Command Palette
Search for a command to run...
Heterogeneous Scientific Foundation Model Collaboration
Heterogeneous Scientific Foundation Model Collaboration
Zihao Li Jiaru Zou Feihao Fang Xuying Ning Mengting Ai Tianxin Wei Sirui Chen Xiyuan Yang Jingrui He
Abstract
Agentic large language model systems have demonstrated strong capabilities. However, their reliance on language as the universal interface fundamentally limits their applicability to many real-world problems, especially in scientific domains where domain-specific foundation models have been developed to address specialized tasks beyond natural language. In this work, we introduce Eywa, a heterogeneous agentic framework designed to extend language-centric systems to a broader class of scientific foundation models. The key idea of Eywa is to augment domain-specific foundation models with a language-model-based reasoning interface, enabling language models to guide inference over non-linguistic data modalities. This design allows predictive foundation models, which are typically optimized for specialized data and tasks, to participate in higher-level reasoning and decision-making processes within agentic systems. Eywa can serve as a drop-in replacement for a single-agent pipeline (EywaAgent) or be integrated into existing multi-agent systems by replacing traditional agents with specialized agents (EywaMAS). We further investigate a planning-based orchestration framework in which a planner dynamically coordinates traditional agents and Eywa agents to solve complex tasks across heterogeneous data modalities (EywaOrchestra). We evaluate Eywa across a diverse set of scientific domains spanning physical, life, and social sciences. Experimental results demonstrate that Eywa improves performance on tasks involving structured and domain-specific data, while reducing reliance on language-based reasoning through effective collaboration with specialized foundation models.
One-sentence Summary
This work introduces Eywa, a heterogeneous agentic framework that extends language-centric systems to a broader class of scientific foundation models by augmenting domain-specific models with a language-model-based reasoning interface, enabling predictive foundation models to participate in higher-level reasoning and decision-making across physical, life, and social sciences while improving performance on structured and domain-specific data and reducing reliance on language-based reasoning.
Key Contributions
- The paper introduces Eywa, a heterogeneous agentic framework that augments domain-specific foundation models with a language-model-based reasoning interface to enable inference over non-linguistic data modalities. This design allows predictive foundation models optimized for specialized tasks to participate in higher-level reasoning and decision-making processes within agentic systems.
- The framework functions as a drop-in replacement for single-agent pipelines via EywaAgent or integrates into existing multi-agent systems as EywaMAS. A planning-based orchestration framework named EywaOrchestra dynamically coordinates traditional agents and Eywa agents to solve complex tasks across heterogeneous data modalities.
- Experimental results demonstrate that Eywa improves performance on tasks involving structured and domain-specific data across physical, life, and social sciences. The evaluation confirms reduced reliance on language-based reasoning through effective collaboration with specialized foundation models.
Introduction
Agentic large language model systems excel at reasoning but rely heavily on natural language, which limits their effectiveness in scientific domains requiring structured or non-linguistic data. While domain-specific foundation models exist for tasks like protein folding or weather forecasting, they typically lack native language interfaces, hindering their direct integration into agentic workflows. The authors introduce Eywa, a heterogeneous framework that augments these specialized models with language-based reasoning interfaces to enable modality-native collaboration across single-agent, multi-agent, and orchestration modes. Experiments across physical, life, and social sciences demonstrate that Eywa improves task utility while reducing token consumption compared to language-only baselines.
Dataset
Dataset Composition and Sources
- The authors construct EywaBench from four primary datasets: DeepPrinciple, MMLU-Pro, fev-bench, and TabArena.
- These sources cover three modalities including natural language, time series, and tabular data.
- The taxonomy spans three parent domains (physical, life, and social science) and nine sub-domains.
- Underlying the four main benchmarks are 67 distinct source datasets to ensure high diversity and avoid domain collapse.
Subset Details and Coverage
- The released EywaBench-V1 split contains 200 task instances selected for balanced coverage.
- DeepPrinciple contributes 1,125 questions across chemistry, materials, biology, and physics.
- MMLU-Pro provides 6,978 scientific questions converted from multiple-choice to open-ended formats.
- fev-bench includes 96 time-series datasets with up to 30,000 covariate series each.
- TabArena offers 51 tabular datasets for classification and regression tasks with up to 150,000 rows.
