Command Palette
Search for a command to run...
ケンブリッジ大学などは、地球観測ミッションのためのピクセルレベルの基本モデルを提案し、複数のミッションで最先端の精度(SOTA)を達成した。

広範囲かつ長期間にわたって地球を監視できる地球観測衛星は、農業生産、森林管理、生態系モニタリング、土地管理といった分野で不可欠なツールとなっている。衛星によって取得された長期リモートセンシングデータを用いることで、研究者は地球表面の動的な変化を追跡することができる。しかし、実際の衛星観測データは完璧とは程遠く、雲量、不規則な軌道再訪周期、センサー解像度の不一致、機器ノイズなどが干渉要因となっている。その結果、不完全で、異質で、無秩序な生データが生成され、高精度なインテリジェント分析に直接使用することが困難になる。特に、農業の季節現象や短期的な生態系の撹乱といった詳細なシナリオにおいては、雲が重要な変化プロセスを直接的に覆い隠してしまう可能性がある。
現在、業界では雲を除去しノイズを低減し、標準化された雲のない画像を生成するために、画像合成技術が一般的に用いられている。これはデータ品質と使いやすさを向上させる一方で、重大な情報損失にもつながる。生物季節学的変動や短期的な急激な変化といった微細な時間的特徴は、合成過程においてしばしば弱められたり、場合によっては完全に消去されたりするため、重要な情報が失われることになる。
近年、リモートセンシングの基本モデルは、大規模な事前学習によって大きな進歩を遂げてきました。しかし、ほとんどのモデルは依然として、高度なフィルタリングと正規化処理を施した理想的なデータに依存しており、学習時には雲のない合成画像や時系列平均データのみを使用しています。このアプローチでは、雲の影響を受けているものの、実際の変化パターンを含む大量の観測データが事実上破棄されてしまいます。その結果、実際の運用シナリオにおいて、疎で不完全かつ複雑な雲に覆われた時系列データに直面すると、モデルは苦戦を強いられます。不安定な特徴抽出は、汎化能力を著しく低下させる。
このボトルネックを克服するために、ケンブリッジ大学、アールト大学、ブリストル大学の共同研究チームは、バーロウツインズアルゴリズムに基づく新しい時間的特徴学習パラダイムを構築しました。このパラダイムは、雲を含むデータをフィルタリングする代わりに、同じ場所の異なる観測サブセット間の特徴の一貫性を制約し、モデルが地球表面の安定した時空間変動を自律的に学習し、時間的サンプリング不変性を持つリモートセンシング特徴表現を形成できるようにします。これに基づいて、研究チームはさらに、Sentinel-1/Sentinel-2のマルチモーダル時系列データのためのピクセルレベルのリモートセンシング基盤モデルであるTESSERAを提案した。
関連する研究成果は、「TESSERA:地球表現と分析のための表面スペクトルの時間的埋め込み」と題され、プレプリントプラットフォームarXivで公開されています。
研究のハイライト:
* ラベル利用率の高いグローバル規模のピクセルレベルの特徴埋め込みを構築し、斬新な自己教師ありアーキテクチャを設計し、Sentinel-1/Sentinel-2マルチモーダルデータを統合したピクセルレベルのリモートセンシング基本モデルをトレーニングします。
