Command Palette
Search for a command to run...
MITなどが開発したGPU電力推定フレームワークであるEnergAIzerは、平均1.8秒で予測を完了し、誤差は約81 TP3Tです。

ローレンス・バークレー国立研究所の推定によると、人工知能の爆発的な成長により、2028年までに、データセンターは米国における総電力消費量の12%を消費する見込みだ。AIワークロードの主要なアクセラレータとして、グラフィックス処理ユニット(GPU)は主要な電力消費源となっており、最新のNVIDIA H100とGB200では熱設計電力(TDP)がそれぞれ700Wと1200Wに達しています。ますます深刻化するエネルギー問題に直面する中で、AIワークロードにおけるGPUの電力とエネルギー消費量を迅速に推定することが、極めて重要になってきている。
消費電力モデルでは、動的な消費電力がモジュールのアクティビティに直接比例するため、さまざまなGPUモジュール(DRAMやTensorコアなど)の使用強度を特徴付けるために、ハードウェア使用率情報を入力として必要とするのが一般的です。既存の手法では、主に2つのアプローチでこの情報を取得しています。1つは、命令レベルシミュレータを使用して、GPUの実行サイクルをシミュレートすることでモジュール使用率を導出する方法です。しかし、中規模のワークロードであっても、このような詳細なシミュレーションには数時間かかる場合がある。2つ目は、実行時パフォーマンス分析(プロファイリング)です。しかし、これは分析のオーバーヘッドが増加するだけでなく、利用可能なハードウェアリソースにも依存する。
このような背景のもとMITとMIT-IBMワトソンAIラボの研究者らは、AIワークロード向けの高速GPU電力推定フレームワークであるEnergAIzerを開発した。高価なシミュレーションや性能分析を行うことなく、消費電力モデルに必要なハードウェア利用情報を直接提供できる。この新しいフレームワークを使えば、エンドツーエンドの消費電力推定を平均わずか1.8秒で完了できる。NVIDIA Ampere GPUにおいて、EnergAIzerは消費電力誤差を約81 TP3Tに抑えることに成功しました。これは、複雑な周期シミュレーションやハードウェア性能分析に依存する従来のモデルと遜色ない性能です。
