Command Palette
Search for a command to run...
ドイツの研究チームは、生成型AIモデルを用いてデータを補強することで、小規模サンプルを用いた生物医学研究において新たなブレークスルーを達成した。これにより、TP3T(標的タンパク質3種)あたりに必要な実験動物の数を30~50匹削減できる可能性がある。

動物実験で検証された「有効な治療効果」は、臨床試験では再現されないことが多く、その主な理由の一つはサンプルサイズの不足である。倫理規制、実験費用、研究環境など、複数の制約がこの問題をさらに悪化させている。前臨床段階の生物医学研究では、大規模な動物実験を実施する際にしばしば課題に直面し、それが直接的に統計的検出力の不足につながる。研究者たちは、真の生物学的シグナルを確実に抽出することができず、偽陽性結果が出やすいという問題を抱えているため、基礎研究の臨床応用への移行が著しく阻害されている。
この課題に対処するため、研究者たちはメタ分析やデータ統合などの手法を用いて研究データを統合しようと試みてきた。しかしながら、これらの方法は、異なる研究間における実験計画、検出指標、および操作手順の比較可能性に大きく依存する。その実用範囲は極めて限られている。
近年、生成型人工知能は、小規模サンプル研究に新たなアプローチを提供してきた。すなわち、元のデータの固有の分布構造を学習することで、合成データを生成します。これによりサンプルサイズを拡大します。しかし、一般的な生成型モデルには重大な欠点があります。元のデータにランダムな誤差が含まれている場合、モデルはノイズをさらに増幅し、多数の偽陽性結果を生成するため、研究結果の信頼性が低下する。データ生成時にエラーの伝播を抑制する方法は、生物医学分野における生成型AIの応用において、中心的なボトルネックとなっている。
この重大な問題点に対処するため、フランクフルト大学とフラウンホーファーITMP研究所の共同研究チームがgenESOMを開発した。創発的な自己組織化マップに基づく生成型AIモデルは、特に小規模な生物医学データ向けに設計されている。このモデルの核となる革新は、構造学習とデータ生成プロセスを分離することにある。次元調整によってエラーの伝播を阻止し、負の制御変数を導入することで、データ生成の品質をリアルタイムで監視する。研究チームは、多発性硬化症の前臨床脂質ゲノムデータを研究対象とし、まずサンプルサイズを統計的失敗の閾値まで人為的に縮小し、次にgenESOMを用いてデータ拡張を行った。
この結果は、この手法が偽陽性を厳密に制御しながら、小サンプルデータで失われた重要な生物学的シグナルを効果的に復元できることを裏付けており、小サンプル生物医学研究のための信頼性の高い新しいアプローチを提供する。さらに、探索的研究シナリオでは、このモデルは結果の再現性と科学的妥当性を維持しながら、必要な実験動物の数を約30%~50%削減することが期待される。
