Command Palette
Search for a command to run...
CVEvolveは、アルゴンヌ国立研究所が提案した、コード不要で自己発見型の科学画像処理アルゴリズムであり、コーディング、結果の自己検証、戦略最適化など、フルスタックの機能を備えている。

客観的かつ厳密な科学的結論に到達することは、広大な砂漠で砂金を探すのと同じくらい難しい。特に今日では、高度な科学機器やシミュレーション技術が広く普及しているため、なおさらである。科学研究によって生成されるデータは、膨大な量であり、構造が緩やかで、非常に非構造的である。科学研究データを処理するプロセスは、砂の中から金を探し出すようなものであり、データの価値を解き放ち、科学研究の真実を明らかにする上で、最も重要かつ中核的なステップとなっている。
しかし、まさにここにジレンマがある。専門分野の科学者は、コンピュータビジョン、画像処理、ソフトウェアエンジニアリングといったデータ処理に必要な専門スキルを欠いていることが多く、一方、データ処理に長けた技術専門家は、その分野の背景を深く理解することができず、実際の科学研究シナリオに適合する適応的な処理ワークフローを設計することが難しい。
科学データ処理から生じる専門知識のギャップに対処するため、米国のアルゴンヌ国立研究所(ANL)の研究チームは、過去のAIベースの自動化に関する研究を体系的に分析した結果、CVEvolveと呼ばれるゼロコードの自律エージェントフレームワークを開発した。このフレームワークは、科学研究データ処理に必要なアルゴリズムをマイニングするために設計されています。高い汎用性を持ち、事前に定義された問題アーキテクチャや固定されたプロセステンプレートを必要としません。コード、データ、評価指標、検索レコード、可視化結果など、さまざまな要素のクローズドループ連携を実現できます。コンピュータビジョン、画像処理、その他の分野における実行可能なアルゴリズムの開発をサポートします。単一のモデリング手法に制約されず、コード記述(実行)、効果評価、履歴追跡、結果の自己検証、戦略的な反復最適化など、フルスタック機能を備えています。
要するに、CVEvolveは、現実世界の様々な科学データ処理シナリオに適応した独自のアルゴリズムを開発できる能力を備えています。これにより、プログラミングや画像処理の知識がない分野の研究者でも、コードを一行も書くことなく、高度な分析手法を迅速に開始でき、従来の手法よりも包括的で信頼性が高く、効率的な結果が得られます。
関連する研究成果は、「CVEvolve:非構造化科学データ処理のための自律型アルゴリズム発見」と題され、プレプリントプラットフォームarXivに掲載されている。