* FAIRガイドラインに準拠したデータ埋め込みソリューションを導入し、10メートル解像度のピクセルレベル8ビット整数特徴埋め込みのグローバル年間データセットを公開することで、直接展開可能な準拠したリモートセンシングリソースを提供します。
* 実験により、TESSERAは、多様な分類、セグメンテーション、回帰タスクにおいて、極めて高いラベル付け効率で最先端の精度を達成できることが示されており、通常は軽量なタスクヘッダーと最小限の計算のみを必要とします。

論文を見る:
https://hyper.ai/papers/2506.20380
データセット:グローバルレベルからローカルレベルまでの多次元評価システムの構築
本研究では、モデルの事前学習とモデルの汎化能力のシステム評価の両方に使用できる、大規模なグローバル時系列リモートセンシングデータシステムを構築した。このデータシステムは、事前学習データセットと下流評価データセットから構成される。すべてのデータは、Sentinel-1レーダーデータとSentinel-2光学データに基づいています。レーダー観測と光学観測の相補的な利点を最大限に活用する。

事前学習段階において、研究チームは2017年から2024年までの期間を対象とし、世界中の3000以上のグリッドタイルを空間的に網羅する、グローバル規模の大規模な時系列データセットを構築した。合計で約8億個のdピクセルサンプル。厳密に選定され標準化された多くのデータセットとは異なり、このデータセットは、欠損データ、不規則なサンプリング、雲量など、実際の観測の本来の特性を可能な限り保持しています。さらに、各タイムステップには、観測の有効な状態を示すバイナリマスクが付属しており、モデルが欠損データや観測品質の違いを明確に認識できるようになっています。
下流評価段階、研究チームは、分類、セグメンテーション、回帰という3つの主要なタスクを網羅する、一般に公開されている6つのベンチマークデータセットを選定した。評価対象地域は、ドイツ、フランス、オーストリア、フィンランド、マレーシアなど複数の国と地域に及び、農業や林業といった典型的な応用シナリオを網羅しています。各タスクには、大規模な地域データセットと、より詳細なローカルデータセットの両方が含まれており、それぞれモデルの地域間適用性と、きめ細かな特徴モデリング能力を評価します。
さらに、高解像度で多時期のSentinel-1/2マルチモーダル注釈データが現在不足していることを受けて、研究チームはまた、独自に2つの新しい評価基準を構築した。一つ目は、精密農業のシナリオにおける分類およびセグメンテーション機能を評価するために使用される、オーストリアの区画レベルの作物マッピングデータセットです。二つ目は、森林構造パラメータの逆解析タスクにおける性能を検証するために使用される、ライダー補正に基づいて構築された東南アジアの森林キャノピー高さデータセットです。
地球観測ミッションのためのピクセルレベルの基本モデル
TESSERAは、複雑で不完全な時系列データからモデルが安定した表現を直接学習できるように設計されており、同時に可能な限り多くの元の観測情報を保持することで、データ準備、補完、および修復プロセスへの依存度を低減します。
