Command Palette
Search for a command to run...
フランスの研究チームは、11,647件の臨床データに基づき、機械学習を用いてHCC肝移植における二重死亡リスクの正確な予測を初めて達成した。
肝がんは、その初期段階の進行の悪さと急速さから、古くから「がんの王様」と呼ばれてきました。中でも肝細胞がん(HCC)は最も一般的な肝がんであり、原発性肝がんの70%~90%を占めています。早期段階では、根治的治療として肝移植が必要となる場合が多く、多くのHCC患者にとって、生命の希望を掴む最後の「命綱」ともなっています。
しかし、ドナー臓器の極度の不足により、この生命への希望はますます貴重になっています。さらに困難なのは、肝細胞癌(HCC)肝移植候補者が、肝不全と腫瘍の進行による死亡という二重の脅威に常に直面しているという事実です。この二つの要因は相互に影響し合い、待機期間中の死亡リスクを大幅に高めます。そのため、HCC肝移植候補者の待機期間中の死亡リスクを正確に評価することは、肝移植待機リストの優先順位を最適化し、希少なドナーの公平な割り当てを達成するための鍵となるだけでなく、すべての患者を効率的に救い、苦労して勝ち取った生きる希望を守るための中核的な課題でもあります。
これまで、Child-Pugh法、アルブミン・ビリルビン値(ALBI)、末期肝疾患モデル(MELD)といった従来のリスク評価法が、肝疾患リスク評価に広く用いられてきました。しかし、肝細胞癌患者の複雑な状況においては、これらの方法は重大な欠陥を示しました。これらの方法は、肝機能と肝硬変の程度の評価に重点を置くか、腫瘍の進行予測のみに焦点を当てており、両方のリスクを同時に考慮することができませんでした。その後、HALT-HCCやMehtaモデルといった、両方のリスクを同時に考慮できる包括的なスコアリングシステムが開発されましたが、それでもなお、肝細胞癌のリスク評価は依然として不十分です。また、線形モデル、固定変数の重み、および単一時点での静的測定の制限により、影響要因と疾患の動的進行におけるリスク変化との相互作用を捉えることは不可能であり、正確な個別リスク評価を達成することは困難です。
この臨床上の問題点に対応するために、フランスのTelecom Sud-Parisとパリ・サクレー大学の研究チームは、アンサンブル学習(EL)とSchapel Additive exPlanations(SHAP)分析を統合した機械学習フレームワークを提案した。本研究は、肝細胞癌(HCC)肝移植候補者における死亡リスク評価への新たなアプローチを提示する。11,647人の患者の臨床データに基づき、ランダムフォレスト(RF)、XGBoost、LightGBMの3つのアンサンブルモデルを比較した。さらに、SHAP値をUniform Manifold approximation and Projection(UMAP)低次元空間に埋め込み、教師ありクラスタリングのためのK-medoidsアルゴリズムと組み合わせることで、肝機能障害と腫瘍の進行がHCC患者の死亡における2つの主要なリスクであることを明らかにした。
