Command Palette
Search for a command to run...
ICLR 2026 | タスクあたりの学習可能パラメータを125倍削減!新しい手法であるタスクトークンが、具現化された知能による複雑なタスク能力の向上を支援

近年、ロボット制御分野における模倣学習の進歩により、ヒューマノイド型インテリジェントエージェントのマルチモーダル制御を可能にするトランスフォーマーベースの行動基盤モデル(BFM)の開発が促進されている。これらのモデルは、骨盤の位置に基づいてロボットを特定の座標に誘導するなど、高レベルの目標や指示に基づいてソリューションを生成する。BFMは、ゼロショットの例で堅牢な行動を生成することに優れているが、特定のタスクを実行する際には高度なプロンプトエンジニアリングが必要となることが多く、最適とは言えない結果につながる可能性がある。
この文脈では、イスラエル工科大学(テクニオン)の研究チームは、BFMの柔軟性を維持しながら、特定のタスクに効果的に適応させることができる「タスクトークン」と呼ばれる手法を提案した。標準的なベースライン手法と比較して、この新しい手法は、タスクあたりの学習可能なパラメータ数を最大125分の1に削減し、収束速度を最大6倍向上させることができます。
一方、研究者らは、さまざまなタスク(分布外シナリオを含む)におけるタスクトークンの有効性を検証し、他のプロンプト方法との互換性も実証した。実験結果から、タスクトークンは、汎用性を維持しながら、BFMを特定の制御タスクに適応させるための有望なソリューションであることが示された。
関連研究の成果である「タスクトークン:行動基盤モデルを適応させるための柔軟なアプローチ」が、ICLR 2026に採択されました。
研究のハイライト:
* タスク固有の適応: タスクトークンは、トークン化された制御を通じて、基本モデルの微調整を必要とせずに、MaskedMimic (GC-BFM) を特定のタスクに適応させ、ゼロショット機能を維持します。
* ハイブリッド制御パラダイム:ユーザー定義の高レベル事前情報(テキストや共同目標など)と報酬ベースの学習最適化をシームレスに統合できます。
* 性能と汎化能力:タスク性能に関してはフルファインチューニング法と同等であり、環境ダイナミクス(重力や摩擦など)の変化に対する堅牢性に関しては他の方法を凌駕します。

用紙のアドレス:
https://hyper.ai/papers/2503.22886
最先端の AI 論文をもっと見る:
課題:現実世界に近い一連のシナリオにおいて、モデルの汎用性を検証する。
本研究では、モデルの汎用性と適応性を、現実世界に近い様々なシナリオで検証するために、一連の標準化されたタスクを設計した。各タスクは、制御問題に異なるレベルの複雑さを導入するように設計されている。
方向(特定の方向に歩くこと)
このタスクでは、キャラクターを特定の方向に移動させ、基本的な歩行制御と目標方向のアライメントにおけるモデルの能力をテストします。成功基準は、測定時間内に、人型モデルの目標方向への速度偏差が目標速度の20%を超えないことです。