研究者らはまた、EnergAIzerの周波数スケーリング機能とアーキテクチャ構成の探索機能も実証した。NVIDIA H100の消費電力の予測を含めても、誤差はわずか7%です。EnergAIzerは、AIワークロードの消費電力を高速かつ正確に予測する機能を提供します。データセンターの運用者は、これらの予測値を利用して、限られたリソースを複数のAIモデルとプロセッサに効率的に割り当て、エネルギー効率を向上させることができます。
関連する研究成果は、「EnergAIzer:AIワークロード向け高速かつ高精度なGPU電力推定フレームワーク」と題され、arXivにプレプリントとして公開されている。
研究のハイライト:
* 新しいフレームワークは、わずか数秒で信頼性の高い消費電力推定値を生成できるのに対し、従来のモデリング手法では結果が出るまでに数時間、場合によっては数日かかることもある。
* この新しい予測ツールは、まだ導入されていない新興設計を含む、幅広いハードウェア構成に適用できます。
このツールは、アルゴリズム開発者やモデル提供者が、新しいモデルを導入する前に、その潜在的なエネルギー消費量を評価するのに役立ちます。

用紙のアドレス:
https://arxiv.org/abs/2604.20105
弊社の公式WeChatアカウントをフォローし、バックグラウンドで「電力消費予測」と返信すると、PDF版の全文を入手できます。
データセット:様々な主流の演算子タイプとテンソル形状を網羅
すべての実験において、研究者らは、NVIDIA A100-40GB-PCIEおよびA10 GPUに基づいてオフラインカーネルデータベースを構築した。EnergAIzerのトレーニングに使用する様々な主流の演算子タイプとテンソル形状については、以下の表を参照してください。
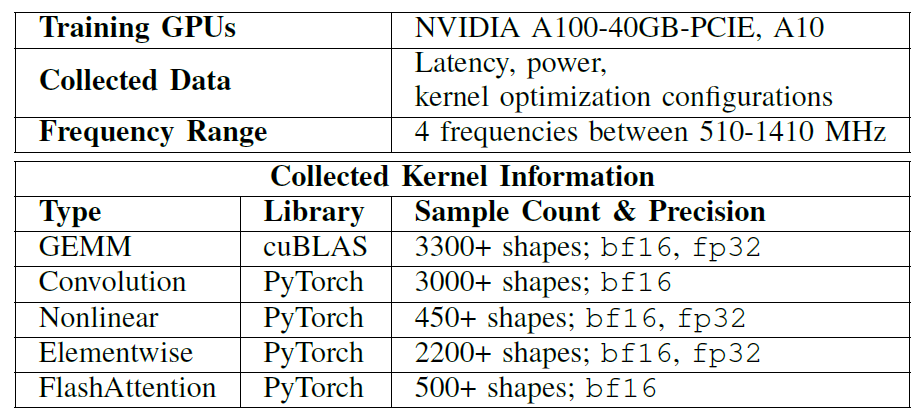
含む:
* GEMM型行列計算
畳み込み
* 非線形
* 要素ごと
* フラッシュアテンション
研究者たちはEnergAIzerに実験用リソースを提供した。これには、推定フレームワークのソースコード、経験的フィッティングのための事前収集済みデータベース、および予測を検証するための実際の測定データが含まれます。そのリソースには、実験を再現するためのスクリプト、単一カーネルレベルの電力とレイテンシの推定値を生成するスクリプト、およびAIワークロードのエンドツーエンドの推定値が含まれています。
