Command Palette
Search for a command to run...
論文まとめ|大規模強化学習の最新動向:マイクロソフト、グーグル、スタンフォード大学、中国人民大学、小紅書などが、信用配分、複雑な推論、エージェント強化学習における主要な成果を発表

強化学習の現状を見ると、長連鎖推論におけるクレジット配分能力の向上、複雑な環境におけるモデルの自律的探索の強化、長期計画とフィードバック学習能力を備えたインテリジェントエージェントシステムの構築など、その中核となる目標はすべて同じ方向を指し示している。報酬がまばらで監視が静的であるという限界を打破し、これにより、モデルは相互作用を通じて継続的に学習し、進化することが可能になる。
強化学習とは、本質的には、知能エージェントが「知覚→意思決定→実行→フィードバック」という閉ループを通して、行動戦略を継続的に最適化することを可能にする手法です。固定されたデータ分布に依存する従来の教師あり学習とは異なり、強化学習は、環境との相互作用における試行錯誤を通してモデルが学習する能力を重視し、動的なタスクにおいて長期的な利益を最大化する意思決定メカニズムを徐々に形成することを可能にします。つまり、強化学習は人工知能を「質問に答えることができる」段階から「自律的に行動できる」段階へと進化させており、「受動的な生成」から「能動的な知能」への大きな飛躍を遂げている。
今週、HyperAIは、大規模モデル強化学習分野における最新の研究論文の中から、厳選した6つの論文をご紹介します。このプロジェクトを支えているのは、スタンフォード大学や中国人民大学といった一流大学に加え、マイクロソフト、グーグル、快手、小紅書などのテクノロジー大手企業です。彼らの関連論文は、強力な推論能力と自己学習能力を備えた次世代の大規模モデル構築に向けた、非常に刺激的な新しいソリューションを提供しています。一緒に学びましょう!⬇️
さらに、より多くのユーザーが学術界における人工知能分野の最新の発展を理解できるようにするために、HyperAIの公式サイトに「最新論文」セクションが追加され、ユーザーは最先端のAI研究に関する最新情報を入手できるようになりました。
最新のAI論文:https://go.hyper.ai/hzChC
今週のおすすめ紙
1 エコー
論文のタイトル:
ECHO:ターミナルエージェントが無料で世界モデルを学ぶ
