Command Palette
Search for a command to run...
視覚的現実を超えて:清華ワールドアリーナの新しい評価システムが具現化された世界モデルの能力ギャップを明らかにする

生成AIが信じられないほどリアルな動画を作成できるようになると、私たちは真の具現化された知能の実現に近づいているのではないでしょうか。答えはそれほど楽観的ではないかもしれません。
ここ数年、動画生成モデルは驚異的な進歩を遂げてきました。照明や影のディテールから複雑な動的シーンまで、多くのモデルが肉眼では現実とほぼ区別がつかない画像を生成できるようになりました。しかし、これらのモデルを実際にロボットシステムに組み込み、現実世界での意思決定や実行に活用すると、残念な現実が浮かび上がります。視覚的なリアリティが機能的な信頼性に結びついていないのです。
身体世界モデルに対する現在の評価システムは、主に「視覚的リアリティ」という一次元的な比較に依存しており、最も鮮明で滑らかな映像を生成したモデルが優れたモデルとみなされています。しかし、根本的な疑問が見落とされています。美しい映像を生成できるこれらのモデルは、現実の物理世界における安定した意思決定と行動を真にサポートできるのでしょうか?
これはまさに、新しい評価システム WorldArena が答えて解決しようとしている中心的な質問です。清華大学、北京大学、香港大学、プリンストン大学、中国科学院、上海交通大学、中国科学技術大学、シンガポール国立大学などの機関が提案したワールドアリーナは、評価を見た目だけに限定するのではなく、映像生成の品質と具現化されたタスクの機能性を初めて統合し、「リアルに見える」から「実際に使える」までの包括的な評価フレームワークを構築しました。

論文タイトル: WorldArena: 具現化された世界モデルの知覚と機能的有用性を評価するための統一ベンチマーク
用紙のアドレス:
http://arxiv.org/abs/2602.08971
プロジェクトのホームページ:
http://world-arena.ai
評価ランキング:
https://huggingface.co/spaces/WorldArena/WorldArena
コードリポジトリ:
https://github.com/tsinghua-fib-lab/WorldArena
6 つの次元から「良い」生成されたビデオを構成するものを再定義します。
生成されたビデオの品質を体系的に評価するために、WorldArena は 6 つのコアディメンションを中心に構成されています。彼らは視覚的な美学に焦点を当てるだけでなく、物理法則や空間知能についても深く掘り下げます。
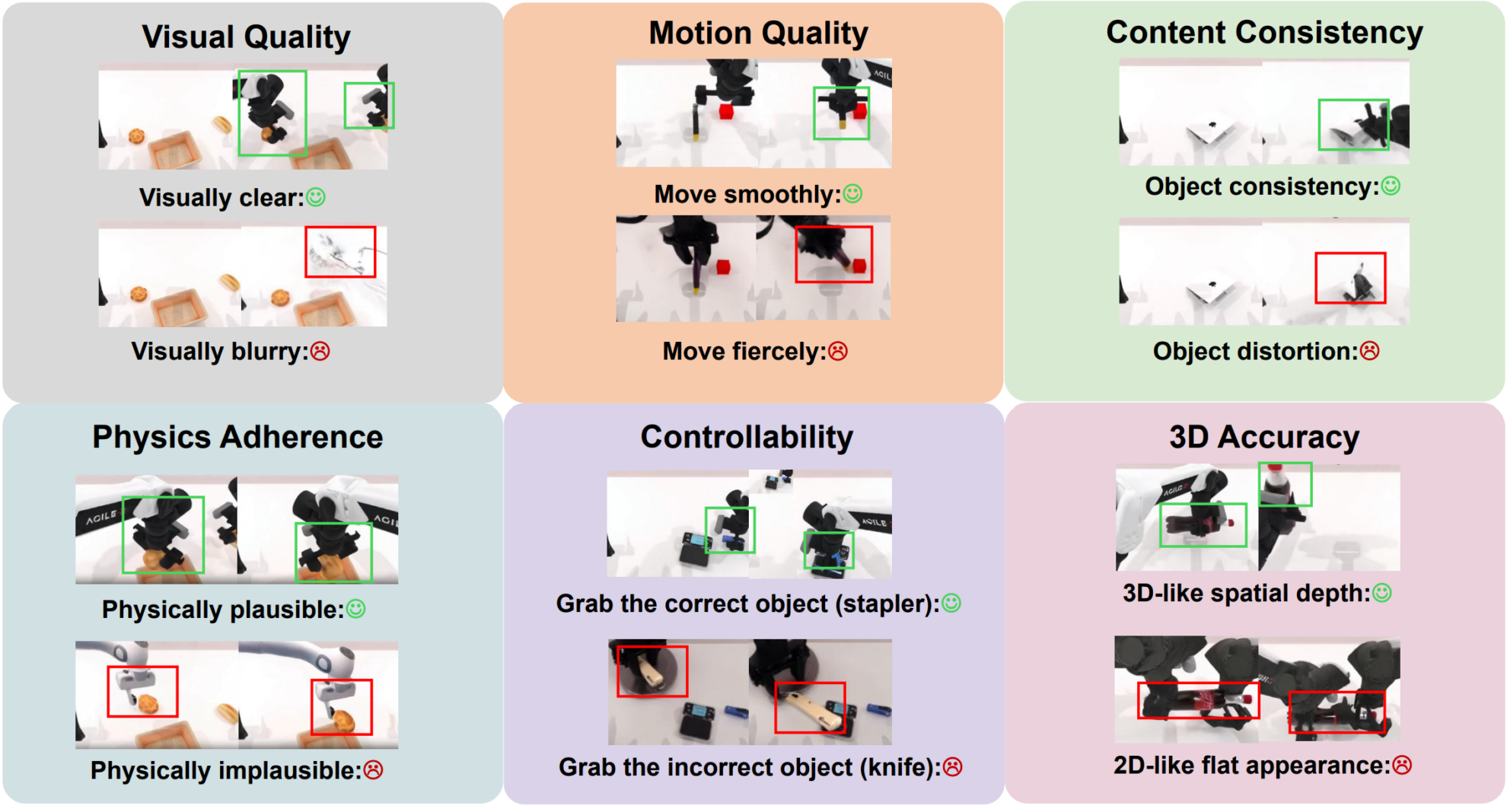
視覚的な品質
