Command Palette
Search for a command to run...
オンラインチュートリアル | 香港科技大学チームが初の決定論的ビデオ深度フレームワークDVDをオープンソース化し、ゼロショットで最先端の結果を達成

深度推定は、3D ビジョンの分野で最も基本的かつ重要なタスクの 1 つです。自動運転やロボットナビゲーションから AR/VR、デジタルツイン、ビデオコンテンツ生成まで、システムはシーン内のオブジェクトとカメラ間の空間的な関係を正確に理解する必要があります。しかし、ビデオ深度推定は、長年にわたり解決不可能な矛盾に直面してきました。拡散モデルに代表される生成手法は、強力な意味理解能力を持ち、大量の事前学習済みデータを使用して複雑なシーン構造を推論できますが、その予測結果はランダムサンプリングプロセスの影響を受けることが多く、幾何学的錯覚、スケールドリフト、および時間的不安定性が発生しやすくなります。一方、従来の識別手法は、決定論性は優れているものの、大規模なラベル付きデータに大きく依存するため、トレーニングコストが高く、複雑なシーンでの汎化能力が制限されます。
この業界の課題に対処するため、香港科技大学(広州)の研究チームはDVD(決定論的ビデオ深度推定)を提案した。今回初めて、事前学習済みのビデオ拡散モデルが、単一の順伝播型ビデオ深度推定器へと決定論的に変換された。