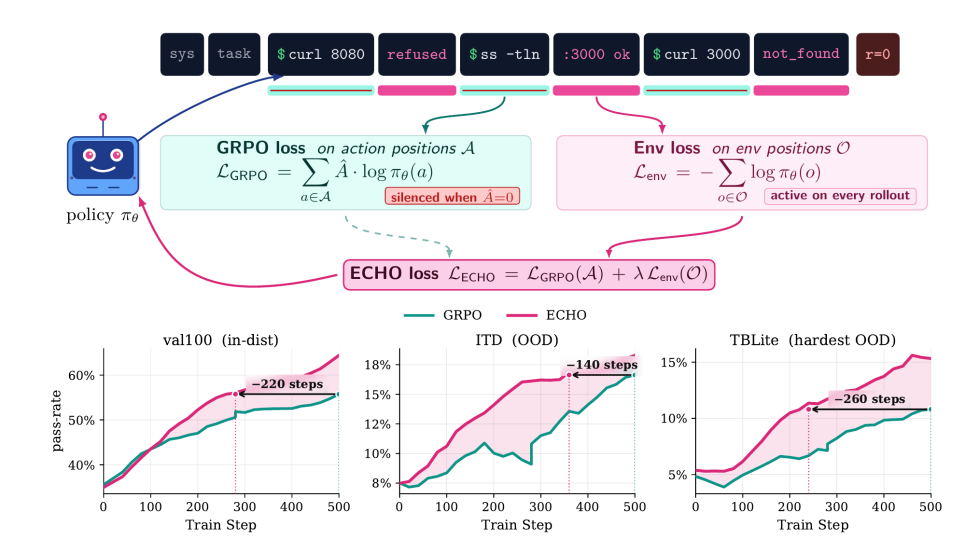
端末エージェントの相互作用は膨大な量の環境フィードバックを生成しますが、従来の強化学習では、アクションラベルの更新にわずかな報酬しか使用しないため、観測データが著しく無駄になっています。本研究では、アクション損失を維持しつつ、環境フィードバックラベルの交差エントロピー予測損失も計算するECHOメソッドを提案します。このメカニズムは順伝播のオーバーヘッドを増加させないため、ポリシーはトレーニング中に端末の指示に対する応答を同期的に予測することができ、実質的に世界モデルを無料で学習できます。
実験結果によると、この手法は端末制御ベンチマークにおける初回応答精度を2倍に向上させ、未知の端末ダイナミクスを予測する能力を大幅に高め、専門家によるデモンストレーションへの依存度を大幅に低減し、外部検証なしで自己進化を実現できることが示されています。
論文と詳細な解釈:https://go.hyper.ai/qma4O
2 デルタ
論文のタイトル:
DelTA:検証可能な報酬に基づく強化学習のための識別型トークンクレジット割り当て
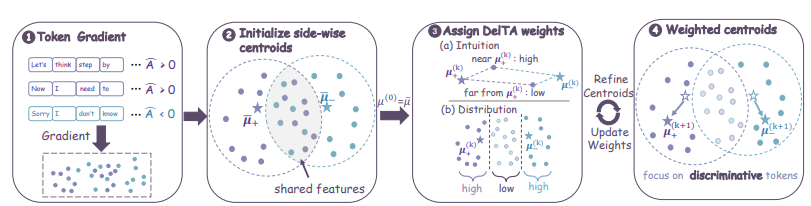
検証可能な報酬に基づく強化学習は、しばしばクレジット配分の粒度が粗すぎるという課題に直面します。定期的な更新は、組版などの高頻度で共有されるパターンに容易に支配され、真に高い報酬を生み出す重要な推論マーカーを効果的に識別することができません。この問題を解決するために、本研究では、独自の係数を計算することで自己正規化された目的関数を再重み付けするDelTAを提案します。このメカニズムは、正と負の報酬の両方に固有のマーカーの勾配方向を正確に増幅し、共有され識別力の弱い方向を強く抑制し、勾配更新のコントラストを大幅に改善します。数学的推論とコード生成の評価において、この手法は同規模の最良のベースラインを総合的に上回り、異なるアーキテクチャ間で優れた汎化能力を示します。
論文と詳細な解釈:https://go.hyper.ai/IdI42
3 ゴーロングRL
論文のタイトル:
GoLongRL:マルチタスクアライメントを備えた能力指向型長期コンテキスト強化学習
