Command Palette
Search for a command to run...
フランスの研究チームは、239万個の抗ファージタンパク質を正確に予測し、深層学習モデルを用いて細菌の抗ウイルス免疫をマッピングすることに成功した。

微小な世界では、細菌とバクテリオファージの「軍拡競争」は絶えることなく続いています。バクテリオファージは通常、細菌の約10倍の数で、細菌を宿主として増殖します。一方、細菌は長期にわたる進化を経て、非常に多様な抗ウイルス防御システムを発達させてきました。現在、制限修飾系やCRISPR-Casシステムなど、さまざまなメカニズムを含む250以上の抗ファージシステムが実験的に検証されており、新しいシステムが絶えず発見されています。この現象は、細菌の防御システムの複雑さと多様性が現在の理解をはるかに超えている可能性を示唆しています。しかし、従来の実験手法や計算技術の制約により、多数の潜在的な抗ファージ機構が細菌ゲノム内に隠されたままであり、体系的に探索されていない。
既存の研究では、既知の抗ファージ系において、タンパク質配列およびゲノム構造レベルでいくつかの共通の特徴が指摘されている。例えば、特徴的なドメインの繰り返し出現や、「防御島」またはプレファージ領域におけるそれらの分布の濃縮などが挙げられる。これらのパターンは、以下のことを示唆している。これらの共通パターンを特定し活用できれば、ゲノム全体規模で未知の抗ファージシステムを体系的に解明できる可能性がある。
このアプローチに基づき、フランスのパスツール研究所の研究者らは、ファージ耐性の大規模予測のための3つの相補的な深層学習モデルを開発し、微調整した。ALBERT_DFモデルは推論に局所的なゲノムコンテキストのみを使用し、ESM_DFはタンパク質言語モデルを使用してアミノ酸配列を解析し、GeneCLR_DFは配列情報とゲノムコンテキストを統合する。統一ベンチマークテストでは、GeneCLR_DFが最も優れた性能を示し、精度991 TP3T、再現率921 TP3Tを達成した。
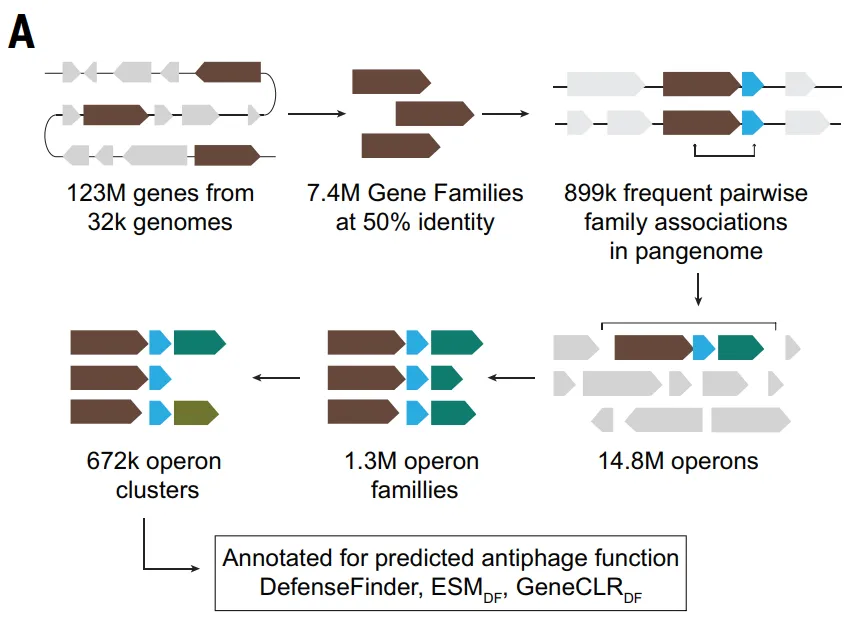
