Command Palette
Search for a command to run...
AIが118個の新たな系外惑星を発見しました!ウォーリック大学の研究チームは、惑星の存在シナリオと誤検出シナリオを1対1で比較できるRAVENというシステムを提案しました。

天文学研究の継続的な進歩に伴い、系外惑星の発見は急速な発展段階に入った。特に、NASAのトランジット系外惑星探査衛星(TESS)ミッションが提供する光度曲線データにより、科学者たちは毎日多数のトランジット信号候補を取得できるようになった。
しかし、候補天体の惑星としての特性を確認または否定することは、時間と労力を要する困難なプロセスです。現在までに、系外惑星アーカイブには7,658個のTESS(遠隔探査対象天体)ターゲット(TOI)が登録されており、そのうち5,152個が依然として候補天体として指定されています。真の系外惑星として確認されたのはわずか666個で、さらに558個はTESSによって検出されたものの、以前に確認済みである。一方、TESSの候補天体のうち1,185個が「偽陽性(FP)」と判定され、さらに97個が「誤報(FA)」と分類された。これほど多くの誤報は、系外惑星候補の確認がいかに難しいかを物語っている。
候補惑星の選定よりもさらに一歩進んだのが「検証パイプライン」であり、これは統計的手法を用いて候補惑星が実在する惑星であることを確認することを目的としている。従来の検証方法は、主に手動による分析とそれに続く観測に依存しており、これには視線速度(RV)測定や地上望遠鏡による追跡などが含まれる。これらの方法は信頼性は高いものの、時間とコストがかかる。
これに対し、ウォーリック大学の研究チームは、デイビッド・J・アームストロングらが提唱したケプラー過程を基に、TESS候補のための新たなスクリーニングおよび検証プロセスであるRAVEN(RAnking and Validation of ExoplaNets)がさらに開発されました。新しいプロセスにおける最も重要な変更点は、合成トレーニングデータセットの導入です。これにより、タスク自体によって生成される閾値超過(TCE)イベントデータのみに依存する必要がなくなりました。この改善により、機械学習モデルがカバーする惑星および偽陽性シナリオのパラメータ空間が大幅に拡大・強化されます。
結果は次のようになります。この手順は、偽陽性のシナリオすべてにおいて971 TP3Tを超えるAUCスコアを達成したが、1つのシナリオでは991 TP3Tを超えた。1,361個の事前分類済みTESS候補を含む独立した外部テストセットにおいて、このワークフローは91%の全体精度を達成し、TESS候補の自動ランキングにおける有効性を実証した。
研究者たちはこの手法を用いて118個の新たな系外惑星を確認するとともに、2000個以上の質の高い惑星候補を特定した。そのうち約1000個はこれまで発見されたことのないものだった。
関連する研究成果は、「RAVEN:ExoplaNetsのランキングと検証」と題され、arXivにプレプリントとして公開されています。