長文コンテキスト強化学習は、均質な検索訓練データによって制約を受けることが多く、従来のアルゴリズムは、複数のタスクにわたる混合報酬を扱う際に、スケールや難易度の違いによって優位性の推定が歪む傾向があります。本研究では、能力指向型のGoLongRLスキームを提案し、9つのコア能力とカスタマイズされた報酬を網羅するオープンソースデータセットを先駆的に提供します。最適化の課題に対処するため、タスクレベルの正規化を利用して異なる報酬スケールを整合させ、難易度適応型重みを組み合わせて高価値で困難なサンプルに焦点を当てるTMN-Reweightメカニズムを設計しました。評価結果は、このスキームが複数の長文ベンチマークにおいて既存の主要モデルを総合的に上回り、一般的な推論能力と記憶能力の低下を効果的に回避することを示しています。
論文と詳細な解釈:https://go.hyper.ai/omy5E
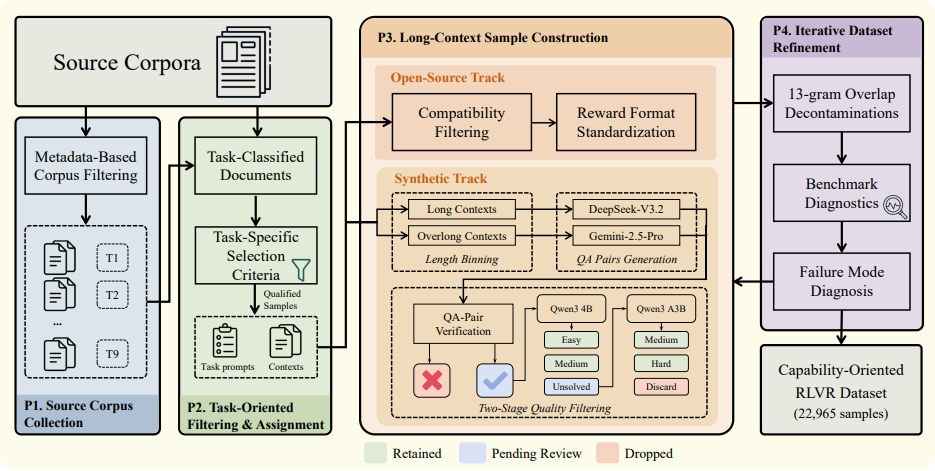
著者らは、9つの能力指向型タスクを網羅し、コンテキスト長が0.1Kトークンから256Kトークンまでの範囲である22,965個のサンプルを含むデータセットを構築した。
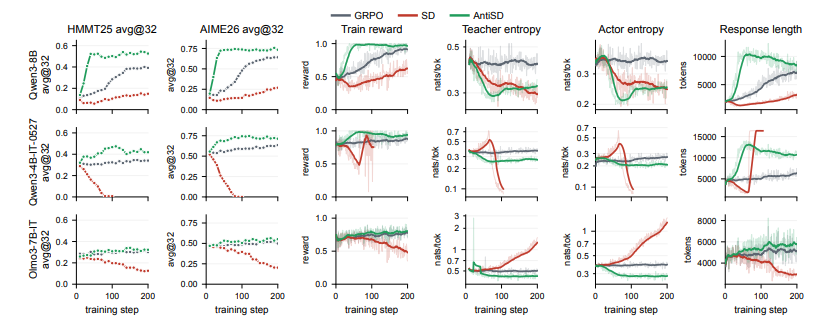
4 AntiSD
論文のタイトル:
ポイントごとの相互情報量による推論強化学習のための反自己蒸留
数学的推論タスクにおける従来の自己蒸留法では、モデルが「近道」に走りやすく、既知の答えに過度に依存し、多段階探索を真に推進する思考プロセスを抑制してしまうという問題があります。この問題に対処するため、本研究ではアンチ自己蒸留(AntiSD)法を提案します。教師モデルと生徒モデル間のギャップを単に縮小するのではなく、JSダイバージェンスを最大化して勾配信号を反転させ、特に探索的思考マーカーに報酬を与え、さらにエントロピーベースのゲーティングメカニズムでトレーニングの安定性を維持します。パラメータスケールが異なる複数の大規模モデルでのテストでは、この方法は、ベースラインのトレーニングステップの5分の1から2分の1で目標を達成できるだけでなく、複数の数学的推論ベンチマークで最終的な精度を最大11.5パーセントポイント向上させます。
論文と詳細な解釈:https://go.hyper.ai/Vax3f
5 ルーブリックEM
論文のタイトル:
RubricEM: 検証可能な報酬を超えたルーブリック誘導型ポリシー分解を用いたメタ強化学習