この高精度モデルに基づいて、本研究ではさらに全ゲノム規模の抗ファージシステムの予測を行った。その結果、32,000を超える細菌ゲノムにおいて、典型的な細菌ゲノムでは約1.51個のTP3T遺伝子が抗ウイルス防御に関与していることが示された。さらに重要なことに、予測される防御関連タンパク質ファミリーを表す851個以上のTP3T遺伝子は、これまで免疫機能と関連付けられたことがなかった。最終的に、このモデルは、約239万個の抗ファージタンパク質を予測し、その多くは単一遺伝子防御システムに属しており、遺伝子の共起関係に基づいて約2万3000のオペロンファミリーを定義した。これらの細菌の大部分は、これまで抗ウイルス防御とは無関係と考えられていた。これらの研究結果は、細菌の抗ウイルス免疫の体系的な全体像を描き出し、その規模と多様性が既存の知識をはるかに超えていることを明らかにしている。
「タンパク質およびゲノム言語モデルが細菌免疫の未解明な多様性を明らかにする」と題された関連研究成果は、科学誌『サイエンス』に掲載された。
研究のハイライト:
* 合計239万個の抗ファージタンパク質が予測され、そのうち85%はこれまで免疫機能と関連付けられたことがなかった。
* 一般的な細菌ゲノムでは、約1.51個のTP3T遺伝子が抗ウイルス防御に特異的に関与している。
* 約23,000種類のマニピュレーターのサブファミリーが予測され、その大部分は今回初めて発見されたものである。
* 予測される防御タンパク質の多くは単一遺伝子システムとして存在しており、防御機能は通常複数の遺伝子の協調によって達成されるという従来の考え方に疑問を投げかけている。

用紙のアドレス:
https://www.science.org/doi/10.1126/science.adv8275
弊社の公式WeChatアカウントをフォローし、バックグラウンドで「GeneCLR」と返信すると、PDF全文を入手できます。
データセット:1億2300万個のタンパク質と3万2000個のゲノムに基づく
この研究では、まずDefenseFinderとPadLocツールを利用し、RefSeqデータベースに登録されている32,798個の完全な細菌ゲノムを体系的にスキャンし、既知の抗ファージシステムを定量的に特徴付けた。約1億2300万個のタンパク質のうち、DefenseFinder v1.3は抗ファージシステム構成要素に属する521,360個(TP3Tの0.41)を特定し、PadLocはTP3Tの0.651に相当する805,357個を特定した。
注目すべきは、多くの防御システムが、既知のシステムとのゲノム上の関連性を通じて最初に発見されたことである。これらの関連性は、「防御スコア」を用いてタンパク質ファミリーレベルで定量化することができ、これは特定のタンパク質ファミリーがゲノム内で既知の防御タンパク質と共起する頻度を測定するものである。
