Command Palette
Search for a command to run...
MITは、推論速度を1.4~3.7倍向上させることで、拡散モデルにおけるサンプリング遅延のボトルネックを克服するDRiffusionを提案している。

生成AIの分野では、拡散モデルは独自の反復ノイズ除去メカニズムにより、生成品質と多様性の面で従来のモデルの限界を効果的に克服し、画像処理、ビデオ処理、音声処理、分子設計など、さまざまな最先端分野で広く応用されています。しかし、この「時間対品質」の精緻化プロセスでは、高忠実度の結果を得るために、通常数十回、場合によっては数百回の反復処理が必要となります。その結果、サンプリング速度が極めて遅くなり、推論コストが高くなります。これは、拡散モデルがリアルタイムアプリケーションや大規模展開へと移行する上で、主要なボトルネックとなっている。
サンプリングの遅さという課題に対処するため、研究者たちは整流フローや蒸留などの高速化手法を提案してきた。前者はノイズ除去パスを最適化することで無効な反復回数を減らし、後者は知識蒸留を用いてモデルを軽量化する。しかし、高速化率を高めるためにサンプリングステップ数を大幅に圧縮すると、どちらの方法も出力品質を著しく犠牲にする(例えば、ディテールの喪失やテクスチャのぼやけなど)上に、蒸留処理は結果の多様性を著しく低下させる可能性さえある。
並列化技術は品質を損なうことなく補完的なアプローチを提供する一方で、既存のシステムレベルの手法はモデルアーキテクチャ(U-NetやTransformerなど)によって制限され、汎用性に欠けるという問題があります。拡散過程を微分方程式としてモデル化し、効率的なソルバーを設計する数学的手法は、主流のフレームワークとの互換性が低く、元のサンプリング分布から逸脱しやすいという欠点があります。これらの解決策はいずれも、拡散モデルに内在する直列依存性(各ノイズ除去ステップが前のステップの出力に依存する)を根本的に克服するものではありません。
この課題に対処するため、MITの研究者たちは最近、根本的な問題に取り組み、簡潔な数学的発見と革新的なスケジューリングモデルを通じて、拡散フレームワーク内の未活用の固有の並列性を初めて実証しました。これに基づき、研究者たちは、DRiffusionというドラフト・アンド・リファイン拡散モデルを提案した。システムレベルの手法と数学的手法の利点を組み合わせることで、生成品質を犠牲にすることなく大幅な高速化を実現し、拡散モデルにおける高忠実度とサンプリング効率のバランスを取るための新しいソリューションを提供する。
関連する研究成果は、「DRiffusion:ドラフト作成と改良プロセスにより拡散モデルを容易に並列化」と題され、arXivにプレプリントとして公開されています。
研究のハイライト:
* 拡散モデルの本質的な並列性を明らかにする、DRiffusionの「ドラフト・リファインメント」並列フレームワークを先駆的に開発。
* 積極的な加速モードと穏やかな加速モードの両方を提供し、品質と速度の間で柔軟なトレードオフを可能にします。
* マルチモデルのフィールドテストにおいて、実世界で1.4~3.7倍の高速化を実現し、ほぼロスレスの生成品質と既存手法に対する総合的な優位性を達成しました。

