Command Palette
Search for a command to run...
スタンフォード大学は、25,000 の臨床データ ポイントに基づいて、752 のタスクをリードする初のネイティブ 3D 腹部 CT 視覚言語モデルである Merlin をリリースしました。
コンピュータ断層撮影(CT)は、臨床診断と治療において広く用いられる画像診断技術であり、身体の様々な部位の疾患診断に広く利用されています。統計によると、世界中で毎年約3億回のCTスキャンが実施されており、そのうち約4分の1が腹部CTスキャンです。医療診断と治療における画像診断技術への依存度が高まるにつれ、画像診断の需要は増加し続けています。しかし、放射線科医が腹部CT画像を1枚読影するのに通常20分を要しており、急速に増加する臨床需要に診断効率が追いついていません。さらに深刻なのは、深刻な放射線科医不足です。予測データによると…2036年までに、一部の地域では19,000人以上の放射線科医が不足すると予想されており、業界における需要と供給の不均衡の拡大が浮き彫りになっている。
高度なデータ処理能力と高スループット分析能力を備えた機械学習は、膨大な量の医療画像から迅速に特徴を抽出し、インテリジェントに識別することを可能にし、従来の手作業による画像読影における低効率性や人員不足といった課題を効果的に解決します。特に、コントラスト言語画像事前学習(CLIP)技術を基盤とする視覚言語モデル(VLM)は、テキスト表現と視覚表現を共通の埋め込み空間に整合させ、自然言語を用いた視覚モデルの教師あり学習をサポートします。このタイプのモデルは基礎モデルとして、ゼロショット学習を実現できるだけでなく、大規模な言語モデルと組み合わせて臨床データでトレーニングした後、放射線画像やレポートの分析にすぐに適応できます。
理論と技術の進歩に加え、現在のVLMベースの手法は、BiomedCLIP、LLaVA-Rad、Med-PaLMMといったモデルが実用化され、放射線医学分野において大きな応用可能性を示しています。しかしながら、技術の進歩とモデルの実用化は、必ずしも成熟した応用につながるわけではありません。VLMは実用化において依然として多くの重要な課題に直面しており、臨床現場での広範な採用と信頼性の高い使用を阻んでいます。
初め、既存の手法は主にX線写真などの2次元画像を対象としており、腹部CTスキャンなどの3次元画像を効率的に処理することが困難です。スライス画像を集約して全体像を解析する方法は極めて非効率的です。第二に、現在、VLMの学習・評価に利用できる腹部CTデータセットは公開されていません。民間モデルは、診断コーディングや放射線学的レポートなどのマルチモーダル臨床データを完全に統合しておらず、統一された3次元腹部CTタスクベンチマークも存在しないため、関連する基本モデルの学習・評価システムに大きなギャップが生じています。
