Command Palette
Search for a command to run...
ICLR 2026 | NVIDIA/オックスフォード大学などが、最先端(SOTA)性能を持つ原子レベルのタンパク質結合剤生成方法を提案。

計算生物学の分野では、特定の標的に正確に結合できるタンパク質を設計することは、最も重要かつ困難な課題の一つである。これは、医薬品開発、生物療法、酵素工学といった主要分野に直接関係するだけでなく、複雑な疾患への介入やバイオ製造における人間の効率の上限を決定するものでもある。
分子レベルで見ると、タンパク質が標的に結合することは、本質的に三次元構造の問題である。アミノ酸組成、立体構造、および界面の分子間相互作用が総合的に結合の親和性と特異性を決定する。したがって、ほぼすべてのバインダー設計手法は、最終的には「構造」という中心的な変数に立ち返り、構造解析や予測を用いて分子構築を導くことになる。
近年、機械学習の導入により、このパラダイムは大きく変化しつつあります。構造予測モデルや構造生成モデルにおける画期的な進歩により、研究は実験的な構造への強い依存から徐々に脱却し、「構造の分析」から「構造の生成」へと移行しています。これにより、バインダーをゼロから設計することが可能になり、研究開発のコストと時間を大幅に削減できるようになりました。
しかし、方法論の面では、現在のAI駆動型バインダー設計には依然として明確な相違点が見られる。その一つが生成手法であり、RFDiffusionに代表される。候補構造を直接生成するために大規模なトレーニングに依存しているが、推論段階で柔軟に調整する能力に欠けている。もう一つのタイプは、BindCraftに代表されるような、錯覚を利用した手法です。構造予測器のスコアリングによる勾配最適化は柔軟性を提供するものの、生成的な事前情報が欠如しているため、全く新しい構造空間を探索することは困難である。この「生成と最適化の分離」は、自然言語処理や画像処理の分野ですでに確立されている「事前学習済みモデル+推論時の計算拡張機能」という統一的なパラダイムとは対照的である。
このような状況において、NVIDIA、オックスフォード大学、ケベック人工知能研究所、およびその他の機関からなる共同研究チームは、プロテイン複合体(以下、複合体と呼ぶ)フレームワークを提案した。生成手法と錯覚手法の間のギャップを埋めることを目的としたこのアプローチは、基本的な生成モデルと推論時の最適化メカニズムを単一のシステム内に統合します。これはTeddymerの事前学習に基づいています。Complexaは、追加の配列再設計ステップを必要とせずに、最先端の新規結合剤設計を可能にします。拡散モデルのテスト時間スケーリング技術をこのフレームワークに適用することで、生成と最適化が直接的に統合され、従来の錯覚ベースの手法よりも性能面で優れている。
「生成型事前学習とテスト時計算による原子レベルのタンパク質結合設計のスケーリング」と題された関連研究成果が、ICLR 2026に採択されました。