結果を生成するために複数回の反復を必要とする従来の拡散モデルとは異なり、DVDは単一の順方向計算で深度予測を完了できます。これにより、推論効率が大幅に向上するだけでなく、ランダムサンプリングによって引き起こされる幾何学的錯覚の問題も完全に解消され、ビデオシーケンスにおける時間的一貫性と構造的安定性が根本的に保証されます。
さらに、DVDは、基本的なビデオモデルに含まれる膨大な量の幾何学的および意味論的な事前知識をうまく保持することに成功した。革新的な構造的アンカー機構と潜在多様体補正(LMR)技術により、このモデルはシーン全体の安定性を維持しながら、オブジェクトのエッジ、高周波テクスチャ、および動きの詳細を正確に復元することができ、深度マップの構造的忠実度を大幅に向上させます。
複数の公開ベンチマークテストにおいて、DVDのゼロサンプル性能は最先端(SOTA)レベルに達している。さらに、わずか36万7000フレームの学習データで最高レベルの性能を達成しました。これは、主流の識別手法で必要とされる6000万フレームと比較して約163分の1の削減です。この成果は、幾何学的理解における生成ベースモデルの計り知れない可能性を証明するだけでなく、将来的に低コストで高精度なビデオ3D認識を実現するための全く新しい技術的道筋を示すものです。
開発者がDVDを迅速に体験できるよう、HyperAIは導入が容易なノートブックをリリースしました。これにより、参入障壁が低くなり、最先端(SOTA)モデルへのワンクリックアクセスが可能になります。⬇️