上記の課題に応えて、スタンフォード大学の研究チームは、腹部 CT スキャン用の最初のネイティブ 3D 視覚言語モデルである Merlin と、腹部 CT スキャンと放射線レポートのペア 25,494 枚を含むデータセットを提案しました。 Merlinは、実際の病院から収集した構造化データと非構造化データ(ペアCTスキャン、電子健康記録(EHR)の診断コード、放射線レポートなど)を用いて、単一のNVIDIA A6000 GPU上で学習されました。研究チームは、5,137件のCTスキャンを用いた内部検証、44,098件のCTスキャンと腹部CTスキャンに焦点を当てた2つの公開データセット(VerSeとTotalSegmentator)を用いた外部検証を実施しました。検証結果から、Merlinはベンチマークタスクにおいて特定のベンチマークモデルを総合的に凌駕することが示されました。
「Merlin: コンピューター断層撮影による視覚・言語基盤モデルとデータセット」と題された関連研究成果が Nature 誌に掲載されました。
研究のハイライト:
* この研究では、2D 画像のみに焦点を当てた従来のモデルの限界を克服し、腹部 CT スキャンに特化した初のネイティブ 3D 視覚言語モデルである Merlin を提案します。
* この研究では、25,494 枚の腹部 CT スキャンと放射線レポートのペアを含む大規模なデータセットを公開し、データセット分野のギャップを埋めました。
* この研究では、構造化されたEHRデータと非構造化放射線レポートを監視信号として革新的に統合し、マルチタスク学習と段階的トレーニングを組み合わせた多段階事前トレーニングフレームワークを提案しています。

用紙のアドレス:
https://www.nature.com/articles/s41586-026-10181-8
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「Merlin」と返信すると、完全な PDF を入手できます。
VLMのトレーニングと評価のためのデータギャップを埋める
3D VLM のトレーニングと評価に使用できる公開腹部 CT データセットの不足を補うために、研究チームは実際の医療センターから取得した大量の準拠データを使用しました。最終的に、ペア CT スキャン、非構造化放射線レポート、構造化 EHR を網羅した、18,321 人の患者を含む高品質の臨床データセットが公開されました。で:
* CTスキャンデータ:
データは腹部全体のCTスキャンから得られ、それぞれ複数のシーケンスが含まれています。情報量を最大化するために、最も多くの軸方向スライスを含むシーケンスが選択されました。このプロセスにより、25,528枚のCTスキャンから10,628,509枚の2次元画像が得られました。
* 放射線学的報告書:
本研究では、各CTスキャンに対応する放射線学的レポートをまとめました。これらのレポートは複数の部分で構成されており、最も重要なのは「所見」と「印象」です。前者には各臓器系の詳細な観察結果が含まれ、後者には主要な臨床所見が要約されています。提供された情報の粒度と先行研究の妥当性に基づき、トレーニングでは「所見」セクションのみ、合計10,051,571トークンが使用されました。
* 電子健康記録:
このデータは、国際疾病分類(ICD)コード形式の診断情報を用いてモデルの学習に使用されました。これらの情報は、対応する患者のCTスキャン記録に関連付けられています。データセットには、合計954,013件のICD9コード(5,686の固有コードを含む)と、2,041,280件のICD10コード(10,867の固有コードを含む)が含まれています。
データ分割に関しては、事前学習データセットは3つのサブデータベースに分割されました。60%(15,331枚のCTスキャン)、20%(5,060枚のCTスキャン)、20%(5,137枚のCTスキャン)で、それぞれ学習、検証、テストに使用されました。予防措置として、同一患者の複数のCTスキャンが同じサブデータベースに含まれないようにしました。
また、この実験では、外部検証のために 3 つの独立した機関から取得した 44,098 のデータ ポイントも使用され、すべてがテストに使用されました。詳細は以下のとおりです。
* 外部データセット1: 6,997件の腹部CTスキャンを含む
* 外部データセット2: 25,986件の腹部CTスキャンが含まれています
* 外部データセット 3: 腹部 CT スキャン 4,872 件と胸部 CT スキャン 6,243 件が含まれています。
腹部CTスキャン専用の公開データセットは他に2つあり、VerSeとTotalSegmentatorです。VerSeデータセットには160枚のCTスキャンが含まれ、TotalSegmentatorデータセットには401枚のCTスキャンが含まれています。これらのうち、選ばれた34枚のスキャンは、マルチタスク・マルチ疾患予測の事前学習とテストに使用され、残りの367枚のスキャンは、それぞれ学習用と検証用に80%(293枚)と20%(74枚)に分割されました。
マルチタスク学習と段階的なトレーニング戦略、差別化されたソリューションにより、Merlin の高い効率性が保証されます。