EnergAIzerカーネルレベル予測モデルを構築するための3つのステップ
ENERGAIZERの中核を成すのはカーネルレベルの予測モデルであり、研究者たちはこれを3つのステップで構築する。初め、タイリング、スレッドブロックスケジューリング、パイプライン処理といったソフトウェア最適化戦略などのワークロード表現を確立することで、パフォーマンスモデルの基礎となる構造化された実行パターンが形成される。第二に、これらのパターンを足場として、パフォーマンスモデルを構築し、実証データに適合させる。やっと、電力消費モデルは、予測された利用率を用いて動的な電力消費量を推定する。
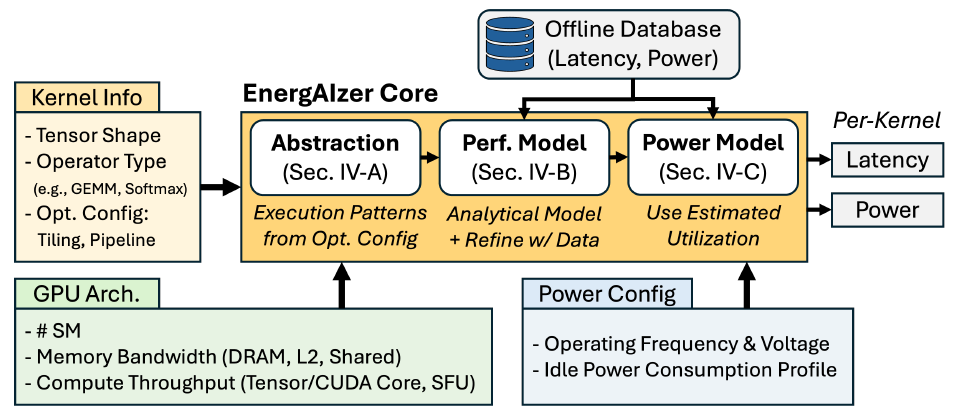
ワークロード構造モデリングレイヤー
最適化戦略
テンソルは、GPU実行のさまざまなレベルで階層的にデータタイルに分割されます。スレッドブロックスウィズリングは、同じ入力タイルにアクセスするスレッドブロックを隣接するテンソルにスケジュールすることで、L2キャッシュの再利用性を向上させます。ソフトウェアパイプライン処理は、データ転送と計算を時間反復でオーバーラップさせます。パイプライン構造によって、パフォーマンスモデリングの重要な要素であるレイテンシが決定されます。
GEMMを超えて
この知見に基づき、研究者らはサービス電力モデリングにおけるモジュールレベルの利用率を導き出すことを目的として、AIにおける主要なカーネルタイプ(非線形カーネル、要素単位カーネル、融合カーネルなど)すべてに分析を体系的に拡張した。
確認する
研究者らは解析手法を用いて、共有メモリ、L2キャッシュ、およびDRAMの総負荷トラフィックを算出し、NVIDIA A100-40GB-PCIE GPU上でNCUパフォーマンス解析によって得られたハードウェアカウンタデータと比較した。790個以上のGEMMコア、70個のSoftmaxコア、および380個以上のFlashAttentionコアにおいてほぼ完全な相関関係が確認され、ブロックパラメータと理想的なスレッドブロックの再配置がメモリトラフィックを決定することが実証された。
パフォーマンスモデルレイヤー
タイムラインの作成