研究のハイライト:
* 本研究では、La-Proteinaをバインダー設計に拡張し、Teddymerを利用し、生成事前分布によって加速された効率的な推論時間最適化を実現するComplexaを提案する。
* 配列の再設計を必要とせずに、タンパク質および低分子標的、酵素設計のベンチマークにおいて、最先端のコンピュータシミュレーション成功率を達成しました。
用紙のアドレス:
https://openreview.net/forum?id=qmCpJtFZra
弊社の公式WeChatアカウントをフォローし、バックグラウンドで「Complexa」と返信すると、PDF全文を入手できます。
データセット:「単一ユニット濃縮」から「複合体再構築」まで
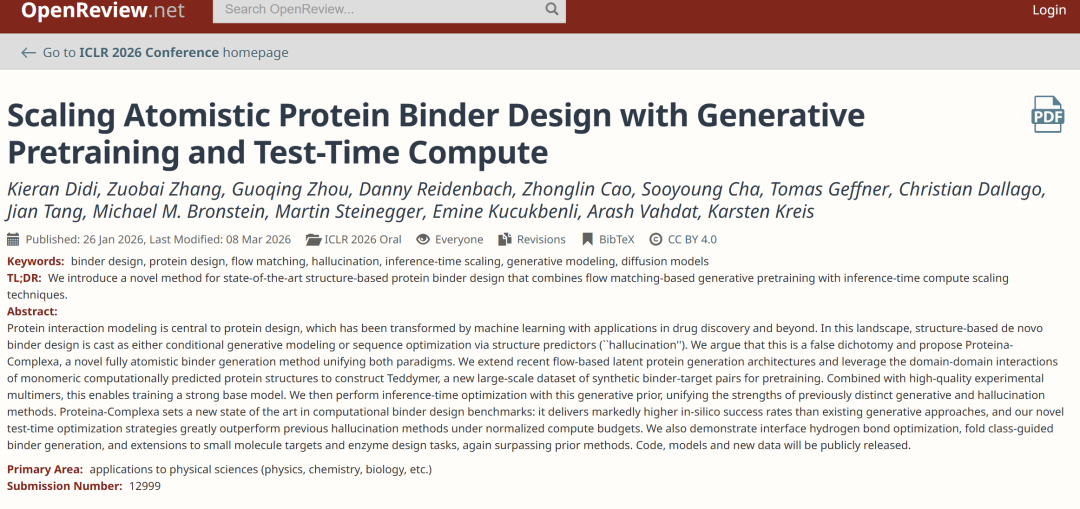
結合剤生成モデルの根本的な限界はデータにある。理想的には、モデルのトレーニングには大量の「結合剤-標的複合体」データが必要となるが、実際には、この種のデータは主に実験的に解析されたタンパク質データベース(PDB)から得られるものであり、その規模は限られており、高品質のサンプルはさらに少ない。一方、より大規模なAlphaFoldデータベース(AFDB)は膨大な量のタンパク質構造を提供しているが、それらのほとんどは単量体構造であり、複合体に関する情報が不足している。「個々の構成要素は豊富だが、複雑な構成要素は少ない」という構造的なギャップは、モデルを大規模に学習させる能力を直接的に制限する。
この研究の重要なブレークスルーは、AFDBの内部構造に関する新たな理解から得られたものです。AFDBに含まれるタンパク質のほとんどはマルチドメインタンパク質であり、ドメイン分割ツールTEDはそれらに詳細なアノテーションを提供します。さらに分析した結果、同じタンパク質内の異なるドメイン間の相互作用は、多重鎖複合体における相互作用と統計的に類似した特性を示すことが明らかになりました。この観察結果は、重要な転換点につながります。モノマー構造はそれ自体が「役に立たないデータ」ではなく、複雑な構造に関する潜在的なデータ源として再解釈することができる。
この知見に基づき、本研究は「人工マルチマー構築」の方法を提案する。多ドメインタンパク質を独立したドメインに分解し、それぞれを異なる鎖として扱うことで、モノマー内部に複合体のような構造を構築することができる。具体的なプロセスはAFDB50から始まり、TEDアノテーションを持つタンパク質をスクリーニングし、それらを「擬似マルチマー」に分割し、さらにダイマーを抽出し、空間的な近接性に基づいてフィルタリングし、完全なアノテーションを持つサンプルを保持します。最後に、冗長性を除去するためにクラスタリングを行い、約350万個のダイマークラスターを取得します。このデータセットはTeddymerと名付けられ、その本質は単にデータ規模を拡大することではなく、構造再編成を通じて「モノマーの利点」を「複合供給」へと転換することにあります。