モデルアーキテクチャの観点から言えば、Merlin は、画像エンコーダーとテキスト エンコーダーで構成されるデュアル エンコーダー アーキテクチャを採用することで、画像とテキストの位置合わせを実現します。画像エンコーダーはI3D ResNet152を使用しています。これは、2次元事前学習済みモデルの重みを「インフレーション」によって再利用し、3次元畳み込みカーネルの3次元目にコピーします。本論文で使用したエンコーダーはClinical Longformerです。これは、他の生物医学事前学習済みモデルや一般的なCLIPエンコーダーよりも長いテキストに対応しており、4,096の長いコンテキストをサポートし、長文レポートのニーズに適応します。
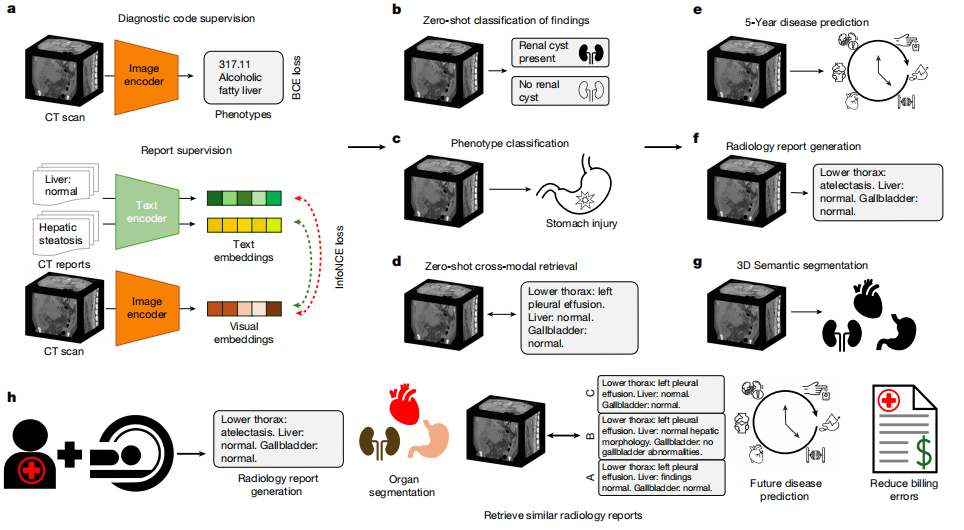
モデルトレーニングでは、Merlin は表現型分類と放射線学的レポートをそれぞれ処理するために 2 つの損失関数を使用します。バイナリクロスエントロピー損失関数は表現型分類に使用され、InfoNCE 損失関数は放射線レポートのコントラスト学習に使用されました。画像とテキストの両方の埋め込み次元は、OpenCLIP実験のViT-Baseモデルで使用された埋め込み次元と一致するように、一律に512に設定されました。その後、学習戦略において、ビジュアルエンコーダとテキストエンコーダの両方で勾配チェックポイントが有効になり、FP16混合精度学習が採用されました。
使用した最適化器はAdamWで、初期学習率は1 x 10⁻⁵、β = (0.9, 0.999)でした。コサイン学習率スケジューラを採用し、学習率が0に減衰する訓練エポック数を300に設定しました。ハードウェアは48GBのA6000 GPU 1基で、最大バッチサイズは18でした。
EHR表現型と放射線学的レポートをマルチタスク方式で使用してトレーニングすることに加えて、この研究では段階的なトレーニング プログラムも検討されました。具体的には、Merlin画像エンコーダは、まず第一段階でEHR診断コードを用いて学習され、次に第二段階では放射線学的報告書を用いて比較学習されます。第一段階で学習されたEHR情報が忘れ去られないように、第二段階の学習では表現型損失関数の重みを低く設定します。
最初のステージでは、初期学習率が 1 x 10⁻⁴、β = (0.9、0.999) の AdamW オプティマイザー、γ = 0.99 の指数学習率スケジューラ、およびバッチ サイズが 22 の単一の A6000 GPU を使用します。第 2 ステージで使用されるハイパーパラメータは、マルチタスク トレーニングで使用されるものと同じです。
要約すると、マルチタスク学習と段階的訓練は、2つの戦略において差別化された設計を実現し、研究チームは段階的訓練において忘却防止の改良を行いました。この差別化された訓練戦略は、Merlinの効率性と厳密性を保証する中核的な設計であり、その後のアブレーション実験でさらに検証されました。
