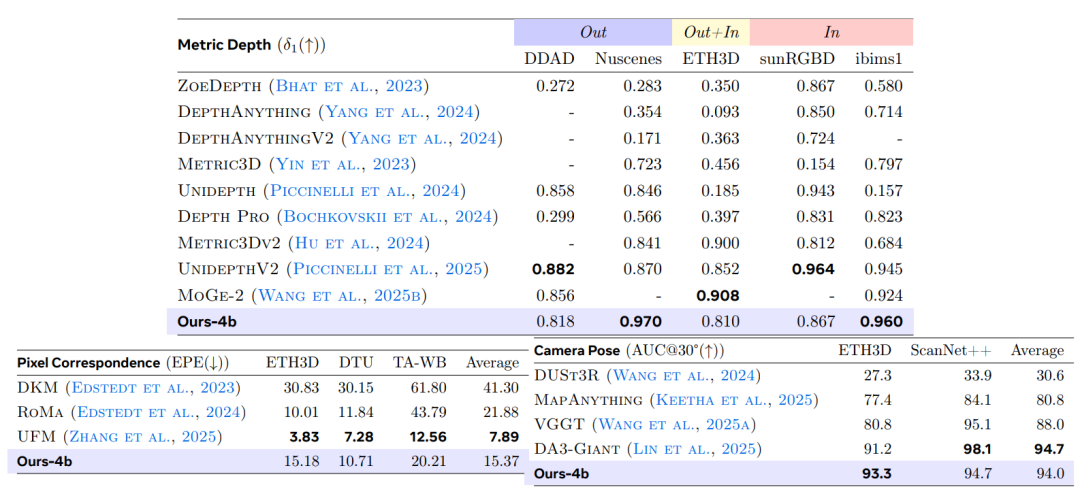
カメラ姿勢推定タスクにおいて、本研究ではETH3DデータセットとScanNet++データセットそれぞれに対してAUC₃₀°指標を用いて評価を行った。その結果、…VLM³は、ベースとなるVLMの予測性能をほぼランダムなレベルからAUC₃₀°94%まで向上させます。これはVGGTやMapAnythingといった主流の手法を凌駕し、現在の最高性能モデルであるDA3-Giantの性能レベルに迫るものです。
最後に書きます
長らく、3Dビジョン研究は主に「タスク駆動型」のアプローチ、すなわち深度推定、ピクセルマッチング、姿勢解決といった異なるタスクごとに専用モデルを設計するというアプローチをとってきました。しかし、VLM³は、それとは異なる可能性を示しています。追加のエンコーダ、独自の損失関数、複雑な視覚キューイング機構を導入することなく、標準的な視覚言語モデルが、標準化された画像処理、テキスト空間モデリング、洗練されたデータ戦略のみによって、複数のきめ細かい3Dタスクにおいて、一部のエキスパートモデルと同等、あるいはそれ以上の性能を達成できるのです。この研究結果は、汎用視覚言語モデルの3D表現能力が従来の予想をはるかに超える可能性を示唆しており、3Dビジョンが「タスク固有の最適化」から「統一された基本モデル」へと移行する新たな実証的証拠を提供しています。