この目的を達成するために、本研究は、時系列データを整理する新しい方法であるdピクセルを初めて提案した。従来の分析では通常、単一シーンの画像または固定時系列を入力として使用するのに対し、d-pixelは単一の空間位置に焦点を当て、異なる時間に取得された同じピクセルの複数のソースからの観測を時系列順に整理して観測シーケンスを作成します。各dピクセルには、Sentinel-2の光学情報とSentinel-1のレーダー情報が含まれているだけでなく、マスクベクトルによって、どのタイムステップに雲による遮蔽やデータ欠落があるかも識別されます。この表現方法は、地表面変化の時間的特性を完全に保持します。植生成長による緩やかな変化であれ、災害や撹乱などによる短期的な急激な変化であれ、すべて保持することができ、従来の正規化処理における情報損失を根本的に回避します。
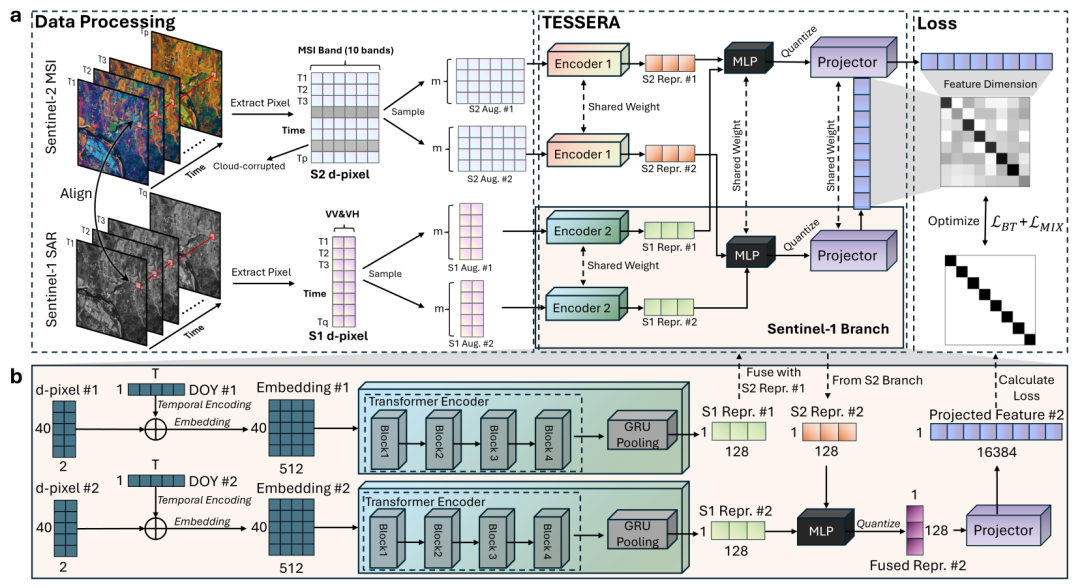
モデルアーキテクチャの観点から言えば、TESSERAは、光学データとレーダーデータを別々に処理するために、デュアルブランチエンコーダを採用している。2 種類のデータは、画像化メカニズムと物理的特性が大きく異なります。独立したエンコーディングにより、それぞれの特徴を十分に探究でき、その後、融合によりマルチモーダルな相補性を実現できます。各モダリティについて、モデルはまず有効な観測値を埋め込み、学習可能な年内日次位置エンコーディングを追加して時間情報を導入します。次に、Transformer エンコーダを使用して、長期的な時間的依存関係をモデル化します。最後に、ゲート付きリカレント ユニットを使用して、時系列全体を集約し、固定次元の単一モーダル表現を生成します。光学的特徴とレーダー特徴を融合した後、128 次元のマルチモーダル表面表現が形成されます。この研究では、量子化された知覚トレーニングも導入し、最終的な特徴を 8 ビット整数に圧縮します。精度をほとんど損なうことなく、ストレージ容量を約75%削減することができました。
事前学習戦略は、TESSERAの中核となる革新的な技術です。Barlowツイン自己教師あり学習フレームワークに基づき、システムは同一のdピクセルに対して、完全な時系列データからランダムに2つのサブセットを抽出し、2つの異なる「視点」を構築します。2つの観測セットは異なる時点のデータを含み、一部のタイムステップが欠落している場合もありますが、いずれも同じ地表オブジェクトを記述しています。
トレーニング中、モデルは2つの観測セットを可能な限り一貫性のある特徴空間にマッピングする必要があります。このようにして、このモデルは、特定の観測における瞬間的な特徴を学習するのではなく、異なる観測の背後に隠された安定した表面パターンを学習する。これにより、時間サンプリング手法に左右されない頑健な特徴表現が得られます。さらに、本研究では、観測データの変動や空間自己相関に対するモデルの頑健性をさらに高めるために、ハイブリッド正則化とグローバルシャッフル戦略を導入しています。
TESSERAは、ラベル数が少なくデータが少ない場合にその優位性を発揮する。
TESSERAの性能を包括的に評価するため、本研究ではリモートセンシング分野における典型的な応用シナリオに基づいた体系的な実験を設計した。分類、セグメンテーション、回帰の3つのタスクから始め、実験では異なるデータスケール、アノテーション条件、地域シーンにおけるモデルの性能を検証した。いくつかの主流のリモートセンシング基本モデルと古典的なビジュアルモデルをベースラインとして選択し、1%、30%、100%の3つの均一なアノテーション比率を設定した。焦点は、タグが少ない状況における学習能力の評価にある。公平性を確保するため、異なるタスク間での下流推論には軽量アダプタが使用されます。