752 のタスク カテゴリを総合的に評価した結果、Merlin が他のすべてを上回っていることが示されました。
実験プロセスにおいて、研究チームは 5,137 枚の CT スキャンに基づく内部検証と、44,098 枚の CT スキャンおよび腹部 CT スキャンに重点を置いた 2 つの公開データセット (VerSe と TotalSegmentator) に基づく外部検証を実施しました。評価タスクには合計 6 つの主要カテゴリがあり、752 の特定のサブタスクをカバーしています。主なタスク カテゴリには、ゼロ ショット分類 (31 のサブタスク)、表現型分類 (692 のサブタスク)、ゼロ ショット クロスモーダル検索 (23 のサブタスク)、5 年間の疾患予測 (6 つのサブタスク)、放射線レポート生成、および 3D セグメンテーションが含まれます。
ゼロショットの所見分類タスクでは、内部および外部の臨床データからの 30 個の腹部 CT スキャンが分析されました。Merlin は、内部検証データセット (95% の信頼区間、0.727 ~ 0.755) で F1 スコア 0.741 を達成し、外部検証データセット (95% の信頼区間、0.607 ~ 0.678) で平均 F1 スコア 0.647 を達成しました。これらのスコアは、k=1プーリングを用いた2D OpenCLIPモデル、および平均プーリングを用いて微調整された2D BioMedCLIPモデルと比較して有意に高かった(P < 0.001)。下の図をご覧ください。
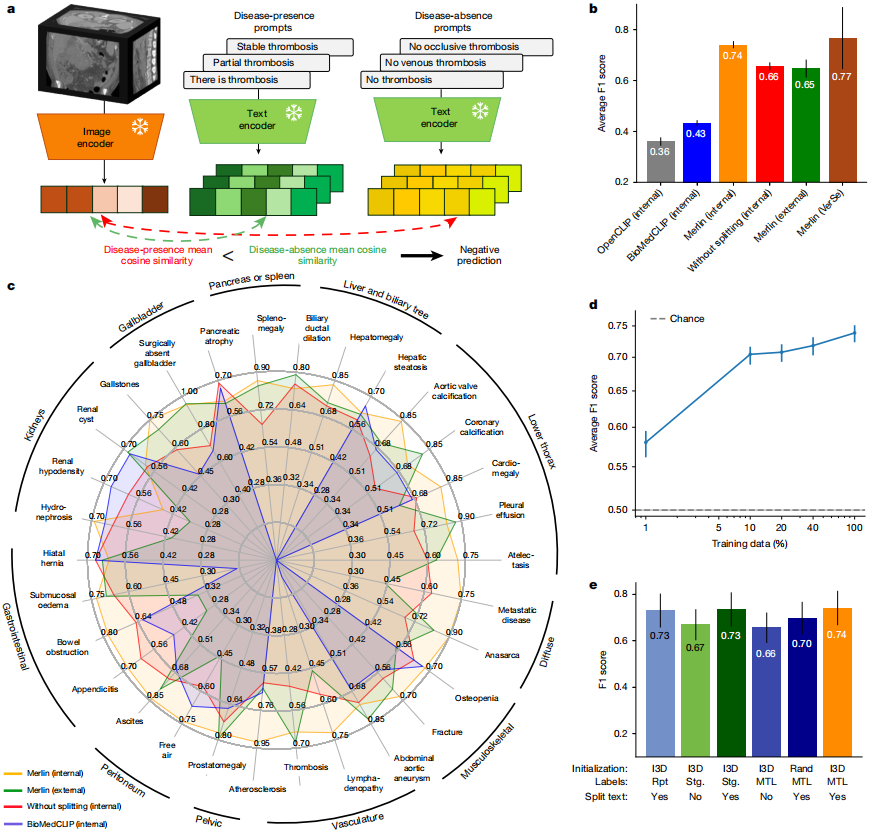
質的な観点から見ると、Merlin は、胸水や腹水などの重要な特徴を持つ疾患の外部データセットで高いパフォーマンスを維持します。しかし、虫垂炎やリンパ節腫脹といった微細な特徴の検出においては、パフォーマンスがわずかに低下します。さらに、放射線レポートのセグメンテーションを行わない場合、Merlinは外部評価データセットにおいて平均F1スコア0.656(信頼区間95%)を達成しました。
アブレーション実験の比較において拡張 3D ネットワークで初期化された Merlin モデルは、最高のパフォーマンスを示します。F1スコアは0.741(95%の信頼区間、0.727~0.755)であった。放射線レポートをセグメント化すると、EHRと放射線レポートを組み合わせたモデルスコアは0.735(95%の信頼区間、0.719~0.748)となった。放射線レポートのみを使用し、レポートセグメント化を実施したスキームは、F1スコア0.730(95%の信頼区間、0.714~0.744)で3位となった。放射線レポートのセグメント化の有無がモデルのパフォーマンスに最も大きな影響を与え、レポートセグメント化を行わない場合、MerlinモデルのF1スコアは平均7.9ポイント低下した(P < 0.01)。
