Command Palette
Search for a command to run...
MITの研究チームは、生成AIを用いて無線視覚システムを改良し、完全に遮蔽された物体を高精度で再構築することに成功し、851 TP3Tという最高精度を達成した。

コンピュータビジョンやインテリジェントセンシングの分野において、完全に遮蔽された物体を再構築することは、常に困難な研究課題でした。物流倉庫に積み重ねられた荷物、生産ライン上の複雑な装置、あるいは隠れた物体を識別する必要のある拡張現実アプリケーションなどを想像してみてください。カメラやLiDARといった従来の光学センサーは、多くの場合、効果を発揮しません。これらのセンサーは可視光やレーザー光の反射を利用しますが、これらの信号は障害物に遭遇すると遮断され、物体を観測できなくなってしまうのです。
近年、ミリ波(mmWave)技術の登場により、この問題に対する新たな解決策がもたらされた。ミリ波信号は、段ボール箱や布地といった一般的な障害物を透過できるだけでなく、人体にも安全で優しい。これにより、産業、物流、ロボット工学、拡張現実などの分野で大きな可能性が生まれます。しかしながら、ミリ波信号は鏡面反射特性、高ノイズ、低空間分解能といった特徴を持つため、完全な3D再構成に直接利用することは困難である。この問題を克服するための一つのアプローチは、既存の視覚ベースの形状補完モデルをミリ波再構成に適用することです。しかし、これらのモデルはもともと高カバレッジ・高解像度の可視光センサー向けに設計されており、ミリ波反射特有の物理的特性を考慮していないため、この戦略では信頼性の高い再構成結果が得られないことがよくあります。
この問題点に対応するため、MITの研究者らは、ミリ波の物理的特性を学習プロセスに組み込むことで、無線センシングと最新の形状補完技術の間のギャップを埋める「ウェーブフォーマー」と呼ばれる新しい手法を提案した。これにより、完全に遮蔽された多様な日常的な物体の高精度な3D形状再構築が可能になる。この手法は、高信号ノイズや深刻な遮蔽といった問題を解決するだけでなく、革新的な物理的知覚トレーニングフレームワークによる合成データトレーニングに基づき、実世界環境における高精度な再構成を実現します。最先端のベースライン手法との直接比較では、Wave-Formerは851 TP3Tという高い精度を維持しながら、再現率を541 TP3Tから721 TP3Tに向上させています。
関連する研究成果は、「Wave-Former: ワイヤレス形状補完による遮蔽を越えた3D再構成」と題され、arXivにプレプリントとして公開されている。
研究のハイライト:
* 本論文では、多様な物体に対するミリ波3D形状補完フレームワークを初めて提案し、モデルを合成データのみでトレーニングしながら、同時に実データ上で3D再構成を実現することを可能にする。