研究のハイライト:* 自律的な科学データ処理のためのアルゴリズムを発見するための汎用プロキシフレームワークを提案します。これは、構造化されていない問題に特化して設計されており、事前に定義された問題フレームワークや固定されたプロセステンプレートの必要性を排除します。 * CVEvolveは、生成、調整、進化のメカニズムをソース認識状態管理およびエージェント駆動の保持テストと組み合わせたロングフィールド検索アーキテクチャを導入し、フレームワークの柔軟性、自律性、成熟度、および使いやすさを保証します。 * CVEvolveは、X線蛍光顕微鏡画像レジストレーション、ブラッグピーク検出、高エネルギー回折顕微鏡画像セグメンテーションなど、さまざまなタスクで検証されており、実用的なアルゴリズムを発見し、科学的発見を加速する能力が実証されています。

論文を見る:
https://hyper.ai/papers/2605.11359
3種類のタスクそれぞれについて、専用の検証データセットが作成された。
本研究では、すべてのデータセットは対照実験のために特別に設計されたものである。
蛍光顕微鏡画像位置合わせデータセット
実際のXRF画像に基づいて、並進シフト、ポアソンノイズ、スキャンジッター、ぼかしを人為的に適用し、実際の焦点ドリフトによる画像の違いをシミュレートしました。画像は対数スケールで描画され、サイズはわずか10~30ピクセルでした。データセットは809組のテスト/参照画像で構成され、101個のTP3Tがホールドアウトセットとしてランダムに割り当てられ、残りの901個のTP3Tがアルゴリズムの反復と開発に使用されました。
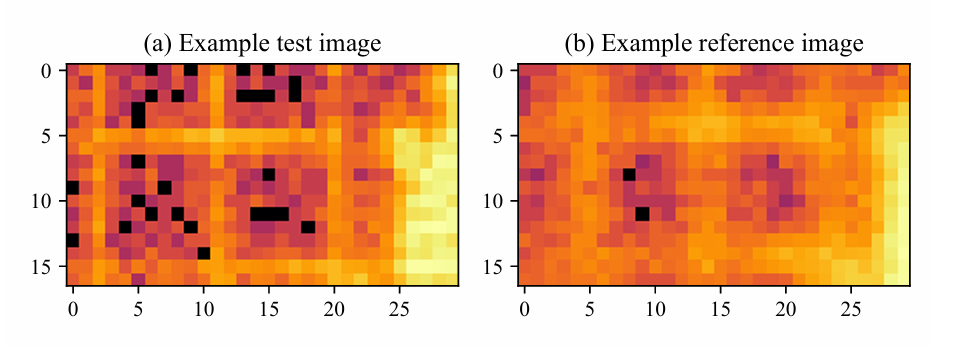
ブラッグピーク検出データセット
回折画像はすべての走査点から取得され、2つのグループに分けられた。各グループの画像はピクセル単位で重ね合わせられ、2つの画像が作成された。一方の画像はアルゴリズム開発段階における性能評価に使用され、もう一方の画像はホールドアウトセットとして使用された。両方の画像におけるブラッグピークは手動でラベル付けされた。
高エネルギー回折顕微鏡画像セグメンテーションデータセット:開発データセットには、5枚の画像とそれらに手動で作成されたラベルが含まれており、2つのサンプルはテストセット用に確保されています。
LLMベースのインテリジェントエージェントを構築するための3つの主要プロセスと5つの主要ツール。
全体的なアーキテクチャの観点から言えば、CVEvolveは、大規模な言語モデルエージェントを中心とした自律型検索コントローラです。エージェントはツールを使用して候補となるソリューションを生成、実行、評価することができ、コントローラは過去のデータに基づいてその後の探索の方向性を決定します。この反復戦略は、Pty-Chi-Evolveフレームワークに着想を得ており、生成、調整、進化という3種類の操作ステップから構成されています。拡張されたツールセットと改善された状態管理により、より多くのタスクに対応できるようになっています。