この研究は、特に二重リスクを伴う研究において、HCC 肝移植候補者を正確に評価するための従来の機械学習モデルのギャップを埋めるものです。この研究は、HCC 肝移植候補者の 3 か月の待機期間中の死亡率の正確な予測と臨床的解釈を実現し、肝移植を受ける HCC 患者の臨床的意思決定とリスク層別化のための新しいツールを提供します。
「肝細胞癌の肝移植候補者の説明可能な死亡率予測:教師ありクラスタリングアプローチ」と題された研究結果は、Health Data Science 誌に掲載されました。
研究のハイライト:
* この研究は、機械学習モデルを使用して、待機リストにあるHCC肝移植候補者の死亡リスクを詳細に分析した初の包括的な研究です。
* SHAP + UMAP + K-medoids を使用することで、臨床的に説明可能な 7 つのリスク サブグループが層別化され、二重リスクの中核要因が特定されました。
* 8 つの主要変数の SHAP スクリーニングに基づいて構築された新しいリスク スコア ELM-HCC は、従来のスコアと比較して大幅に優れた予測精度を示しています。
* この研究は、HCC 肝移植候補者のリスク評価に主要な動的変数 (AFP_DIFF など) を組み込んだ初めての研究であり、HCC 患者の待機期間中の死亡率の主要な予測因子としての役割を明らかにしています。
用紙のアドレス:
https://spj.science.org/doi/10.34133/hds.0295
完全な PDF を取得するには、当社の公式 WeChat アカウントをフォローし、バックグラウンドで「肝臓移植」と返信してください。
最先端の AI 論文をもっと見る:
データセット: 大規模サンプル戦略 + 動的変数導入
交絡因子を減らすために、この研究では、公開データベースデータに基づいた大規模サンプル戦略を採用しました。
具体的には、研究データは臓器提供・移植ネットワーク(OPTN)と全米臓器分配ネットワーク(UNOS)の標準移植分析・研究(STAR)ファイルから取得され、2002年2月27日から2023年9月30日の間に登録され、複数の臓器移植を受けていない成人HCC患者を対象としている。
この研究は、肝細胞癌患者における肝移植までの3ヶ月間の待機期間中の死亡率を予測することを目的としていました。そのため、研究チームは研究対象集団を2つのグループに分けて解析を行いました。3 か月を超えて待機リストに登録されている患者は「待機リスト登録患者」と呼ばれ、3 か月以内に待機リストに登録されたまま死亡した患者、または病状が悪化して移植を受けられなくなった患者は「待機リスト登録死亡者」と呼ばれます。ファイナル、研究対象コホートには合計 11,647 人の患者が含まれていました。このうち11,199人が待機リストに登録されており、448人が死亡待機リストに登録されていました。データには、臨床、検査、および疾患関連の多次元変数が含まれていました。