長期にわたる詳細な研究課題では、客観的な報酬が不足していることが多く、従来の強化学習では粗いフィードバックしか得られず、効果的な経験を蓄積することができません。本研究では、コアインターフェースとして「評価尺度」を革新的に用いるRubricEMフレームワークを提案します。このモデルは、独自に構築した尺度に基づいて、長い軌跡を計画、検索、レビュー、応答の各段階に分解し、きめ細かな報酬配分を実現します。同時に、このフレームワークはメタポリシーを非同期的に学習し、過去のインタラクションを再利用可能なリフレクティブメモリに抽出します。複数の長期研究評価において、この8Bモデルは数多くのオープンソースソリューションを凌駕し、トップレベルのクローズドソースシステムに匹敵する性能を発揮し、最小限の学習ステップで効率的な長期コンテキスト学習と優れたクロスタスク汎化を実現します。
論文と詳細な解釈:https://go.hyper.ai/xSVTh
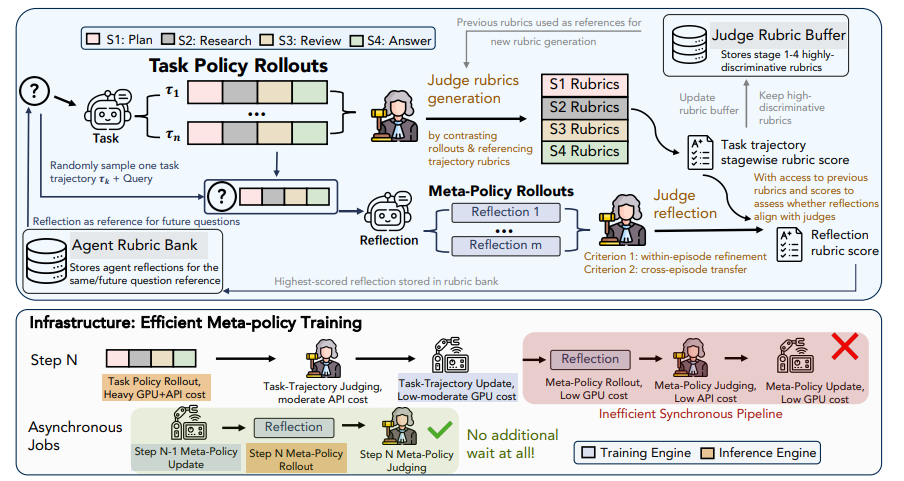
データセットの構成とソース:研究チームは、約11,000個のサンプルを含む教師ありファインチューニングデータセットを構築しました。データソースは、Gemini教師モデルによって生成され、Qwen3向けに調整されたエージェントの軌跡です。

6 ポリEPO
論文のタイトル:
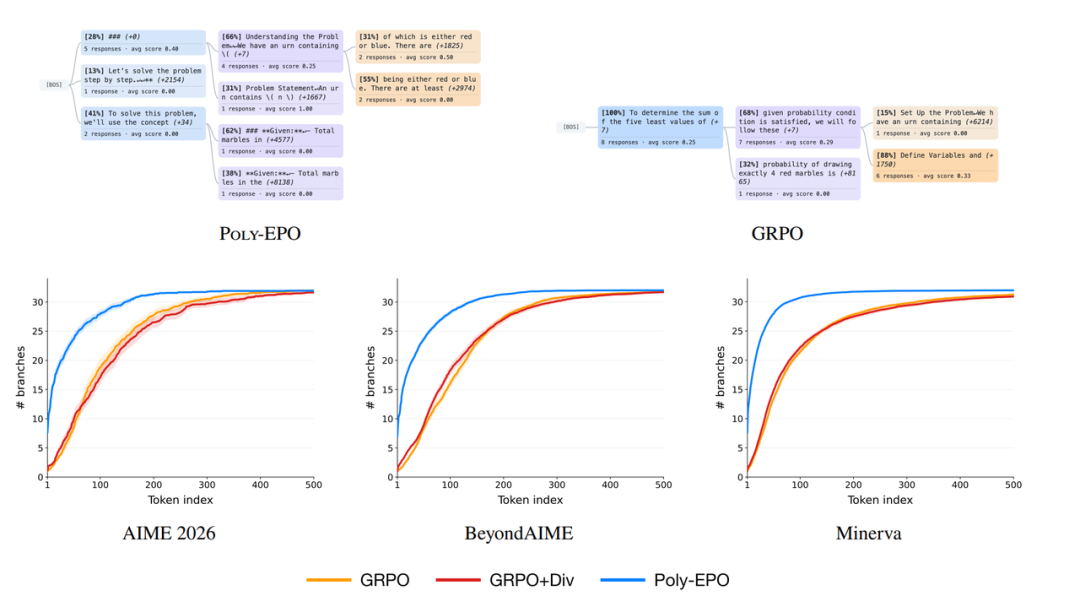
Poly-EPO:探索的推論モデルのトレーニング
大規模強化学習モデルの事後学習では、生成多様性が崩壊することが多く、テスト中の新しい推論経路の探索や計算の拡張が阻害されます。協調的な探索と利用に対処するため、本研究ではアンサンブル強化学習に基づくPoly-EPOアルゴリズムを提案します。この手法は、個々の応答を個別に評価するという従来のアプローチから脱却し、一連の応答の平均報酬に推論ポリシーの多様性スコアを乗じることで、共同最適化目標を設定し、多様な探索を促すシグナルをアドバンテージ関数にネイティブに組み込みます。数学的推論評価において、このアルゴリズムはポリシーの均質化をうまく回避し、pass@kカバレッジを最大20%向上させ、多数決メカニズムの下でより強力な拡張可能性を示しました。
論文と詳細な解釈:https://go.hyper.ai/j9Z3C
今週の論文推薦は以上です。さらに最先端のAI研究論文をご覧になりたい方は、hyper.ai公式サイトの「最新論文」セクションをご覧ください。
また来週お会いしましょう!