オンラインで実行:https://go.hyper.ai/w8kUO
オープンソースのアドレス:https://github.com/EnVision-Research/DVD
その他のオンラインチュートリアル:
デモの実行
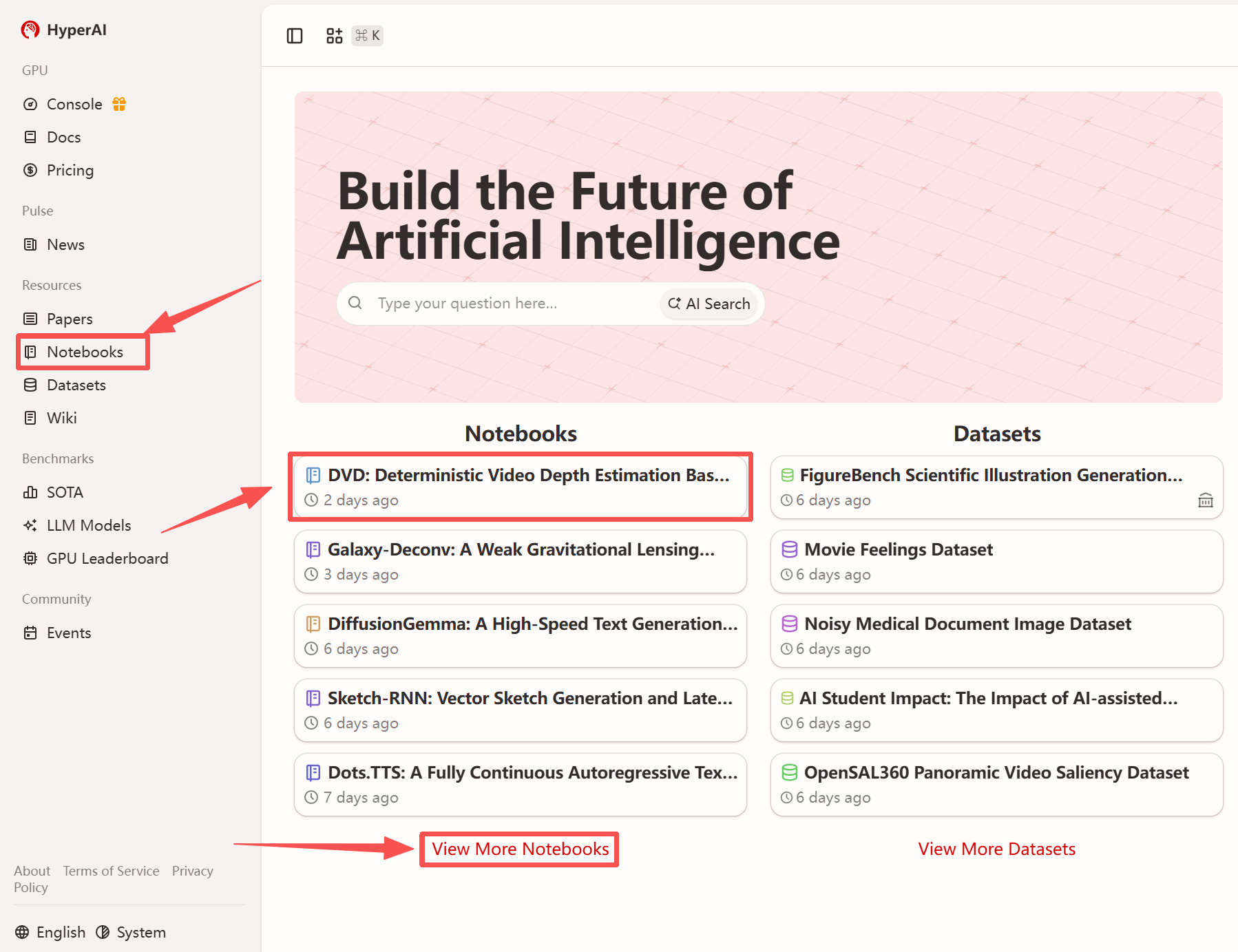
1. hyper.ai のホームページにアクセスしたら、「チュートリアル」ページを選択するか、「その他のチュートリアルを表示」をクリックし、「DVD: 生成事前分布に基づく決定論的ビデオ深度推定」を選択して、「このチュートリアルを実行」をクリックします。
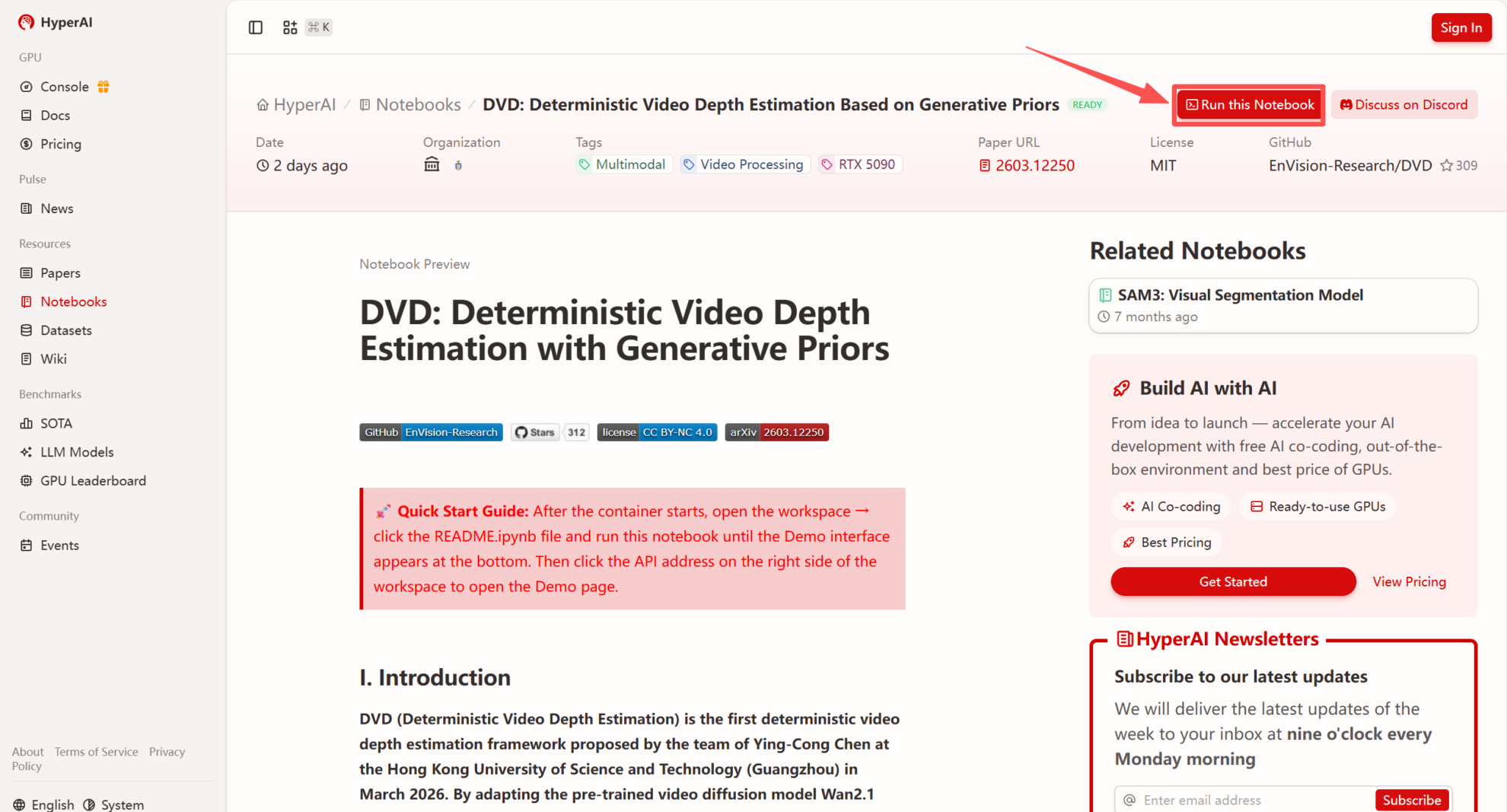