* この手法は、実際のMITOデータセットにおいて、リコール率を54%から72%に向上させ、既存のミリ波再構成手法を凌駕します。
* ミリ波部分点群に適用した場合、ネイティブの視覚補完モデルを上回り、再現率を121 TP3T向上させ、851 TP3Tのピーク精度を達成します。
用紙のアドレス:
https://arxiv.org/abs/2511.14152
弊社の公式WeChatアカウントをフォローし、バックグラウンドで「ミリ波」と返信すると、PDF全文を入手できます。
3Dオブジェクトデータセットは豊富なサンプルを提供する。
Wave-Formerのトレーニングと検証のために、研究チームは公開されている3つの3Dオブジェクトデータセットを使用しました。
* OmniObject3D:これには、家具、工具、おもちゃなどのカテゴリを網羅した、日常的な物体の多様な点群データが大量に含まれています。
* Toys4K-3D:おもちゃや小さな物に焦点を当てることで、形状や素材特性の多様性を豊かにしている。
* Objaverse Thingiverse サブセット:これは、合成トレーニングデータを生成するための3Dモデルを作成するためのオープンソースプラットフォームを提供する。
これら3つのデータセットには、合計で25,000個以上の3D点群が含まれています。これは、Wave-Formerのための豊富なトレーニングサンプルセットを提供します。
実世界での評価において、研究チームはYCBデータセットから抽出した61個のオブジェクトを含むMITOデータセットを使用した。これらの製品は、台所用品、道具、食品、おもちゃなど、さまざまな用途に対応しています。木材、金属、段ボール、プラスチックなどの素材で作られており、形状も多種多様で複雑です。これには、鋭利なエッジ、平面、曲面が含まれます。ミリ波測定は、視線方向と完全遮蔽の両方の条件下で各物体に対して実施され、モデルの汎化能力を徹底的に検証しました。
注:YCBデータセット(YCBオブジェクトおよびモデルセットの略)は、ロボット工学およびコンピュータビジョンの分野で広く使用されている、古典的で標準的なデータセットです。
Wave-Formerの学習は完全に合成データに依存している点に注目すべきである。物理的知覚学習フレームワークを通して、このモデルはミリ波信号の特性を学習できるため、実世界の測定において優れた性能を発揮し、実際のミリ波データの不足によって生じる学習上の困難を回避できる。
波形生成器:合成データで学習させた後、実データ上で3D再構成を実現します。
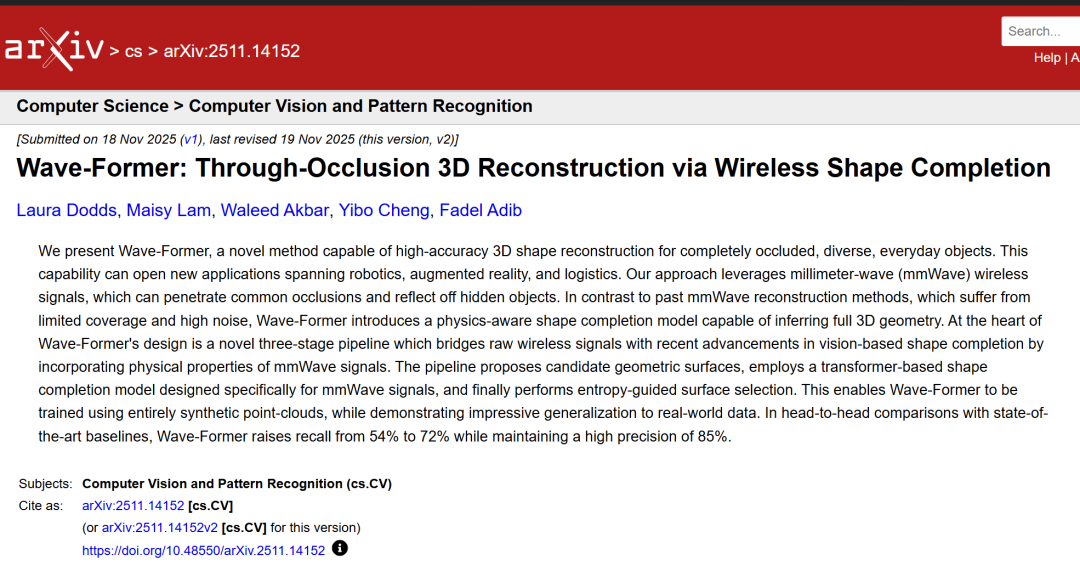