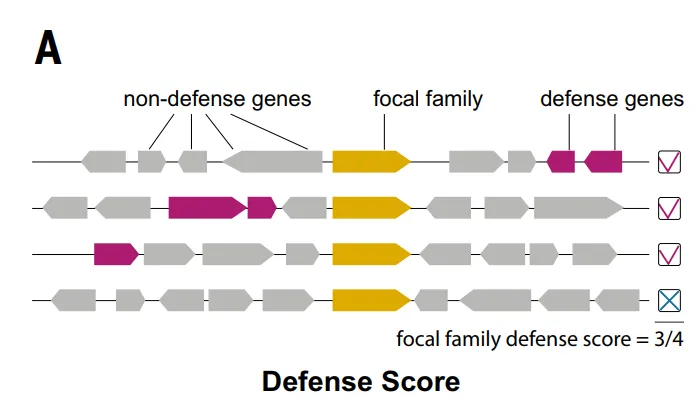
防御スコア方式に基づくと、以下の図に示すとおりです。研究者らは、合計37,959のタンパク質ファミリー(TP3Tの4.61%)を抗ファージ候補ファミリーとして特定した。その後、この研究では、コアとなる生物学的機能や可動遺伝因子に関連するインテグラーゼなどの7,799のファミリーが除外され、最終的に30,160の候補ファミリーが選択されました(TP3Tの3.71を占める)。
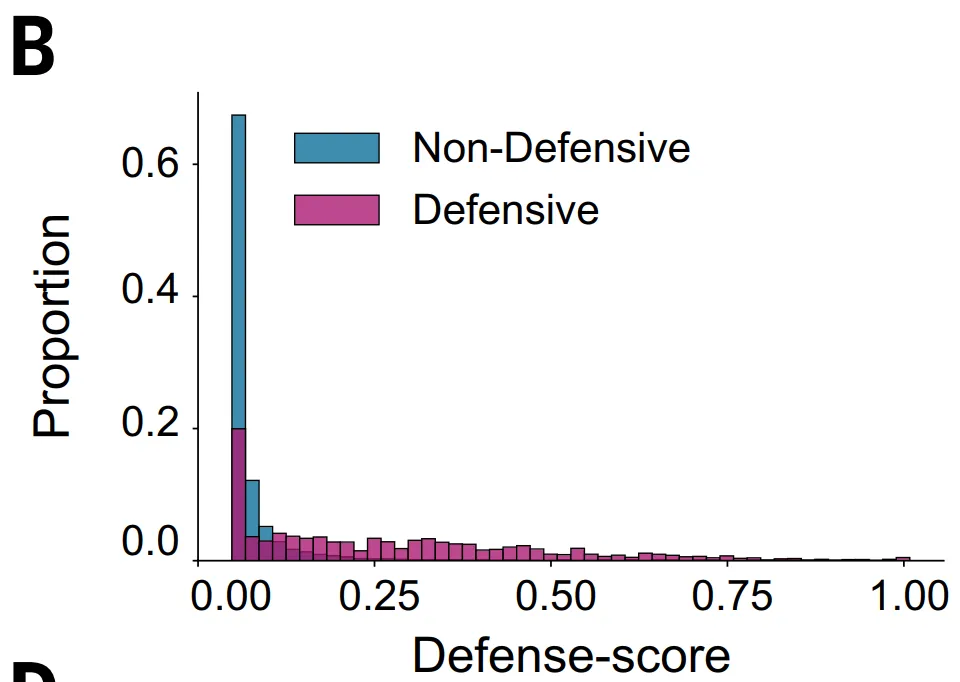
しかし、この方法には明らかな限界がある。まず、これは、5つ以上の相同配列を含むタンパク質ファミリーにのみ適用されるため、約23%のタンパク質は除外されます。第二に、一部の抗ファージシステムは典型的な防御島に位置しておらず、防御機能を持っていたとしても、防御スコアが低いため見過ごされてしまう可能性がある。
上記の制限を克服し、防御関連のゲノムシグナルをより包括的に捉えるために、本研究ではさらに、深層学習に適したデータセットを構築した。ALBERT_DFモデルの枠組みの中で、この研究では細菌ゲノムを「言語的」な方法でモデル化した。つまり、各タンパク質ファミリーを「単語」として、隣接する遺伝子セグメントを「文」として扱った。
完全なデータセットには800万を超える異なるタンパク質ファミリーが含まれており、これは従来の言語モデルの語彙のサイズをはるかに超えているため、この研究では、トレーニング対象を放線菌門に限定し、10,796個のゲノムを含むデータセットを構築した。遺伝子は420万のタンパク質ファミリーに分類されたが、語彙は最も一般的な524,288のファミリーに限定され、約891のTP3Tタンパク質を網羅した。
ESM_DFおよびGeneCLR_DFモデルについては、本研究ではGembase_DFデータセットを構築しました。下図に示すように、DefenseFinderでラベル付けされた521,360個の抗ファージタンパク質を陽性サンプルとして使用し、99%以上に存在する1億1600万個の高度に保存されたコア遺伝子と1400万個の非防御可動遺伝因子遺伝子を陰性サンプルとして使用し、残りのタンパク質はラベル付けされていない候補として保持しました。