研究のハイライト:
* RAVENは合成データセットを活用することで、惑星シナリオと各偽陽性シナリオとの1対1の比較を可能にします。これは従来、モデル適合に依存する検証フレームワークでのみ見られた機能です。
この新しいプロセスでは、合成トレーニングデータセットが導入され、タスク自体によって生成されるTCEデータのみに依存することはなくなります。
この新しいプロセスは高い運用効率を維持しており、一般的な候補者の処理には約1分しかかからず、マルチプロセス対応により優れた拡張性も備えている。
用紙のアドレス:https://arxiv.org/abs/2509.17645*
弊社の公式WeChatアカウントをフォローし、バックグラウンドで「TESS」と返信すると、PDF全文を入手できます。
データセット:入力データからトレーニングサンプルまでの完全な構築パス
入力データ:光度曲線を中心とした複数ソースの情報融合。
RAVENワークフローでは現在、TESS科学処理運用センターが公開するTESSフルフレーム画像(FFI)から生成された光プロファイルを使用しています。これらの光プロファイルは、各観測セクターのFFIデータから開口測光を用いて抽出され、セクター1~27では30分、セクター28~55では10分のサンプリングレートとなっています。TESS第2次延長ミッション(セクター56から開始)で公開されたFFIデータのサンプリングレートは200秒です。本研究で使用した光プロファイルはセクター55で終了しています。
トレーニングデータ:惑星の体系的なモデリングと偽陽性
RAVENプロセスでは、タスクにおいて既存の分類済み候補光度曲線データに依存する代わりに、機械学習モデルのトレーニング用に合成光度曲線データを導入します。
初期の複合イベントセットでは、シミュレーションされたトランジットまたは食を使用し、それらをSPOC光度曲線に組み込みました。シミュレーションされたイベントは、研究者のPASTISソフトウェアの改良版を使用して生成され、当初はトランジット惑星(Planet)、食連星(EB)、層状食連星(HEB)、層状トランジット惑星(HTP)、背景食連星(BEB)、背景トランジット惑星(BTP)などのシナリオが含まれていました。複合データが実際のTESS観測集団に近似するように、各シナリオの主星は、完全に特性が付けられたTESS入力カタログ(TIC)サンプルからランダムに選択されました。最終的に、ターゲットサンプルには1,200,520個のSPOC FFI星が含まれていました。
これを踏まえると、偽陽性データの構築はより複雑かつ重要になります。近傍偽陽性 (NFP) については、研究者は次の NFP シナリオを検討します。近傍トランジット惑星 (NTP):惑星がトランジットを起こし、主星を希釈します。近傍食連星 (NEB):近傍の希釈源は食連星です。近傍層状食連星 (NHEB):近傍の希釈源は層状食連星です。
テストデータ:TOIを中心とした実世界のアプリケーションシナリオ