下の図に示すように、トレーニングプロセスでは、単一のデータソースに依存するのではなく、AFDBモノマーデータ、テディマー構築データ、PDB実験複合体データ、およびPLINDERタンパク質-リガンドデータを統合し、モデルがモノマー構造、複合体構造、および小分子相互作用の間で統一的な表現を確立できるようにすることで、生成能力と汎化能力の両方を考慮に入れました。
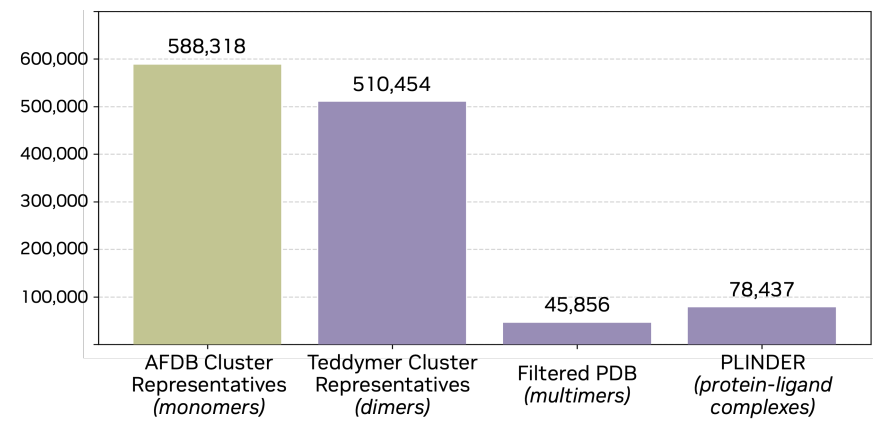
Complexa:タンパク質結合剤生成のための完全原子フレームワーク
モデル設計の観点から見ると、Complexaにおける核心的な変化は、単に「生成能力の向上」ではなく、生成対象が「完全なタンパク質構造」から「特定の界面における結合剤」へと移行したことにある。La-Proteínaを基盤とするComplexaの利点は、原子レベル全体で生成できる点にある。同時に、効率的なTransformerアーキテクチャに基づいているため、従来の構造モデルにおける計算コストの高いモジュールを回避し、大規模なサンプリングシナリオにおいて優れた拡張性を実現しています。
この研究は、これを基に、ターゲットポイントとインターフェースホットスポットを条件とする生成メカニズムを導入する。このメカニズムは、モデルが完全な複合体を生成するのを防ぎ、代わりに結合部分のみを生成し、生成プロセス中にターゲット情報に明示的に依存する。具体的には、フローマッチングモデルは条件付き制約の下で構造を生成する役割を担い、オートエンコーダーはモノマーバインダーのエンコードとデコードにのみ使用されるため、表現力を維持しながらモデリングの複雑さを軽減できる。
モデルがターゲット情報を効果的に理解できるように、入力表現の体系的な設計が実装されました。タンパク質ターゲットはAtom37メソッドを使用してエンコードされ、残基レベルの3D座標、アミノ酸タイプ、およびインターフェースホットスポット情報がモデルに一律に入力されました。ホットスポットは潜在的な結合領域を示します。トレーニング中は、これらのホットスポットは実際のインターフェースから抽出され、推論中は、事前情報として使用されるか、前処理によって取得されました。低分子ターゲットの場合、モデルは原子レベルでタイプ、電荷、および空間座標をエンコードし、これらは結合剤表現とともにTransformerに入力され、共同モデリングが行われました。
研修目標に関して、重要な改善点は、結合体の座標にランダムなグローバル並進ノイズを導入することで、モデルに分子の空間的局在化能力を学習させることである。これはモノマー生成においては重要ではありませんが、バインダーをターゲット界面に正確に配置する必要があるタスクにおいては、生成品質を左右する重要な機能です。トレーニングプロセス全体は段階的な戦略を採用しており、モノマーモデリングから一般的な構造生成、そしてバインダー固有のトレーニングへと段階的に進んでいきます。同時に、LoRAによって過学習が抑制され、モノマーレベルのオートエンコーダーはアーキテクチャをシンプルに保つために繰り返し使用されます。