トレーニング、検証、テスト間の情報漏洩を防ぐため、本研究では同じ防御システムに属するすべてのタンパク質を同じデータフォールドにグループ化し、MMseqs2を使用してデータフォールド間の残存相同性を除去することで、モデル評価の厳密性を確保した。
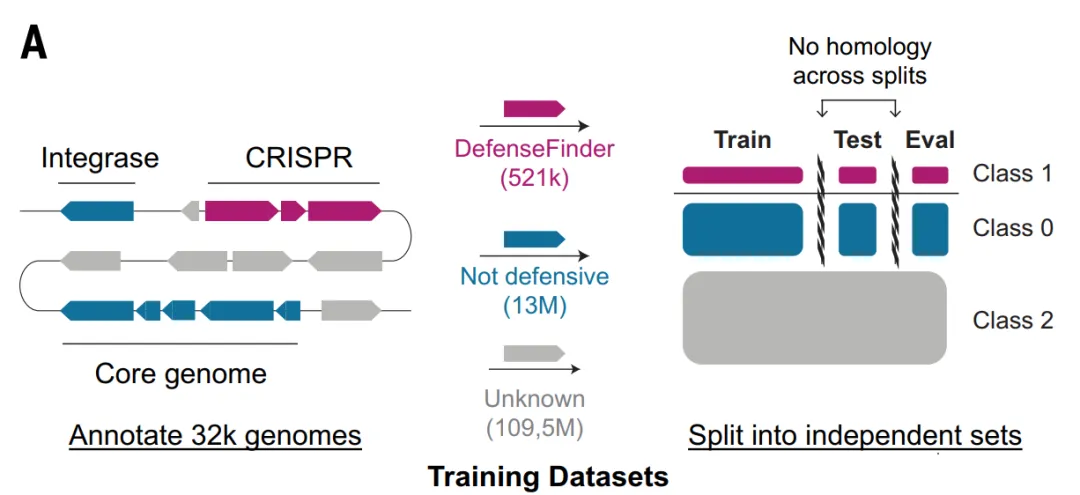
モデルアーキテクチャ:段階的に進行する3層構造の深層学習モデル。
従来の「防御スコア」手法の限界を克服するため、研究チームは、未知のシステムの発見、全ゲノム規模のマイニング、高精度な統合予測という3つの目標を掲げた、補完的かつ先進的な深層学習フレームワークを構築した。具体的には、ゲノムコンテキストに基づくALBERT_DF、タンパク質配列に基づくESM_DF、および配列情報とコンテキスト情報を統合するGeneCLR_DFが含まれます。
中でも、ALBERT_DFは遺伝子の「近隣関係」から機能シグナルを学習することに重点を置いており、新しい防御システムを発見する能力を持っています。ESM_DFはアミノ酸配列モデリングを直接使用し、優れた配列間汎化能力を持っています。一方、GeneCLR_DFは2種類の情報を統一的なフレームワークに統合し、認識精度と予測範囲のより良いバランスを実現しています。
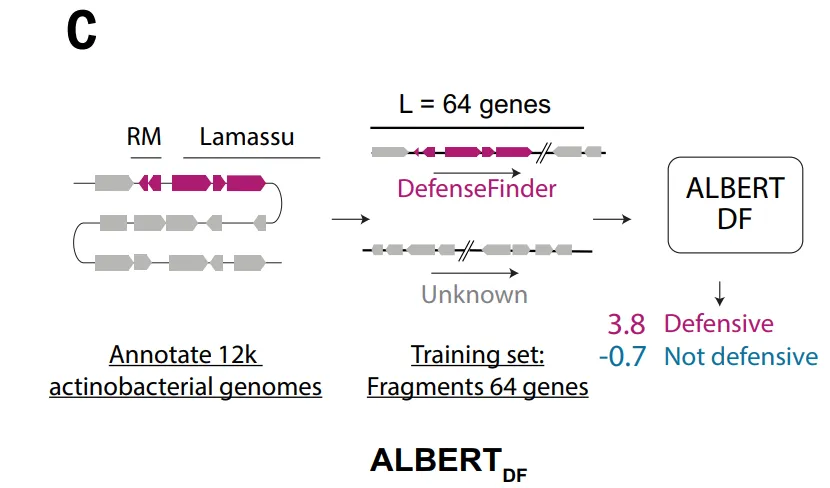
ALBERT_DFモデルは、重要な観察結果に基づいています。抗ファージシステムはゲノム内でクラスター化する傾向があり、隣接する遺伝子内および遺伝子間に安定した組織パターンが存在するということです。この特性に基づいて、本研究は、自然言語処理におけるALBERTアーキテクチャをゲノムモデリングに導入するものである。タンパク質ファミリーを「単語」、遺伝子配列を「構文構造」として扱うことで、マスクされた遺伝子を予測し、局所的な文脈を学習します。
従来の配列類似性に基づく手法とは異なり、このモデリング手法はゲノム構造情報を直接利用するため、既知のシステムとの相同性を持たない新たな防御機構を特定する可能性がより高い。しかし、離散化された「語彙的」表現に依存しているため、この手法は種を超えて適用する際に本質的な限界がある。
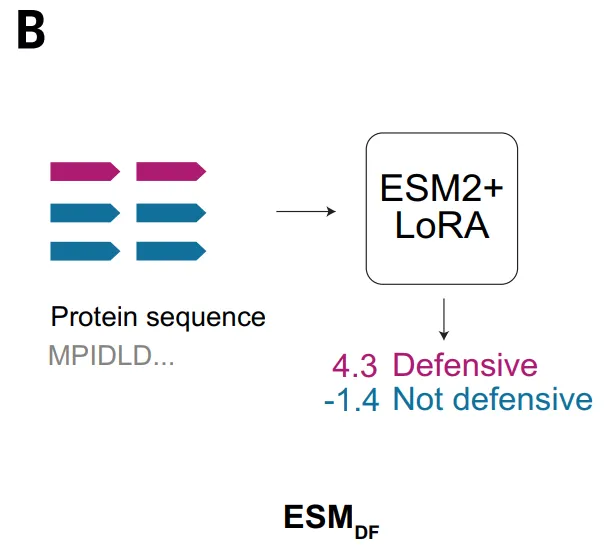