データ前処理段階では、患者の健康状態の動的な特徴を捉えるために、研究チームは、血清ナトリウム、クレアチニン、アルブミン、ビリルビン、アルファフェトプロテイン(AFP)、国際標準化比(INR)など、従来のスコアリングに関係する6つの主要な臨床検査変数の連続測定差(DIFF)を計算し、患者の健康状態の変化の動的な軌跡を捉えました。これにより、機能の合計数は 31 に増加します (元の静的変数 25 個 + 新しく追加された動的変数 6 個)。
欠損値の処理については、数値変数(欠損率<7%)はクラス平均を使用して補完され、カテゴリ変数(欠損率<0.1%)は欠損値を含む観測レコードが直接削除されました。
モデルアーキテクチャ:エンドツーエンドの統合プロセス + 複数のアンサンブル学習モデルの比較
肝細胞癌肝移植候補者の3ヶ月の待機期間中の死亡率予測の信頼性のある正確性と解釈可能性を確保するために、研究チームは、アンサンブル学習、SHAP 解釈可能性分析、UMAP 次元削減、K-Medoids 教師ありクラスタリングを組み合わせたエンドツーエンドの統合プロセスを構築しました。以下に示すように:
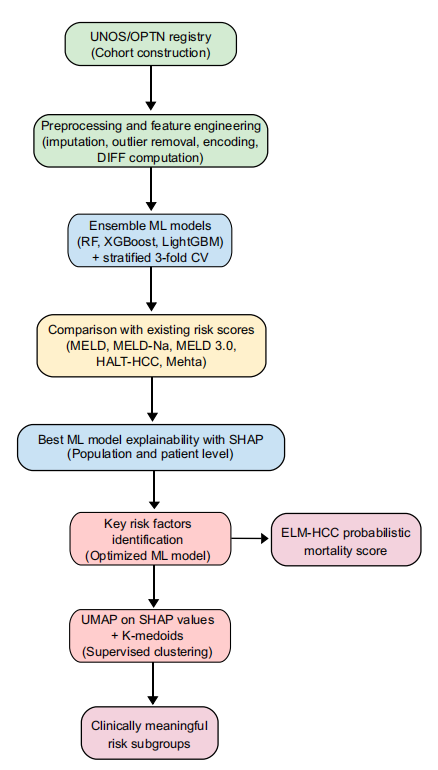
まず、コア モデルでは、アンサンブル学習ツリー モデルが採用されています。これらのタイプのモデルは、表形式データや異種データの処理に特に効果的です。これらのモデルの性能をさらに比較するために、本研究では3つの基本的なアンサンブル学習モデル(ランダムフォレスト、XGBoost、LightGBM)を使用しました。実験は2つの学習シナリオで実施されました。1つ目のシナリオでは、元の静的変数を25個のみ使用し、2つ目のシナリオでは、動的変数を含む静的変数と動的変数を組み合わせた31個の変数を使用しました。
第二に、解釈可能性の目的は、予測された結果の科学的かつ合理的な解釈を提供し、それによって臨床上の意思決定の基盤を強化することです。この目的のために、研究チームは、主要なリスク要因を特定し、モデル予測を明らかにするフレームワークに SHAP 解釈可能性分析を組み込みました。
全体的解釈においては、SHAP値を計算すると、各特徴量のモデルの予測結果への寄与度が定量化され、死亡予測における中核リスク因子が特定され、特徴量と死亡リスクの相関関係が明確になります。局所的解釈においては、SHAPサマリープロットとSHAPフォースプロットを用いることで、個々の特徴量が予測結果に及ぼす具体的な影響や、各患者における特徴量の寄与分布を示すことができます。さらに、このステップにより、後続のクラスター分析のためのSHAP値特徴量セットが提供され、元のデータが置き換えられることで、クラスタリングの臨床的解釈性が向上します。
最後に、患者のリスク層別化を精密化するために、焦点は集団レベルの予測からサブグループ固有の分析に移りました。研究プロセスには、UMAP 次元削減と K-Medoids 教師ありクラスタリング手法が組み込まれました。まず、予測されたSHAP値をUMAP次元削減空間に埋め込みます。次に、K-Medoidsアルゴリズムを用いて、3D UMAP空間に埋め込まれたSHAP値をクラスタリングし、異なる臨床特性を持つ潜在的な患者サブグループを発見します。この手法は、元のデータではなくSHAP値に基づいてクラスタリングを行うため、「教師ありクラスタリング」と呼ばれます。