用紙のアドレス:
https://arxiv.org/abs/2603.25872
弊社の公式WeChatアカウントをフォローし、バックグラウンドで「DRiffusion」と返信すると、PDF全文を入手できます。
MS-COCOデータセット:5,000枚の画像と25,000件の説明文が含まれています。
この実験では、5,000枚の画像を含むMS-COCO 2017検証セットをベンチマークデータセットとして使用した。各画像には5行の説明文が添えられています。標準的な手順に従い、生成された画像と参照テキストが1対1で対応するように、各画像の最初の説明文のみが画像とテキストの整合性評価に使用され、評価の厳密性が保証されます。
従来の評価指標では、細かな視覚的嗜好に対する感度が不十分であることを考慮し、本研究では、補足的な評価指標としてPickScoreとHuman Preference Score v2.1(HPSv2.1)を導入しました。効率性の評価には、最大4基のNVIDIA V100 GPUを使用し、複数の定常状態実行を通じて平均サンプリング遅延を測定しました。単一GPU拡散モデルのベースラインと比較した相対的な高速化と、この手法によって導入される追加のメモリオーバーヘッドを報告します。
ベースラインと比較するために、代表的な拡散モデル高速化手法として、直接スキップ(サンプリングステップ数を削減する手法)とAsyncDiff(サブネットワークを異なるデバイスに分散させ、非同期サンプリングを実行することでノイズ除去を並列化する手法)の2つを選択した。評価の一貫性を確保するため、研究者らはAsyncDiffの公式実装に基づき、同じ測定設定で実験結果を再現した。
DRiffusion:ドラフト・リファインメントプロセスを通じて拡散モデルを簡単に並列化
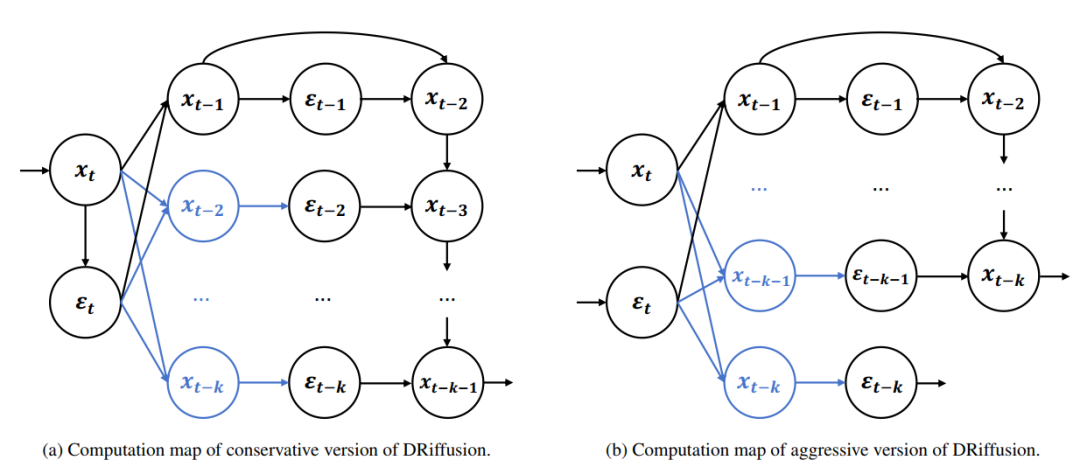
DRiffusionの設計は、根本的な疑問に基づいています。拡散モデルは、複数の時間ステップにおけるノイズ予測を同時に計算できるのでしょうか?従来の拡散モデルでは、各ノイズ除去ステップが前のステップの出力状態に依存するため、この目標を直接達成することは困難です。スキップステップ遷移は、この制約を克服するための新たな視点を提供する。スキップ操作を独立して呼び出し可能なローカル演算子とみなすことができれば、完全な軌跡に沿ってステップを踏むことなく中間状態を直接構築できるため、時間ステップ全体にわたる並列計算が実現できる。
ジャンプ遷移の概念は新しいものではありません。下の図に示すように、連続時間の観点からは、システムダイナミクスはより長い時間間隔で積分することができ、中間ステップをスキップすることは自然な操作です。しかし、現在では...拡散モデルのフレームワークでは、通常、この自由度はグローバルレベルでのみ利用されます(例えば、時間ステップのシーケンスを再選択することによって)。ローカルで呼び出して必要に応じて使用できる、段階的なメカニズムが不足している。