関連する研究成果は、「誤差膨張制御を組み込んだ自己組織化ニューラルネットワークに基づく生成型AIは、サンプルサイズを削減しながら前臨床研究からの効果的な知識抽出を強化する」と題され、Pharmacological Research誌に掲載された。
研究のハイライト:
* 組み込みのデータ駆動型エラー制御メカニズムにより、GANなどの制約のない手法とは異なり、偽陽性の増加を効果的に抑制します。
サンプルサイズを縮小した後でも、偽陽性率を増加させることなく、主要な脂質シグナル(リゾホスファチジン酸など)を正常に復元することに成功した。
* 動物の使用量を30~50%削減でき、研究の信頼性と3R倫理原則の両方を考慮しながら、補助的な分析ツールとして機能します。

論文を見る:
https://www.sciencedirect.com/science/article/pii/S1043661826000745
データセット:完全な実験から小サンプル統計的失敗まで
本研究のデータは、多発性硬化症に関する、一般に公開されている前臨床動物実験から得られたものである。本研究では、SJL/Jマウスを用いて、再発寛解型の実験的自己免疫性脳脊髄炎(EAE)モデルを確立した。本研究は、神経炎症のメカニズムを解明し、承認済みの薬剤であるフィンゴリモドの治療効果を検証することを目的としている。
注:フィンゴリモドは、スフィンゴ脂質代謝を調節することで免疫シグナル伝達経路に干渉するスフィンゴシン-1-リン酸受容体モジュレーターです。多発性硬化症の臨床治療において一般的に使用される薬剤です。
この実験では、生後8週齢の雌マウス26匹を用い、無作為に3つのグループ(ブランク対照群、EAEモデル群、EAE+フィンゴリモド投与群)に分けました。投与群には、免疫誘導18日目から、0.5mg/kg/日の用量で飲水にフィンゴリモドを投与しました。
研究チームは、行動データと分子レベルのデータを同時に収集した。行動指標には、運動能力、身体協調性、社会的行動が含まれます。分子レベルでは、LC-MS/MS標的定量技術を使用して、血漿、小脳、海馬、前頭前皮質の4つの組織における62種類の脂質メディエーターの濃度を検出しました。これには、リゾホスファチジン酸、セラミド、スフィンゴ脂質、エンドカンナビノイドの4つの主要カテゴリーが含まれます。最後に、「個々のマウス×脂質特性」の標準データマトリックスが構築された。