操舵
このタスクでは、人型モデルが骨盤を特定の方向に向けたまま、指定された方向に沿って移動する必要があります。これは、より高度な動作制御能力をテストし、より複雑なシナリオを導入します。成功基準は、キャラクターが目標方向の速度偏差を20%以下に維持し、かつ全体の向きの偏差が45°を超えないことです。
到着
このタスクでは、ヒューマノイドモデルは右手で指定された座標点に到達する必要があります。そのためには、高い動作精度が求められます。成功基準は、右手の位置と目標位置との距離が20センチメートル未満であることです。
ストライク
この課題では、まずキャラクターがターゲット付近まで歩き、次にターゲットを倒す動作を行う必要があります。これは基本的な歩行能力だけでなく、時間制御や空間認識といった複雑なタスク指向行動も評価します。成功基準は、ターゲットが倒され、特定の姿勢で傾き、その傾き角度が約78°を超えないことです。
走り幅跳び
キャラクターは幅1メートルのトンネルを走り抜け、20メートル進んだところでラインを越えてジャンプする必要があり、踏み切り線を越えた後は地面に再び触れてはならない。成功の基準は、ジャンプ距離が1.5メートル以上であることである。
MaskedMimicアーキテクチャに基づく効率的なタスク適応ソリューション
本研究で提案する手法は、MaskedMimic と呼ばれる「目標条件付き行動基盤モデル (GC-BFM)」に基づいています。学習に報酬信号に依存する従来の GCRL 手法とは異なり、MaskedMimicはTransformerアーキテクチャを組み合わせ、入力トークンとして使用される将来のターゲットに対してランダムマスキングを実行します。これにより、将来の関節位置、テキストによる指示、インタラクティブなオブジェクトなど、複数のモダリティから人間のような行動を学習し、再現することが可能になります。
このアーキテクチャと制御メカニズムの組み合わせにより、MaskedMimicはタスクトークンアプローチの理想的な基盤となります。さらに、研究者たちはタスク固有のトークンを学習することで、下流のタスクのパフォーマンスを最適化し、その機能をさらに強化しています。
タスクトークン
下の図に示すように、タスクトークンは3種類の入力ソースを統合します。
* 事前トークン: テキストプロンプトまたは結合条件を介してユーザー定義の行動事前を導入するために使用されるオプションの入力。
* タスクトークン:現在のターゲット観測を処理する訓練済みのタスクエンコーダによって生成されます。
* 状態トークン:環境の現在の状態を表します。
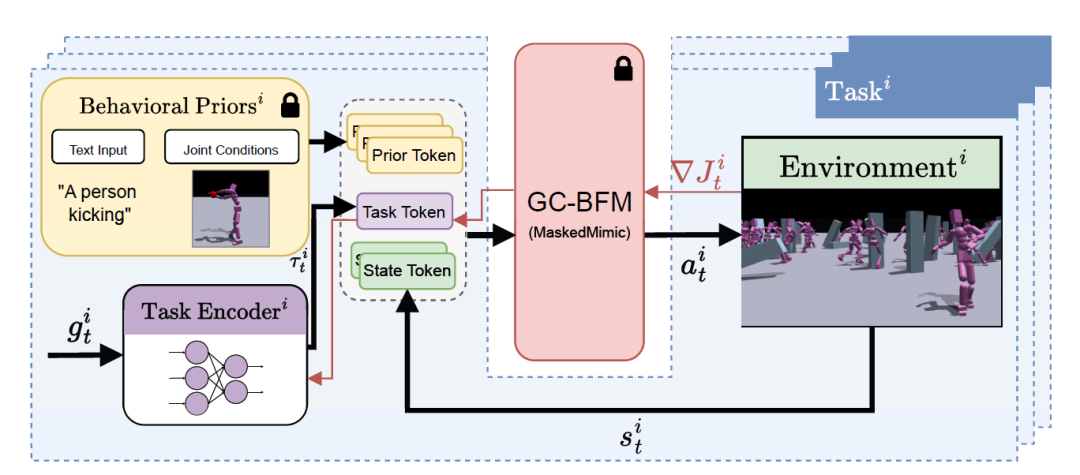