Wave-Formerの中核となる設計は、物理的な知覚訓練プロセスと現実世界における推論プロセスの2つの部分から構成されている。この設計では、ミリ波信号の特性である鏡面反射、高ノイズ、低空間分解能、および可視性の不均一性を十分に考慮しています。全体のプロセスは下図に示されています。
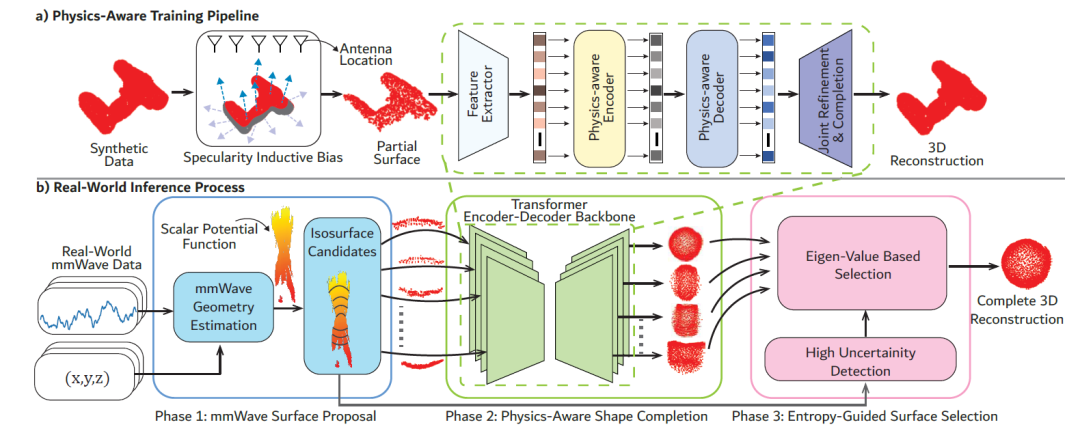
物理法則を考慮したトレーニングパイプライン
Wave-Formerの物理法則を考慮した学習プロセスは、鏡面反射知覚の誘導バイアス、反射に依存する可視性パターン、および最適化と補完を組み合わせたフレームワークを通じて、物理的特性を学習に組み込むことで、モデルを合成データのみで学習することを可能にします。
一つ目は、鏡面反射の知覚における帰納的バイアスである。既存の視覚ベースの補完モデルは、基本的に可視光と整合する誘導バイアスを符号化していますが、このバイアスはミリ波信号とは互換性がありません。なぜなら、それらの「カメラのような」部分観測は、拡散反射と広い範囲を前提としているからです。この問題を解決するために、研究者たちは、物理的に整合性のある部分観測を通して誘導バイアスを再定義し、ミリ波信号の鏡面反射をシミュレートしました。
2つ目は、反射に依存する視認性です。光学センサーとは異なり、ミリ波の可視性は強い異方性を示します。つまり、測定可能な反射率は入射角と物体からの反射強度に依存します。そのため、形状が全く同じ2つの物体であっても、材質特性の違いによって可視性が大きく異なる場合があります。
この動作をモデル化するために、研究者らは、反射率に依存する視認性パターンを導入した。減衰面の位置は、物理的な指針と材料上の制約によって決定されます。これにより、従来の等方性カバレッジの仮定が置き換えられ、ネットワークはミリ波の可視性が本質的に不均一であり、角度に依存することを理解できるようになります。
3つ目は、ノイズ除去と補完を組み合わせた処理です。既存の画像認識に基づく形状補完モデルは、カメラやLiDARセンサーの一般的なノイズ特性と解像度特性に合わせて設計されているため、入力された部分点群を再構築された点と直接結合できることを前提としています。しかし、ミリ波信号はノイズが著しく高く、解像度も低いため、既存の結合手法では最終的な再構築結果に大きな歪みが生じてしまいます。
この問題を解決するには、研究者らは、最適化と完了を同時に行う手法を提案した。トレーニング中にノイズを導入することで、実際のミリ波信号の特性をシミュレートし、その後、損失関数を再定義することで、モデルが(入力をつなぎ合わせることなく)完全な3D形状を出力できるようにし、信頼性の低い点を単に保持するのではなく、再解釈できるようにします。
トレーニングフレームワーク全体は、Transformerエンコーダー・デコーダーアーキテクチャ(PoinTrバックボーン)をベースとし、物理的に整合性のある観測モデルと、ノイズ除去および補完の目的を組み合わせて構築されています。これにより、モデルを完全に合成データで学習させ、実際のミリ波信号に対して高精度な再構成を実現することが可能になります。