この目的を達成するために、DRiffusionはまずジャンプ遷移を演算子に変換します。具体的には、DDPM、DDIM、常微分方程式(ODE)に基づくソルバーなどの主流の拡散モデルに対して、グローバルな時間ステップスケジュールを再定義することなく、任意の2つの拡散状態間を直接接続できる統一的なジャンプ遷移式が導出される。
DDPMを例にとると、現在の状態x_tから将来の状態x_t-kへのジャンプ遷移には閉形式解が存在します。また、DDIMも周辺分布の一貫性に基づいて一般化できます。さらに、ODEモデリングにおいては、中間ステップをスキップすることは、より大きな数値積分ステップサイズを直接使用することと同等です。この演算子の導入により、サンプリングパターン設計の柔軟性が大幅に向上し、その後の並列化の基礎が築かれます。
ジャンプ遷移演算子に基づくDRiffusionの中核となるワークフローは、ドラフト作成と洗練という2つの段階に要約できます。アンカータイムステップ t における状態 x_t が与えられた場合、ジャンプ遷移を用いて後続の k タイムステップの状態を並列に生成し、ドラフト推定値を取得します。ステップサイズが大きくなったため、これらのドラフトの精度は連続する反復処理の精度よりも若干低下しますが、全体的な結果は元のノイズ除去済み軌跡との整合性を維持します。
続いて、これらのドラフトは並列にノイズ予測器に入力され、対応するノイズ推定値が得られます。その後、標準的なノイズ除去更新が実行され、各ドラフトが改良されます。最後に、改良された状態とその対応するノイズが得られ、これが次の反復処理の基準点となります。
この設計には潜在的な問題がある。大きなジャンプステップサイズは、ノイズ予測の不完全性により、生成品質の低下につながる可能性がある。既存の研究では確かにこのリスクが指摘されているが、我々の実験観察では、2つの緩和要因が明らかになった。初め、知覚される品質がわずかに低下したとしても、表現能力が著しく低下するわけではありません。生成された画像や潜在ベクトルは、通常、根底にある意味情報や構造情報のほとんどを保持しています。2番、ノイズ予測器は完全に正確ではないものの、その汎化能力は、妥当なサンプル近傍を妥当な結果にマッピングするのに十分である。これらの2点に基づき、DRiffusionは大きなストライドを使用した場合でも、十分に高品質な画像を出力できる。
実施方法に関して言えば、DRiffusionには急進版と保守版の2つのバージョンがある。
下図に示すように、この革新的なバージョンでは、複数のノイズ予測を1回の反復で完全に並列化します。通信などの軽微なオーバーヘッドを無視すれば、理想的な高速化はk倍に達し、実行時間は元の1/kに短縮されます。
保守的なバージョンでは、まず高精度の電流ノイズ(精製された状態から生成)を独自に計算し、これを基に積極的なバージョンの処理を再現します。さらに時間ステップを1つ進めることで、理想的な2k+1倍の高速化を実現します。両バージョンの基本的な考え方は同じで、ドラフトを並列計算能力と交換し、精製によって出力品質を確保するというものです。
3つのGPUで、実測値で約3倍の高速化を実現しました。
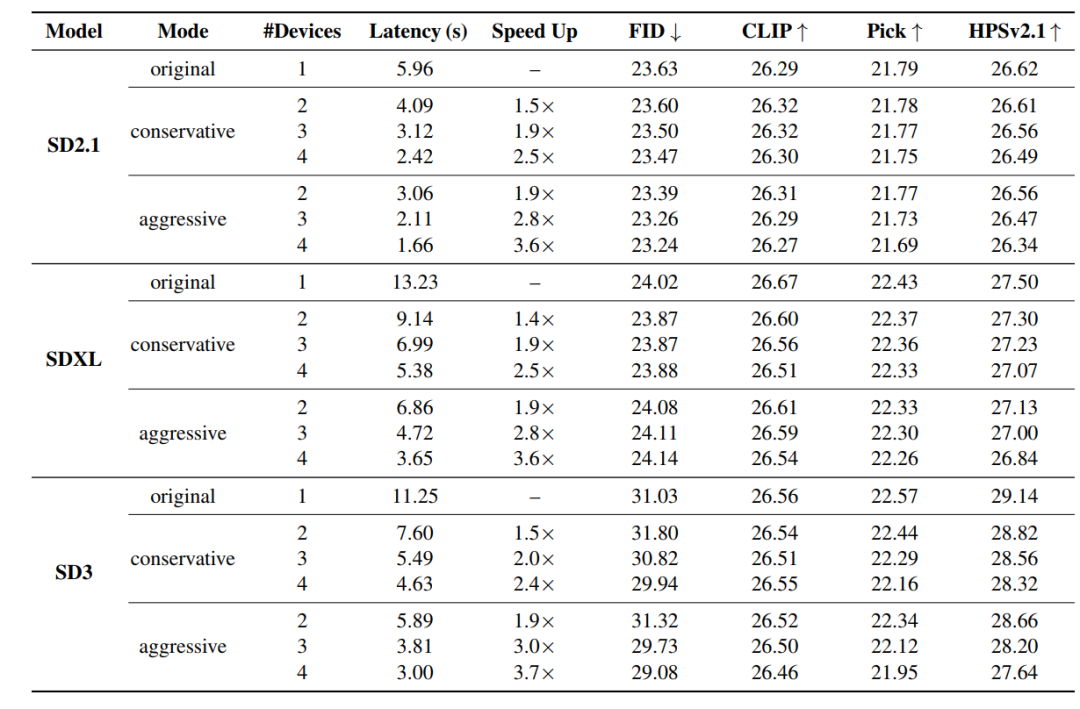