最適なクラスター数は、まずシルエット係数やデイヴィス・ボールディン指数などの定量的指標を用いてスクリーニングを行い、次にSHAP分析によってクラスタリング特性を臨床的に検証することで決定されました。最終的に、最適なクラスター数は7と決定されました。
実験結果: 新しいモデルは、比較として 8 つの従来の評価方法と最適な機能セットを使用してトレーニングされました。
リスクスコアのパフォーマンス比較
この研究では、提案されたフレームワークのパフォーマンスを、ALBI、Child–Pugh、AFP、HCC の LT に関連するハザード (HALT-HCC)、Mehta モデル、MELD とその 2 つのバリエーションである MELD-Na と MELD 3.0 を含む 8 つの従来のリスク評価方法と比較しています。
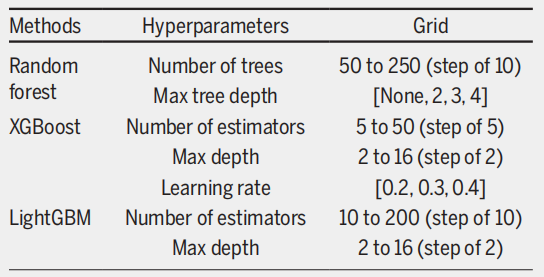
データセットにおける深刻なクラス不均衡を考慮し、本研究では多数派グループ(待機リスト登録者)をダウンサンプリングし、少数派グループ(待機期間中の死亡者)と同程度のサイズのサブセットを30個生成しました。各バランスの取れたサブセットに対して3分割交差検証を実施し、同一患者からのすべての観測値がトレーニングセットまたはテストセットのいずれかに割り当てられるようにしました。その後、グリッドサーチを用いて、3つのアンサンブルモデルの最適なハイパーパラメータ設定を決定しました(下図参照)。
結果は次のようになります。従来のスコアリング システムでは、Mehta モデルが AUROC 0.782 で最も優れたパフォーマンスを示し、次に HALT-HCC が AUROC 0.763 で続きます。さらに重要なのは、これら2つのモデルは感度と特異度の点でよりバランスの取れたパフォーマンスを提供していることです。MELD 3.0は基本的なMELDモデルおよびMELD-Naモデルよりも優れた性能を発揮しますが、感度と特異度のバランスが崩れています。
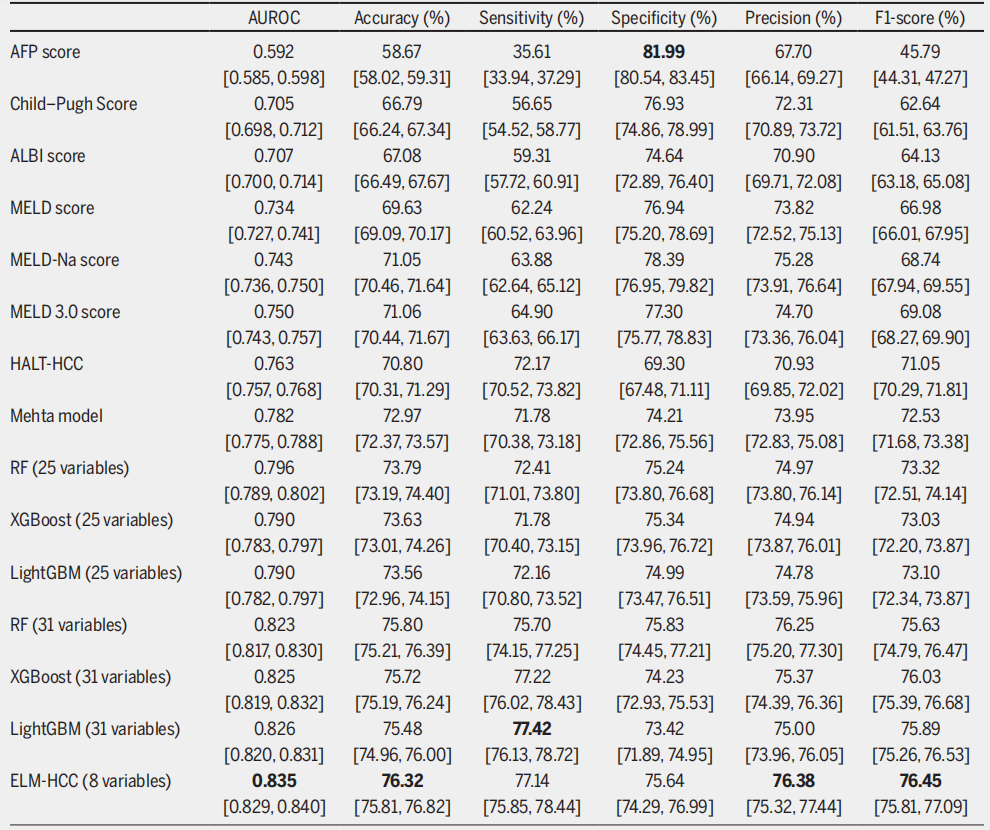
実験をアンサンブル学習フレームワークに拡張したところ、25個の静的変数で学習した全てのモデルの精度が従来のスコアリングシステムを上回りました。RFはAUROCが0.796で最も高いパフォーマンスを示し、感度72.41%、特異度75.24%とバランスが取れていました。動的変数と静的変数を組み合わせた31個の変数を導入した後、全てのアンサンブル学習モデルはさらに優れたパフォーマンスを達成しました。LightGBM は AUROC 0.826 と最高感度 77.42% を達成し、高リスク患者を特定するための最も効果的なモデルとなりました。
主要なリスク要因を特定する能力の分析