また、言及する価値があるのはゼロショット Merlin は、10% と 100% の両方のトレーニング データでの教師あり実験において、すべての教師ありベースラインを上回りました。100%のトレーニングデータを使用した場合、F1スコアは29%向上しましたが、10%のトレーニングデータを使用した場合は、驚異的な45%向上しました。実験では、100%のトレーニングデータを使用した場合、ゼロショットMerlinは教師ありMerlinを大幅に上回り、F1スコアが16%向上することが実証されました。
表現型分類タスクにおいて、PheWASで定義された692の臨床表現型を予測する際のMerlinの性能が評価され、受信者動作特性(AUROC)のマクロ平均下面積は0.812(95%信頼区間、0.808~0.816)に達しました。AUROC値が0.85を超えた表現型は合計258個、AUROC値が0.9を超えた表現型は102個でした(下図参照)。
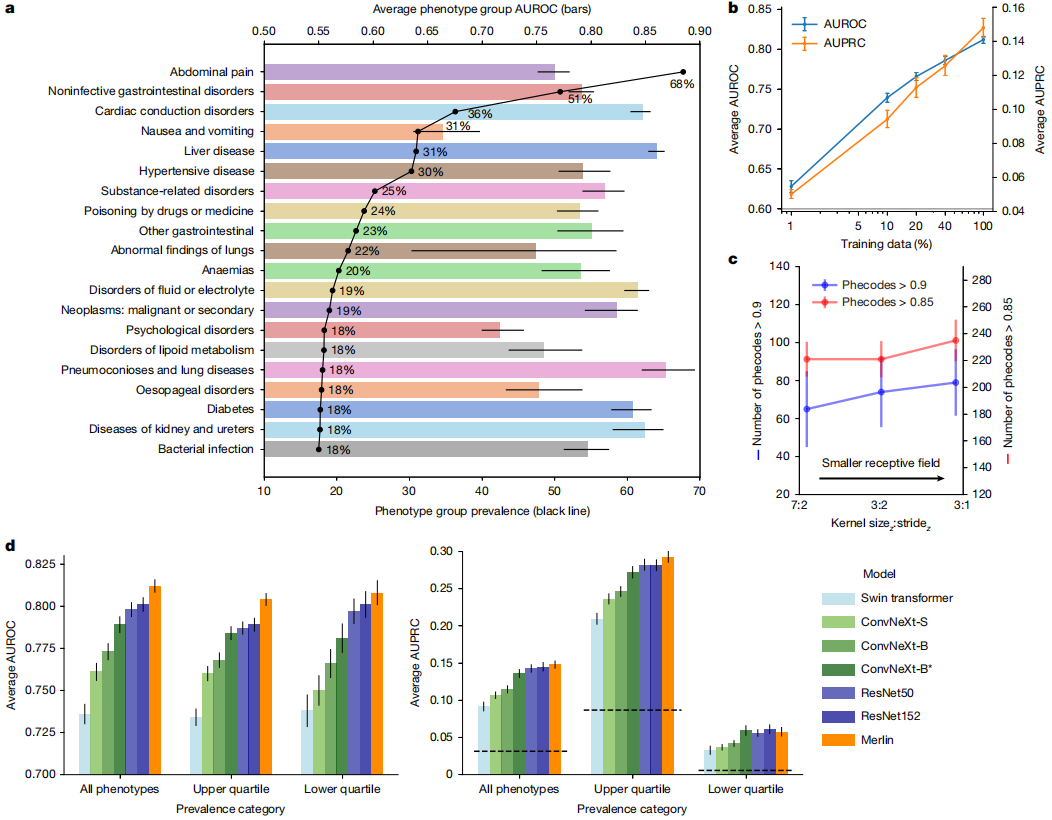
社内テストで最も発生率の高い上位20の最も一般的な表現型を分析すると、Merlin は、肝臓、腎臓、尿管、消化管など、複数の臓器系の疾患の検出に優れています。
ゼロショットクロスモデル検索タスクでは、最初のステップとして、64 のケースを含む「画像発見」に基づく検索タスクが行われます。Merlin は、OpenCLIP および BioMedCLIP に比べて大きな利点があります。これはMerlinが使用しているClinical Longformerテキストエンコーダのおかげです。OpenCLIPとBioMedCLIPでは、それぞれ最大77と256のトークン長が許容されています。一方、Merlinの優れた性能は、64症例に基づく「発見画像」検索タスクでも再現されました。下の図をご覧ください。
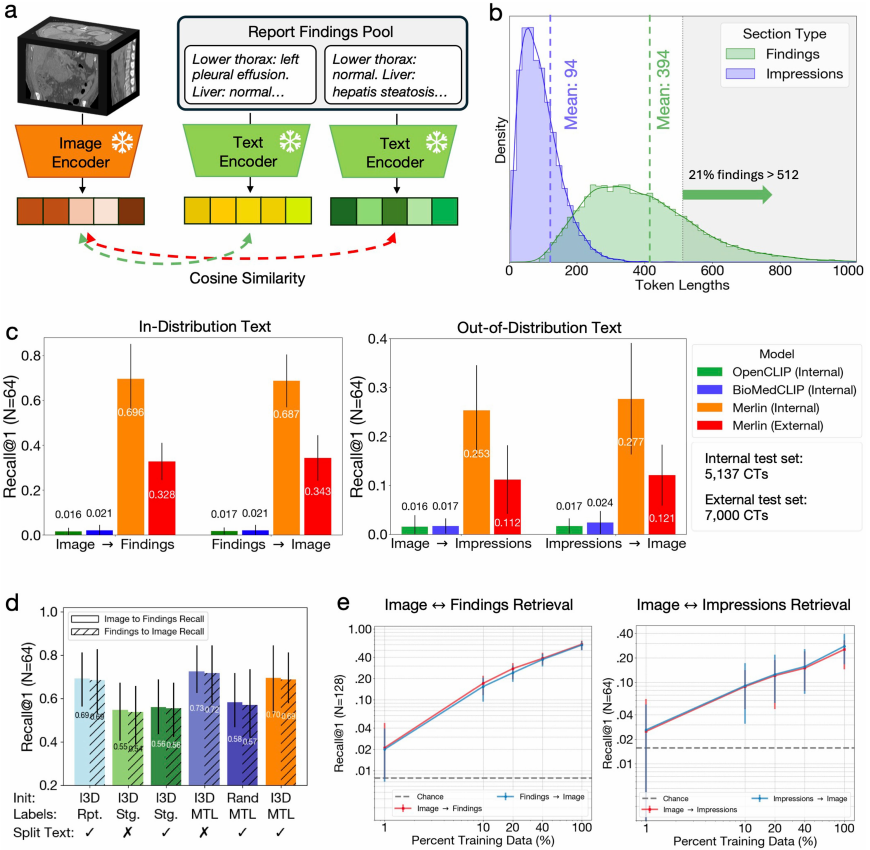
さらに重要な証拠は、マーリンが視覚言語アライメント訓練の報告書で客観的に記述された「発見」のみを使用した場合でも、高度に一般化されたレポートの「インプレッション」を扱う場合でも、高度なクロスドメイン一般化能力を発揮します。その後、リバースエンジニアリングタスクで結果が再度検証されました。さらに、Merlinの外部テストデータセットにおける検索性能は内部テストデータセットと比較して低下したものの、それでも他の外部ベースラインと比較すると5~7倍優れていました。