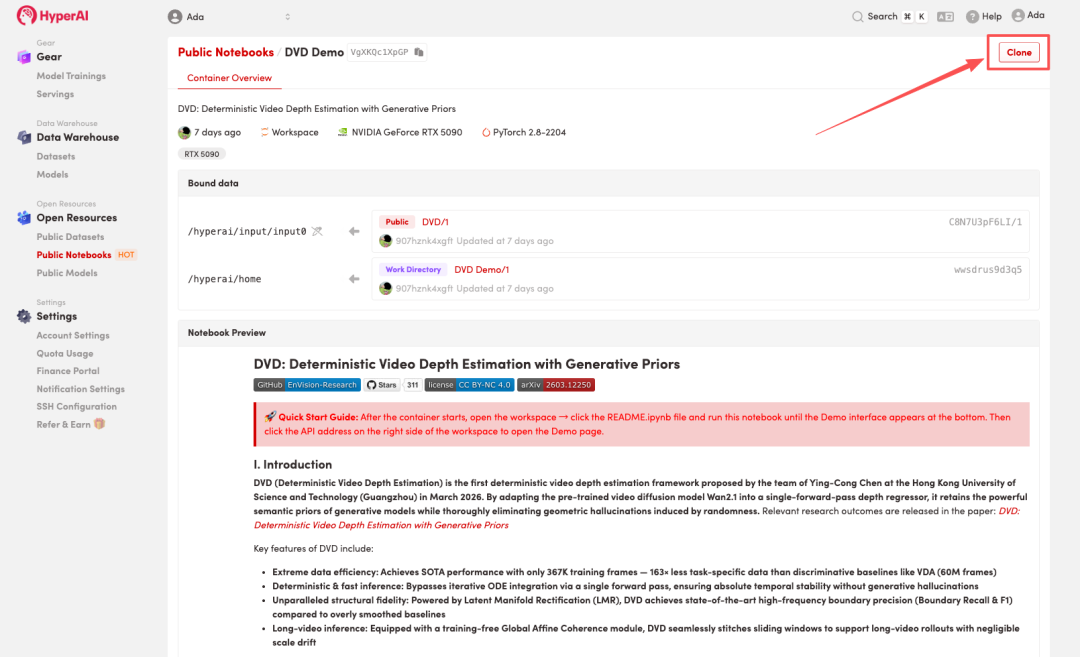
2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。
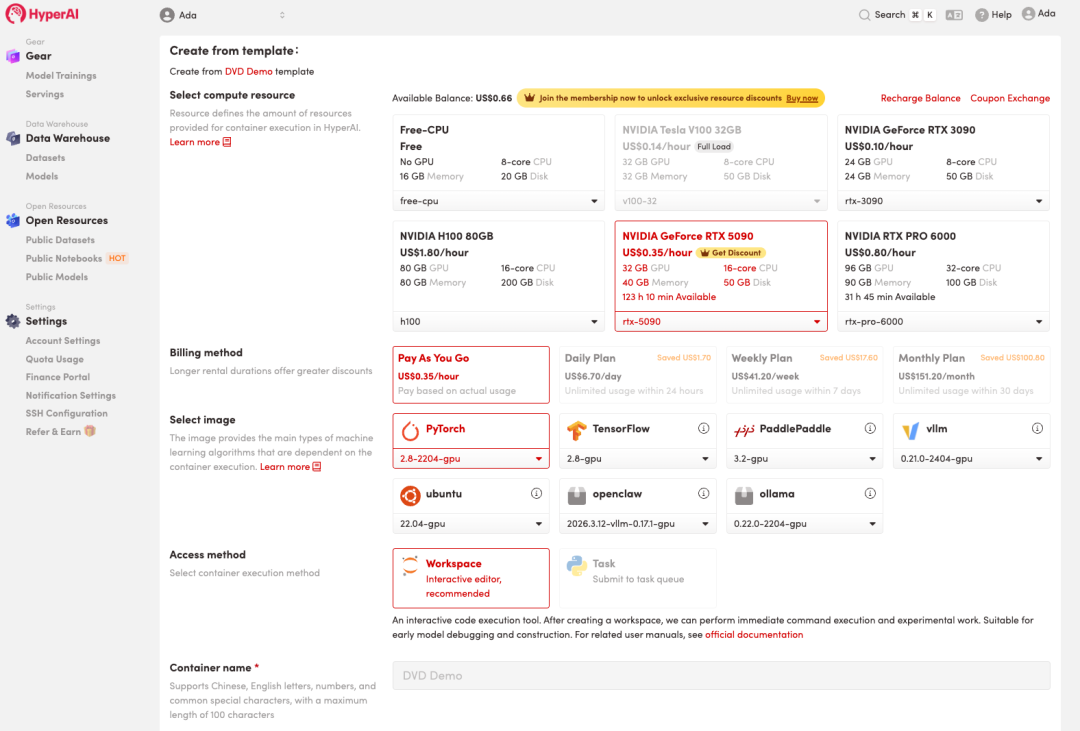
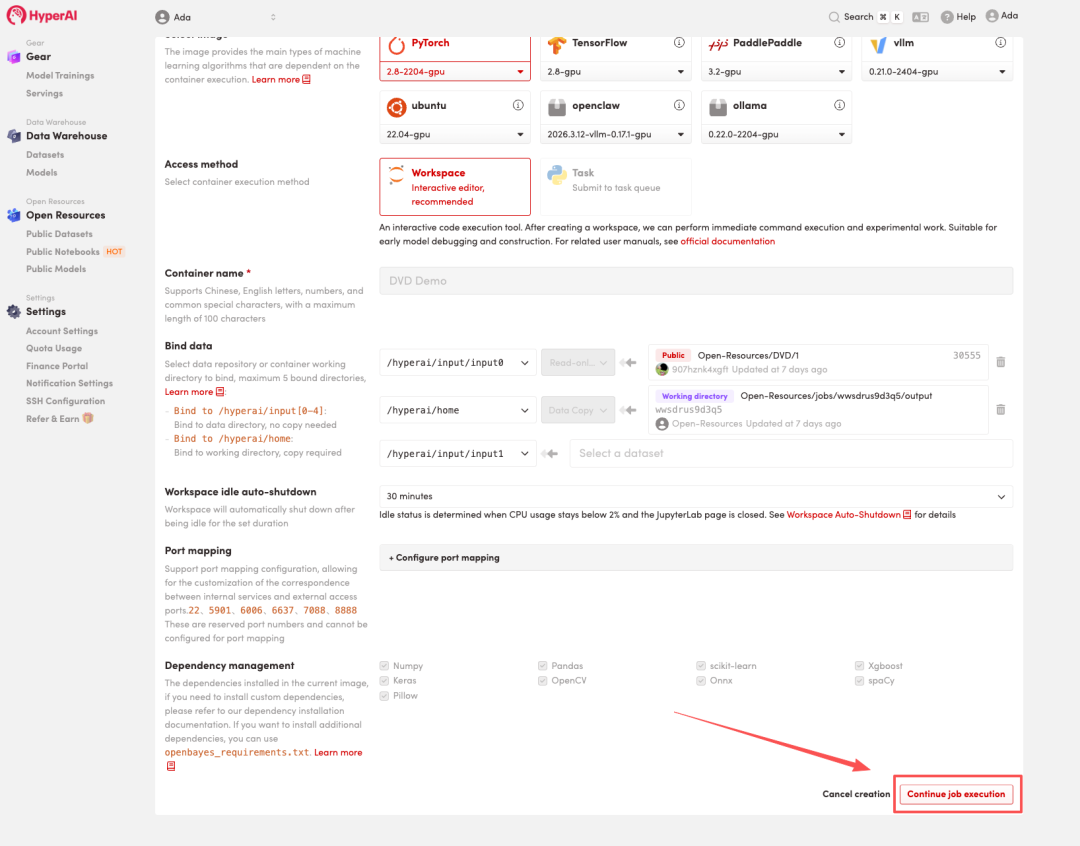
3. 「NVIDIA RTX 5090」と「PyTorch」の画像を選択し、「ジョブの実行を続行」をクリックします。
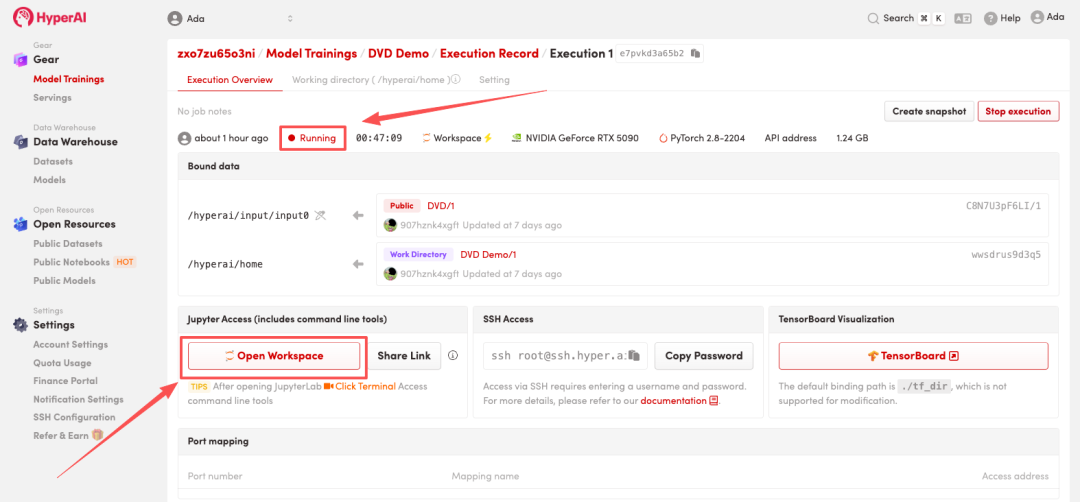