視覚品質は、最も基本的な知覚層の評価です。画像の鮮明度、美的スコア、JEPA表現類似度などの指標を用いて、ビデオのリアリティと統計的分布の類似性をピクセルレベルで測定します。この次元は、主に 1 つの質問に答えます。生成された結果は、実際のデータ分布を視覚的に近似しているでしょうか?

アクションの質
モーション品質の次元は、光学フローの連続性、モーションの強度分析、およびモーションの滑らかさを通じて、時間的な合理性に焦点を当てています。ビデオ内のオブジェクトの動きが首尾一貫しており、安定しており、自然法則に準拠しているかどうかを評価します。モデルが明確なフレームを生成できたとしても、動作の軌跡にジャンプや不連続性がある場合、その物理的な信頼性は依然として不十分です。

コンテンツの一貫性
現実世界では、物体は消滅したり変化したりしません。コンテンツ一貫性次元は、対象と背景の時間と空間における安定性を追跡し、構造の変動、対象者の同一性の混乱、背景の不一致といった問題を検出します。この次元では、長期的なタスクをサポートするための前提条件である「一貫した一貫性」を維持する能力を重視します。

物理的なコンプライアンス
物理的な適合性は、視覚と機能をつなぐ重要な架け橋です。WorldArenaは、動画内のロボットアームと物体の相互作用が適切であるか、そして動作軌道が基本的な力学に従っているかを具体的に評価します。言い換えれば、モデルは「見た目」だけでなく「正しく動く」ことも必要です。この側面は、モデルが実用的な制御と計画に使用できるかどうかに直接関係します。

3D精度
身体性知能は、3次元空間構造の理解に依存します。3D精度の次元は、深度推定誤差と遠近法の一貫性を通して、モデルがシーンの空間的幾何学的関係を正確に捉えているかどうかを検証します。空間関係が歪んでいる場合、たとえ2次元画像がリアルであっても、ロボットはその予測に基づいて正確な操作を行うことはできません。

制御性
最後に、制御可能性があります。これは、生成モデルが実用的になるための重要な機能です。この次元では、モデルが本当に指示を「理解」しているかどうか、セマンティックレベルでユーザー入力に正確に応答できるかどうか、さまざまな条件下で識別的な結果を生成できるかどうかを調べます。制御可能性は、生成されたデータの品質だけでなく、タスクへの適応性にも関係します。

これら6つの側面が組み合わさって、WorldArenaの包括的な生成ビデオ品質プロファイルを構成します。これらはもはや独立した指標ではなく、相互に補完し合いながら、生成されるコンテンツは、知覚、時間性、物理的特性、空間、そして意味論の面で高度なリアリティを備えていなければならないという、一つの目標を指し示しています。
本当のテスト: 世界モデルはミッションの実行者になれるか?