- Domain distribution is near-uniform with physical, life, and social sciences represented at 32.0%, 30.0%, and 38.0% respectively.
- Modality distribution covers natural language, time series, and tabular data at 41.0%, 39.0%, and 20.0% respectively.
Data Usage and Evaluation
- The benchmark is used exclusively for evaluation rather than model training.
- The 200-sample subset allows for manual configuration and validation of agentic systems without prohibitive cost.
- Performance is measured using a unified utility score between 0 and 1 for all modalities.
- Results are aggregated as unweighted means per domain and across all tasks.
- The pipeline is parametric and scalable, allowing for additional instances via resampling without changing the schema.
Processing and Metadata Construction
- Data is stored as a dictionary-encoded Parquet file with Snappy compression.
- Financial time series inputs undergo timestamp anonymization to prevent model memorization of historical trends.
- MMLU-Pro questions are reformatted to require direct open-ended answers instead of multiple-choice selection.
- Time series and tabular tasks support scalable instance generation by sampling different windows or data subsets.
- Metrics include soft-match scores for text and normalized error combinations (sMAPE and MAAPE) for numerical predictions.
Method
The Eywa framework addresses the inherent trade-offs between Large Language Models (LLMs) and Domain-Specific Foundation Models (FMs). While LLMs possess strong general-purpose reasoning capabilities, they often lack the specialized knowledge required for scientific or domain-specific tasks. Conversely, FMs provide faithful domain-specific computation but typically lack a native language interface. The authors propose a unified architecture that integrates these components through a modular design. Refer to the framework diagram below, which illustrates the conceptual analogy drawn from the Avatar universe and its technical realization within the Hugging Face ecosystem.
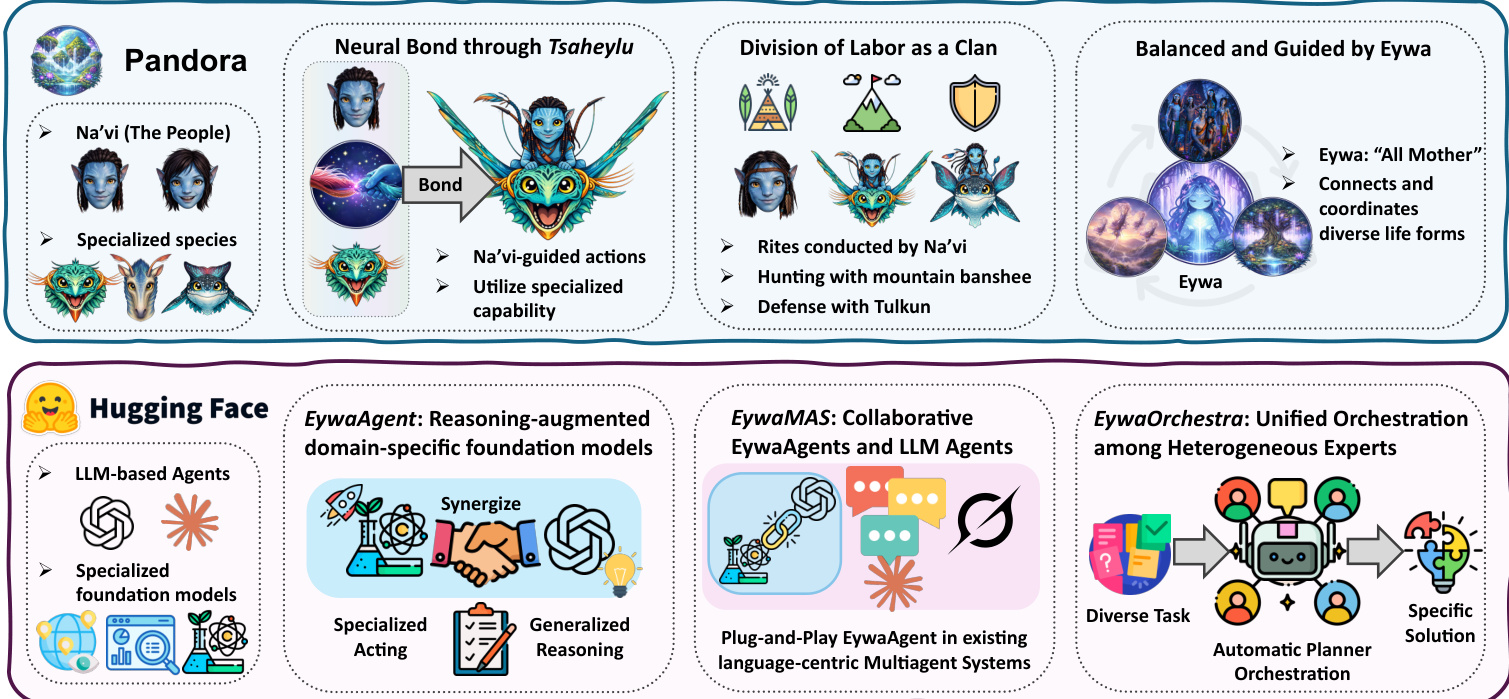
The architecture is organized into three hierarchical levels. The top level conceptualizes the relationship between Na'vi (representing LLM agents) and specialized species (representing FMs) connected via a neural bond. The bottom level translates this into three technical modules: EywaAgent for reasoning-augmented domain models, EywaMAS for collaborative multi-agent systems, and EywaOrchestra for unified orchestration among heterogeneous experts.