モデルの学習後、最も関連性の高い特徴量のみを用いてパフォーマンスを評価します。この目的のため、研究チームはゲイン重要度とSHAPグローバル重要度という2つの特徴量重要度評価手法を用いて、最もパフォーマンスの高いLightGBMモデルの主要な特徴量を選別しました。
LightGBM モデル (最高のパフォーマンスを誇るモデル) に基づいて、SHAP グローバル重要度を使用して選択された上位 8 つの特徴により、最適なモデル パフォーマンスが実現されます。AUROCは0.835、感度は77.141 TP3T、特異度は75.641 TP3Tであり、ゲイン重要度スクリーニングの結果(8つの特徴量でAUROCは0.812、12の特徴量で最高値の0.828)を上回っただけでなく、31変数の完全なセットにおいてLightGBM(AUROCは0.826)のパフォーマンスも上回りました。そのため、研究チームはこれを最適な特徴量セットとして選択しました。
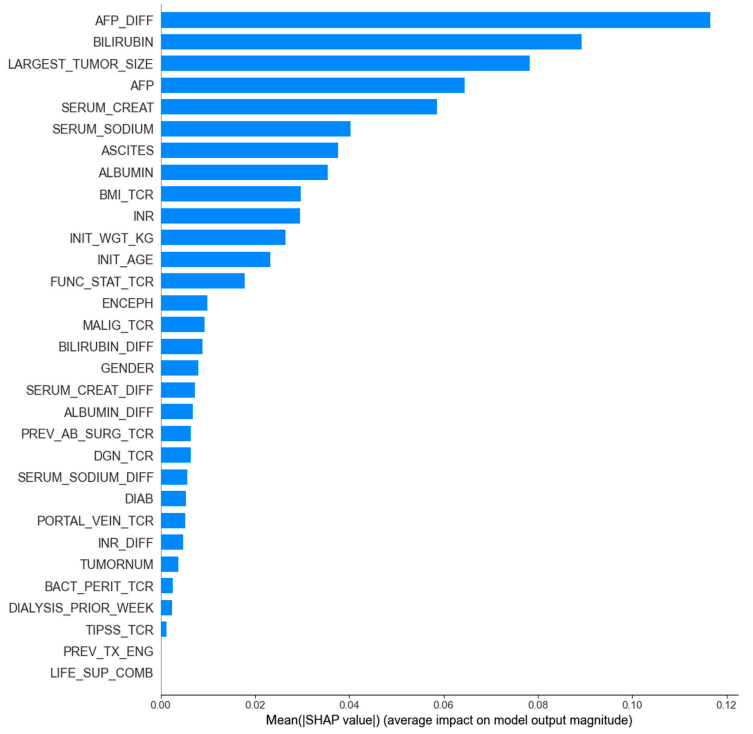
最終的に、本研究では、最適な特徴セットで学習されたLightGBMモデルに基づき、肝細胞癌患者の確率的死亡スコア(ELM-HCC)を特定し、構築しました。特筆すべき点は…LightGBM は、完全な 31 変数セットと比較して、簡素化された変数セットで AUROC を上回り、選択された 8 つの変数の予測力がより強力であることが実証されました。一方、主要な関連特徴における AFP_DIFF の出現は、動的情報を組み込むことの重要性も強調しています。
リスク層別化とサブグループ分析
この研究では、SHAP値を用いた教師ありクラスタリングに基づき、臨床的特徴とリスクレベルの異なる7つの患者サブグループを特定しました。下の図Bは、クラスター1からクラスター7にかけて死亡確率が徐々に増加する層別死亡率分析を明確に示しています。
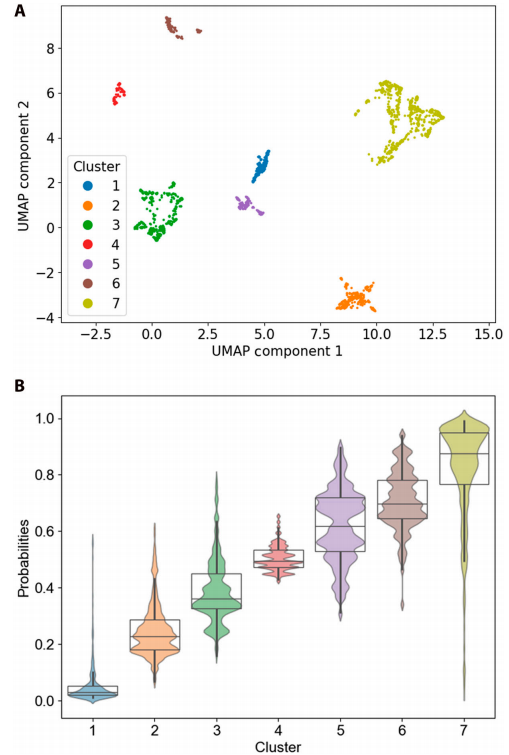
B は、クラスター化された 7 つの観測値の死亡確率のボックス プロットと母集団プロットを表します。
クラスカル・ワリス検定に基づくさらなる分析により、異なるクラスター間で変数に差異があることが明らかになりました。SHAPプロットに示されているように、死亡確率はクラスター1からクラスター7にかけて徐々に増加しました。例えば、代表的な患者の死亡確率は0.03から0.98に増加しました。この傾向はボックス プロットで観察されたランキングと一致しており、クラスタリング手法の有効性を強調しています。
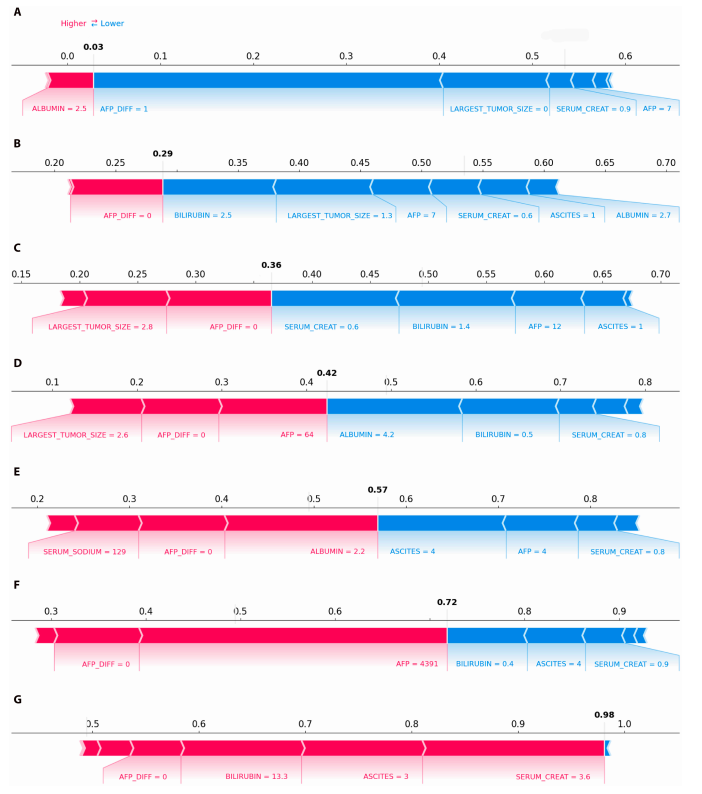
さらに、サブグループ解析により、死亡リスクが高い主な原因が 2 つあることが明らかになりました。重度の肝不全 (高ビリルビン、高クレアチニン、中等度の腹水が特徴で、これらはすべて陽性の SHAP 値に相当し、死亡リスクを大幅に高めます) と活発な腫瘍の進行 (高 AFP レベルが特徴) です。