研究者たちは、新しいタスクごとに専用のタスクエンコーダーを訓練し、対応する固有のトークンを生成させた。これらのタスクトークンは、対象となる行動の固有の要件と制約をカプセル化し、簡潔かつ有益なガイダンス信号を基本モデルに提供することで、一般的な行動の事前知識を維持しながら、特定のタスク要件を満たす出力を生成できるようにする。
タスクエンコーダー
タスクエンコーダは、現在のタスク目標を定義する観測データを受け取ります。これらの観測データは、エージェント自身を基準座標系として表現され、タスクトークンとして出力されます。観測データの形式はタスクによって異なります。例えば、旋回タスクでは、ターゲットの移動方向、向き、目標速度などが観測データに含まれます。
MaskedMimicは将来の姿勢目標に基づいて学習されるため、タスクエンコーダーは事前学習された表現に合わせるための固有受容感覚情報も受け取り、それによって意味のある目標信号を生成します。
研究者らは、タスクエンコーダーをフィードフォワードニューラルネットワークとして実装した。その出力(すなわちタスクトークン)は、BFM入力空間内の他のエンコーダートークンと連結され、トークン「文」を形成する。この構造において、タスクエンコーダーが出力するトークンは、動作の自然さを維持しながら、モデルが特定のタスクを完了するように導くために使用される、特殊な「単語」に相当する。
トレーニング
タスクエンコーダを新しい下流タスクに適応させるため、研究者らは近接方策最適化(PPO)を採用した。トレーニング中、BFMはタスクトークンを含む入力トークンの組み合わせに基づいて行動確率分布を予測する。次に、タスク固有の報酬とBFMが出力する行動確率に基づいてPPO目的関数が計算され、BFM自体は固定したまま、タスクエンコーダのパラメータを更新するために使用される勾配が得られる。
BFMを特定のタスクに効率的かつ効果的に適応させる
研究者らは、一連の包括的な実験を通じてタスクトークン法の有効性を評価し、4つの主要な側面におけるその性能と適用可能性を検証するとともに、以下のような複数の競合するベースライン手法と比較した。
純粋な強化学習:PPOトレーニング戦略のみを使用し、ベースモデルに依存しません。
* MaskedMimic ファインチューニング: 報酬信号を使用して MaskedMimic モデル全体を最適化します (パラメータを固定しません)。
* MaskedMimic (関節条件のみ): 関節条件をキューメカニズムとしてのみ使用するオリジナルのMaskedMimic。
* PULSE:モーションキャプチャデータ内の潜在的なスキル空間を再利用する階層的なアプローチ。
* AMP: 識別器を利用してタスクのパフォーマンスを最適化しつつ、アクションの品質を確保します。
タスク適応能力
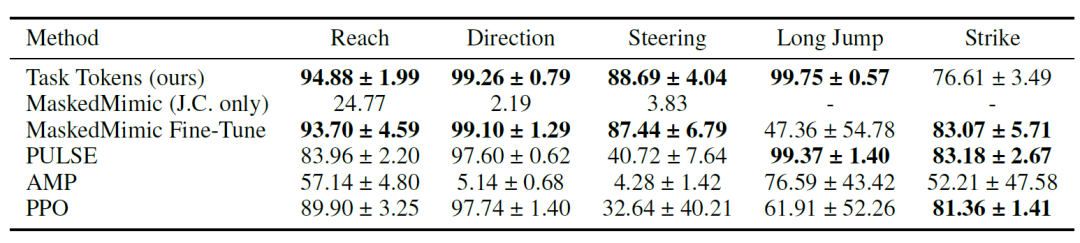
研究者らはまず、タスクトークンがMaskedMimicを下流タスクに効果的に適応させることができることを実証しました。数値結果は以下の表に示されています。結果は、…タスクトークンはほとんどの環境で高いスコアを達成し、特にストライクタスクではPULSE、MaskedMimic Fine-Tune、PureRLがより高いスコアを記録した。