DRiffusionの性能を検証するため、実験では、U-Netに基づくStable Diffusion 2.1(SD2.1)、U-Netに基づくStable Diffusion XL(SDXL)、およびフローマッチング用のTransformerに基づくStable Diffusion 3(SD3)など、さまざまなアーキテクチャとスケールの拡散モデルを対象としました。このように複数のモデルを網羅することで、既存の手法との公平な比較が可能になるだけでなく、本手法の汎用性を十分に検証することができます。
定性的な結果を下の図に示します。高い加速度比の下では、DRiffusionはベースラインのピクセル単位の出力を完全に再現することは難しいものの、意味的な一貫性を一貫して維持し、木目の質感や猫の胸のハイライトといった細かいディテールを効果的に保持します。ノイズサンプリングの手順を適度に省略することで、高速化バージョンは、より強いコントラストとより鮮明なディテール(猫の目の反射など)を持つ画像を生成できる場合があります。積極的な高速化(4倍近く)は、色の過飽和や軽微なアーティファクトなど、わずかな画質低下を引き起こす可能性がありますが、全体としてはベースラインとの高い一貫性を維持しています。

定量的な結果を以下の表に示す。すべての構成において、FID値はベースラインに非常に近く、CLIPスコアの最大減少値は0.16を超えません。一部のシナリオでは、FIDはわずかに改善しましたが、これは主に方法論的な改善ではなく統計的なばらつきによるものです。補足的なPickScoreとHPSv2.1の評価では、それぞれ平均で0.17と0.43の減少が見られました。唯一の例外は、積極的な4デバイスモードのSD3で、HPSv2.1は1.50減少しました。これは、SD3のデフォルトのサンプリングステップ数がわずか28ステップであり、極端なステップサイズが近似誤差を増幅するためです。4つの指標の安定性と大幅な高速化を考慮すると、この品質低下は許容範囲内です。
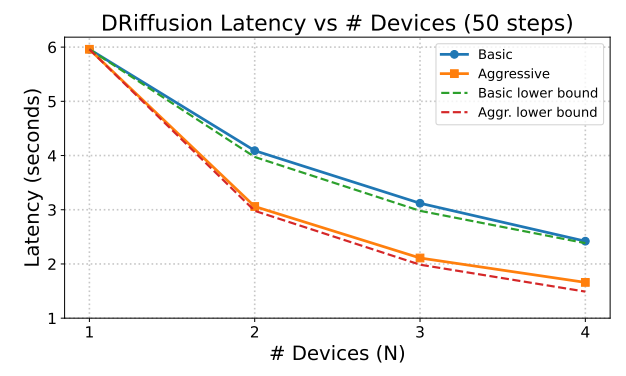
加速性能に関して言えば、実際の高速化率は1.4倍から3.7倍で、サンプルあたりの総計算コストは元のモデルとほぼ同じです。実験データによると、アグレッシブモードの遅延スケーリングは理論上の下限O(1/N)に近く、一方、コンサーバティブモードはO(2/(N+1))と非常に一致しており、DRiffusionが効率的かつスケーラブルな並列化を実現していることが証明されています。
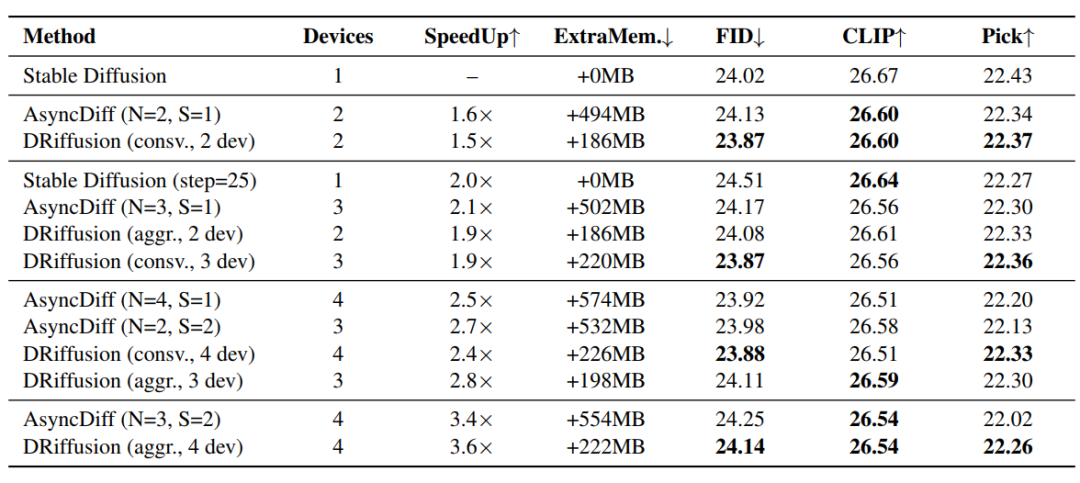
方法比較の結果を以下の表に示す。すべての高速化グループにおいて、DRiffusionは生成品質の点でAsyncDiffおよび単純なスキップベースラインを上回った。加速効果に敏感なPickScoreを主要指標として使用した結果、DRiffusionは平均で48.61 TP3T、4台のデバイスでは最大で58.51 TP3Tのパフォーマンス低下ギャップを削減しました。加速効果はデバイス数にほぼ比例し、加速率は同数のデバイスにおけるAsyncDiffと同等か、わずかに優れています。