推論段階では、Complexaはさらに、「テスト時計算拡張」メカニズムを導入しており、これは生成プロセスと探索最適化を組み合わせたものである。サンプル数を増やしたり、バンドルサーチやモンテカルロツリーサーチを導入したりすることで、モデルはより大きな計算予算の下で生成品質を継続的に向上させることができます。この設計により、モデルの機能はトレーニング段階のみに限定されることなく、推論中に動的に拡張することが可能になります。
成功率の向上、処理速度の向上、拡張性の向上
本研究では、モデルの性能を検証するために、単純なものから複雑なものまで、一連の実験を設計した。中心的な問いは、Complexaは基本的な性能において優れているだけでなく、計算リソースが増加するにつれて性能が向上し続けるのか、ということである。
基本的な発電能力に関して言えば、タンパク質を標的とする場合でも、低分子を標的とする場合でも、Complexaは既存の手法を大幅に凌駕し、より高い成功率とより速いサンプリング速度を誇ります。同時に、生成される構造の新規性も大幅に向上します。さらに重要なのは、このモデルはProteinMPNNなどの二次設計ツールに頼ることなく、高品質な配列を直接出力できるため、プロセス全体が簡素化される点です。
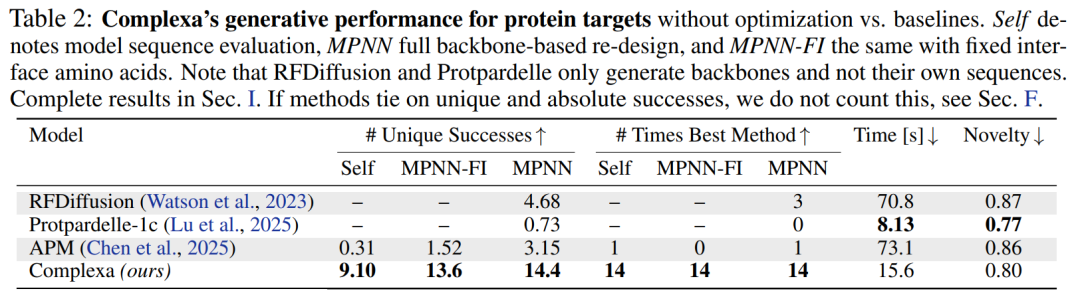
構造的な制御性の観点から言えば、本研究では条件付きラベルを導入することで、モデルが生成される構造の種類を明示的に制御できるようにした。例えば、αヘリックスとβフォールドのどちらかを選択することで、従来の生成モデルにおける単一構造の問題を効果的に軽減し、構造的多様性を大幅に向上させることができる。
推論段階における計算拡張実験の結果、単純なタスクではサンプル数を増やすだけで全てのベースライン手法を上回る性能を発揮することが示された一方、複雑なタスクでは、より高度な探索戦略(バンドル探索やモンテカルロ木探索など)を導入することで、その優位性がさらに拡大することが示された。これは、計算予算が増加するにつれて、モデルの性能が継続的に向上する可能性があることを示している。以下に示すように
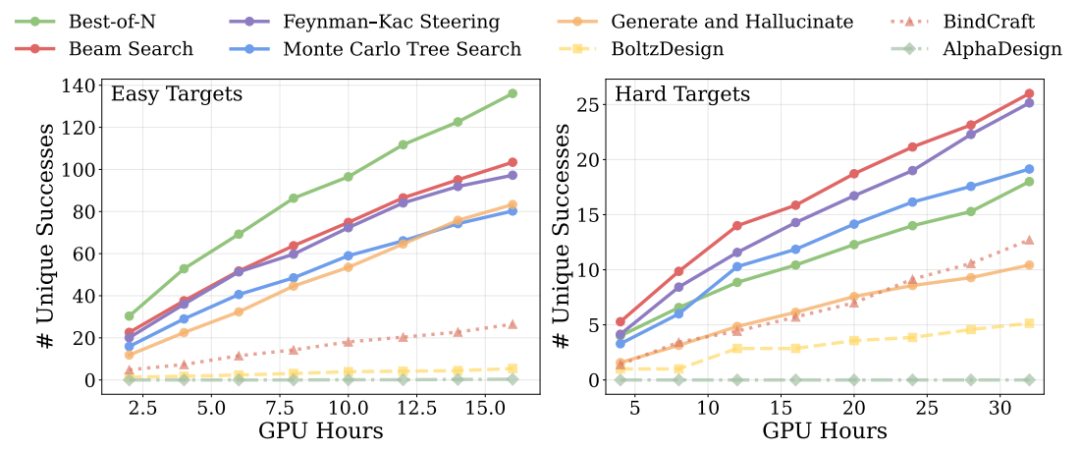
物理的な妥当性に関しては、界面水素結合および関連するエネルギー指標を最適化するためのさらなる研究が必要である。このモデルは、構造的に健全な結合剤を生成するだけでなく、微細な相互作用レベルでそれらを最適化できることがわかった。これにより、接合プロセスの安定性が向上します。
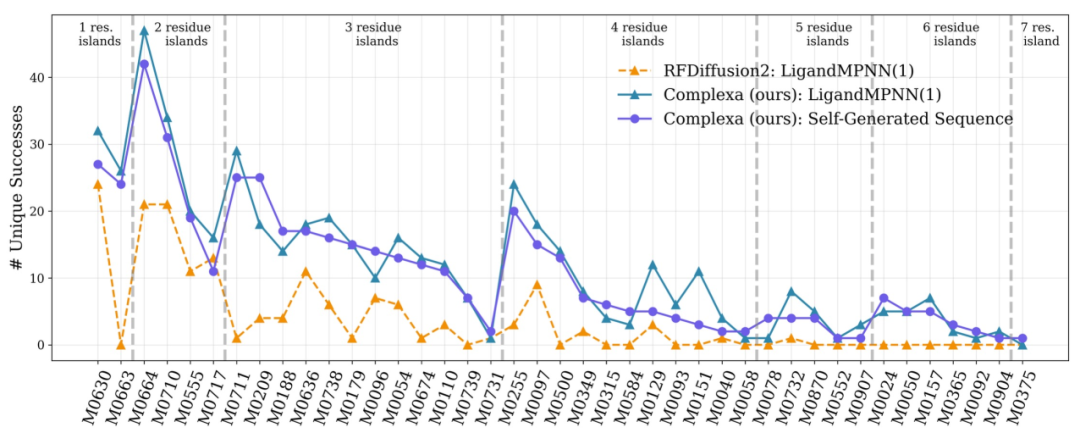