パフォーマンスモデルは、粗粒度操作で構成される実行タイムラインを構築します。ティルティングは操作の粒度(データロード/ストレージ、計算命令数など)を決定し、パイプライン処理は依存関係に基づいてこれらの操作がどのように重複するかを決定します。このタイムラインは分析の枠組みを形成し、以下の図に示すようにモジュールレベルの利用状況を明らかにするために使用されます。
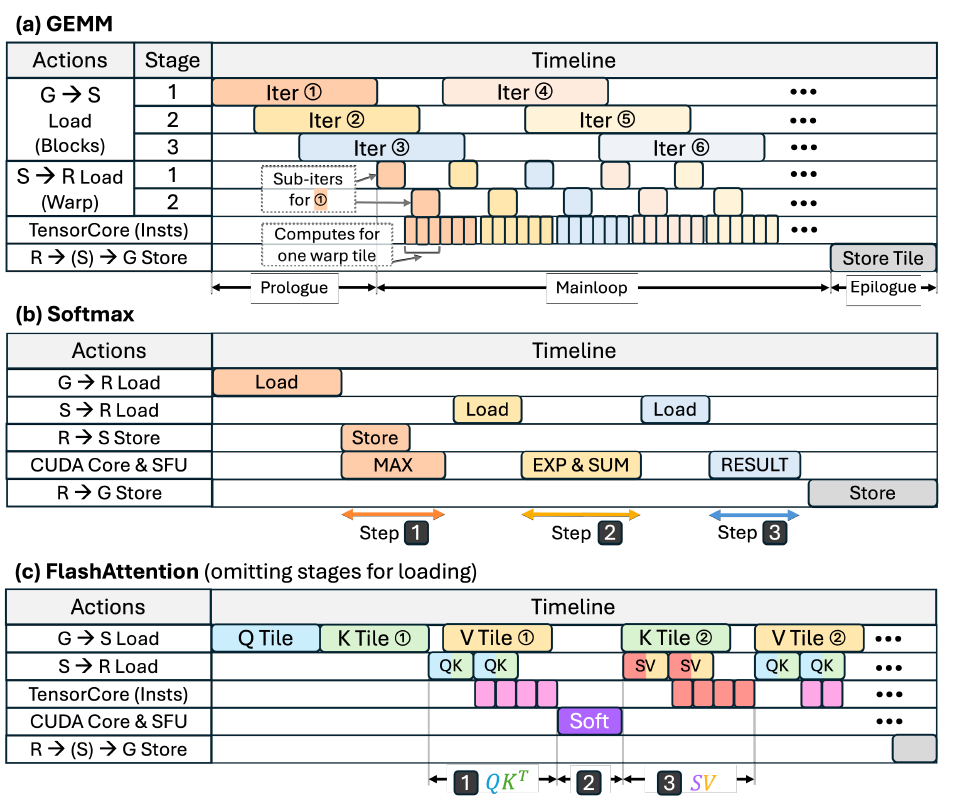
遅延予測
タイムライン構造を確立した後、各操作のレイテンシを計算する方法について説明します。その後、これらの個々の操作のレイテンシを組み合わせて全体の実行時間を算出し、パイプラインの影響を反映させます。
利用率の算出
ビルドのタイムラインに基づいて、6つの主要モジュール(DRAM、L2キャッシュ、共有メモリ、テンソルコア、CUDAコア(通常の浮動小数点演算用)、特殊機能ユニット(指数関数やその他の非線形関数用))の使用率が抽出されました。各モジュールの使用率は、そのモジュールのアクティブ時間とカーネル実行時間の合計との比率として定義されました。
消費電力モデル層
研究者らは、性能モデルから得られたモジュールレベルの利用率に基づいて、標準的な動的消費電力式を用いてそれを推定した。この方法は形式的には従来の消費電力モデリングと一致するが、重要な違いは利用率αの算出方法にある。オフラインデータベースは複数の動作周波数における消費電力測定値を網羅しているため、C係数は全周波数範囲にわたって誤差を最小化するように調整され、推論段階で追加の測定を行うことなく、任意の周波数における消費電力推定を可能にする。
平均すると、ワークロード1件あたりわずか1.8秒で、レイテンシと消費電力の同時推定が完了する。
研究者たちは、EnergAIzerの予測能力と、様々な設計オプションの検討におけるその応用について、実験的に評価した。
AIワークロードにおけるレイテンシと消費電力推定の精度
下の図は、さまざまな言語モデル(BERT-Large、GPT-2、OPT-1.3B、Qwen2-1.5B)と視覚モデル(ResNet101、ViT、MobileViT)のエンドツーエンド遅延と消費電力の推定結果を示しています。
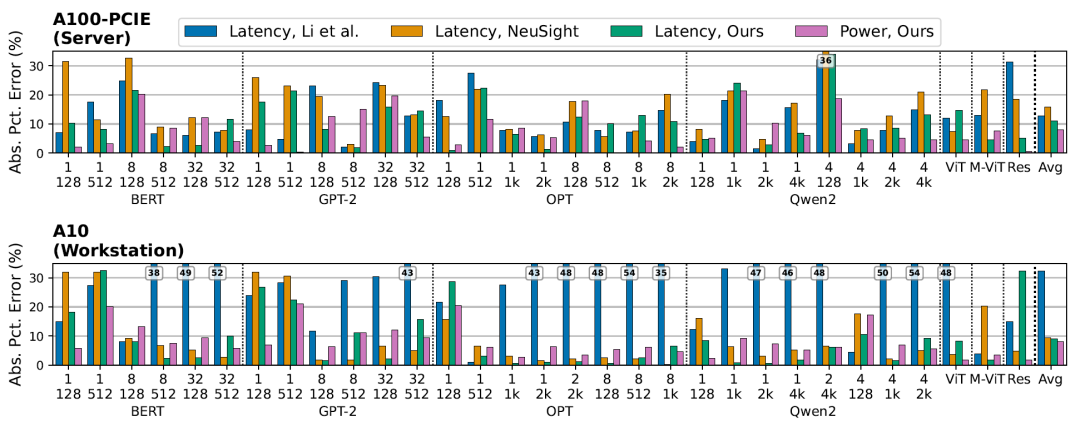