メモリ効率のメリットはより顕著です。AsyncDiffはデバイス数が増えるにつれて最大574MBの追加メモリを必要としますが、DRiffusionは186~226MBの安定したオーバーヘッドしか発生させません。SDXLのベースラインメモリ要件が約13GBであることを考えると、このオーバーヘッドは無視できるほど小さいと言えます。バッチサイズが5の場合、AsyncDiffは32GBノードでメモリ不足の異常が発生しましたが、DRiffusionは正常に動作しました。その理由は、DRiffusionはサンプリング反復プロセスのみを変更し、モデル構造やコア計算から切り離すからである。
総括する、DRiffusionは、3つのGPU上で約3倍の高速化を実現しながら、生成品質と微細なディテールを維持し、推論速度を大幅に向上させています。簡潔な理論的特徴と実用的な並列実装を組み合わせることで、高品質で安定した実験結果が得られた。
拡散モデルの並列化により処理が加速される
拡散モデルの並列化は、世界中の学術界と産業界の両方が追求する主要な研究分野となっています。学術界では、多くの主要機関がこの分野で画期的な成果を上げています。MITと香港大学が共同で提案したFast-dLLMは、モデルの再学習なしに、大規模な拡散言語モデル(長文テキスト生成タスク)のエンドツーエンド処理を27.6倍高速化し、精度損失を2%以内に抑えています。
論文タイトル:FAST-DLLM V2:効率的なブロック拡散LLM
論文リンク:https://arxiv.org/pdf/2509.26328
カリフォルニア大学バークレー校が開発したStreamDiffusionV2ストリーミングシステムは、SLO(スロー・オブ・スロー)に対応したバッチスケジューラと、ビデオ拡散モデルに対応したモーション認識ノイズコントローラを統合し、マルチGPU環境におけるビデオ生成フレームレートを58FPSに向上させ、リアルタイム生成における計算能力のボトルネックを打破します。
論文タイトル:StreamDiffusionV2:動的かつインタラクティブなビデオ生成のためのストリーミングシステム
論文リンク:https://arxiv.org/abs/2511.07399
企業向け分野において、NVIDIAは並列化技術をハードウェアとソフトウェアのエコシステムに深く統合しています。計算パスの最適化と複数デバイス間の連携により、拡散モデルの推論速度を大幅に向上させ、画像や動画生成シナリオにおける計算コストを削減します。一方、Stability AIは、Stable Diffusionシリーズのモデルにおいて並列サンプリング戦略を探求しています。バッチ処理パラメータの最適化と、DDIMやPLMSなどの並列処理をサポートするサンプラーの有効化により、生成品質を維持しながら画像生成効率を3~5倍向上させます。
要約すると、学術界と産業界の共同努力により、拡散モデルの並列化は技術革新のホットトピックとなっています。代表的なソリューションであるDRiffusionは、固有の並列性を活用することの実現可能性と効率性を実証しました。今後、ハードウェアとアルゴリズムの緊密な連携により、拡散モデルは高い忠実度を維持しながら真のリアルタイム生成体験を実現し、AIの幅広い応用における効率性の障壁を取り除くことが期待されます。