コンテキストの長さを制御し、計算コストを削減するために、各イテレーションで完全に新しいコンテキストが使用されます。このラウンドで実行されたアクションに対応するシステムプロンプトとタスクプロンプトのみが保持され、過去の対話記録は蓄積されません。同じラウンドで、生成と調整は複数の並列ワーカーによって同時に実行できるため、システムは対話記録を更新する前に、複数の新しいソリューションを探索したり、異なる元のコンテンツに対して最適化と調整を複数回実行したりできます。
各ラウンド終了後、エージェントから提出された候補アルゴリズムは、進化系統に基づいてグループ化され、親子関係が記録され、優れた設計パターンが保持されます。候補サンプリングのアーキテクチャはMAP-Elitesアルゴリズムから借用されており、ランダムに実行されます。チューニングおよび進化ステップでは、CVEvolveは常に現在の最良の候補を選択するのではなく、ランダムな候補サンプリングを使用します。
3段階のワークフロー
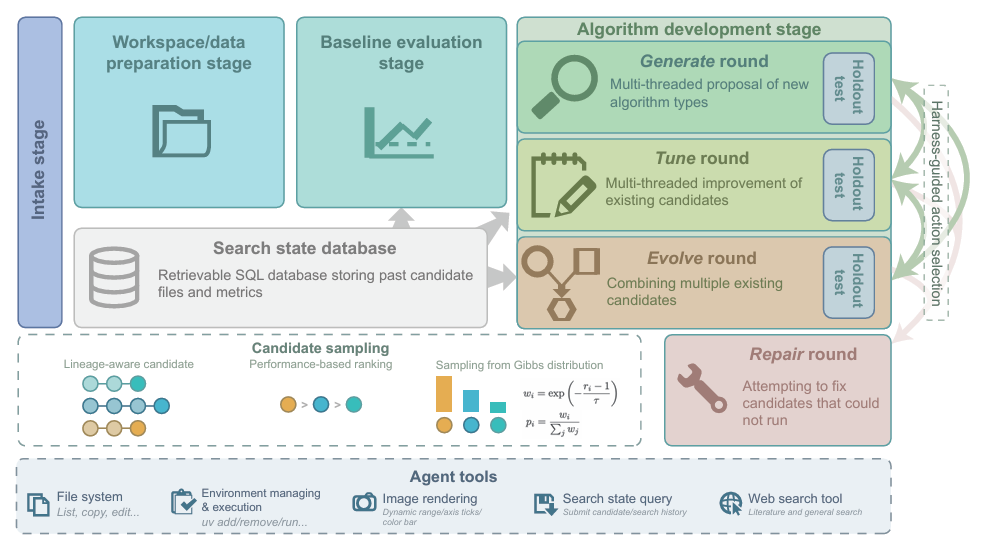
* 作業スペースの準備段階:ワークスペースの準備から始まり、実行環境がセットアップされ、タスクの説明やユーザーからのプロンプトに基づく評価指標が、実行可能な評価コードに自動的に書き込まれます。
* ベースライン評価段階:既存のベンチマークアルゴリズムを実行・評価し、その後の比較作業の基準値を提供する。
* アルゴリズムの反復と開発フェーズ:このアルゴリズムは、生成、調整、進化という戦略に従って、複数回の反復探索を実行します。生成戦略は、複数のスレッドを使用して広範囲な探索と新しいアルゴリズムの設計を担当します。調整戦略は、基本的な最適化を担当し、最適な候補アルゴリズムをランダムに選択してそのパラメータを最適化します。進化戦略は、反復的な進化を担当し、複数のアルゴリズムの利点を組み合わせて新しいアルゴリズムを生成します。
さらに、研究の厳密性と合理性を確保するため、全体のプロセスには、実行できない候補アルゴリズムを修正するためのオプションの修復ラウンド、各ラウンド後の独立したテスト、ステータスデータベースのSQL検索、およびプロセス全体を通しての候補、指標、反復ラウンド、進化系統の記録も含まれています。
5つの主要なサポートツール
* ファイルシステムツール:ワークスペース内のファイルの一覧表示、読み取り、書き込み、編集、コピー、移動、削除をサポートしており、エージェントはセッションサンドボックス内で候補コード、ヘルパースクリプト、評価ツールを作成できます。