分類タスクにおいて、TESSERAは時間的特徴の学習において顕著な優位性を示します。このモデルは、全国規模の樹種分類と高度な作物分類の両方のタスクで優れた性能を発揮します。特に、1%ラベル付きデータのみを使用する極めて少ないサンプルサイズのシナリオにおいて、TESSERAは安定した性能を維持します。分類精度は、最適なベースラインと比較して約8パーセントポイント向上しました。この利点は主に、モデルが長期的な地表面変化を効果的にモデル化していることに起因します。植生の成長サイクルと季節的特性を捉えるために完全な時系列観測を利用することで、最小限の注釈でも非常に識別力の高いカテゴリ表現を形成できます。
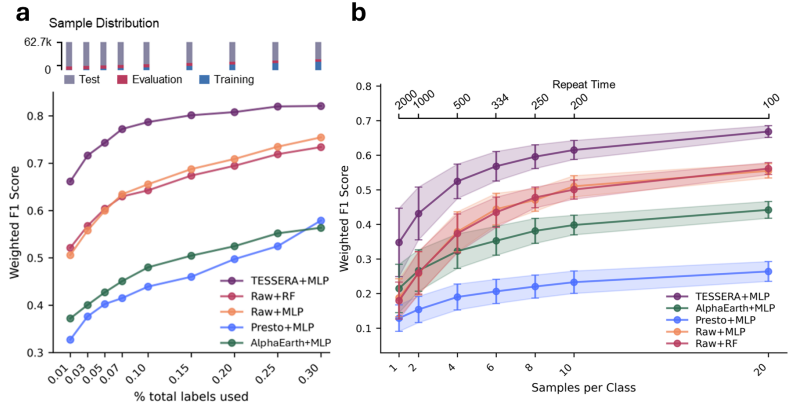
セグメンテーションタスクにおいて、TESSERAは優れた空間ディテールレンダリング能力も示しました。大規模な農地セグメンテーションタスクに直面した際、このモデルはラベルが完全に付与された条件下で業界トップクラスの性能を達成し、ラベルが少ないシナリオでは、その性能はすべての対照モデルをさらに上回りました。注目すべき点は…TESSERAは、軽量デコーダのみを使用して空間コンテキスト情報を効果的に学習することができ、精度を維持しながら展開効率も確保します。オーストリアの作物セマンティックセグメンテーションデータセットにおいて、このモデルはより明確な区画境界を生成し、異なる作物間の混同を大幅に軽減し、全体的な意味的一貫性を向上させた。
回帰タスクでは、主にモデルが連続的な地表面パラメータを表現する能力を検証します。地上バイオマス推定タスクでは、TESSERAはさまざまなラベリングスケールで最良の結果を達成し、予測誤差が低く、空間分布がより連続的でした。森林キャノピー高さ逆解析タスクでは、モデルは3次元の森林構造情報を捉える能力をさらに実証し、推定結果はライダー測定データと最も高い一致を示し、森林の垂直構造特性を効果的に復元しました。
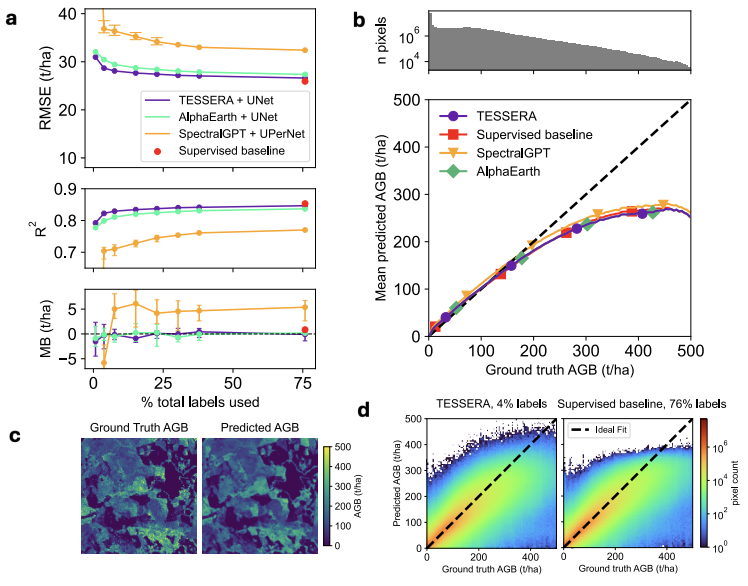
すべての実験結果に基づくと、TESSERAは、分類、セグメンテーション、回帰という3種類のタスクすべてにおいて安定した優位性を維持しており、注釈が少ない、データが少ない、観測値が欠落しているといった複雑な条件下では、その優位性はさらに顕著になります。高品質な訓練データに依存する多くのモデルと比較して、TESSERAは実際のリモートセンシングシナリオにおいて、より緩やかな性能低下を示し、より優れた堅牢性と汎化能力を発揮する。
最後に書きます
リモートセンシングの基礎モデルは本当に「理想的なデータ」を必要とするのでしょうか?TESSERAのアプローチは、これとは異なる答えを提示します。モデルが現実世界の不完全で不規則、かつ頻繁に雲の影響を受ける観測シーケンスに直接対応できるようにし、自己教師あり学習フレームワーク内で時系列サンプリング不変性を持つ特徴表現を学習します。これはデータクリーニングがもはや重要ではないという意味ではなく、研究者が「データのクリーニング」から「不完全なデータを処理できるようにモデルを訓練する」ことに焦点を移す可能性があることを示唆しています。結局のところ、雲を含むすべての衛星画像は現実世界の観測の一部です。より「完璧な」データを絶えず追求するよりも、モデルが現実世界の複雑さを理解できるようにすることの方が、リモートセンシングの基礎モデルの一般化にとって重要な方向性となるかもしれません。