The core unit of this framework is the EywaAgent, which augments a foundation model with a language-based reasoning interface. The mechanism enabling this integration is the "Tsaheylu" bond, designed to establish a robust communication channel between the language model and the specialist foundation model. As shown in the figure below, this interface ensures that the LLM can correctly configure the control input conditioned on the task state while delegating specialized computation to the foundation model.
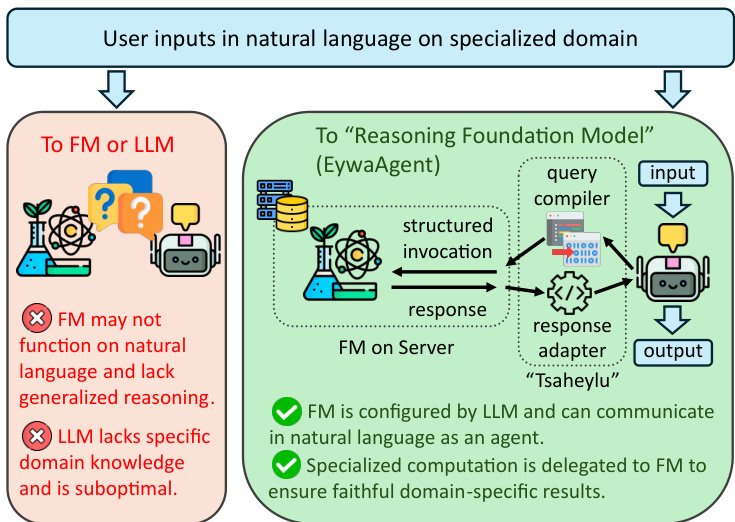
Formally, the Tsaheylu interface is defined as a bidirectional communication pair (ϕk,ψk) for a domain k. The query compiler ϕk translates the task state from the LLM into a structured FM invocation, while the response adapter ψk converts the specialist output into a planner-consumable representation. This pipeline allows the system to dynamically decide whether to invoke the foundation model based on task requirements, effectively subsuming language-only agents as a special case while strictly expanding the class of computable functions.
Building upon the single-agent unit, the framework extends to multi-agent settings to enable complex and heterogeneous collaborations. EywaMAS generalizes the EywaAgent to a distributed multi-agent setting, allowing multiple specialized agents to interact. Unlike traditional multi-agent systems that rely solely on language-based agents, EywaMAS enables seamless integration of both language-only agents and EywaAgents within a unified framework. Refer to the comparison diagram below to see how EywaMAS generalizes existing multi-agent topologies.
