Command Palette
Search for a command to run...
Googleのグローバル洪水予測システムがバージョン2にアップグレードされ、信頼できる予測期間が6日間延長され、精度が大幅に向上しました。

洪水は、世界で最も広範囲に及び、甚大な被害をもたらす自然災害の一つです。河川流量予測の精度と洪水警報の迅速な発令は、河川流域の防災・減災能力、生態系の安全、そして社会経済活動の安定性に直接影響を与えます。そのため、水文学では長年にわたり、「いかにして洪水をより正確に予測するか」を主要な課題の一つとして捉えてきました。
過去数十年にわたり、機械学習は水文シミュレーションと洪水予測の分野で継続的な進化を遂げてきた。初期の研究は主に概念的な降雨流出モデルに焦点を当てていた。これらの手法は、観測データが乏しく、現地測定ステーションが少ない「データ不足流域」において重要な役割を果たしてきた。データ規模と計算能力の向上に伴い、研究の焦点は予測精度の向上といった単純なものから、モデルの解釈可能性、不確実性の定量化、データ同化、深層学習とメカニズムモデルの統合といったより複雑な方向へと徐々に移行し、「データ+メカニズム」の相乗効果によって水文予測は新たな段階へと進んでいます。
こうした背景のもと、Google Researchは最近、ビジネスで検証済みの機械学習による水文モデルを、世界の洪水予測システムに大規模に導入した。同社のグローバル洪水予測システムの第2版(v2)が正式にリリースされ、Google FloodHubの河川予測モジュールのコアエンジンとなった。初版と比較して、v2では、運用展開を阻害してきた3つの主要な長年の課題、すなわち、訓練データの不足、時系列データの長さの制限、および入力データの分布の偏りに対処するための体系的な改善が提案されています。これらの改善により、地球規模の河川流量予測の安定性と信頼性が大幅に向上します。
しかし、「モデルの有効性」から「コミュニティにおける再現性と拡張性」へと移行するには、アルゴリズムの透明性やデータの公開性といった課題に取り組む必要があります。こうした点を踏まえ、研究チームはv2システムのリリースと同時に、開発プロセスの主要な実装詳細と現在直面している課題についても公表しました。彼らはまた、Google流出量再分析・再予測データセット(GRRR)も公開した。このデータセットは、世界中の100万を超える河川観測地点を網羅しており、数十年にわたる過去のシミュレーション結果と再予測結果が含まれているため、その後の方法論的研究やモデルの反復のための重要なデータ基盤となる。