* 環境管理およびコード実行ツール:サポートワークスペースにおける依存関係のインストールまたは削除、およびPythonスクリプトの実行。
* 画像表示ツール:浮動小数点画像処理、高ダイナミックレンジ画像の対数スケーリング、TIFFからPNG形式への変換、その他の調整機能をサポートしており、通常の線形レンダリングでは検出が困難な微細な構造、明るさの変化、異常を識別することを可能にします。
* 検索ステータスツール:これは、エージェントがコア指標を設定し、評価結果を記録し、履歴データを検証し、候補者の結果を分析し、構造化クエリ言語で検索レコードに新しい候補者を提出する際に役立ちます。
* ウェブ検索ツール:arXiv、Semantic Scholar、およびTavilyへのアクセスを許可することで、外部の技術参考情報を活用し、反復アルゴリズムの開発が促進されます。
さらに、大規模な言語モデルインターフェースでは画像を直接送信できないという制約を補うため、マルチモーダル画像フォローアップミドルウェアが設計に追加されました。具体的には、ツールが画像パスを返すと、レンダリングされた画像がフォローアップメッセージとしてダイアログに自動的に再挿入されます。
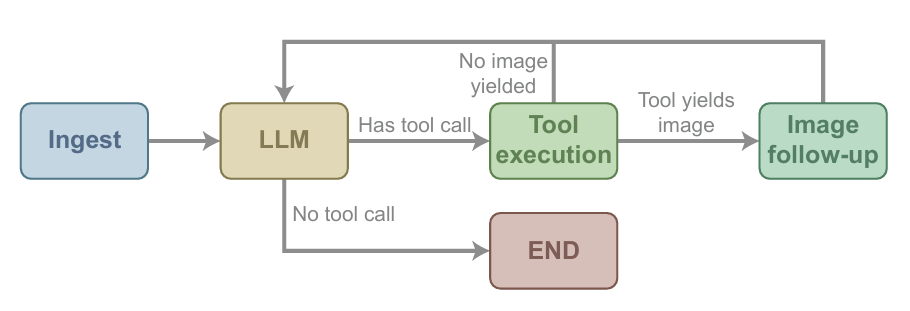
コアとなる基盤となる実行アーキテクチャ
CVEvolveはLangGraphをベースとしたエージェントアプリケーションです。実行時には簡略化されたノードグラフを使用し、メッセージ受信、モデル推論、ツール呼び出し、画像後処理という4つのコアプロセスを通じてデータを処理します。ツールが画像パスを返すと、画像処理ノードがそれをマルチモーダル観測データに変換し、次の推論ラウンドで使用するためにモデルに送り返します。詳細は以下の図を参照してください。
3種類の科学画像処理シナリオにおけるCVEvolveの実用性の検証
CVEvolveの実用性と汎用性を実証するために、研究チームは、その有効性を検証するための、実際の科学画像処理実験を3セット特別に設計した。すべての実験はClaude Opus 4.6を使用して実施されました。
蛍光顕微鏡画像の位置合わせ
研究者らはまず、顕微鏡の焦点合わせ後の画像オフセット補正の問題に対処する、X線蛍光顕微鏡(XRF)画像の並進位置合わせのための堅牢なアルゴリズムを見つけるというCVEvolveのタスクを実証した。
ベースラインアルゴリズムには、ハニング窓前処理を用いた位相相関と総当たり誤差最小化の2種類があり、性能比較指標は、計算されたシフトと真のシフトとの間の平均ユークリッド距離です。