より複雑なマルチチェーンターゲットタスクにおいては、既存の手法では限られた計算予算内で効率的な解を得ることができない。Complexaは計算リソースを拡張した後、高品質な候補を生成することに成功し、複雑な問題におけるスケーラビリティを実証した。最後に、酵素設計などの様々なタスクにおけるテスト結果を下図に示す。このフレームワークは優れた汎用性を持ち、結合剤設計からより広範なタンパク質工学の問題へと拡張可能である。
AIタンパク質設計におけるパラダイムシフト
近年、AIを活用したタンパク質結合剤の設計は、理論から実践へと急速に移行しており、ノーベル賞受賞者のデビッド・ベイカー氏とそのチームは、この分野における主要なリーダーであり続けている。2025年には、彼らのチームは科学誌『サイエンス』に複数の研究論文を発表した。このシステムは、RF拡散に基づいて高特異性pMHC結合分子を設計する実現可能性を検証した。関連研究では、11の疾患カテゴリーを対象とし、T細胞が腫瘍を認識するように促す結合タンパク質の生成に成功し、クライオ電子顕微鏡を用いて原子レベルでの設計精度を検証することで、AI設計の検証可能性の始まりを示した。
一方、MITの研究チームは、BoltzGenモデルにおいて、より統合的なアプローチを模索し、構造予測と凝集体生成を単一の全原子モデルに統合し、従来の離散的なモデリングではなく連続的な幾何学的表現を用いることを試みた。26種類の標的を対象とした実験において、66%は結合剤としてナノモル濃度の親和性を示した。また、配信対象外のターゲットに対しても高い成功率を維持しており、一定の汎化能力を示している。
業界は、これらの機能のエンジニアリング実装により重点を置いている。2026年初頭、バイエルとクレードルは、AIタンパク質エンジニアリングプラットフォームを抗体開発プロセスに統合するための3年間の共同研究を開始した。このプラットフォームは50以上のプロジェクトに適用され、開発サイクルを大幅に短縮し、「設計・テスト・学習」というクローズドループの反復プロセスをサポートしている。これは、AIが研究開発プロセスにおいて補助ツールから基本的な機能へと移行しつつあることを示している。
タンパク質設計における競争は、全体として、単一モデルの性能からシステムレベルの効率性と拡張性へと移行しつつある。学術界はモデル能力の限界を押し広げ続けており、産業界はそれを安定した再利用可能な研究開発プロセスへと導いている。したがって、AIによるタンパク質設計はより実践的な段階に入りつつあり、もはや重要なのは「設計できるかどうか」ではなく、「継続的かつ効率的に設計できるかどうか」である。
参考リンク:
1.https://news.bioon.com/article/00bf92186439.html
2.https://mp.weixin.qq.com/s/1zKXUQtXgCJ7GA1_OUEShg
3.https://www.bayer.com/en/us/news-stories/ai-enabled-antibody-discovery-and-optimization