このプロセスの性能は、既存の事前分類を持つ一連のTOI(すなわち、TESSの関心対象ターゲット)を用いて最終的にテストされた。テストで使用された TOI のリストと分類情報は、2025 年 2 月 3 日付けの NASA 系外惑星アーカイブから取得しました。当時、事前分類された TOI は 2,134 個あり、そのうち 548 個が既知惑星 (KP)、485 個が TESS 確認惑星 (CP)、1,113 個が FP、96 個が FA に分類されていました。しかし、関連する公開 SPOC FFI 光度曲線が付与されていた TOI は 1,918 個のみでした。最終的に、残りのサンプルに深度と周期的な制約を適用した後、処理対象となるTOIの総数は1,589個となる。
すべてのTOIは、TICでターゲット星が「重複」とマークされた1つのFP TOIを除いて、パイプライン処理の全ステップを受けました。最終結果では、ターゲット星の恒星半径がTICになかったため68個のTOIが除外され、TESS等級が13.5を超えたため87個が除外され、Gaia等級が14を超えたため22個が除外されました。
本研究で使用したトレーニングセットには、13.5 Tmag または 14 Gmag を超えるターゲット星を持つイベントは含まれていませんでした。さらに、特徴生成時に計算された MES が 0.8 未満であったため 28 個の TOI が除外され、特徴生成の失敗により 2 個の TOI が破棄されました。最後に、重心データによって位置確率の生成が妨げられ、事後確率が提供されなかったため、21 個の TOI は以降の解析から除外されました。
したがって、このテストで事前に分類されたTOIの最終数は1,361で、そのうち705は既知または確認済みの惑星、630はFP、26はFAでした。
2つの機械学習モデル(GBDT+GP)を組み合わせる
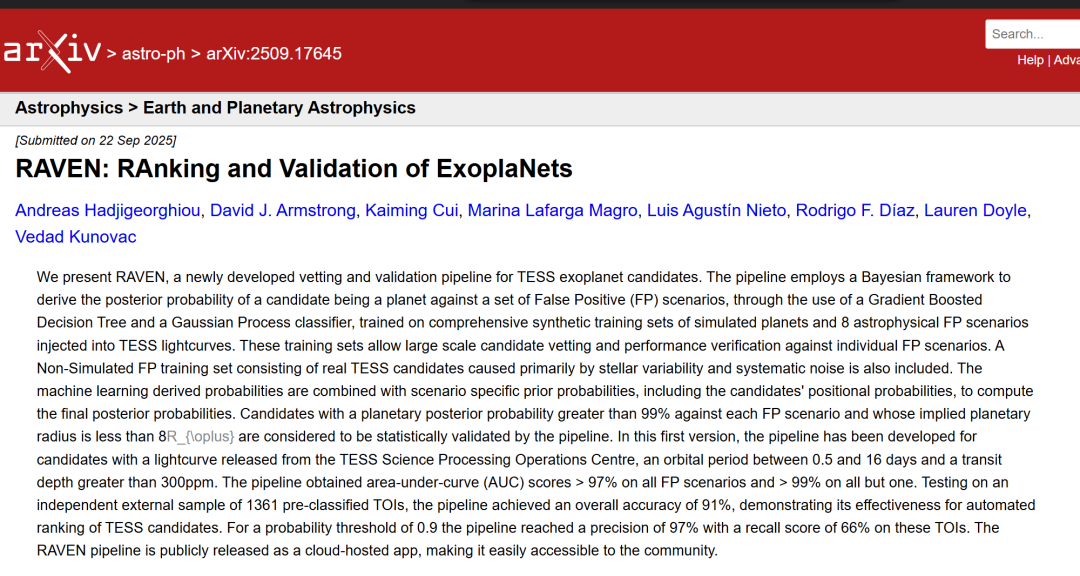
RAVENワークフローは、2021年にDavid J. ArmstrongらがKeplerミッション候補向けに提案した統計的検証フレームワーク(以下、A21と呼ぶ)に基づいています。このフレームワークは、トランジット系外惑星探査衛星(TES)のデータにも適用され、拡張およびアップグレードされています。ワークフロー全体の実装と運用は、複数のステップを含む比較的複雑なものです。簡略化されたフローチャートを以下の図に示します。
機械学習のトレーニング
RAVENの中核は、勾配ブースティング決定木(GBDT)とガウス過程(GP)という2つの機械学習モデルを組み合わせたものです。このプロセスでは、候補となる惑星ごとに8つの偽陽性シナリオに対する事後確率を生成し、最小値を取ることで、候補の信憑性に対する信頼度が最も低いRAVEN確率を取得します。
① 勾配ブースティング決定木(GBDT)