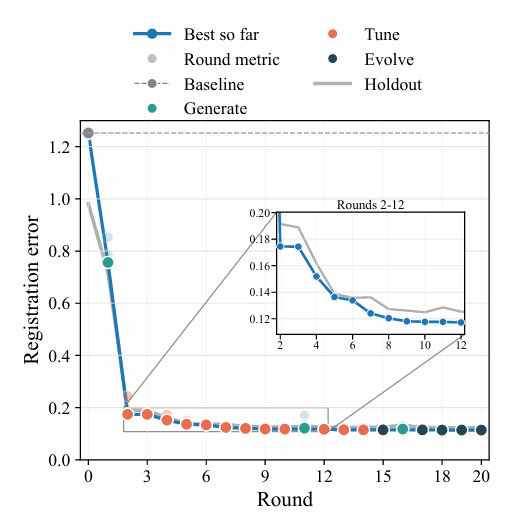
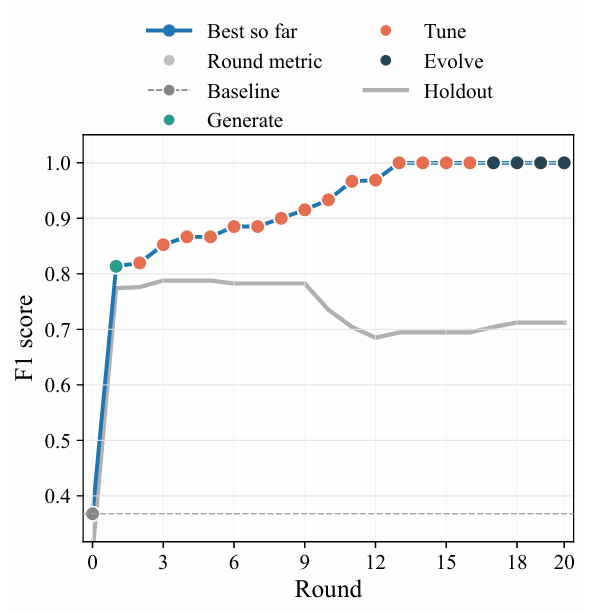
本研究では、20回の探索ラウンドを経て、誤差の変化と性能特性を明らかにしました。最初のベースラインラウンドでは、総当たり誤差最小化の平均ユークリッド誤差は1.25でしたが、ハニング窓前処理後の位相相関法の誤差は5.8に達しました。その後の生成および進化ラウンドを経て、位置合わせ誤差は継続的に減少し、それぞれ0.8と0.43に達し、9ラウンド後には性能が安定しました。これは下図に示されています。
最適な位置合わせアルゴリズムを選択するために、本アルゴリズムは粗密段階の画像位置合わせ手法を採用しています。まず、マルチスケール正規化相互相関を用いて、整数ピクセルレベルでの位置合わせと位置決めを行います。次に、スプライン関数や最適化アルゴリズムなど、様々な前処理手法を組み合わせて、精度をサブピクセルレベルまで向上させます。最後に、座標に基づいて複数の推定結果セットに適切な重み付けを行い、統合することで、安定かつ信頼性の高い最終オフセットを出力します。
ホールドアウトセットでのテストとさまざまなベースラインアルゴリズムとの比較により、最適な位置合わせアルゴリズムのエラーは0.12であり、より優れた性能を持つ総当たりエラー最小化アルゴリズムよりも約8倍低いことが示されました。一方、研究者らはさらに、CVEvolveによって発見された候補とOpenEvolveによって発見された候補を比較した。500回の反復後、誤差は0.23で安定したが、これはCVEvolveによって発見された候補アルゴリズムの誤差よりもかなり高い値だった。次の表に示すように:

ブラッグピーク検出
本実験の目的は、X線回折画像におけるブラッグピークを検出するアルゴリズムを見つけることである。目標は、特定の格子面の対応する環状領域内およびその周辺におけるブラッグピークを識別し、位置を特定する手法を開発することである。評価指標には、F1スコア、精度、再現率が含まれる。
開発データセットには画像が1枚しか含まれていないため、アルゴリズムは過学習を起こしやすく、汎化性能を監視するためにホールドアウト法を使用する必要があります。結果を下図に示します。開発セット画像のF1スコアは上昇を続け、最終的には満点の1に近づきますが、予約テストセットのF1スコアは5ラウンド目でピークに達した後、9ラウンド目以降は急激に低下し始めます。
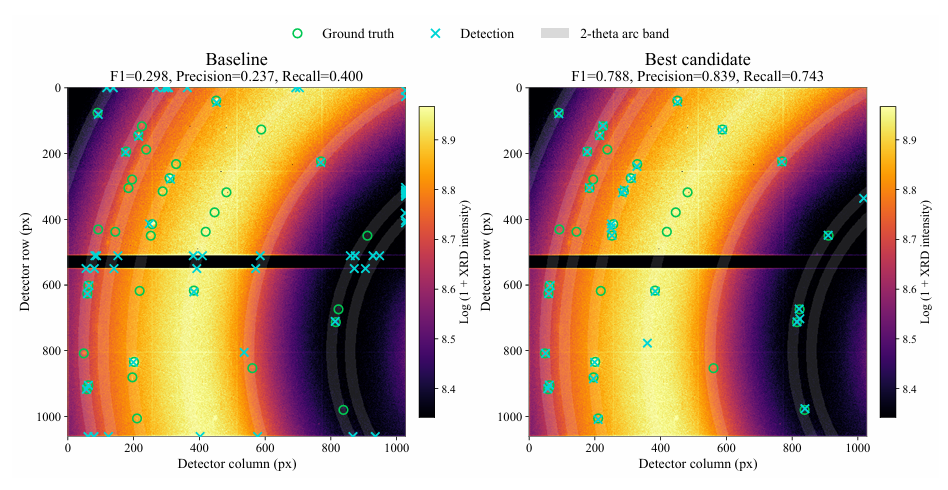
次に、第5ラウンドで最適な候補を選択します。まず、無効領域をマスクし、円弧状の極座標を用いて背景を減算し、局所ノイズを正規化することで信号対雑音比マップを生成します。その後、複数ラウンドの相補アルゴリズムを用いてピーク値を求めます。最後に、中心点を統合、検証、最適化して、最終的なピーク座標を出力します。