関連するデータセットはオンラインで入手可能です。
関連する研究成果は、「中期世界洪水予測の拡張:Google世界洪水予測モデルバージョン2」と題され、EGUsphereに掲載されました。
研究のハイライト:
* 世界洪水予測システムの第2版を導入し、信頼性の高い予測の有効期間を大幅に改善した。
* 世界中の1,223の試験流域において、統合予測の第2バージョンは、第1バージョンおよび2つの第三者機関のベースラインモデルと比較して、優れた精度を示した。
* NSEを評価指標として使用した場合:ライブ予測の最初のバージョンと比較して、2番目のバージョンでは、実際の観測ステーションがある流域では信頼できる予測期間が6日間、実際の観測ステーションがない流域では1日間延長されます。

論文を見る:
https://egusphere.copernicus.org/preprints/2026/egusphere-2026-2283/
データセット:静的属性、動的要因、および流出観測データ
河川予測モデルの中核的な役割は、各流域の出口における日平均流出量を予測することである。モデルへの入力データは主に3つの部分から構成されます。静的な流域属性、動的な気象駆動データ、および目標流出データです。
静的流域属性は、流域の長期的、安定的、かつ時間的に不変な物理的特性を記述するために使用される。本研究では、合計92個の空間平均属性を使用した。このデータは主にHydroATLASから取得され、ERA5-Land再解析データと組み合わせて、地形、気候、土地被覆、土壌、人間の活動など、さまざまな側面を網羅する水文気候統計を計算します。これには、平均標高、乾燥度、降水量の季節性、森林被覆、土壌水理特性、人口密度などが含まれます。
動的な気象データは、水文応答を引き起こす気象プロセスを特徴付けるために使用されます。既存の研究では、複数の情報源からの気象データの融合により、LSTMのようなモデルの予測能力が大幅に向上することが示されています。そのため、v2システムでは、欧州中期予報センター(HRES)、米国海洋大気庁(NOAA)のCPC、GraphCast、米国航空宇宙局(NASA)のIMERGなど、複数のグローバル気象プロダクトを同時に統合しています。入力変数には、総降水量や2メートル気温などの主要な気象要素が含まれており、日単位のデータに統一的に集約されます。単一の気象情報源と比較して、この複数情報源融合アプローチは、異なる地域や時間スケールにわたるエラーの問題をより効果的に軽減できます。