データ分析の前に、研究チームは、統計分析における分布の仮定に適合させるため、脂質濃度データに対数変換を施した。元のデータ5.3%の欠損値については、マルチメソッドアライメント後、ランダムフォレストアルゴリズム(missForest)を使用して欠損値を補完した。続いて、62の脂質指標に対して一元配置分散分析(ANOVA)を実施し、Šidák補正を使用して多重検定エラーを制御した。同時に、ランダムフォレスト、サポートベクターマシン、k近傍法の3つの機械学習モデルを導入し、グループ間の差異の有意性と分類予測能力という2つの側面から、データ内の生物学的シグナルの安定性を相互検証した。
基本的な分析を完了した後、研究ではコア検証実験を実施しました。サンプルサイズを体系的に減らし、サンプル数が少ない場合に統計的に失敗する臨界値を特定しました。研究者は各グループのマウスの数を段階的に減らし、減らすたびに分析手順全体を繰り返しました。結果は、サンプルサイズをグループあたり6匹のマウスに減らすと、元のデータから重要な統計結果が完全に消失することは、genESOMのデータ拡張能力を評価するためのベンチマークとなる。―統計的手法が全く効果を発揮しない小規模サンプルシナリオにおいて、AIがノイズに埋もれてしまった生物学的信号を復元できるかどうかを検証する。
小規模な生体医療データ向けに特別に設計された生成AI
従来の生成モデルは、少量のサンプルデータを処理する際に常にジレンマに直面します。生成されたデータは情報が不足していて元の生物学的信号を復元できないか、あるいはノイズが過剰で偽陽性が大量に発生するかのどちらかです。genESOMの中核設計は、これら2つの要素間の厳密なバランス機構を確立し、安全かつ解釈可能な少量サンプルデータの拡張を実現することです。
genESOMは、創発的自己組織化マップ(ESOM)ニューラルネットワークに基づいており、従来の自己組織化マップ(SOM)と比較して2つの重要な改良点を実現しています。まず、ニューロンは、高次元データの近傍構造関係を最大限に維持するために、二次元円形グリッド状に配置されている。第二に、サブグループ間隔と投影誤差を符号化する第3の次元を追加することで、潜在的なクラスタリング構造を特定する精度が大幅に向上する。
標準化と欠損値除去の後、データはトレーニングのためにESOMネットワークに投影されます。モデルは各サンプルに対して最適なニューロンを継続的にマッチングし、ニューロンの重みを動的に調整し、学習率を徐々に下げてトレーニングの安定性を確保します。トレーニング後、モデルは2つのコア行列を出力します。U行列はニューロン間の間隔を特徴付け、クラスタ境界を識別します。P行列は局所的なデータ密度を統計的に分析するために使用され、合成データ生成の基礎となります。合成データ生成の範囲を制御する半径パラメータは、ガウス混合モデルを使用して距離分布を適合させることで自動的に決定され、手動による介入は不要です。