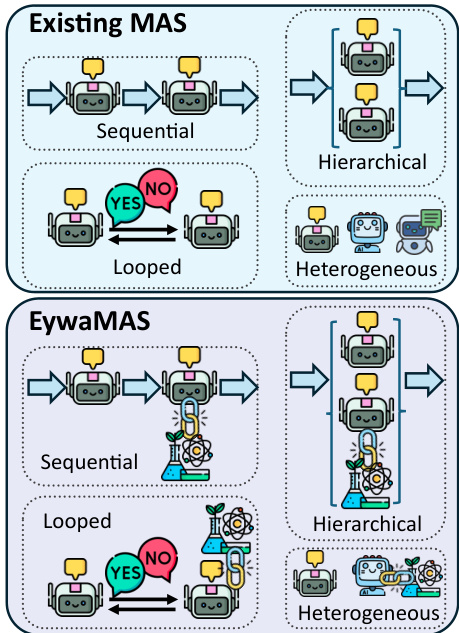
The system supports flexible composition across different language models, different foundation models across domains, and mixed agent types. This plug-and-play property allows domain-specific foundation models to be incorporated into existing agentic systems without redesigning communication protocols. The communication topology G governs the interactions, ensuring that the specialized capabilities of the EywaAgents propagate through the network to solve complex tasks.
To handle the diversity of real-world tasks, the framework introduces EywaOrchestra, a dynamic orchestration mechanism. A conductor, instantiated as a large language model, maps the input task to a system configuration. This involves selecting the role and type of each agent, the backbone language model, the attached foundation model, and the communication topology. To support this heterogeneous interaction, the authors adopt a unified prompt template that specifies the task role, tool context, structured input field, and expected output format. The structure of this general prompt is detailed in the figure below.

The template includes placeholders for task identity, model descriptions, and modality-specific instructions. This design allows different task types to share the same high-level prompting interface while preserving modality-specific instructions through specialized input tags and output constraints. By combining adaptive orchestration with a standardized interface, the framework achieves enhanced expressivity and improved task performance across various scientific domains.
Experiment
Experiments on EywaBench evaluate Eywa variants against single-agent and multi-agent language model baselines across diverse scientific domains. Results demonstrate that integrating domain-specific foundation models significantly enhances utility and efficiency, as language-only agents often fail to perform accurate numerical computations on structured data. Additionally, adaptive orchestration in EywaOrchestra achieves performance comparable to expert-designed systems while reducing costs, confirming that cross-modality heterogeneity is more critical than combining heterogeneous language models alone.