決定木は、シンプルでありながら強力な機械学習モデルの一種です。大きな利点は、解釈の容易さです。しかし、単一の決定木は堅牢性に限界があり、木の深さが大きすぎると過学習を起こしやすいという欠点があります。これらの問題を解決するために、複数の「弱い」木から構成されるアンサンブル手法が一般的に用いられます。勾配ブースティング決定木(GBDT)は、そのようなアンサンブル手法の一つであり、複数の決定木を順次構築することで、より強力な最終モデルを形成します。
GBDTの主な特徴は以下のとおりです。新たに生成される各ツリーは、元のラベルに基づいて直接学習されるのではなく、前のラウンドでモデル予測によって生成された残差誤差から学習する。つまり、各新規モデルの目標は、全体モデルの損失関数を最小化することであり、これは基本的に勾配降下法に似たプロセスです。アンサンブル処理では、各サブモデルの出力は学習率でスケーリングされ、最終的な予測値を得るために合計されます。
モデルの損失は、あらかじめ定義された損失関数を用いて計算され、残差はその損失関数の勾配によって決定されます。本研究では、ChenとGuestrinによって提案されたXGBoostを用いてGBDT分類器を実装しました。
② ガウス過程分類器
ガウス過程(GP)は、ガウス確率分布を「確率変数の分布」から「関数の分布」へと一般化した確率過程です。GP分類では、0から1の間の離散的なクラスラベルまたはクラス確率を出力することが目標となります。これを実現するために、GP出力に応答関数を適用し、結果を0から1の区間にマッピングします。そして、これを確率尤度関数(ベルヌーイ尤度など)と組み合わせます。
本研究では、James Hensmanらが提案した変分近似法を採用する。この方法は、データの代表的な部分集合である「誘導点」のセットを利用することで、計算の複雑さを軽減しつつ、モデルのスケーラビリティを向上させる。
トレーニングとキャリブレーション
2つの分類器を訓練および最適化するために、反復的なアプローチを採用しました。合成訓練セットを異なるハイパーパラメータの組み合わせで訓練し、検証セットで性能を評価して最適なパラメータを選択しました。パラメータ調整は、最も一般的な偽陽性イベントであるEB、NEB、およびNSFPの3つの主要な偽陽性シナリオに主に焦点を当てました。同時に、単一のシナリオの過剰最適化とそれに伴う過学習を避けるため、可能な限りシナリオ間でパラメータの一貫性を維持しました。
すべてのモデルで「早期停止」メカニズムが有効になっています。検証セットにおける損失関数が20回の連続した反復で少なくとも0.0001減少しない場合、トレーニングは終了し、検証セットにおける損失関数の最後の改善時点のモデルの状態に戻ります。
統計的検証
このプロセスの最終段階では、機械学習によって得られた各惑星-FPカテゴリの確率と、それに対応するシナリオ固有の事前確率を組み合わせることで、惑星仮説の事後確率を導出します。この事後確率は、候補が惑星であるか、特定のFPシナリオである確率のみを表します。したがって、研究者らの統計的検証方法では、候補が検証済みとみなされるためには、8つの惑星-FPカテゴリそれぞれについて、事後確率が0.99を超える必要があります。