一方、ESM_DFモデルは異なるアプローチを採用し、タンパク質のアミノ酸配列に直接作用する。このモデルは、大規模な事前学習を通して、残基間の共変動と長距離配列関係を学習します。これにより、人工的な特徴に頼ることなく機能的なシグナルを抽出できます。微調整後、ESM_DFはあらゆるタンパク質をスコアリングして、それが抗ファージ防御に関与しているかどうかを判定できます。このアプローチにより、本手法の適用範囲が大幅に向上し、全ゲノム規模での動作が可能になります。しかし同時に、ESM_DFの識別能力は依然として配列類似性にある程度依存しているため、既知の防御システムの遠縁変異体を識別するのに優れており、相同性のない新規ドメインを識別する能力は比較的限られています。
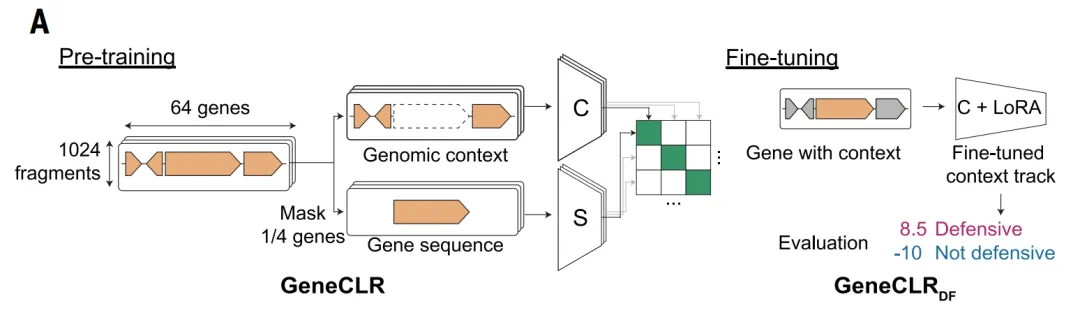
これに基づき、配列情報とゲノムコンテキスト情報を統合するGeneCLR_DFモデルが提案された。このモデルは対照学習フレームワークを採用しており、各遺伝子について2つの表現を同時に学習します。一方の表現はタンパク質配列から得られ、もう一方の表現はそのゲノム上の近傍領域から得られる。モデルを訓練することで、これら2つの表現が同じ遺伝子に対応するかどうかが判定され、それによって2種類の情報が表現空間内で整合される。
この設計には重要な利点があります。特定の遺伝子が配列レベルで相同性を欠く場合でも、その典型的なゲノムコンテキストは識別の手がかりを提供できます。逆に、コンテキスト情報が非典型的であっても、配列の特徴は識別をサポートできます。この相補的なメカニズムにより、GeneCLRは、新規システムを発見する能力と、その後の予測における大規模なアプリケーションに対応できる拡張性とのバランスを取っている。
全体として、これら3種類のモデルは、コンテキストに基づく局所的なパターン学習から、シーケンスに基づく全体的な一般化、そして複数の情報源からの情報を統合的にモデル化するという、明確な技術的道筋を形成している。この階層的な設計は、単一の手法の限界を回避するだけでなく、未知の抗ファージ機構を体系的に探求するための、より普遍的な技術的枠組みを提供する。
991 TP3Tの精度と921 TP3Tの再現性を実現します。
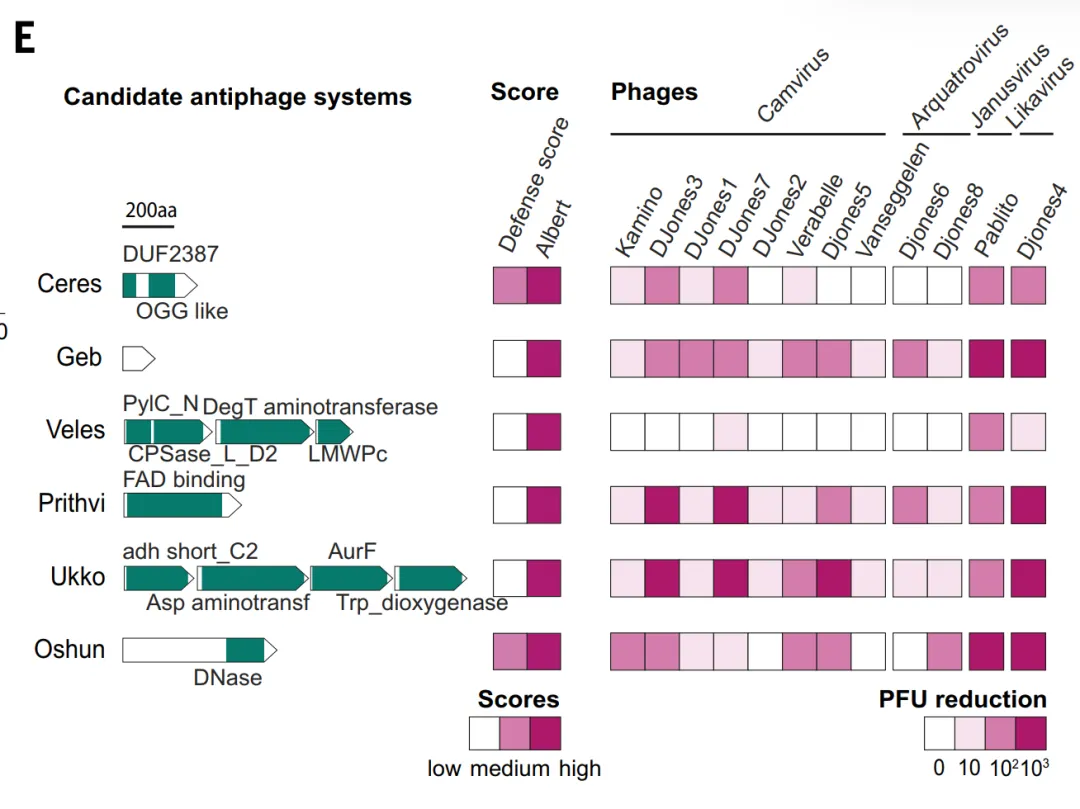