4. リソースが割り当てられるのを待ちます。ステータスが「実行中」に変わったら、「ワークスペースを開く」をクリックしてJupyterワークスペースに入ります。
エフェクト表示
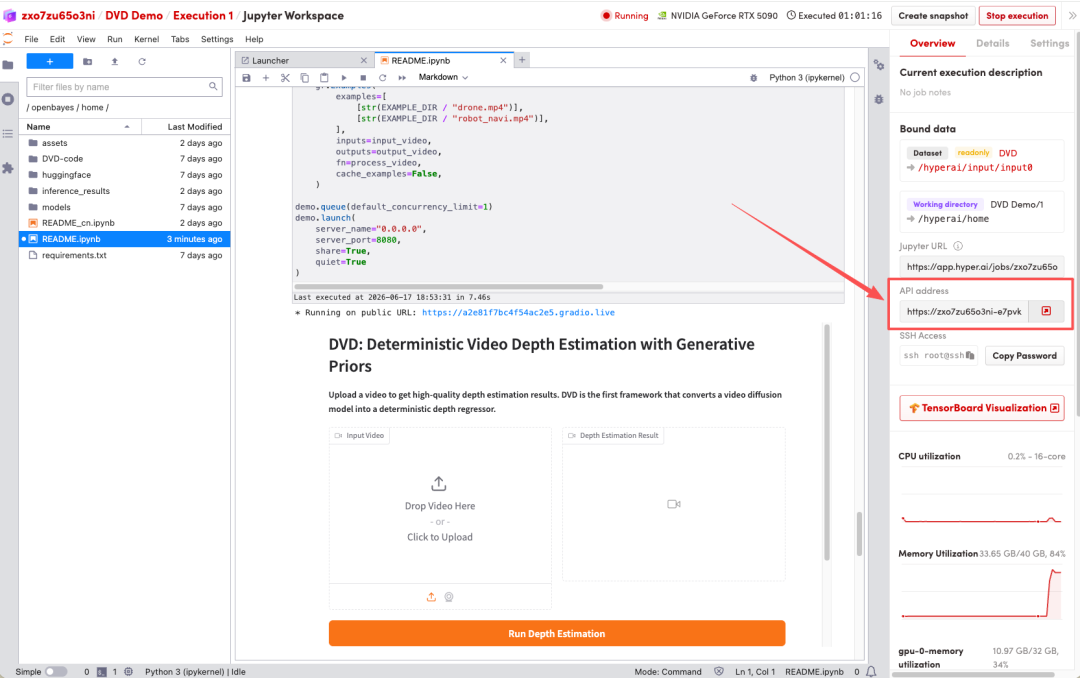
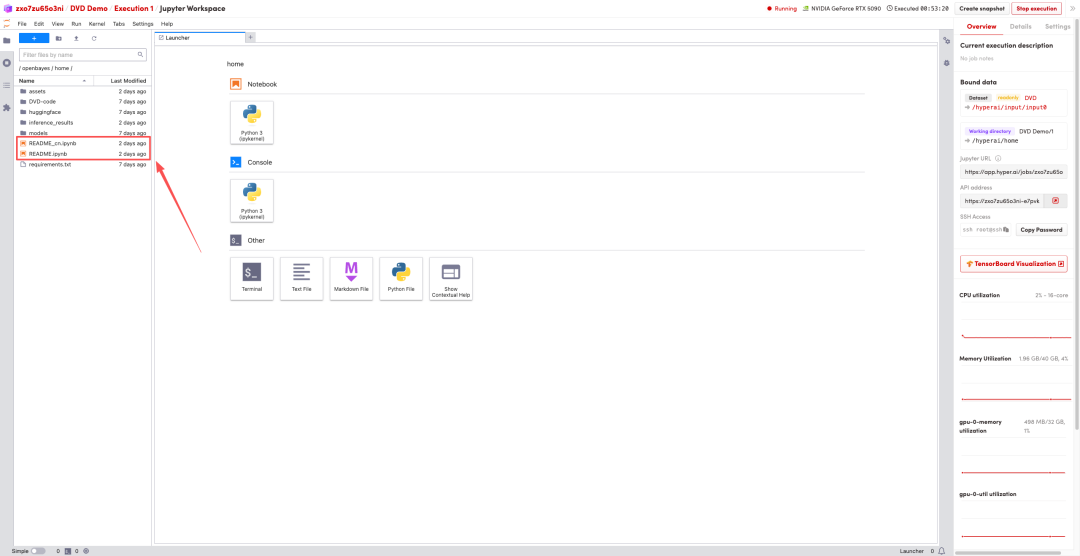
1. ページがリダイレクトされたら、左側のREADMEファイルをクリックし、上部の「実行」をクリックします。
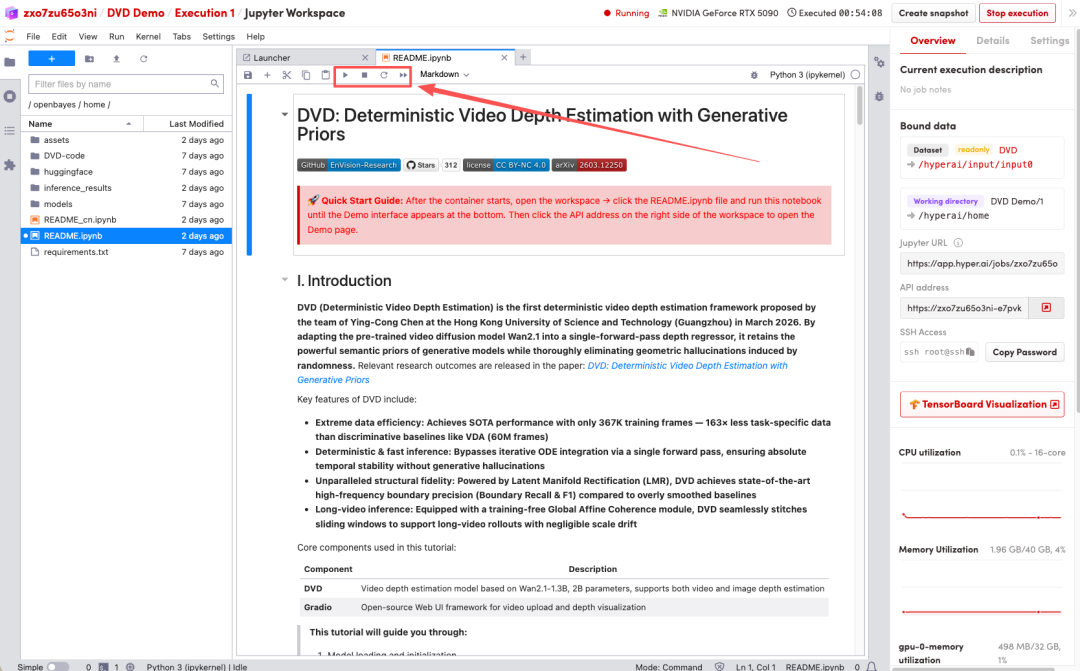
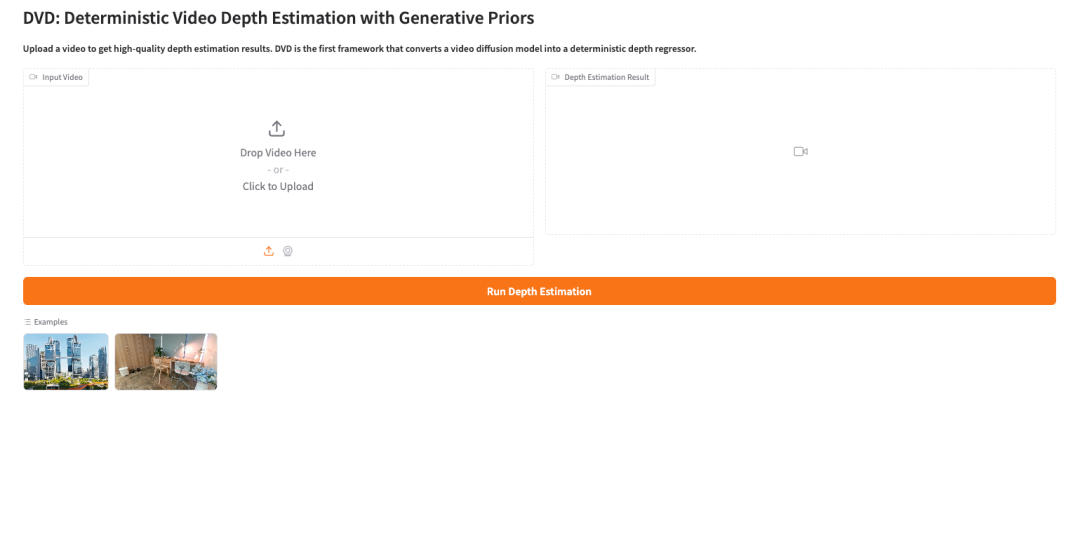
2. 処理が完了したら、右側のAPIアドレスをクリックしてデモインターフェースを開きます。