RAVENは、実際の惑星候補の選別、順位付け、検証において優れた性能を発揮する。
RAVENの性能を評価するため、研究者らはトレーニングセットとテストセットの両方で以下の検証を行った。
研究者らはまず、トレーニングセットの未知のサブセット(各シーンからランダムに選択され、トレーニング前に個別に分離された101個のTP3Tイベントで構成)でモデルの性能をテストした。モデルの性能は、精度、ROC曲線下面積(AUC)、適合率、再現率という4つの主要な指標を用いて評価された。性能テストの結果は以下の表に示す。
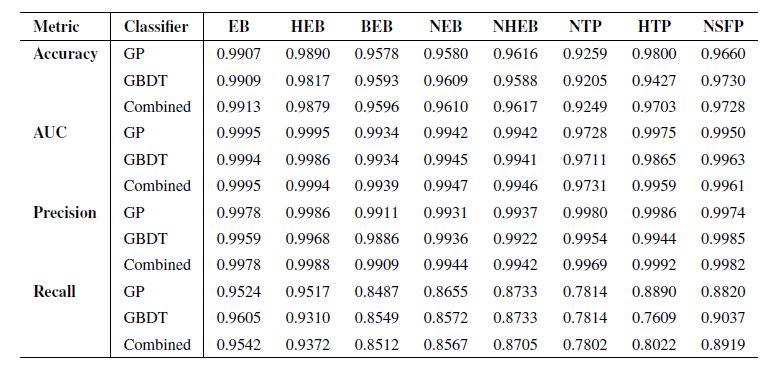
結果から、両方の分類器はすべてのFPシナリオにおいて、特に精度において優れた性能を発揮することが示された。RAVENパイプラインの主な目的は、実際の惑星候補を選別・検証することであるため、精度は最も重要な指標であり、誤分類なくFPを正しく識別するパイプラインの能力を反映している。2つの分類器の結果を組み合わせると、すべてのシナリオにおいて精度はほぼ99%に達します。
RAVENプロセスの性能は、事前分類済みのTOIセットで最終的にテストされました。サンプルに含まれる1,361個のTOIすべてに対するRAVEN確率は、次の図に示されています。
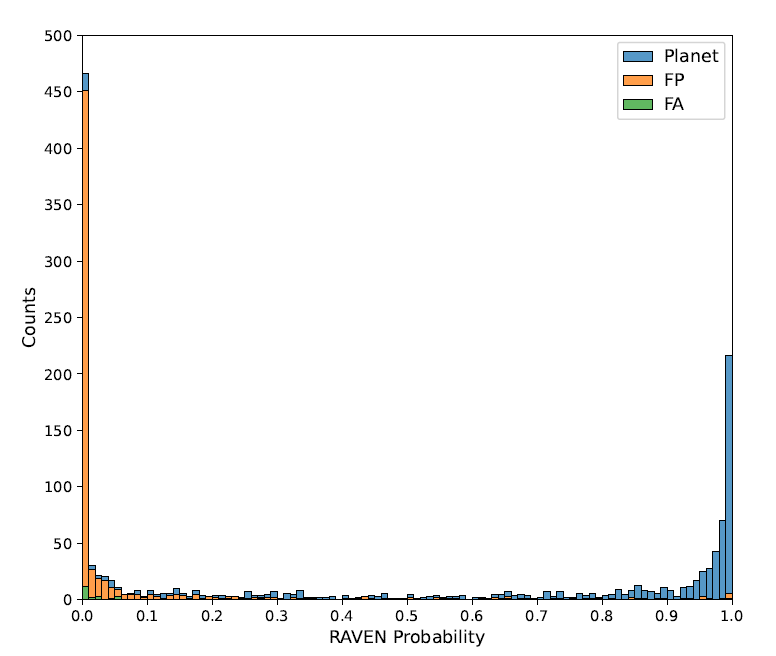
ヒストグラムは、3つのクラス間の確率の差が有意であり、分布が良好で、極端な値が明確であることを示している。これは、RAVENがFPイベントを特定し、それらに低い惑星事後確率を割り当てる上で有効であることを示している。具体的には、93.8%では偽陽性事象の事後確率の最小値は0.5未満であり、69.7%では0.01未満である。偽陽性事象の平均確率は0.076、中央値は0.00022である。
同様に、26件のFA TOIのうち、23件は確率が0.5未満であり、カテゴリー全体の中央値は0.016でした。全体として、FPとFA TOIの結果は、TESS候補のスクリーニングにおけるパイプラインの効率性を裏付けており、ほとんどのFPイベントを除去するために使用できます。
次に、研究者らはRAVENが偽陽性(FP)を識別する能力を検証し、以下の表には確率が0.9を超える12件のFPイベントがさらにリストされている。
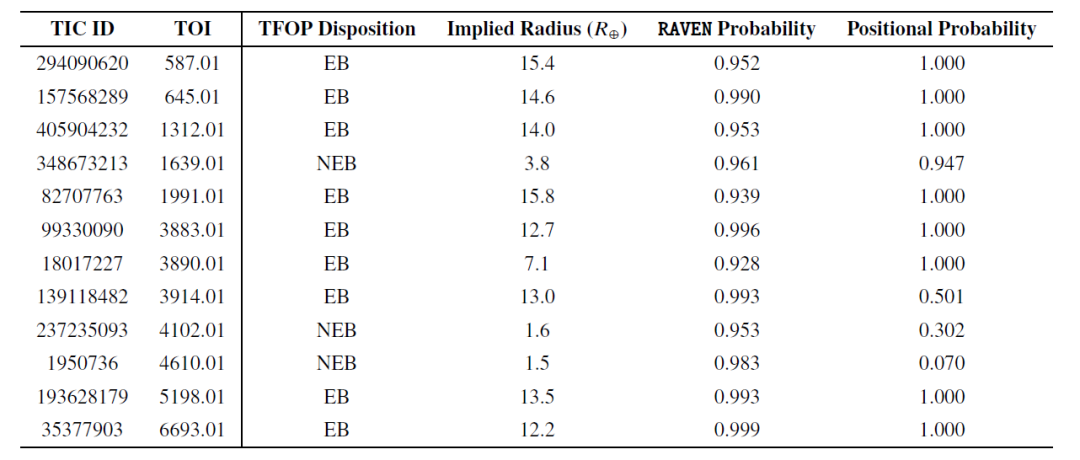
これらの高確率FPイベントのうち、ほとんどが食連星(EB)であり、近隣食連星(NEB)はわずか3つでした。サンプル中で最も多かったFPタイプはNEBでしたが、これはRAVENがNEBの識別に効果的であったことを示唆しています。実際、2つのNEBイベント(TOI-4102.01とTOI-4610.01)について、RAVENの手順では位置情報の確率が低いと判断し、追跡観測で確認された真のホストに最高確率を正しく割り当てました。