複数疾患の 5 年間予測タスクでは、実験では、今後 5 年間に健康な患者が慢性腎臓病、骨粗鬆症、心血管疾患、虚血性心疾患、高血圧、糖尿病など複数の主要な慢性疾患を発症するリスクについての Merlin の予測を評価しました。
Merlin を微調整し、100% ダウンストリーム ラベルを使用した結果、5 年以内の疾患発生率を予測する AUROC 値は 0.757 (95% の信頼区間、0.743 ~ 0.772) に達しました。このパフォーマンスは、画像のみを使用する ImageNet 事前トレーニング済み (I3D) モデルよりも 71 TP3T 高くなります。10%ラベルのみを使用した場合でも、Merlinの5年以内の疾患発生率予測におけるAUROCは0.708(95%の信頼区間、0.692~0.723)に達し、ImageNetの事前学習済みモデルの4.4%を上回りました。下の図をご覧ください。
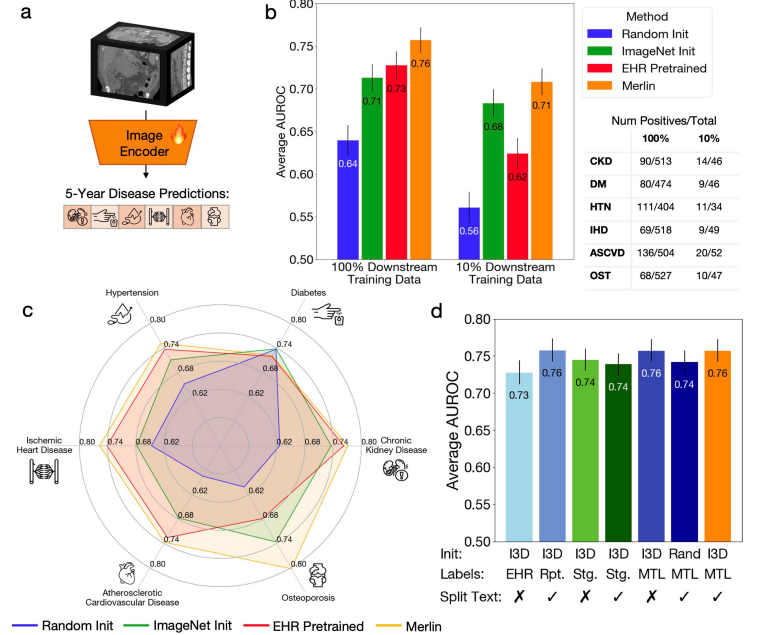
加えて、トレーニング データの 1/10 のみを使用した場合でも、Merlin の予測パフォーマンスは、100% のデータでトレーニングされた ImageNet 事前トレーニング済みモデルの予測パフォーマンスに匹敵します。これは、Merlin のゼロショット機能と強力な転送能力を大いに実証しています。
放射線レポート作成タスクでは、ベースラインモデルRadFMと比較して、RadGraph-F1、BERTスコア、ROUGE-2、BLEUなどの定量的指標に基づくテストで、Merlin は、解剖学的論理構造と完全なレポート結果のあらゆる面で前者を上回っています。
品質面では、Merlinは診断、病変部位の特定、症状の説明において非常に正確な優れたレポートを生成します。しかしながら、Merlinは時折、手動生成レポートとCTレポートの両方で見られる問題点を過小評価するなど、保守的な判断を下すことがあります。これは、CTスキャンから生成された放射線レポートの初期段階のデモンストレーションによるもので、レポートの品質向上に伴い、さらに改善される予定です。
3D セマンティック セグメンテーション タスクでは、101 TP3T のトレーニング データのみを使用した場合、Merlin は nnUNet フレームワークよりもマクロ平均 Dice スコアで 4.71 TP3T 優れています。1001 TP3T のトレーニング データを使用した場合、nnUNet フレームワークは Merlin の初期モデルよりもわずかに優れていますが、Dice スコアの差はわずか 0.006 です。
テスト セットの 20 個の臓器について、Merlin は 10% データでトレーニングした場合、12 個の臓器で nnUNet フレームワークよりも高い Dice スコアを達成し、前立腺のセグメンテーションでは最大 41% の改善が見られました。