実世界の推論プロセス
Wave-Formerの実世界推論プロセスは、3段階のパイプラインを利用して、実際のミリ波信号から完全な3Dオブジェクトを再構築します。
ミリ波表面候補生成(第1段階)
まず、研究者らは生のミリ波測定値を、反射に含まれる幾何学的情報を正確に捉えた候補部分表面のセットに変換しました。通常、ミリ波部分点群推定はミリ波3Dパワー画像の閾値処理に依存しますが、この方法では多数の誤った点が生成されます。研究者らは、ミリ波イメージングにおける最近の進歩を利用して、生の反射を幾何学的に整合性のある部分表面空間に変換しました。
物理的知覚による形状完成(第2段階)
訓練済みのモデルを各候補表面に適用し、物理的に整合性のある完全な候補再構成画像のセットを生成する。
エントロピー感知型表面選択(フェーズ3)
ノイズが多い場合や反射が弱い場合は、点群の連続性と平面性を局所エントロピーで測定し、エントロピーが最も低い候補再構成を選択して、最終的な高忠実度3D点群を取得します。
このプロセスにより、Wave-Formerは複雑な遮蔽、低カバレッジ、高ノイズといった現実世界のシナリオに対応し、包括的な3D再構成を完了することができます。
Wave-Formerは、従来の最先端のミリ波3D再構成手法に比べて大幅な改善を実現している。
性能を評価するため、研究者らはWave-Formerを4つの最先端のミリ波再構成基準と比較した。
* バックプロジェクション:最も古典的で広く使用されているミリ波イメージング手法であり、第一原理に基づいたボリューム再構成手法です。
* mmNorm: 最近提案された最先端のミリ波3D再構成手法で、これも第一原理に基づいており、表面法線ベクトルを推定することによって物体の表面を再構成します。
* RMap:最先端の学習ベースのミリ波再構成手法であり、元々はシーンレベルの理解のために開発された。
* RMap(ファインチューニング版):RMapは、オブジェクト再構成のためにWave-Formerと同じトレーニングデータでファインチューニングされています。
定性的なパフォーマンス
まず、研究者らは実測データを用いて、Wave-Formerと4つの基準手法を定性的に比較した。下の図は、完全に遮蔽された複数の物体の実際のRGB画像(セグメンテーション後)と点群の等角投影図、および各手法による再構成結果を示している。
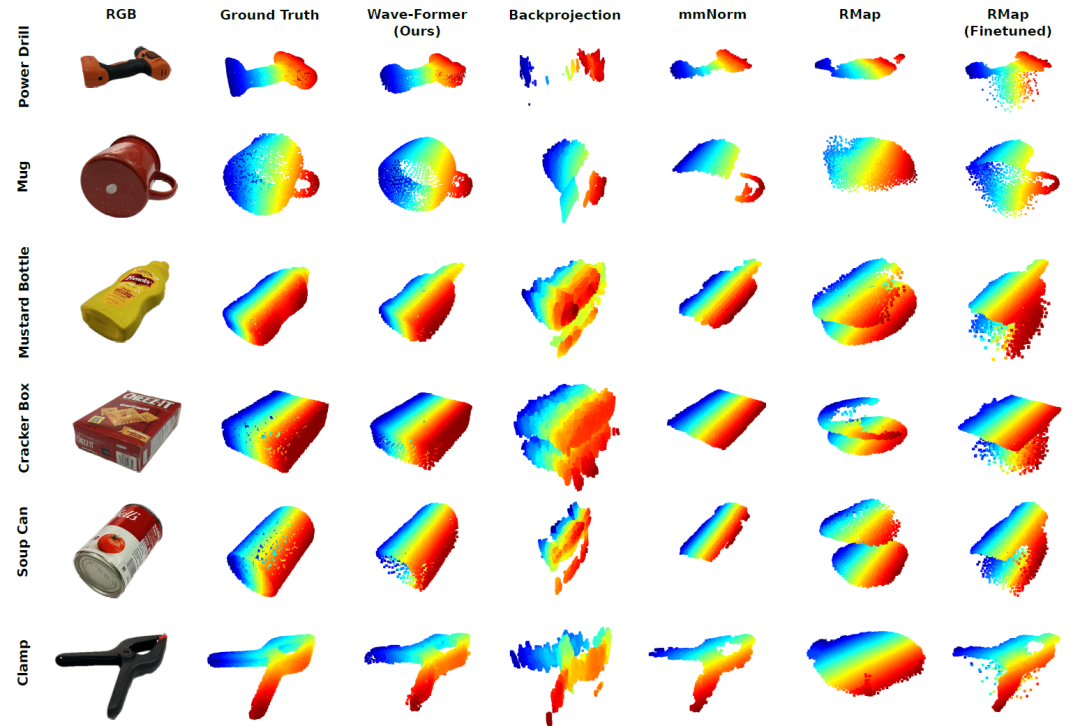
実世界における完全に遮蔽された物体のミリ波3D再構成の視覚的比較