さらに、TOI-4102.01も問題のあるイベントとしてマークされました。これら2つのTOIは、候補を評価する際、特に検証時には、RAVENプロセスの完全な出力と位置情報の確率を併せて考慮し、事後確率が無効となる可能性のある状況を特定する必要があることを示しています。
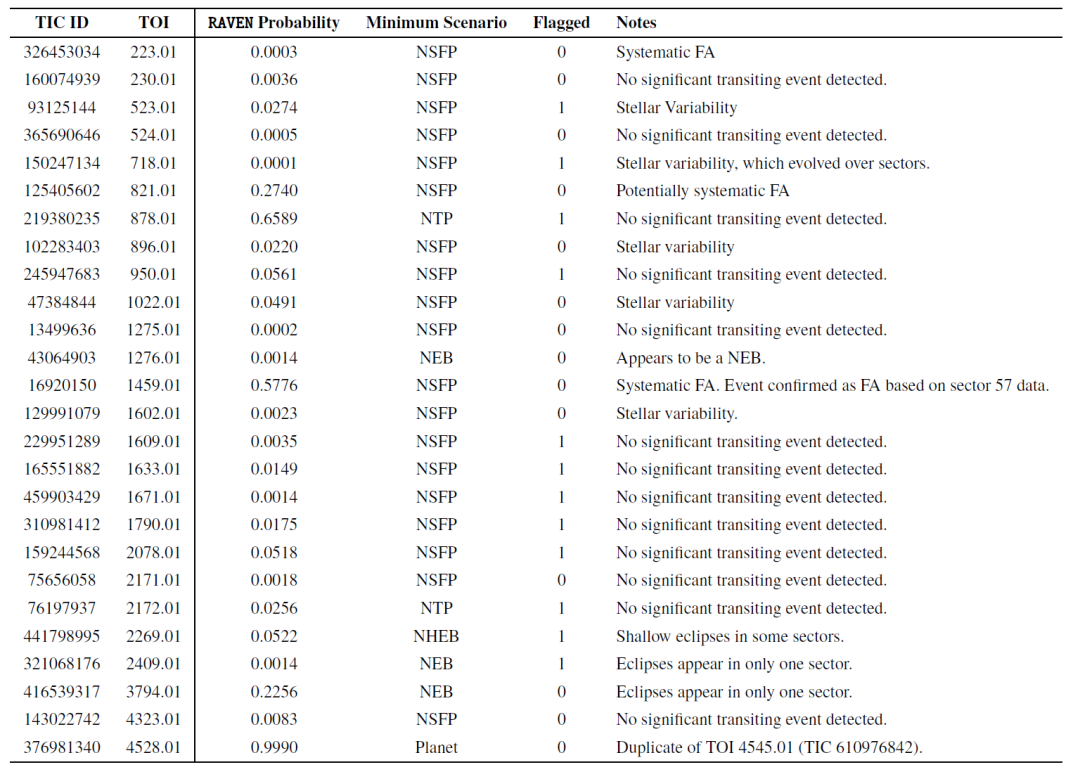
研究者らは、RAVENプロセスによる誤警報(FA)TOIの検出性能も評価した。下の表は、サンプル中の26個のFA TOIについて、事後確率が最も低い値と、それに対応するFPシナリオを示している。ほぼすべてのFA TOIの確率は惑星シナリオと一致しておらず、RAVENがそれらを効果的に識別したことが示された。
最終的に、最初のTOIサンプルをスクリーニングした後、研究者たちは既知の惑星397個と確認済みの惑星308個、合計705個の惑星を残した。その結果は…ほとんどの惑星TOIは高い事後惑星確率を有しており、81%は0.5の閾値を超えている。
特に、420個の惑星は確率が0.9を超え、「可能性のある惑星」の範囲に分類されます。さらに、210個の惑星はTOIが統計的検証の閾値である0.99を超えており、これは全惑星サンプルの約30%に相当します。これらの結果は、RAVENが実際の惑星候補の選別、順位付け、検証において優れた性能を発揮することを示している。
AIは徐々に天文学研究にとって重要なインフラとなりつつある。
より広い視点から見ると、技術進化において人工知能は徐々に天文学研究にとって重要なインフラになりつつあります。その意義は単に「データ処理効率の向上」にとどまらず、科学的発見の全体的なパラダイムを再構築し始めています。天文学は長い間、物理モデルと人工的なルールに基づく分析手法に依存してきました。しかし、観測能力の向上に伴い、データの規模と複雑さは増大し続けています。光度曲線から高解像度画像、そして多次元スペクトルや星カタログ情報へと、従来の手法は高次元、非線形、高ノイズのデータを処理する際に徐々に限界に近づいています。このような背景から、機械学習と深層学習を中核とするAI技術は、「膨大な観測データ」と「効果的な科学的理解」を結びつける重要な架け橋となりつつある。
観測手法の進歩に伴い、天文学データはもはや単一のモダリティに限定されなくなりました。画像、スペクトル、時系列光度曲線、星カタログパラメータなど、複数のデータソースが共存し、従来の深層学習モデルはこの段階で新たな限界を示し始めています。実際、いくつかの研究ではマルチモーダル天文学モデルの構築が試みられていますが、これらの試みには依然として大きな限界があります。ほとんどの研究は超新星爆発などの単一の現象に焦点を当て、「対照的な目的」を中核技術としている。そのため、モデルが任意のモードの組み合わせに柔軟に対応したり、表面的な相関関係を超えてモード間の重要な科学的情報を捉えたりすることが難しくなっている。