さらに、下の図はトレーニング過程における成功率曲線を示しています。タスクトークンは約5000万ステップで収束するのに対し、PULSEでは同じ性能を達成するのに約3億ステップを要することがわかります。
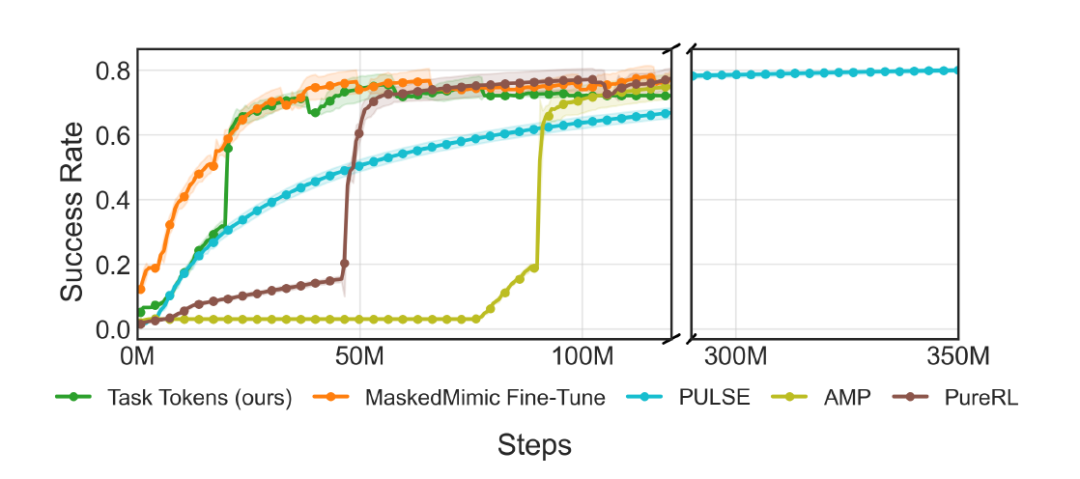
上記の結果を達成するために、タスクトークンでは、約20万個のパラメータを持つ単一のエンコーダをトレーニングするだけで済みます。PULSEとMaskedMimic Fine-Tuneは、それぞれ930万個(9.3M)と2500万個(25M)のパラメータを必要とし、これは約46.5倍と125倍高い値です。大規模モデルの学習は非常にコストがかかるため、この効率性は実世界のアプリケーションにおいて特に重要です。
これらの結果は、タスクトークンが、MaskedMimicなどの行動基盤モデルを、新規かつ未知のタスクに効率的かつ効果的に適応させることができることを示している。
分布外一般化能力
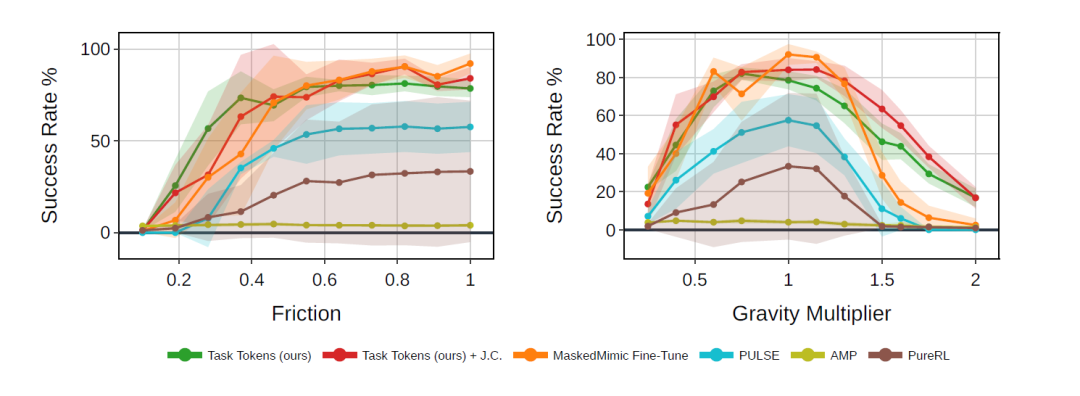
研究者らは、元のBFMとタスクトークンのトレーニング中には発生しなかった分布外(OOD)摂動条件下で比較実験を行い、主に重力と地面摩擦という2種類の変化を考慮した。
下の図の結果は、BFM の助けを借りて、タスクトークンは、これまで想定されていなかった新たなシナリオにおいて、著しく向上した堅牢性を発揮します。まず、ベースライン条件(摂動なし)では、Task Tokensは完全に微調整されたMaskedMimicとほぼ同等の性能を発揮し、他のすべてのベースライン手法を凌駕します。その後、摂動の強度が増加するにつれて、その性能はベースライン手法を大幅に上回ります。特に、Task Tokensは、極めて低い摩擦(例えば、×0.4)と高い重力(例えば、×1.5)の条件下でも、著しく高い成功率を維持します。
ヒトを対象とした研究
以下の表は、各比較方法と比較して、より「人間らしい」アクションとして選択されたタスクトークンの割合を示しています。結果は、…タスクトークンは、MaskedMimic(JCのみ)およびMaskedMimic Fine-Tuneよりもはるかに優れています。これは、ユーザーが設計した条件が、基本的なMaskedMimicモデルに対して特定の分布外特性を持っていること、そしてタスクトークンは微調整よりもアクションの品質に適応するためのより効果的な方法であることを示しています。
さらに、タスクトークンは収束速度、パラメータサイズ、タスクパフォーマンスの点で優れているものの、「人間の行動との類似性」の点ではPULSEの方が高いことが観察される。
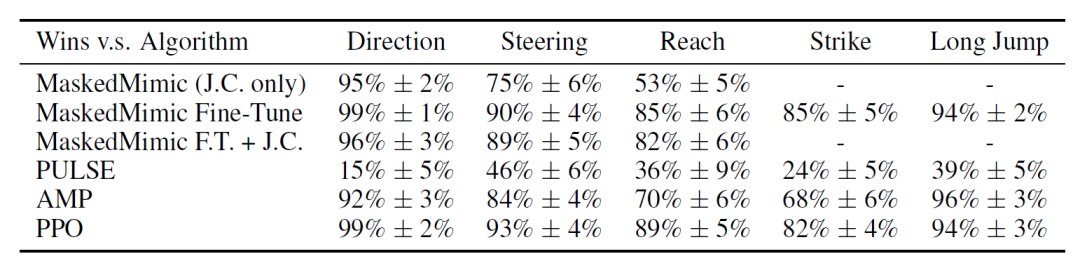
上記の結果に基づくと、タスクトークンは効率性、動作品質、堅牢性のバランスが取れていると結論づけることができる。