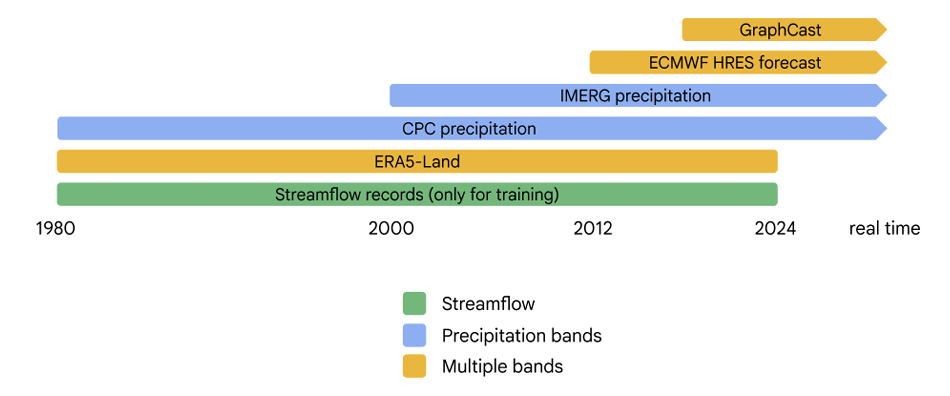
動的入力データセットと目標流出データの時間的利用可能性
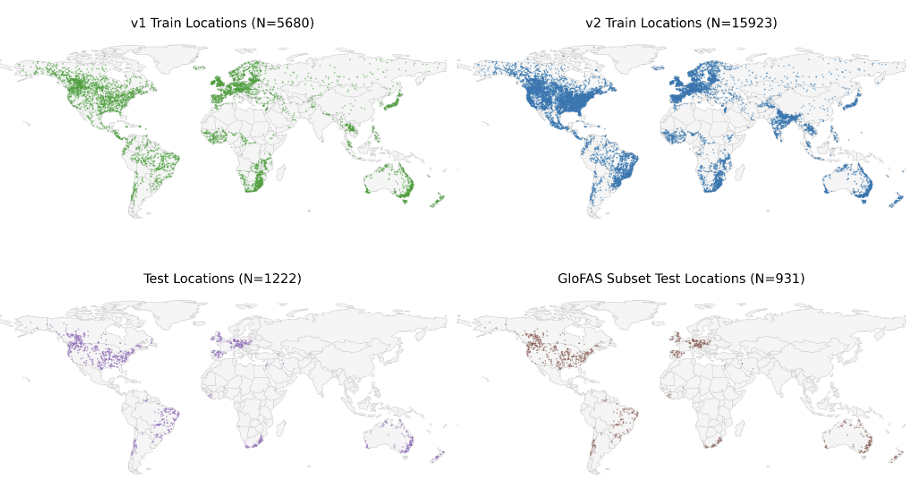
流出データに関して、v2システムは、Caravan、GRDC、BANDASの3つのデータセットを使用してトレーニングされます。v1 は GRDC のみに依存していました。比較可能性を確保するため、v1 で使用された GRDC テストサイトは v2 テストセットに完全に保持されました。下の図に示すように、拡張されたトレーニングサンプルは、世界中のさまざまな気候帯と水文環境をカバーしており、空間的代表性が大幅に向上しています。Caravan 自体は、CAMELS システムに基づいて構築された大規模サンプルのオープンソース流域データセットであり、複数の国と研究機関からのデータリソースを統合しています。
このモデルは、事業運営における2つの段階、すなわち「事後報告」と「予測」を区別している。報告後の段階では、主にHRESとGraphCastの0日リードタイムデータが利用されますが、CPCとIMERGはリアルタイム予測を提供できないため、今後の時系列予測からは除外されます。HRESとGraphCastの運用アーカイブはそれぞれ2012年と2016年に開始されるのに対し、ERA5-Landと流出観測データは1980年まで遡るため、研究チームはERA5-Landを使用して欠落している初期期間を補完し、長期系列トレーニングの一貫性を維持しました。
アーキテクチャのアップグレードにより、予測初期化における急激な変化という不具合が完全に解消されました。
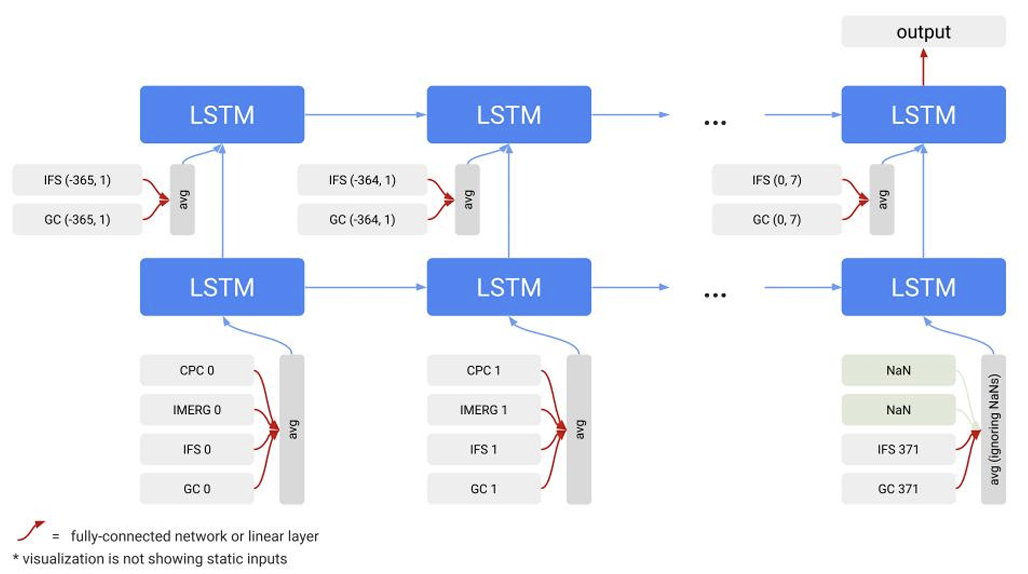
Googleが開発した世界規模の洪水予測システムの第2バージョンの核となるのは、平均値埋め込み型長短期記憶ネットワーク(ME-LSTM)である。最初のバージョンで使用されていたエンコーダー・デコーダーLSTM(ED-LSTM)と比較して、ME-LSTMは欠損入力や長期時系列予測の処理により適しており、v1で報告後段階と予測段階を切り替える際に発生しやすかった予測の突然変異の問題も解決しています。