明らかに、Wave-Formerは、ドリルや治具のような複雑な形状であっても、物体の完全な形状を安定して再構築することができます。対照的に、従来の手法は精度が低く、対象範囲が限られ、ノイズが多く、場合によっては物体の形状をほとんど識別できないという欠点がある。これらの結果は、Wave-Formerが従来の最先端のミリ波3D再構成手法に比べて著しく進歩していることを示している。
定量的結果
以下の表は、平均チャンファー距離、F値、精度、再現率の観点から、Wave-Formerのパフォーマンスをすべてのベースラインと比較した結果を示しています。
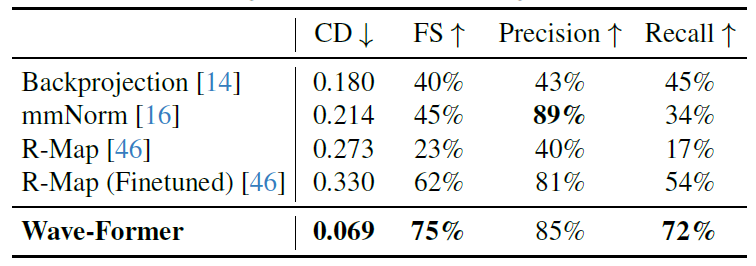
注目に値するのは、Wave-Formerのリコール率は、最良のベースラインRMap(微調整バージョン)の54%から72%へと大幅に向上し、同時に85%という高い精度を維持しています。さらに、Wave-Formerは、最適な基準値である0.18と比較して、0.069という最小の面取り距離を示しました。これは、完全に遮蔽された物体の高精度3D再構成を実現する上で、提案手法の有効性を十分に示しています。
視覚ベースの形状補完と比較して
研究者らはまた、最先端のネイティブ視覚形状補完モデルが高精度ミリ波3D再構成を実現できるかどうかも評価した。以下の表は、Wave-Formerと4つの最先端モデルの性能比較を示している。
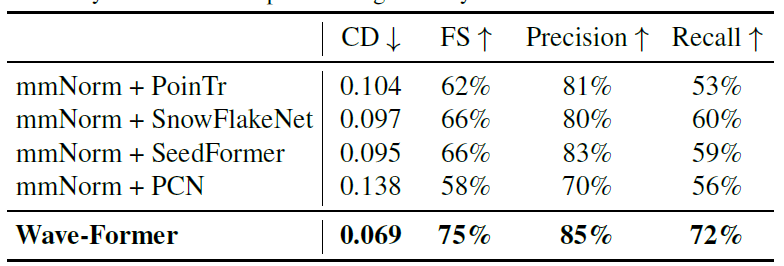
Wave-Formerは、あらゆる指標において他のモデルを凌駕し、再現率を60%から72%に向上させるとともに、85%という最高の精度を達成しました。これは、形状補完モデルに物理的特性を組み込むことの重要性を示している。
アブレーション実験
最後に、研究者らはウェーブフォーマーの各設計要素が全体的な性能にどの程度貢献しているかを分析した。以下の表は、ウェーブフォーマーの平均面取り距離(CD)、75パーセンタイルCD、および3つの異なる部分実装方式と比較した限界改善率を示している。

鏡面反射によって知覚される誘導バイアスと反射に依存する可視性(モデルA)を除去すると、パフォーマンスは著しく低下します。平均面取り距離は521 TP3T増加し、75パーセンタイルは671 TP3T増加します。
ジョイント再構築および完成モジュール(モデルB)をさらに取り外すと、平均面取り距離は10%増加します。
エントロピーを考慮した表面選択モジュール(モデルC)を再び取り外すと、75パーセンタイルCDは19%増加します。
要約すると、これらの結果は、ウェーブフォーマーの各構成要素が全体的な性能にどのように貢献しているかを明確に示している。
技術拡張:「物体の再構築」から「空間の再構築」へ
Wave-Formerは、生成AIとミリ波信号の助けを借りて、「完全に遮蔽された物体」の高精度3D再構成が可能であることを証明しました。MITの研究チームによる同時並行の別の研究では、この機能をさらに一歩進め、単一の物体から空間全体へと拡張している。