genESOMの最も画期的な設計は、構造学習プロセスとデータ生成プロセスを完全に分離している点である。このモデルは、まずデータの固有構造の表現を独自に学習し、次にその安定した構造に基づいて合成データを生成することで、2つのステップにおけるエラーの蓄積を回避します。さらに重要な点として、このモデルは順列変数をネガティブコントロールとして導入し、特徴の重要性が異常に増幅されていないかをリアルタイムで監視できます。エラーの蓄積が検出されると、データ拡張は即座に自動的に停止されるため、過学習や誤検出のリスクを軽減できます。
この研究では、研究チームは1:1の安全な増強比(各オリジナルサンプルから1つの合成サンプルを生成)を使用して、各グループのサンプルサイズを6から12に拡大しました。増強後、信号回復効果を定量的に評価するために、元のデータに対して一連の統計分析および機械学習分析が実施される。一方、この研究では、genESOMを2つの主流の生成手法であるガウス混合モデル(GMM)と条件付きテーブル生成敵対ネットワーク(CT-GAN)と直接比較し、偽陽性率、偽陰性率、および元の信号回復率を主要な指標として、モデルの優位性を検証した。
小規模サンプル環境において、従来の手法よりも大幅に優れた性能を発揮する。
下図に示すように、元のデータセット全体を分析した結果、62の脂質変数のうち27に有意な群間差が認められ、中でもリゾホスファチジルコリン脂質の変化が最も顕著でした。この結果は、多発性硬化症に関するこれまでの研究結果と非常に一致しています。同時に、ランダムフォレストモデルは、ランダム確率をはるかに上回る精度でサンプルを分類しており、これらの2つの結果を裏付けています。これは、元のデータに安定した信頼性の高い生物学的信号が存在することを裏付けている。
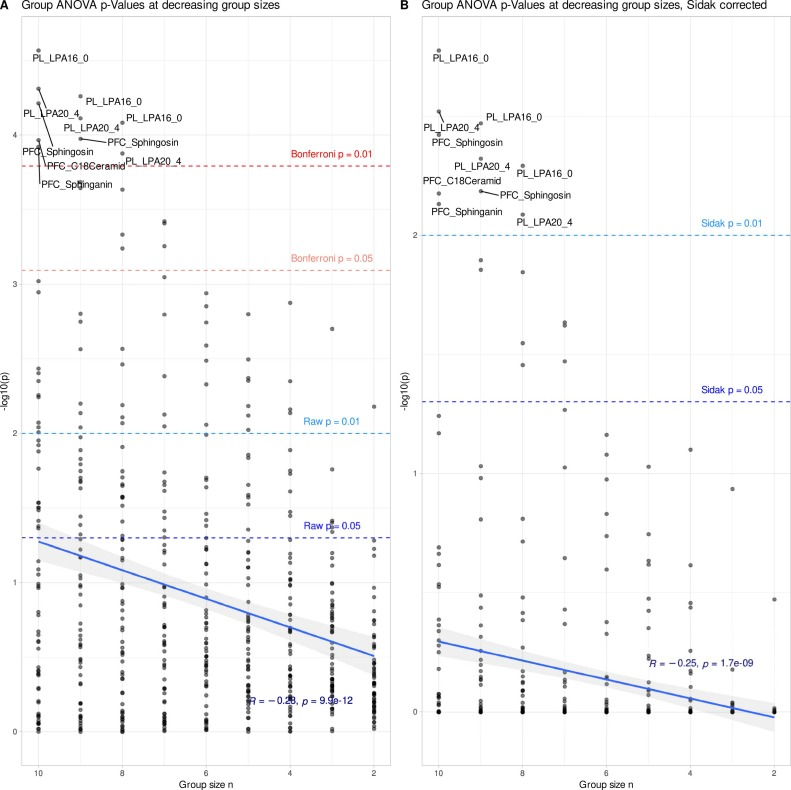
しかし、下図に示すように、各グループのサンプルサイズを6匹に減らすと、データ特性が劇的に変化しました。多重検証補正後、すべての脂質指標の統計的有意性は完全に消失し、ランダムフォレストの分類効率も大幅に低下しました。これは生物学的効果が本当に消失したことを意味するものではないことを強調しておくことが重要です。その代わりに、サンプルサイズが小さいため統計的な検出力が不十分となり、真の信号がノイズに埋もれてしまう。
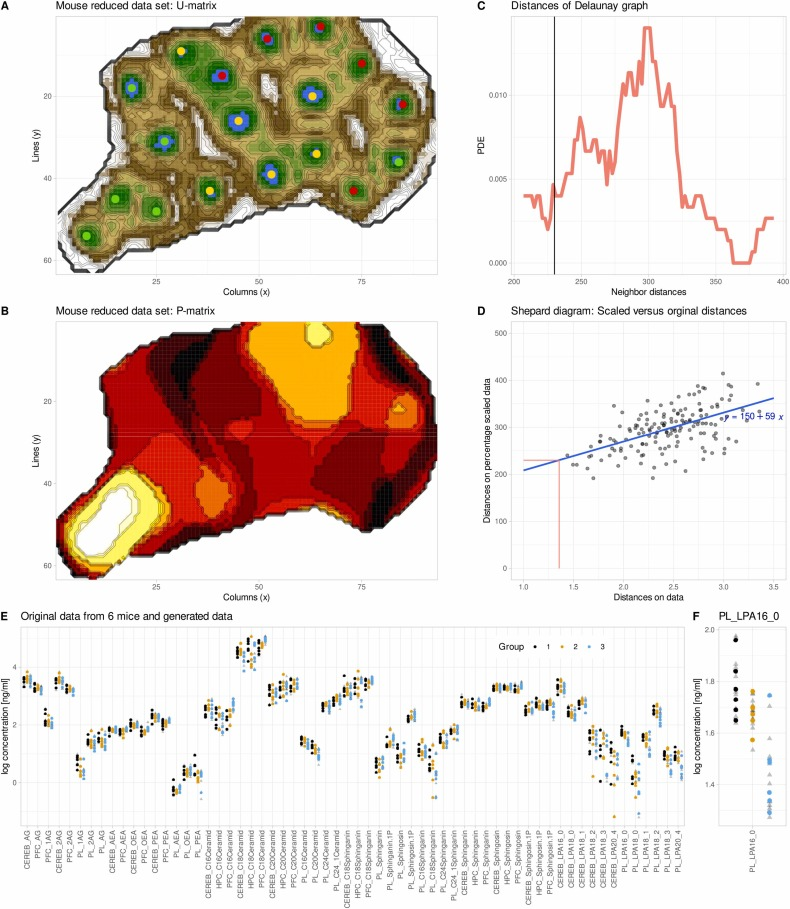
その後、研究チームはgenESOMを用いて、削減されたデータを補強した。20回のトレーニング後も、モデルはESOM空間において3つのサンプルグループの分離傾向をある程度識別することができた。これは、統計的有意性が消失した場合でも、データには潜在的な生物学的構造情報が依然として含まれていることを裏付けている。