v1では、事後評価と予測は2つの独立したLSTMによって処理されます。事後評価ネットワークが出力する隠れ状態とセル状態は、小さなニューラルネットワークによって変換され、予測ネットワークの初期化に使用されます。この設計の目的は、事後評価段階と予測段階で異なるデータ分布を学習できるようにすることで、観測データ、再解析データ、および天気予報データ間の不一致を軽減することです。しかし、実際の運用では…この構造は、初期予測状態において不安定性を容易に引き起こし、モデルが実際の水文過程に迅速に対応するよりも内部状態の調整を優先するようになり、結果として不連続な予測結果が生じる可能性がある。
この問題を解決するため、ME-LSTMはすべての気象入力データを直接結合する方式を廃止しました。その代わりに、各気象データは独立した入力ソースとして扱われ、専用の組み込みネットワークを介して共有の隠し空間にマッピングされる。埋め込み処理の前に、静的な流域属性は対応する動的入力と連結されます。その後、モデルはマスク平均メカニズムを使用してさまざまなソースからのデータを自動的に集約し、欠落した入力を無視することで、欠落データや入力分布の変動に対する堅牢性を向上させます。
時系列モデリングのレベルではME-LSTMは、2つのLSTM層を重ね合わせることで時系列データを均一に処理し、予測段階と予報段階を手動で分離する必要性をなくします。そのため、モデルの状態は継続的に変化します。これにより、v1における状態遷移の問題が根本的に解消されます。最初のLSTM層は入力シーケンス全体を処理して集約された特徴を生成する役割を担い、2番目のLSTM層はこれらの特徴を使用して流出予測を完了します。
両モデルとも、確率的予測を実現するために混合密度出力層を採用しており、将来の流出量の不確実性を特徴付けるために、計数可能な混合非対称ラプラス分布(CMAL)パラメータを出力する。本論文で提示する決定論的結果は、予測分布の平均値から導出されたものである。
トレーニングにおいて、v2はAdamオプティマイザとCMAL尤度損失関数を使用し、ガウスノイズ注入、勾配剪定、ランダム入力破棄などの戦略によってモデルの堅牢性を向上させています。一部の時系列入力特徴量をランダムに破棄する設計により、実世界のビジネス環境における欠損データへの対応能力が向上します。トレーニングプロセス全体は125エポックで構成され、複雑なグローバル水文環境におけるモデルの汎化能力を向上させます。