ビデオ品質評価が「身体検査」だとすれば、具体化されたタスク機能性評価は「現実世界の演習」です。 WorldArena のもう一つの重要なブレークスルーは、現実的なミッション実行シナリオ内に世界モデルを先駆的に配置した点にあります。3 つの主要な役割から始めて、その真の実用的な価値を検証します。
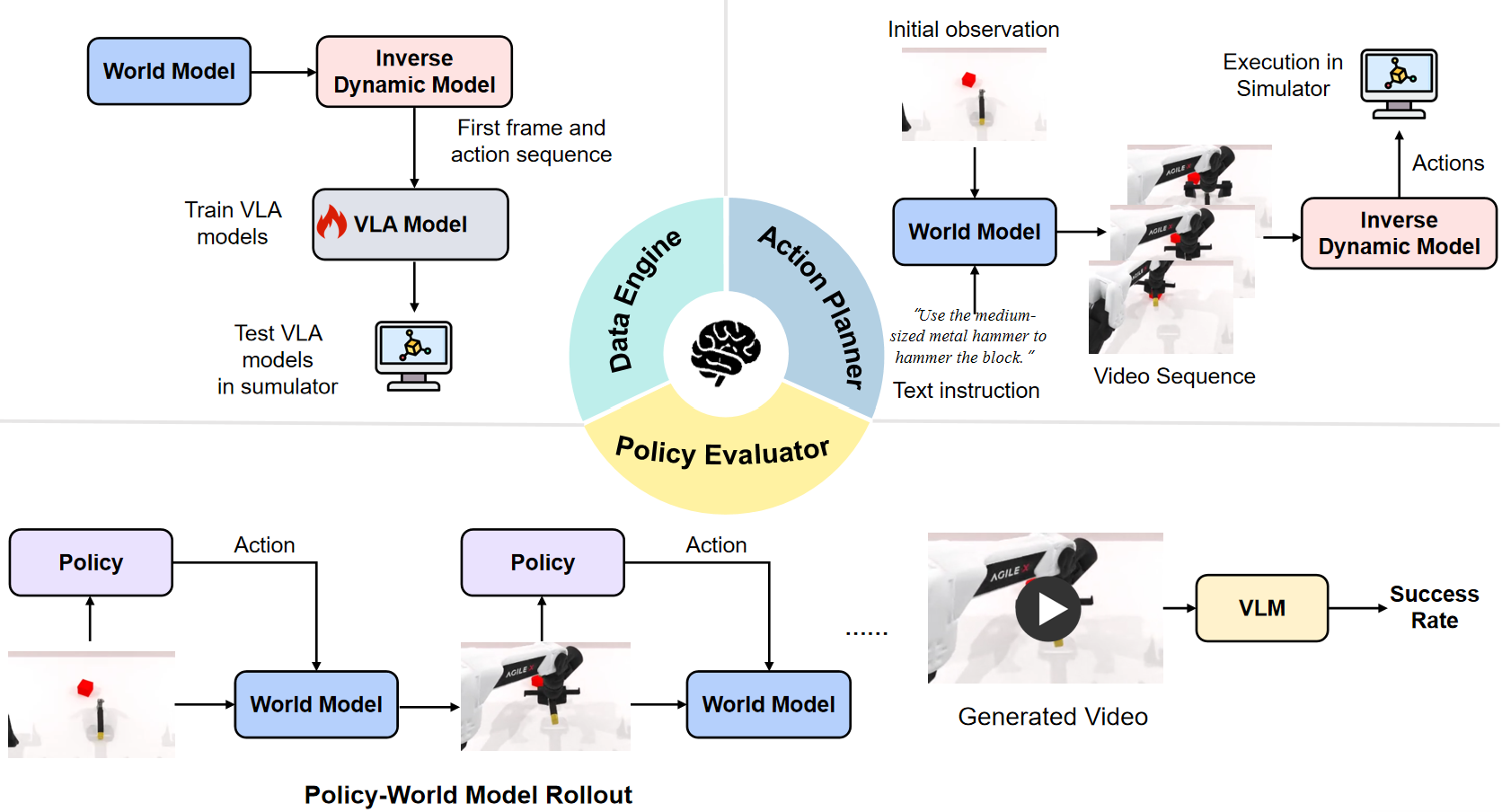
まず、データ生成エンジンとして機能します。
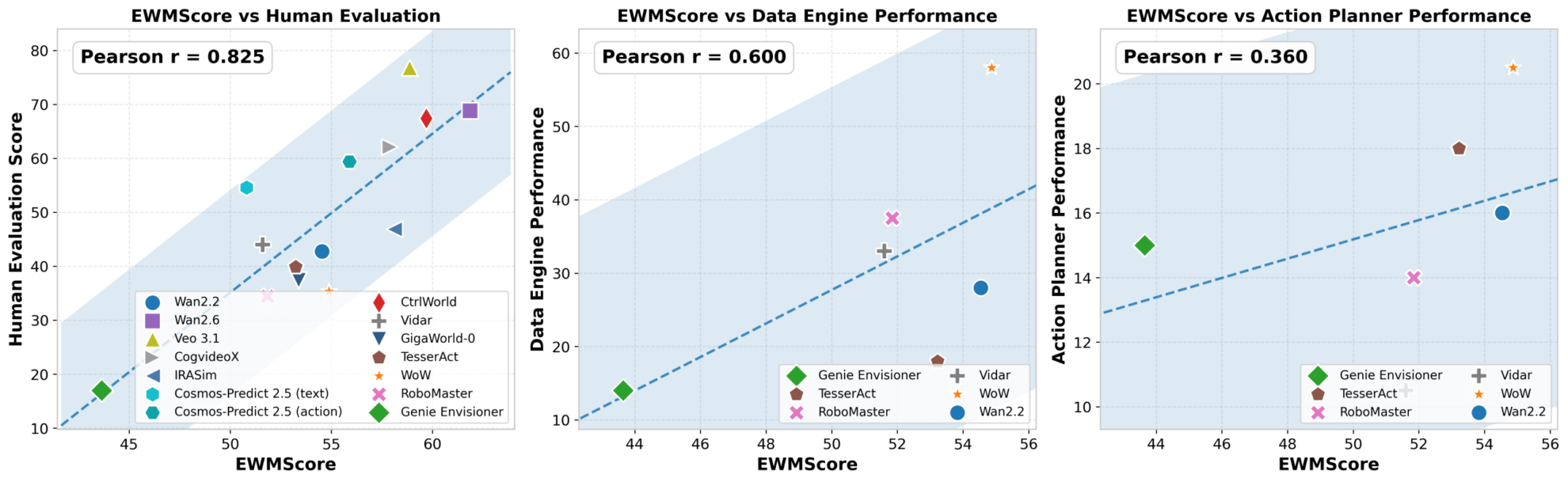
世界モデルは、下流のポリシーモデル(VLAなど)を学習するための高品質な合成軌道データを生成できるでしょうか?実験結果によると、一部のモデルでは確かに性能向上が見られましたが、全体として合成データの品質は実データに比べて依然として大きく遅れており、ほとんどのモデルはポリシー学習において安定的かつ信頼性の高いゲインを提供できていません。つまり、世界モデルを用いて「何もないところから」学習データを作成することは依然として課題です。

第二に、戦略評価者として機能します。
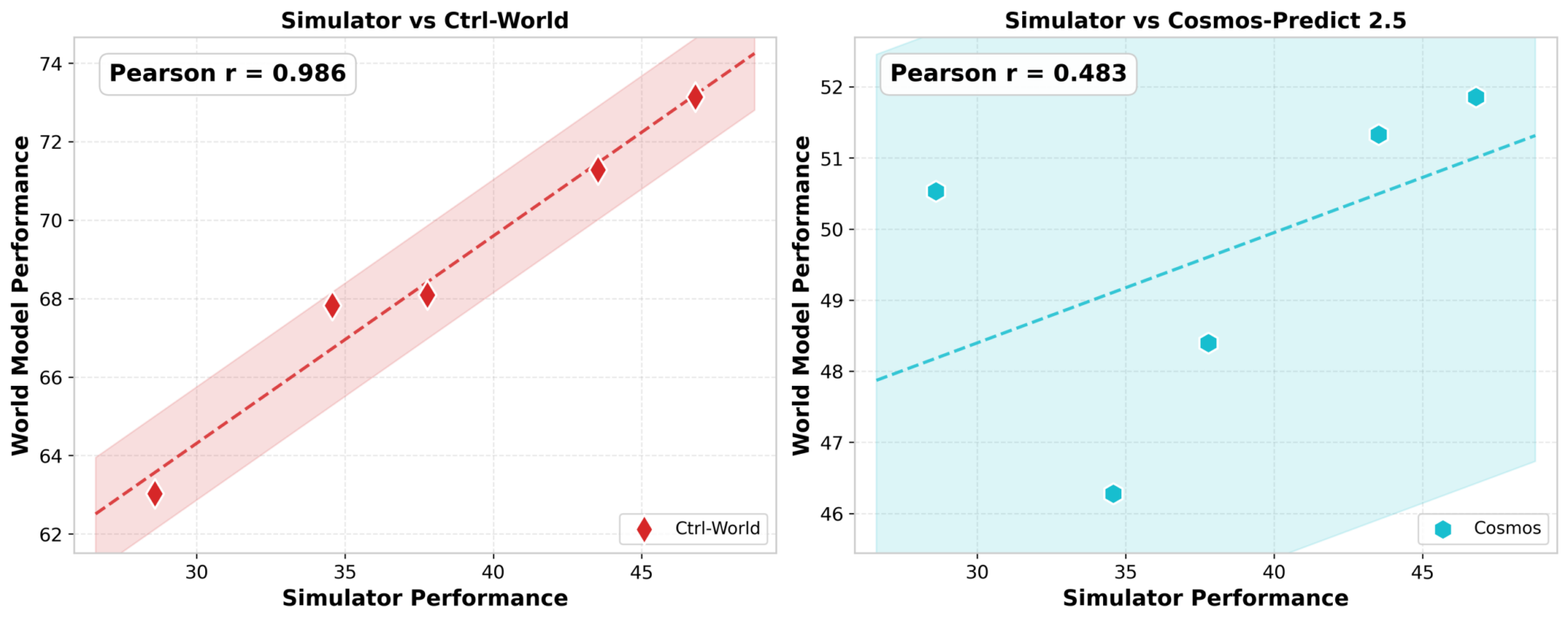