EnergAIzerは、サーバーグレードのGPU(A100-40GB-PCIE)において、平均レイテンシ誤差11.01 TP3T、消費電力誤差8.01 TP3Tを達成しました。ワークステーションクラスのGPU(A10)では、それぞれ8.8%と8.2%となる。これらの結果は、すべてのワークロードにわたって平均化されています。レイテンシ予測に関しては、EnergAIzerは最先端の軽量パフォーマンスモデル(Liら、NeuSight)と同等の性能を発揮するだけでなく、これらのモデルでは提供できない電力推定機能も備えています。
EnergAIzerは、ワークロードごとに平均わずか1.8秒で、レイテンシと消費電力の同時推定を完了します。言語モデルの場合、1回の予測に1.1秒から2.8秒かかります。これに対し、NCUを使用したハードウェアカウンタによるデータ取得には452秒から8192秒かかるため、317倍から3856倍の高速化が実現されます。
電圧周波数調整について探求する
電圧周波数制御は、さまざまな動作点における正確な消費電力予測によってメリットが得られる、一般的に使用されている電力管理技術です。研究者らは、A100-40GB-PCIE 上で、EnergAIzer がさまざまな周波数 (510~1410 MHz) における消費電力を推定する能力を評価しました。実験では、EnergAIzer の電力構成入力パラメータのみを調整し、その周波数における目標周波数、電圧、アイドル時の消費電力を設定しました。次の図は、実際の測定値と予測された消費電力の比較を示しています。
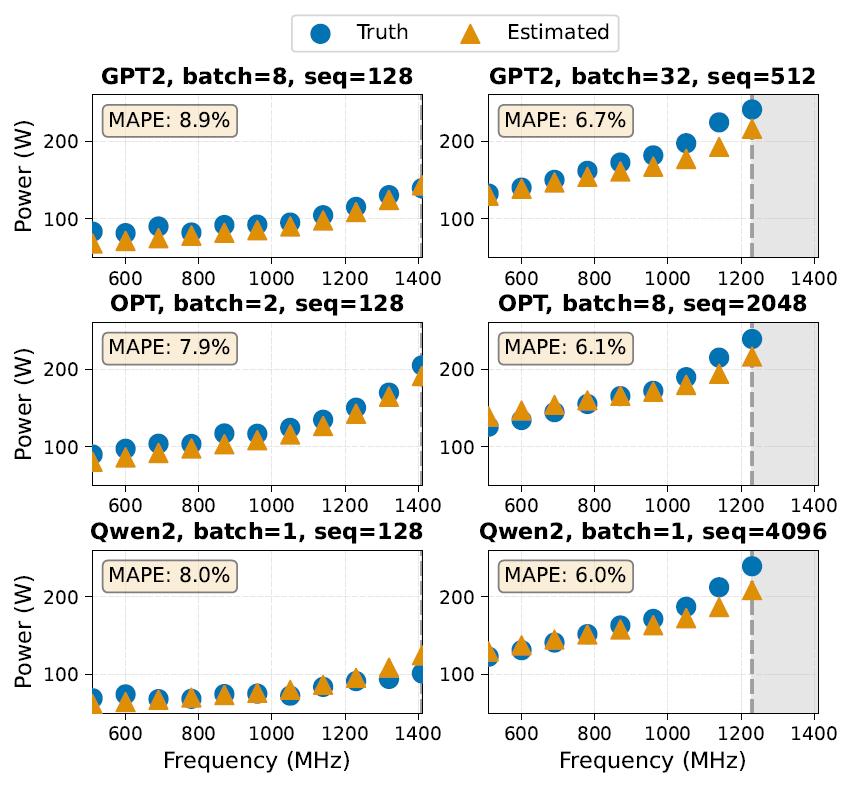
EnergAIzerフレームワークは、さまざまなワークロードタイプにおける典型的なスケーリング挙動を捉えることができます。例えば、利用率の低いワークロード(小規模なバッチ/シーケンス、左図)と、電力制約のあるワークロード(大規模なバッチ/シーケンス、右図)などです。異なる周波数における平均絶対パーセント誤差(MAPE)は6%~9%です。
GPUアーキテクチャ構成の探求
このフレームワークは、GPUアーキテクチャパラメータ(SMの数、メモリ帯域幅、計算スループットなど)を入力として調整することで、さまざまなGPUアーキテクチャ構成を探索することもサポートしています。これにより、ターゲットハードウェアのデータ取得を必要とせずに、新しいアーキテクチャの消費電力を予測することが可能になります。研究者らは、同じGPUアーキテクチャ世代内での探索と、異なるアーキテクチャ世代間での探索という2つのシナリオを評価しました。ターゲットGPU構成は以下の表にまとめられています。