The authors evaluate EywaAgent, EywaMAS, and EywaOrchestra across diverse scientific domains using different LLM backbones. Results demonstrate that integrating domain-specific foundation models significantly enhances utility and efficiency compared to language-only baselines. EywaMAS achieves the strongest overall performance, while EywaOrchestra provides a cost-effective alternative by dynamically adapting the system configuration. EywaMAS achieves the highest overall utility across physical, life, and social science domains compared to single-agent and homogeneous multi-agent baselines. EywaOrchestra matches the performance of the fixed multi-agent system while substantially reducing token consumption and inference latency through dynamic configuration selection. Upgrading the LLM backbone from gpt-4.1-nano to gpt-5-nano yields significant performance improvements, whereas further scaling to gpt-5-mini shows diminishing returns in several sub-domains.
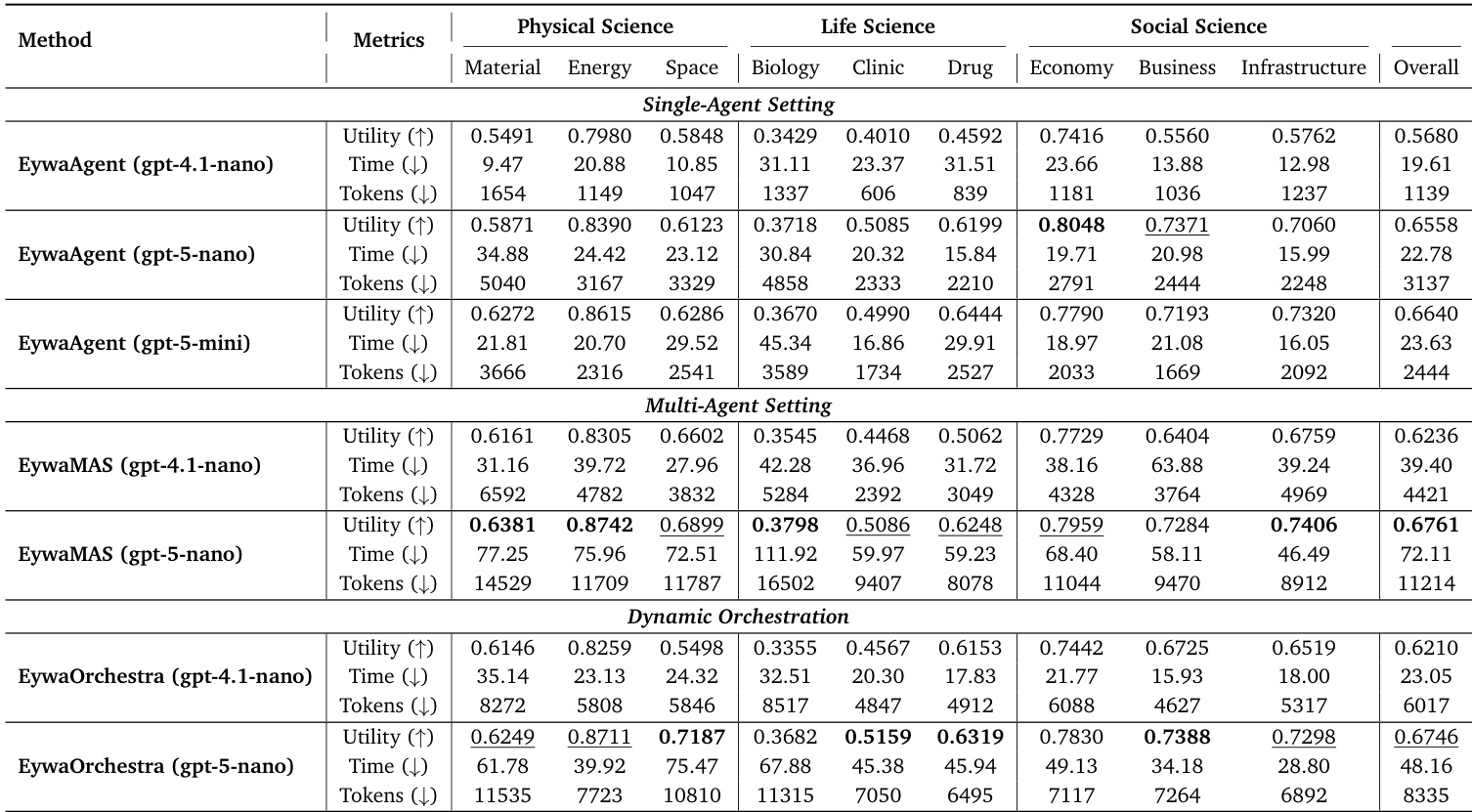
The authors evaluate the EywaAgent system using three distinct LLM backends to analyze the impact of model capability on performance. Results show a clear upward trend in overall utility as the backbone strength increases, with the strongest model achieving the best scores. While the largest model offers the highest utility, it demonstrates a trade-off where token consumption is lower than the mid-tier model but inference time is slightly higher. Increasing the capability of the LLM backbone leads to consistent improvements in overall utility across all scientific domains. The strongest model configuration achieves the highest utility while consuming fewer tokens than the mid-tier configuration. The smallest backbone model is the most efficient in terms of time and token usage but yields the lowest utility.
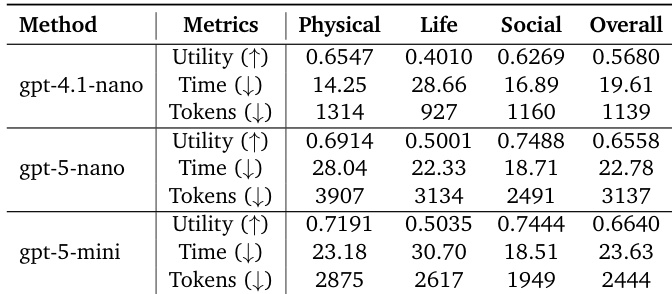
The authors evaluate their proposed methods against various single-agent and multi-agent baselines across scientific domains using a unified protocol. Results demonstrate that integrating domain-specific foundation models significantly improves task utility and computational efficiency compared to language-only approaches. EywaAgent improves average utility and reduces token consumption compared to the single-agent baseline. EywaMAS achieves the highest overall utility while using fewer tokens than other multi-agent baselines. EywaOrchestra reaches utility levels similar to expert-designed systems but with lower latency and token costs.