実験的検証において、本研究はまずALBERT_DFの予測力を評価した。このモデルは合計1,930の候補抗ファージタンパク質ファミリーを予測し、そのうち約331のTP3Tが防御スコア法の結果と重複していた。研究者らはさらに、防御スコアによる裏付けも既知の相同性も欠く10個の候補システムを選択し、それらをStreptomyces whiteusで発現させ、12種類のファージで攻撃した。これらのシステムのうち6つは強力な防御を示し、プラーク形成単位を100倍以上減少させた。これらのシステム(CeresやGebなど)は、代謝酵素や機能が不明な小型タンパク質を含んでおり、従来の防御ドメインの範囲を超えている。これは、ゲノムコンテキストに基づく手法が、従来の方法では特定が困難な新規防御機構を発見できることを示している。
ESM_DFの検証において、本研究では高得点候補群を大腸菌で試験し、そのうち6つのシステムが抗ファージ能力を示した。ESM_DFもその一つで、複数の種類のバクテリオファージに対して耐性を示した。これらのシステムには、既知の防御ドメインの変異体だけでなく、DUF7946など、これまで抗ファージ機能とは関連付けられていなかったドメインも含まれていた。これは、ESMが配列相同性に依存するだけでなく、より広範な機能的特徴を特定できることを示しているが、全体としては依然として既知のシステムの拡張である傾向がある。
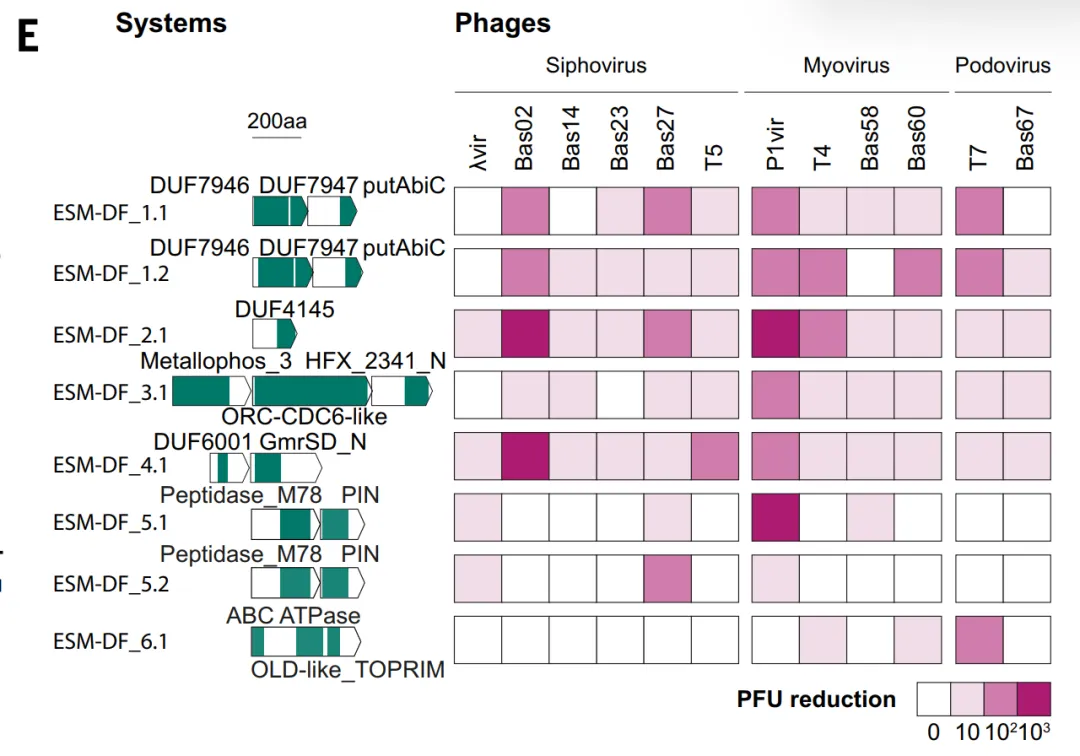
システム評価ではGeneCLR_DFが最も優れた性能を示しました。テストセットでは、その予測スコアは、防御タンパク質と非防御タンパク質を明確に区別することができる。進化解析において、レトロトランスクリプター、CBASS、Thoerisなどの主要な防御系統に一貫して高いスコアを割り当てたが、ESM-650M_DFはそれらを部分的にしか識別できなかった。
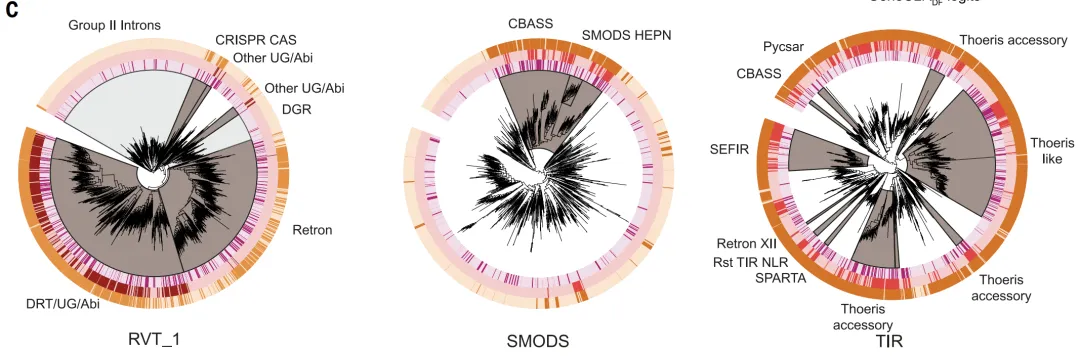
異なるゲノムコンテキスト(防御アイランド、インテグロン、プレファージ領域)において、GeneCLR_DFは防御モジュールを正確に特定できる。定量的結果によると、閾値が -0.74 の場合、GeneCLR_DF は 991 TP3T の精度と 92.41 TP3T の再現率を達成しました。同じ精度で、ESM_DF は 581 TP3T しか再現しませんでした。偽陽性率が 11 TP3T の場合、GeneCLR_DF は既知の防御ファミリーから 941 TP3T を取得しました。これは ESM-650MDF (351 TP3T) および防御分画法 (51 TP3T) よりも有意に高く、561 TP3T ファミリーのみを識別しました。また、新たに追加された 110 システムから 751 TP3T を取得しました。615,672 の候補タンパク質ファミリーのうち、931 TP3T は GeneCLR_DF のみによって検出されました。