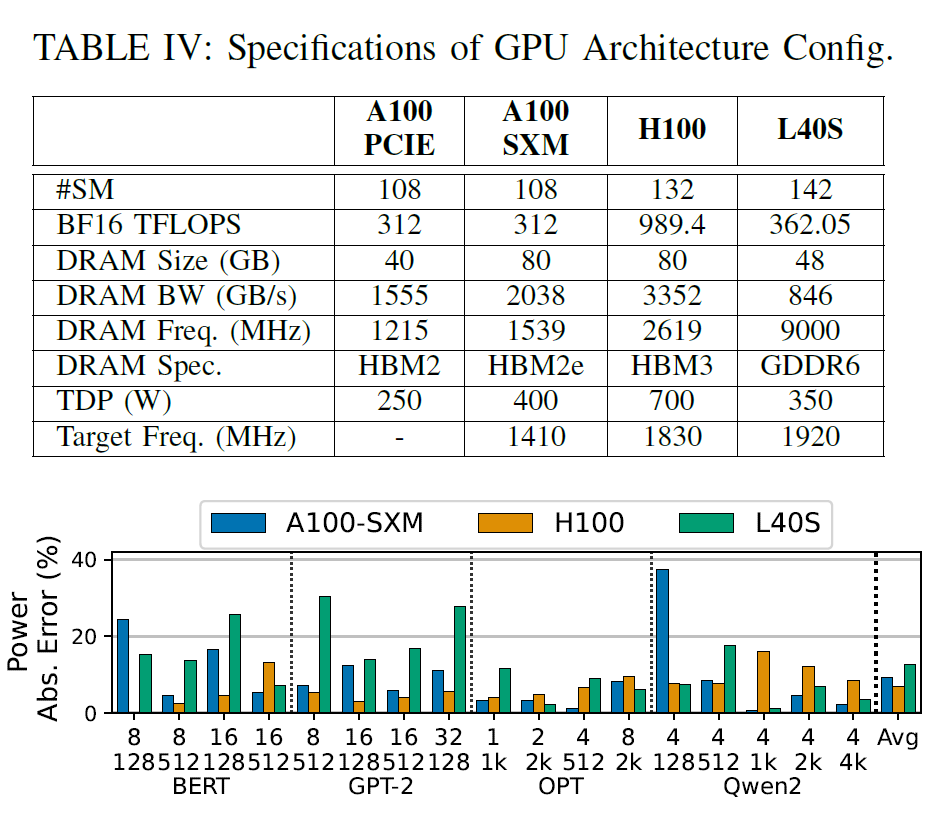
まず、Ampereアーキテクチャ内では、研究者らはA100-40GB-PCIEから収集したデータベースのみを使用してA100-80GB-SXMの消費電力を予測し、平均誤差は9.11 TP3Tでした。次に、世代間シナリオでは、Ampereアーキテクチャのデータベースを使用してHopper(H100)とLovelace(L40S)の消費電力を予測したところ、それぞれ6.71 TP3Tと12.71 TP3Tの誤差が生じました。
総合的に見て、EnergAIzerはAIワークロードの高速かつ正確な消費電力予測を提供します。
結論
データセンター運用者にとって、EnergAIzerはさまざまなGPU構成、周波数戦略、リソーススケジューリング方式のエネルギー消費性能を迅速に評価できるため、より洗練されたリソースオーケストレーションとエネルギー効率の最適化を支援します。AIモデル開発者にとっては、このフレームワークは新しい「ハードウェア認識型」ツールを提供します。モデル設計段階で、異なる精度や運用者の実装によって生じるパフォーマンスと消費電力のトレードオフを評価できるため、エネルギー消費の問題が展開時に初めて顕在化することを回避できます。
もちろん、現在のフレームワークには、マルチGPU協調コンピューティングのモデリング機能の改善、通信オーバーヘッド、不規則な疎なコンピューティングなど、いくつかの制約が残っています。しかし、方法論的な観点から見ると、EnergAIzerは明確な傾向を示しています。GPU消費電力モデリングは、「測定に大きく依存する」オフライン分析ツールから、「軽量で組み込み可能な」オンライン意思決定機能へと進化しています。AIコンピューティング能力の継続的な拡大と、ますます厳しくなるエネルギー制約を背景に、この種の技術の価値は急速に高まっています。今後、モデルの複雑さとハードウェアの多様性がさらに増大するにつれて、EnergAIzerのようなフレームワークは単なる研究ツールにとどまらず、AIインフラストラクチャに不可欠な要素となる可能性が高いでしょう。
参考文献
https://news.mit.edu/2026/faster-way-to-estimate-ai-power-consumption-0427
https://arxiv.org/pdf/2604.20105