時間的相関性を高めることで、統合予測の第2バージョンの精度が大幅に向上する。
本研究では主に、v2システムの性能を2種類のシナリオで評価する。1つのカテゴリは、実際に水文観測所で測定された流域であり、もう1つは、局所的な測定データがなく、予測のために流域横断的な一般化機能にのみ頼る「データフリー流域」です。v1で使用されたランダム化10分割交差検証と比較して、v2ではさらに独立したテストセットを使用して評価を行うため、実験は実際のビジネス展開環境に近くなります。
v2ではモデルアーキテクチャが更新されただけでなく、トレーニングデータと気象入力も拡張されたため、研究チームはまた、AIによる天気予報データの貢献度を個別に分析するために、GraphCastの入力を削除した簡略版も作成した。本実験では、主要指標としてナッシュ・サトクリフ効率係数(NSE)とクリング・グプタ効率係数(KGE)を用いた。前者はモデル全体の適合性を測定するものであり、後者は時間的一貫性、水収支、流量変動といった側面からモデル性能を分析するものである。試験期間は2016年から2023年までとした。
モデルの初期化には長い履歴データが必要であることを考慮し、研究者らはテスト年の前後にそれぞれ1年間の隔離期間を設け、時間情報の漏洩を防ぐため、これらの期間をトレーニングセットから完全に除外した。最終的に、合計1,222の共有テスト流域が統一評価のために選択された。ベンチマークには、Global Flood Awareness System (GloFAS) や European Flood Awareness System (EFAS) などの従来の運用モデルが含まれた。
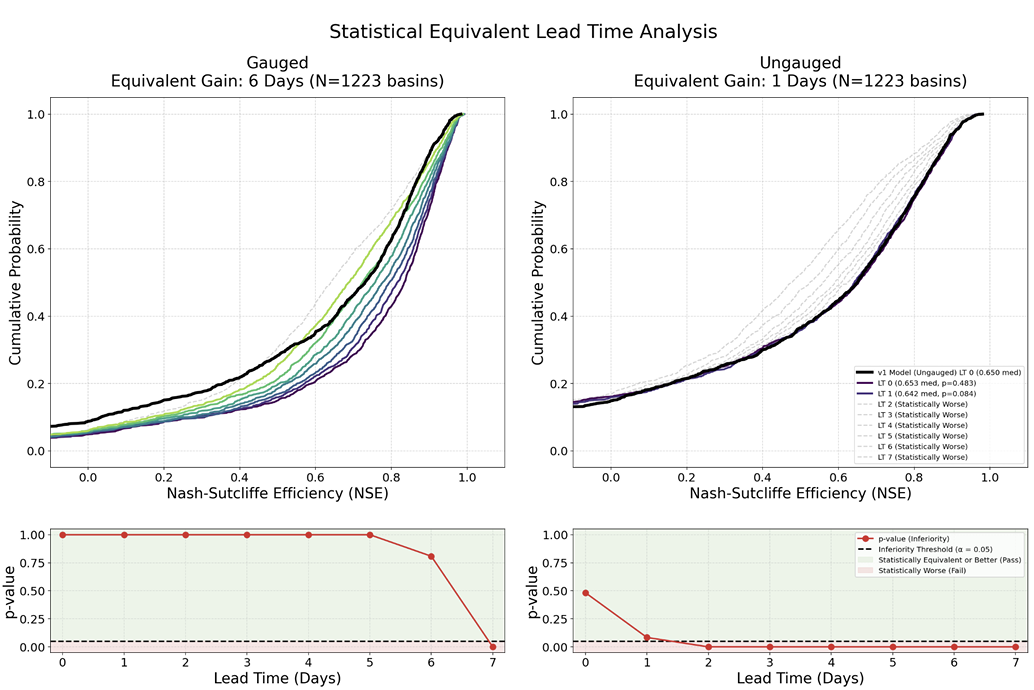
結果は次のようになります。v2は、世界規模、様々な予測期間、そして両方のシナリオにおいて、v1を大幅に上回る性能を発揮します。一方、Googleの2世代にわたるモデルは、いずれも従来のビジネスモデルを大幅に上回る性能を発揮しています。モデルアーキテクチャのアップグレードとトレーニングデータの拡張により、主に実測データのある流域における性能が向上しました。GraphCastによる効果は、中長期予測においてより顕著であり、実測データのあるシナリオと実測データのないシナリオの両方で改善が見られました。KGEの分解結果からも、この改善は主に流出量の時間的変動と流量変動を特徴付ける能力の向上によるものであることが示されています。