オペロンレベルでは、共線クラスタリングに基づくさらなる解析により、多数の防御構造が未解明であることが明らかになった。予測されたタンパク質ファミリー85%はESM_DFとGeneCLR_DFによってのみ同定され、オペロンファミリー45%とオペロンクラスター52.7%はこれまで機能アノテーションが欠落していた。進化解析により、さらに...細菌ゲノムにおける防御遺伝子の割合の中央値は、0.46%から1.53%に増加した。さらに、多数のシステムが可動遺伝因子に富んでおり、23.5%はMGE境界内に位置し、47.1%のサテライト要素は防御能力をコードすると予測されている。
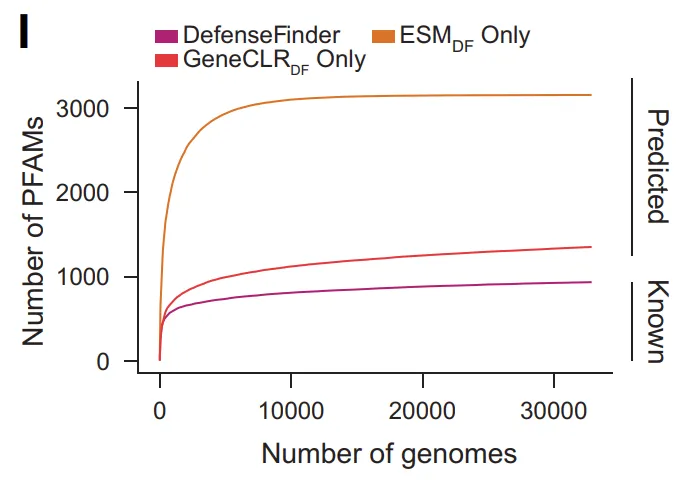
分子多様性レベルでは、GeneCLR_DFは防御関連Pfamファミリーの数を934から3,154(全Pfamの約15%)に拡大しました。同時に、40万を超える予測タンパク質ファミリーにはPfamアノテーションがなく、DefenseFinderに現れるのは5%未満でした。3,500を超えるオペロンファミリーは、既知のドメインを持たないタンパク質のみで構成されていました。これらの結果は、…抗ファージ防御に関わる分子空間の多くは、まだ体系的に解明されていない。
深層学習が抗ファージ防御発見の効率を飛躍的に向上させる
深層学習に基づく抗ファージシステム予測フレームワークと、それらを用いて構築された細菌抗ウイルス免疫アトラスは、この分野においてより拡張性の高い研究の道筋を切り開いています。すなわち、個々の事例発見に依存する「ポイントベースのブレークスルー」から、パターン認識に基づく「体系的なマイニング」への移行です。この変化は、新たな防御機構の発見効率を高めるだけでなく、学術研究と産業応用をより緊密に結びつけることにもつながります。