このボトルネックを克服するために、カリフォルニア大学バークレー校、ケンブリッジ大学、オックスフォード大学など、世界中の10以上の研究機関のチームが協力し、天文学における初の本格的なマルチモーダル基本モデル群であるAION-1(Astronomical Omni-modal Network)を立ち上げた。画像、スペクトル、星カタログデータなどの異種観測情報を、統一された初期融合バックボーンネットワークを通じて統合およびモデル化することにより、ゼロショットシナリオで優れた性能を発揮するだけでなく、その線形検出精度は、特定のタスク向けに特別に訓練されたモデルに匹敵する。
論文タイトル:AION-1:天文学のためのオムニモーダル基礎モデル
用紙のアドレス:https://openreview.net/forum?id=6gJ2ZykQ5W
一方、具体的な科学的疑問のレベルでは、AIは従来の観測手法の限界を押し広げています。例えば、現代天文学において、強い重力レンズは宇宙の大規模構造やブラックホールと銀河の共進化を研究するための重要なツールです。強い重力レンズとして機能するクエーサーは、超大質量ブラックホールとその宿主銀河間のスケーリング関係(特にMBH-Mhost関係)の赤方偏移に伴う進化を研究するための、極めて貴重な観測機会を提供します。
しかし、クエーサーは非常に珍しく、その特定は天文学者にとって常に大きな課題でした。スローン デジタル スカイ サーベイ (SDSS) でカタログ化された約 30 万個のクエーサーのうち、候補として見つかったのはわずか 12 個で、最終的に確認されたのは 3 個だけでした。こうした背景のもと、スタンフォード大学、SLAC国立加速器研究所、北京大学、イタリア国立天体物理学研究所ブレラ天文台、ユニバーシティ・カレッジ・ロンドン、カリフォルニア大学バークレー校など、多数の研究機関からなるチームが、DESI DR1のスペクトルデータにおいて強力な重力レンズとして機能するクエーサーを特定するためのデータ駆動型ワークフローを開発した。このワークフローを用いて、研究者らは7つの高品質(クラスA)クエーサーレンズ候補を特定した。
論文タイトル:DESI DR1で発見された強力なレンズとして機能するクエーサー
用紙のアドレス:https://arxiv.org/abs/2511.02009
将来の観測ミッション(大規模な全天サーベイなど)の進展に伴い、天文学はさらなるデータ爆発の段階に入り、それに伴いAIの役割も深まることが予想される。分析支援から発見の推進、単一タスクモデルから汎用的な基礎モデルまで、AIは宇宙に対する私たちの理解を再構築している。それは「どのように見るか」だけでなく、「何を発見できるか」をも変えつつあるのだ。
参考文献:
1.https://arxiv.org/abs/2509.17645
2.https://phys.org/news/2026-03-ai-approach-uncovers-dozens-hidden.html
3.https://openreview.net/forum?id=6gJ2ZykQ5W