結果は次のようになります。最適な候補ソリューションは、誤検出を効果的に軽減すると同時に、検出漏れの数を減らし、より多くのラベル付きピークを特定することができる。最良候補は、すべての指標においてベースラインを上回る性能向上を達成しました。F1スコアは0.298から0.788に、精度スコアは0.237から0.839に、再現率スコアは0.400から0.743(検出漏れに対応)にそれぞれ向上しました。詳細は下図をご覧ください。
回折画像のセグメンテーション
本研究の課題は多結晶回折画像のセグメンテーションであり、その難しさは回折環とブラッグピークを正確に区別することにあった。実験では重み付きIoU(Intersection-to-Union)指標を用い、40回の観測を行った。その結果、…エージェントが背景差分と閾値分割によって特徴を識別して作成した初期のベースライン候補は、最終的に交差結合比がわずか0.37となり、精度が低いことがわかった。以下に示すように。
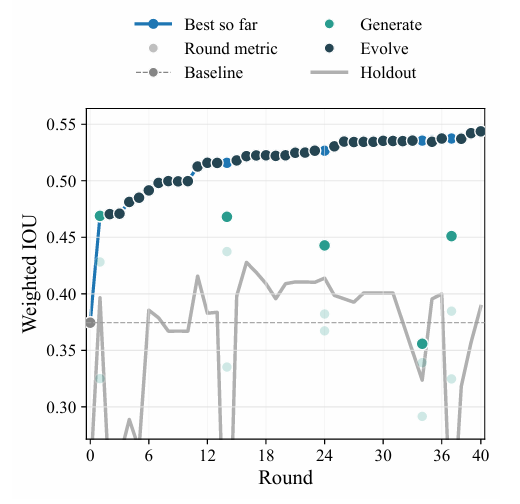
次に、保持テストの指標を追跡することで、16回目のラウンドで最適な候補アルゴリズムが選択されました。候補アルゴリズムは対数回折画像に変換され、ビーム中心と放射状背景パラメータが計算され、放射状および方位角の一貫性チェックを通じて環状結果が識別および検証されました。ピクセルは背景閾値に基づいて分割され、最後に回折ピークが精製され、セグメンテーションマスクが生成されました。
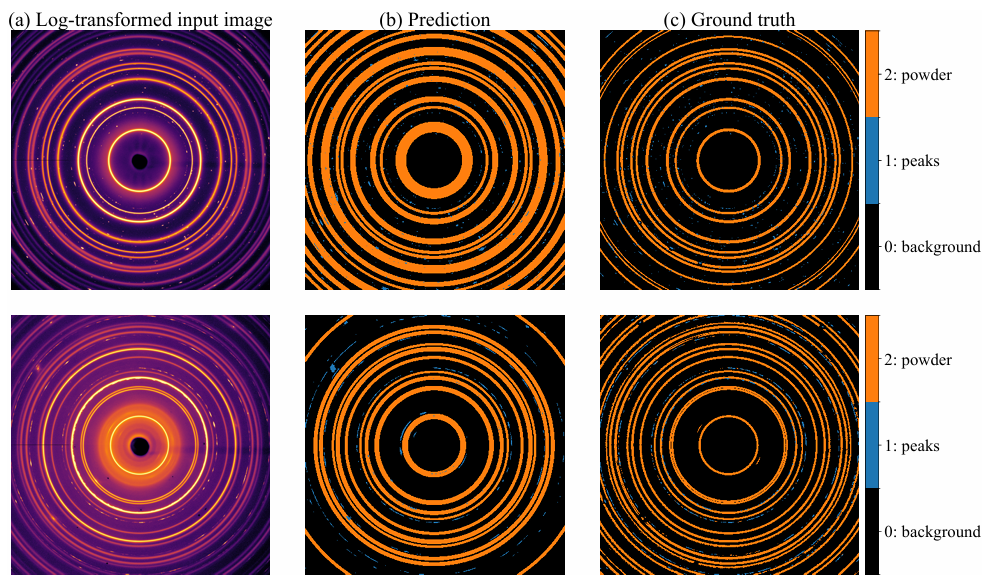
結果によると、最初のデモンストレーションでは、予測された環状マスクは実際のベースライン輪郭よりも幅広く厚かったが、慎重な検証の結果、環状構造の大部分が正常に検出され、様々なブラッグピークも適切にセグメント化されていることが確認された。予測されたマスクは、実際のベースライン輪郭と高い適合度を示した。2回目のデモンストレーションでは、外側領域のごく一部の環状構造が識別および検出されなかった。
最後に書きます
要約すると、CVEvolveのゼロコード開発は、計算画像処理技術への参入障壁を大幅に低減し、現場の科学者がカスタマイズされた科学データ処理を迅速に行えるようにします。今後、CVEvolveは、論文で述べたように、高度なデータ処理とリアルタイムのワークフロー最適化へと拡張することで、その機能をさらに強化していくことが期待されます。これにより、自律的な科学発見ワークフローは、知能と技術の両方によって推進される時代へと突入するでしょう。