学術界では、このアプローチは急速に拡大している。複数の研究機関が、機械学習とゲノム解析を組み合わせて、より大規模なファージ耐性システムを特定しようとしている。例えば、MITの研究チームが開発したDefensePredictorモデルは、タンパク質言語モデルのモデリングロジックを活用し、遺伝子配列とゲノムコンテキスト情報を統合することで、抗ファージタンパク質の高感度な同定が実現した。このモデルは、約17,000個の原核生物参照ゲノムで学習され、独立したテストにおいて約821個のTP3T新規防御システムを同定し、「パターンに基づく未知機能の発見」の実現可能性をさらに検証した。
論文タイトル:DefensePredictor:原核生物の免疫システムを発見するための機械学習モデル
論文リンク:
https://www.science.org/doi/10.1126/science.adv7924
業界では、関連技術も急速に導入が進んでいます。抗生物質耐性の深刻化に伴い、バクテリオファージとその派生技術が再び注目を集め、従来の抗生物質に代わる、あるいは補完する重要な方向性となっています。臨床段階の企業であるLocus Biosciences社は、機械学習と合成生物学を組み合わせた、遺伝子操作されたバクテリオファージに基づくプラットフォームを構築し、多剤耐性大腸菌の治療薬候補であるLBP-EC01を開発することで、ファージ療法の精度と制御性を向上させています。
一方、ミクレオス社はより応用重視のアプローチを取り、バクテリオファージとエンドソームの工業化に注力している。同社の製品であるListexは、食品加工におけるリステリア菌汚染の抑制に用いられ、複数の国で規制当局の承認を得ている。また、Staph Efektは、エンドソームの特異的な殺菌作用をスキンケア製品に活用している。このアプローチは、「機能的実装」、つまり抗ファージ機構を研究室レベルにとどめるのではなく、具体的で実用的な製品へと転換することに重点を置いている。
全体として、抗ファージ研究は、アルゴリズムモデルから実験的検証、そして産業応用へと、徐々に包括的なチェーンを形成しつつあります。より多くのデータが蓄積され、モデルが反復されるにつれて、計算から始まり、実験によって検証され、応用によって導かれるこの道筋は、細菌の免疫システムに対するより深い理解を促進し、これらの知見をより効果的に現実世界の解決策へと転換していくことが期待されます。
参考リンク:
https://mp.weixin.qq.com/s/usrVEOeBD5gphhslZahLCA
https://mp.weixin.qq.com/s/Pxlh69TXSr8ffAp_ul3URw