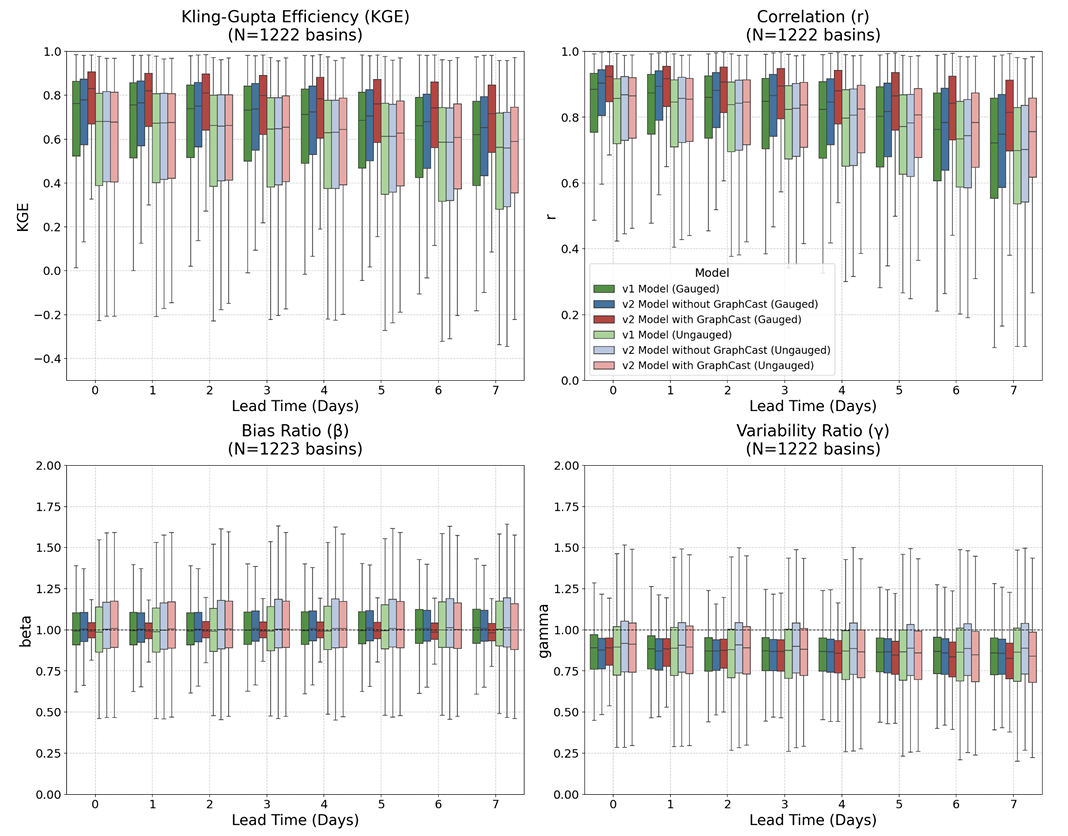
典型的な結果として、測定データが利用可能な流域では、6日目のv2の予測精度はv1のリアルタイム予測レベルに達するか、あるいはそれを上回る可能性があります。一方、測定データのない流域では、予測リードタイムはわずかに延長されるだけです。これはまた、...ローカルな観測データは、モデルの性能に影響を与える重要な要素であり続ける。
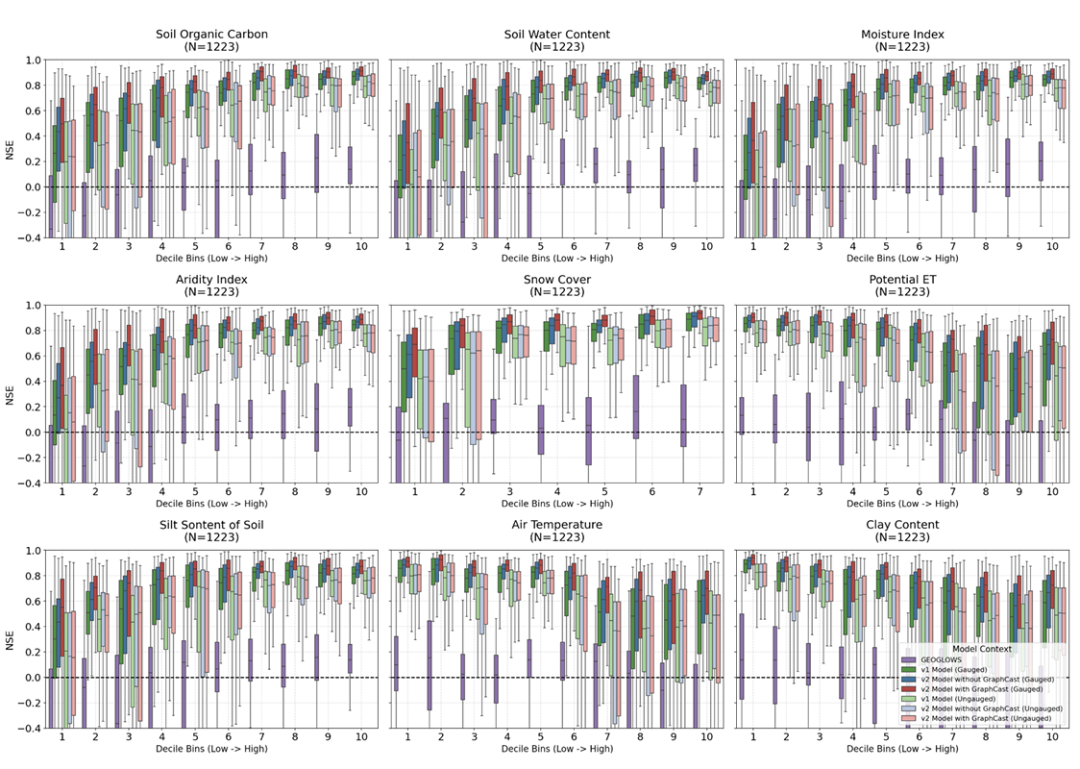
この研究では、流域の自然特性が予測精度に大きく影響することも明らかになった。一般的に、湿度が高く、積雪量が多く、植生が良好な流域では、より安定した予測が得られる傾向がある一方、乾燥地域では、流出量の急激な変動により、より大きな誤差が生じることが多い。しかし、測定データに基づくと…v2の改善は、乾燥した流域でより顕著である。対照的に、多数の貯水池や人工的な制御施設が存在する流域では、モデルの改良後も改善が限定的であったことから、現在の深層学習モデルは、複雑な人間が制御するプロセスを特徴づけるには依然として不十分であることが示された。
最後に書きます
モデル開発や運用展開からデータやコードのオープンソース化に至るまで、v2システムは機械学習を用いた水文モデリングの分野におけるますます明確な傾向を反映しています。研究目標はもはや「精度を数パーセント向上させる」だけではなく、現実の複雑な環境におけるモデルの安定性、汎化能力、拡張性に重点を置くようになっています。もちろん、現在のシステムにもまだ大きな制約があります。乾燥した流域、人為的に規制された地域、実際の観測所がないシナリオは、世界の洪水予測における課題であり、モデルがローカルな観測データに依存しているという問題は、まだ完全には解消されていません。
本研究は少なくとも一つの点を実証している。すなわち、高品質な訓練データ、グローバル規模の多源気象情報、そして運用シナリオ向けに設計された深層学習アーキテクチャを組み合わせることで、機械学習は真にグローバルな洪水予測システムを支えることができるということである。これは、将来の洪水対策と災害軽減、水資源配分、そして異常気象リスク管理にとって、間違いなく重要かつ注目すべき進展である。