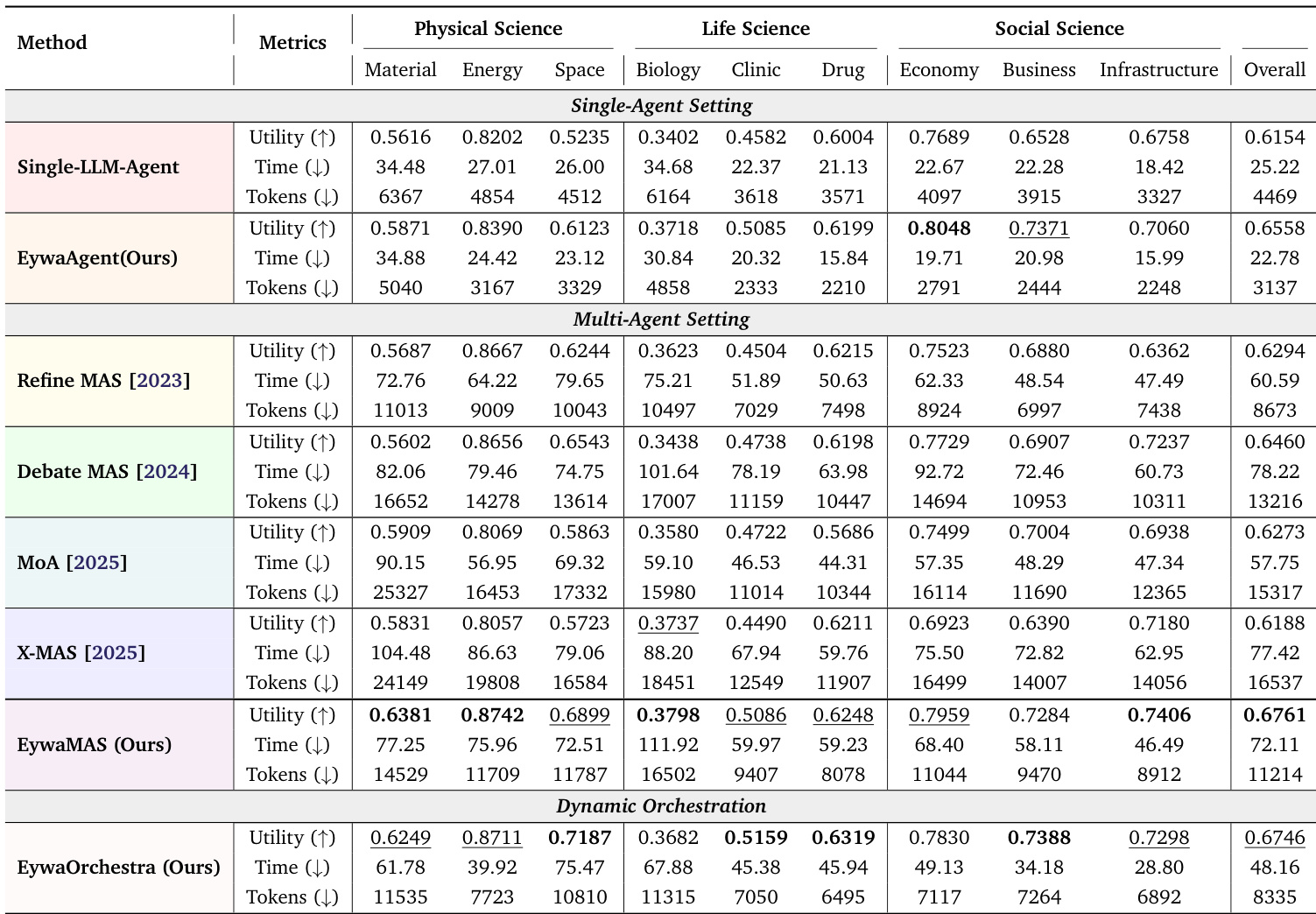
The authors evaluate EywaAgent, EywaMAS, and EywaOrchestra across diverse scientific domains using various LLM backbones to compare performance against single-agent and language-only baselines. Results indicate that integrating domain-specific foundation models significantly enhances utility and efficiency, with EywaMAS achieving the highest overall performance and EywaOrchestra providing a cost-effective alternative through dynamic configuration. Additionally, upgrading the LLM backbone yields significant performance improvements, whereas further scaling shows diminishing returns in several sub-domains.