本研究では、研究者たちはもはや隠された物体の形状だけに焦点を当てるのではない。その代わりに、人体が屋内で移動する際に発生するマルチパスミリ波反射を利用して、屋内の環境全体を再構築する。従来の方法では、このような複雑な反射はノイズとして無視されるのが一般的だが、本研究では、いわゆる「ゴースト信号」と呼ばれるこれらの信号が、実際には空間構造に関する重要な手がかりを含んでいることが分かった。信号が人体と壁や家具の間で複数回反射する際、その経路の変化自体が環境の幾何学的情報を符号化しているのである。
問題は、これらの信号が非常に混沌としており、解像度が限られているため、従来の物理モデルを用いて直接分析することがほぼ不可能である点です。この問題を解決するため、研究チームは生成型AIを導入し、低品質で疎な初期再構成結果を理解して補完することで、モデルがマルチパス反射の統計的パターンを学習し、徐々に完全な空間配置を推論できるようにしました。
広範な実験により、レイアウト再構築の分野における既存の手法と比較して、RISEは面取り距離を601 TP3T(16cmまで)短縮し、IoU 581 TP3Tでミリ波ベースのターゲット検出を初めて実現することが実証されました。これらの結果は、RISEが単一の静止レーダーを用いた幾何学的認識とプライバシー保護型屋内シーン理解のための新たな基盤を築くことを示しています。
論文タイトル:RISE:単一静止レーダーに基づく屋内シーン理解
論文リンク:https://arxiv.org/abs/2511.14019
より広い視点から見ると、これら2つの研究は明確な技術的方向性を示している。AIはもはやセンサーの精度向上だけに留まらず、情報不足そのものを補う方向へと進化し始めているのだ。Wave-Formerによる遮蔽物の補完であれ、RISEによる屋内空間の推論であれ、その本質は生成モデルを用いて、不完全な、あるいは大きく歪んだ入力データを、構造的に完全で物理的に妥当な3次元世界へと変換することにある。つまり、将来の知覚システムはもはや「どれだけ見えるか」ではなく、「どれだけ推論できるか」に依存するようになるかもしれない。こうした流れの中で、ロボット工学、スマートホーム、さらには拡張現実といった分野は、目に見えないものから現実を再構築するという、全く新しい能力を獲得することが期待される。
参考文献:
1.https://arxiv.org/abs/2511.14152
2.https://news.mit.edu/2026/generative-ai-improves-wireless-vision-system-sees-through-obstructions-0319
3.https://arxiv.org/abs/2511.14019