マルチモーダルプロンプト効果
最後に、研究者たちはタスクトークンと他のプロンプト方法との相乗効果を検証し、それらの優れた互換性と柔軟性を実証した。
方向タスクでは、報酬関数はエージェントが正しい方向に移動することのみを促し、人間のような体の向きは考慮していません。そのため、ポリシーは「後ろ向きに歩く」という行動に収束する可能性があります。この行動はより高い報酬と高い成功率をもたらしますが、明らかに期待される行動ではありません。
下の図は、人工的に設計された事前条件(例えば、頭部ターゲットの高さや向きに関する制約など)の導入を示しています。訓練過程を経て、「直立歩行」の動作パターンに収束する可能性がある。

攻撃タスクでは、エージェントはターゲットに命中させる必要があります。よく見られる行動としては、エージェントがターゲットまで後退し、その場で回転しながら「旋風」のような動きでターゲットに命中させるというものがあります。下の図は、これら2つの動作様式を組み合わせたものです。
まず、方向タスクと同様の方向条件を用いることで、エージェントは移動中常にターゲットの方を向くようにする。次に、ターゲットに近づくと、「人がキック動作を行う」というテキスト目標が表示され、エージェントが足を使ってキック動作を完了するように誘導される。

特に、研究者らは、モデル全体を微調整すると、よく知られている壊滅的忘却問題が生じ、モデルのマルチモーダルな手がかりを保持・融合する能力が弱まることを観察した。対照的に、タスクトークンは、基本モデルを固定することで、事前に学習された手がかり機能を保持し、学習された行動を人間が指定した行動とより一貫して融合させることができる。
結論
現在の実験は主にMaskedMimicアーキテクチャに基づいています。今後の研究では、より広範なGC-BFMアーキテクチャ内でこの手法の汎用性を検証する必要があります。タスク関連の報酬と観測の設計は依然として専門家の経験に依存していますが、今後の研究では、参入障壁を下げるために(半)自動化された設計を探求する可能性があります。重要な方向性としては、タスクトークンに適合した戦略を実世界のロボットシステムに移行し、シミュレーションから現実世界への問題に取り組み、アニメーションシミュレーションだけでなく、高度な意思決定を必要とする複雑な実世界のタスクにまで拡張することが挙げられます。
最後に、より複雑なタスクエンコーダーアーキテクチャ(現在のフィードフォワードネットワークアーキテクチャを超えるもの)を探求することで、さらなるパフォーマンス向上につながる可能性があります。これらの問題を解決することで、タスクトークンフレームワークがさらに洗練され、より多様で適応性が高く、有能なヒューマノイド型インテリジェントエージェントの開発が促進されるでしょう。
参考文献:
https://openreview.net/forum?id=6T3wJQhvc3
https://arxiv.org/pdf/2503.22886