要約すると、本研究で提案されたLightGBMとSHAP解釈可能性分析に基づくELM-HCC機械学習フレームワークは、HCC肝移植候補者の3ヶ月間の待機期間中の死亡リスク予測において、従来のスコアリングシステムよりも大幅に優れた性能を示した。同時に、教師ありクラスタリングによって異なるリスク特性を持つ患者サブグループを明らかにし、臨床意思決定のためのより正確で解釈可能なリスク評価ツールを提供する。
肝移植候補者のリスク評価のための革新的な方法。包括的なアプローチにより研究のギャップを埋めます。
前述の通り、肝がんは世界的な公衆衛生上の課題となりつつあります。ますます深刻化する疾患課題と医療ニーズの高まりに直面している今、肝移植候補者リストに関する科学的に妥当かつ合理的な計画は極めて重要です。2002年には既に、末期肝疾患モデル(MELD)が肝移植候補者の優先順位付けに用いられていました。しかし、幾度かの改訂を経ても、MELDの割り当ては依然としてすべての候補者を公平に満足させるには至っていません。
高次元かつマルチモーダルなデータを処理できる機械学習は、現在、臓器移植候補者の死亡リスクを予測するための最良のソリューションとなっています。
機械学習モデルは、これまでにも肝移植死亡率の予測に応用されてきました。例えば、MIT、カリフォルニア大学サンフランシスコ校、テキサス大学の共同チームは、最適分類木(OCT)に基づく死亡率最適化予測モデルであるOPOMを提案しました。この肝臓割り当てモデルに基づくと、MELD モデルと比較して年間の死亡数を約 418 人削減でき、すべての UNOS 地域および疾患重症度レベルにわたって死亡数/除去数が大幅に減少します。さらに、このモデルは、肝細胞癌患者と非肝細胞癌患者に割り当てられる肝臓の数も調整し、肝移植の割り当てを大幅に最適化し、候補者の死亡率を低下させました。
論文タイトル: 肝移植を待つ患者の死亡率の最適化予測の開発と検証
用紙のアドレス:
https://www.sciencedirect.com/science/article/pii/S1600613522090335
しかし、OPOMモデルは良好な成績を示したものの、肝細胞癌患者と非肝細胞癌患者の混合コホートに基づいており、肝細胞癌患者が直面する肝不全と腫瘍進行という二重のリスクに具体的に対処していません。ELM-HCCは間違いなくこのギャップを埋めるものです。
最後に、本研究は先行研究を改良・拡張するだけでなく、著者らが述べているように、既存の研究のギャップを埋めるものである点がさらに重要です。肝細胞癌(HCC)肝移植候補者の3ヶ月の待機期間中の死亡率を、初めて解釈可能かつ正確に予測することに成功したことで、臓器移植候補者のリスク評価と機械学習を組み合わせた新たなアプローチを提供します。
参考文献:
1. フランスのテレコム・シュド・パリとパリ・サクレー大学の研究チームは、アンサンブル学習とSHAple Additive exPlanations(SHAP)分析を統合した機械学習フレームワークを提案し、HCC肝移植候補者の死亡リスクを評価するための新たなソリューションを提供している。
2.https://www.sciencedirect.com/science/article/pii/S1600613522090335