さらに、外部検証試験では、研究チームは 100,000 件を超える外部 CT スキャンのデータセットを使用して、合計 44,098 件の外部 CT スキャンで Merlin を評価しました。トレーニング データセットと外部テスト データセット間の分布オフセットを克服し、さまざまな部位や解剖学的位置にわたって安定した正確なパフォーマンスを発揮します。さらに、そのパフォーマンスは一貫して他のベースライン モデルを上回り、胸部タスクでは特殊な胸部 CT ベースライン モデルをも上回りました。
視覚言語モデルは、大規模なマルチモーダル医療データの潜在的な価値を解き放ちます。
この研究に加え、医療分野における視覚言語モデルに関する成果も次々と発表されています。例えば、スタンフォード大学の研究チームは、視覚言語の基本モデルであるMUSK(Multimodal Transformer with Unified Masked Modeling)を提案しました。これは大規模なラベルなし、ペアなしの画像とテキストデータを統合することを目的としています。
論文タイトル: 精密腫瘍学のための視覚言語基盤モデル
用紙のアドレス:
https://www.nature.com/articles/s41586-024-08378-w
上海交通大学などが提案する知識強化型事例ベースモデルKEEPは、既存のモデルが主にデータ駆動型アプローチに依存し、医学知識の明確な統合が欠如しているという問題に対処します。このモデルは、11,454の疾患と139,143の属性からなる包括的な疾患知識グラフを活用し、数百万もの病理学的画像とテキストのペアを、疾患オントロジー階層構造に沿って意味的に構造化された143,000のグループに再編成します。この知識強化型事前学習手法は、視覚的表現とテキスト表現を階層的な意味空間に整合させることで、疾患の関係性と形態学的パターンの深い理解を実現します。
論文タイトル: 癌診断における視覚言語病理学基礎モデルのための知識強化型事前学習
用紙のアドレス:
https://www.sciencedirect.com/science/article/pii/S1535610826000589
まとめると、クロスモーダル理解能力を備えた視覚言語モデルは、医学および放射線医学の分野で大きな可能性を示しています。医用画像、症例テキスト、臨床ガイドラインを統合することで、インテリジェントな病変特定、症例分析支援、診断レポートの自動生成を実現できます。これは医師に効率的な補助ツールを提供するだけでなく、疾患予測に関する新たな知見をもたらし、現代医療を「経験主導型」から「データ主導型」へと転換させる力となります。