世界モデルは現実世界の環境のダイナミクスを正確にシミュレートし、様々な戦略モデルのパフォーマンス評価において現実環境の代替として機能できるのでしょうか?研究者たちは、様々な能力を持つ一連のVLAモデルを訓練し、現実世界のシミュレーション環境と世界モデル環境の両方でテストを行い、2つの結果セットの相関関係を比較しました。その結果は顕著な違いを示しました。CtrlWorldなどの一部のモデルは現実環境と最大0.986の相関関係を達成し、現実とほとんど区別がつかなくなりました。一方、他のモデルは視覚評価の弱点を反映して、中程度の相関しか示しませんでした。
3番目に、アクションプランナーとして機能します。
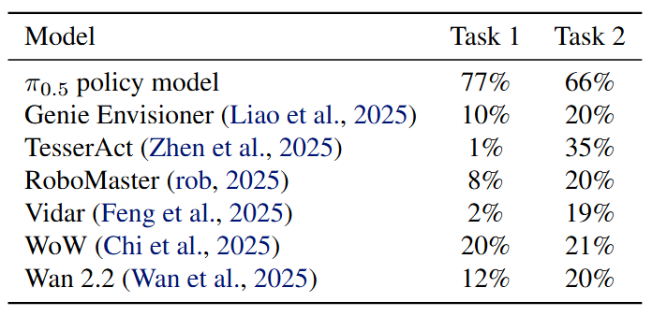
このタスクは、世界モデルを閉ループ制御システムに統合し、エンドツーエンドのタスク実行に直接参加できるようにします。実験の結果、一部のモデルは視覚的に妥当な未来予測を生成できるものの、長期的かつ多段階の閉ループ制御タスクをサポートするパフォーマンスは、成熟した専用のポリシーモデル(Pi 0.5など)に比べて依然として大幅に遅れていることが明らかになりました。これらのモデルは短期的な予測では優れたパフォーマンスを発揮するかもしれませんが、複雑な長期的意思決定においては「道に迷う」傾向があります。