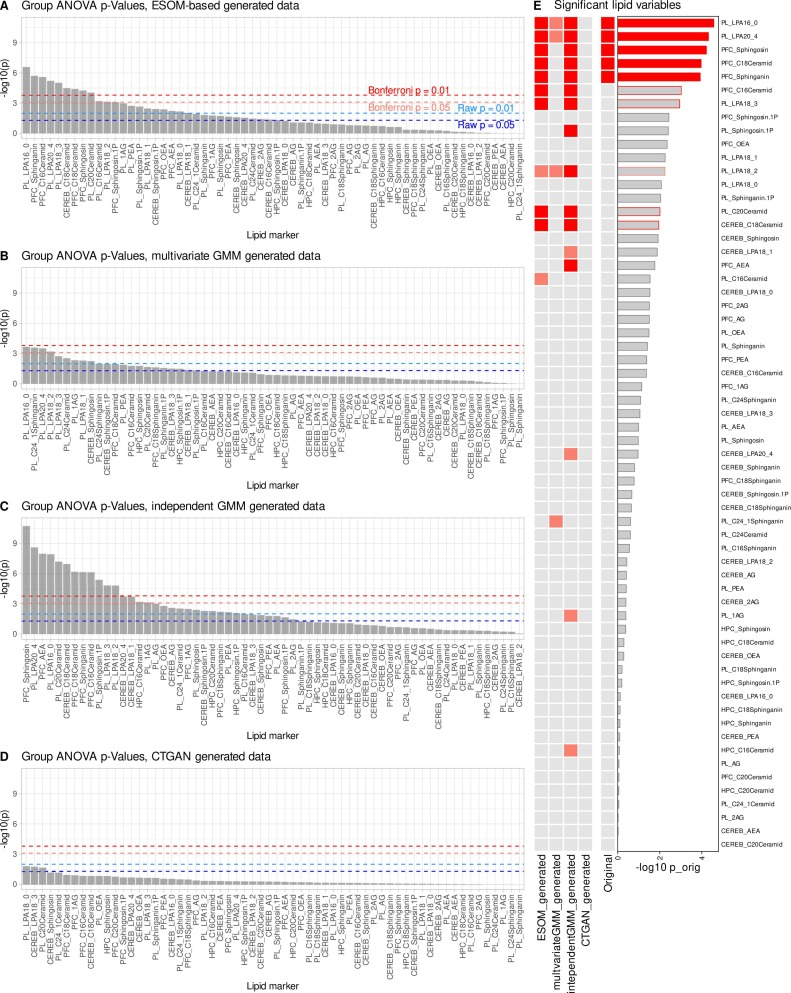
データ拡張後、血漿中の前頭前皮質におけるリゾホスファチジン酸やスフィンゴ脂質などの主要な脂質指標は、再び有意な群間差を示した。これらの指標は、サンプル数が少ないデータでは全く機能していなかったが、AIによる拡張によって正常に復元された。同時に、モデルは不合理な新しい特徴を多数導入することなく、有意水準が近い追加指標がわずかしか出現しなかった。これは、genESOMが何もないところから新たなシグナルを作り出すのではなく、既に存在しているもののサンプルサイズが不十分なために検出できない実際の生物学的シグナルを増幅することを示している。
下図に示すように、同じ小サンプル条件下では、2 つの制御生成方法は性能が劣っていました。多変量ガウス混合モデルは元の信号の一部しか復元できませんでした。独立ガウス混合モデルは、いくつかの重要な指標を復元しましたが、明らかな偽陽性を伴いました。条件付きテーブル GAN は、高い偽陰性率のため、コア結果を効果的に復元できませんでした。全体として、genESOMは、小サンプル環境において、従来の生成方法よりも著しく優れた安定性と信頼性を示す。重要な生物学的シグナルを正確に検出できると同時に、エラーの拡大や誤検出を厳密に制御できる。
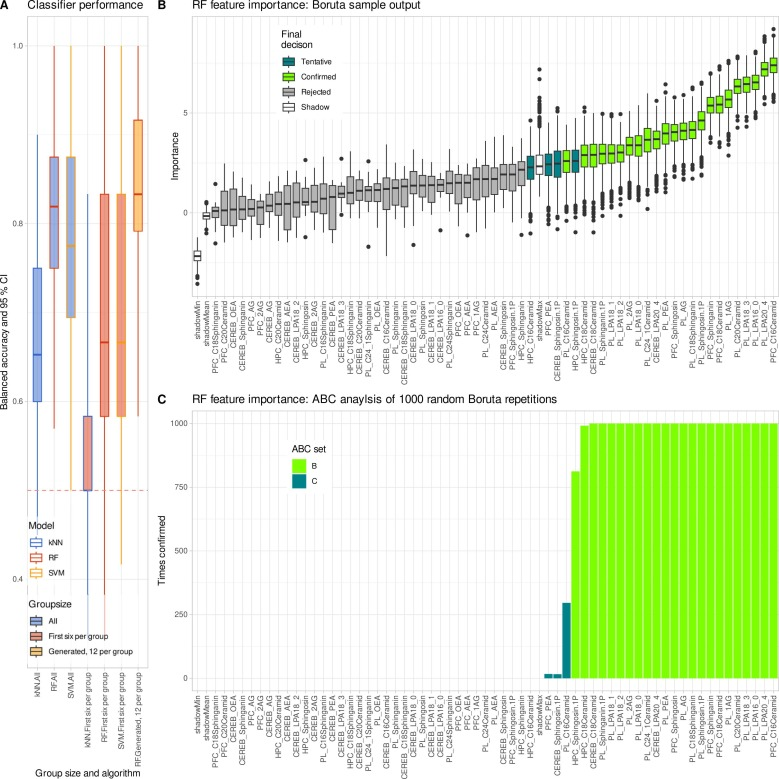
下図に示すように、機械学習分析によってこの結論がさらに検証されました。強化されたデータによってランダムフォレストの分類能力が回復し、選択された主要な特徴は元の研究と非常に一致していました。
最後に書きます
サンプルサイズが小さいことは、生物医学研究において長らく課題となってきた。高コスト、倫理的な障壁、そしてサンプル入手の困難さが、統計的検出力の不足につながる。従来のデータ拡張は比較可能性に制約があり、一般的な生成AIはサンプルサイズが小さい場合、偽陽性が発生しやすい。genESOMの画期的な点は、データを「作り出す」のではなく、限られたデータから既存の生物学的シグナルを着実に復元することにある。
そのコア設計は、構造学習とデータ生成を分離し、次元調整によってエラーを抑制し、リアルタイム監視のためのネガティブコントロールを導入することで、「既に存在するものを強化するだけで、存在しないものを創造しない」という制約のある枠組みを形成しています。強化は実際の実験に取って代わるものではないことに留意することが重要です。この手法はまだ探索段階にあり、その適用性にはさらなる検証が必要です。しかし、この研究は重要なシグナルを発しています。エラーと偽陽性を厳密に制御すれば、生成AIは小規模サンプル研究の効果的な補助ツールとなり、限られたデータから真の結論をより確実に導き出すのに役立つ可能性を秘めているのです。