視覚的リアリズムは機能的リアリズムと同じではありません。これは向き合わなければならないギャップです。
WorldArena は、現在主流となっている 14 の世界モデルを体系的に評価し、厳しい現実を明らかにしました。ビジュアル生成機能とタスク実行機能の間には大きなギャップがあります。
多くのモデルは非常にリアルな動画を生成できるが、複雑な物理的相互作用、長期的な一貫性、そして安定した政策支援といった点で根本的な欠陥がある。そのため、WorldArena は、多次元のビデオ評価結果を単一のスコアに統合し、さまざまな視聴者間で比較できる、統合された総合的なスコアリング メトリックである EWMScore を導入しました。重要なのは、EWMScore はビデオ品質に対する人間の主観的な評価と高い正の相関関係にあり、知覚レベルでの有効性を実証していることです。
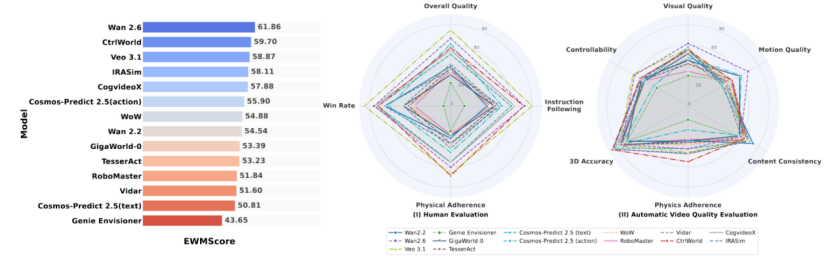
しかし、研究者らがEWMScoreと身体動作タスクのパフォーマンスとの相関分析を行ったところ、より憂慮すべき事実が明らかになりました。データエンジンタスクとの相関は0.600であったのに対し、動作計画タスクとの相関はさらに低く、0.360でした。このデータは、モデルが人間にとって視覚的に許容できるものであっても、必ずしも現実世界の身体動作タスクを効果的にサポートできるとは限らないことを明確に示しています。「美的感覚」と「ユーザーフレンドリー」の間のギャップは、現在の技術が克服しなければならないハードルです。
WorldArenaの意義は、新たな指標の提供だけでなく、研究者の焦点を変えることにもあります。それは、視覚生成の競争から機能的能力の検証へ、知覚的リアリズムから物理的理解と長期的な意思決定の安定性へと焦点を移すのです。
世界モデルの競争が「誰がより映画に似ているか」に限定されなくなり、「誰がより物理学を理解し、誰がより堅牢で、誰がより現実世界の意思決定をサポートできるか」になったとき、具現化インテリジェンスの発展は真に新しい段階に入るでしょう。
評価システムは技術進化の方向性を決定します。ワールドアリーナが提案しているのは、実用的な身体性知能への必要な道筋です。








