Command Palette
Search for a command to run...
データを共有せずに共同トレーニングが可能!UCLチームは、フェデレーテッドラーニングを用いて血液形態検査を再構築しています。

血液形態検査は、血液疾患の臨床診断において極めて重要なステップです。末梢血塗抹標本(PBS)または骨髄穿刺(BMA)における細胞形態を観察することで、医師は白血病、貧血、感染症、遺伝性血液疾患の種類を特定することができます。しかし、この検査は労働集約的であるだけでなく、経験豊富な専門家の力に大きく依存しています。特に低・中所得国(LMIC)では、熟練した専門医が不足しており、迅速で信頼性が高く、拡張性の高い血液学的診断が喫緊の課題となっています。
近年、人工知能(AI)とディープラーニングの発展により、血液形態解析に新たなソリューションがもたらされています。AIモデルは白血球の種類を自動的に識別し、医師の迅速な診断を支援します。研究によれば、ディープラーニングは自動血液診断に大きな可能性を秘めていることが示されています。しかし、実社会への応用には依然として大きな課題が残っています。モデルの学習はデータに大きく依存する一方で、臨床データは通常、複数の病院に分散しており、染色方法、画像機器、そして一部の希少な細胞種にばらつきがあります。こうしたデータの異質性は、新しい施設や患者集団におけるモデルの一般化能力の低下につながる可能性があります。
さらに重要なのは、医療データは患者のプライバシーに関わるものであり、機関間のデータ共有は厳しく制限されていることです。従来の集中型のトレーニング方法では、大量の機密性の高い医療データを集約する必要があり、高性能なコンピューティングリソースに依存するため、多くの機関では導入が困難です。プライバシーを保護しながら、複数機関による共同トレーニングを実現する方法は、医療AI分野において緊急に取り組むべき重要な課題となっています。
この文脈では、ユニバーシティ・カレッジ・ロンドン (UCL) のコンピュータサイエンス学部の研究チームは、白血球の形態分析のための連合学習フレームワークを提案しました。これにより、各機関はトレーニングデータを交換することなく、共同トレーニングを実施できます。複数の臨床施設からの血液塗抹標本を用いることで、フェデレーションモデルは、完全なデータプライバシーを維持しながら、堅牢かつドメイン不変の特徴表現を学習します。畳み込みネットワークとTransformerベースのアーキテクチャを用いた評価では、フェデレーショントレーニングは、施設間パフォーマンスと未知の施設への一般化において、集中型トレーニングよりも優れていることが実証されています。
「MORPHFED: 複数機関の血液形態分析のための連合学習」と題された関連研究成果が、arXiv でプレプリントとして公開されています。
研究のハイライト:
* 集中型トレーニングと比較して、連合型トレーニングはサイト間で優れたパフォーマンスを発揮し、未知の機関にも一般化できる能力を備えています。
この方法により、生データを共有することなく機関間での共同モデルトレーニングが可能になり、リソースが制限された医療環境に実行可能なソリューションが提供されます。

用紙のアドレス:
https://arxiv.org/abs/2601.04121
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「MORPHFED」と返信すると、完全な PDF を入手できます。
データセット: 実際の臨床現場における異質性を反映
この研究では、複数の医療機関からの血液塗抹標本データを使用し、トレーニング データがさまざまな細胞タイプをカバーしているだけでなく、実際の臨床設定における異質性も反映していることを確認しました。
具体的には、この研究では 2 つのセンターからの独立したデータセットを使用しました。これら 2 つのデータセットには、11 種類の一般的な細胞タイプ (好中球、好酸球、好塩基球、前骨髄球など) が含まれています。これは、染色と画像の違いを維持しながら分類目標の一貫性を確保し、実際の異種環境での連合学習の一般化能力をテストするために使用されます。
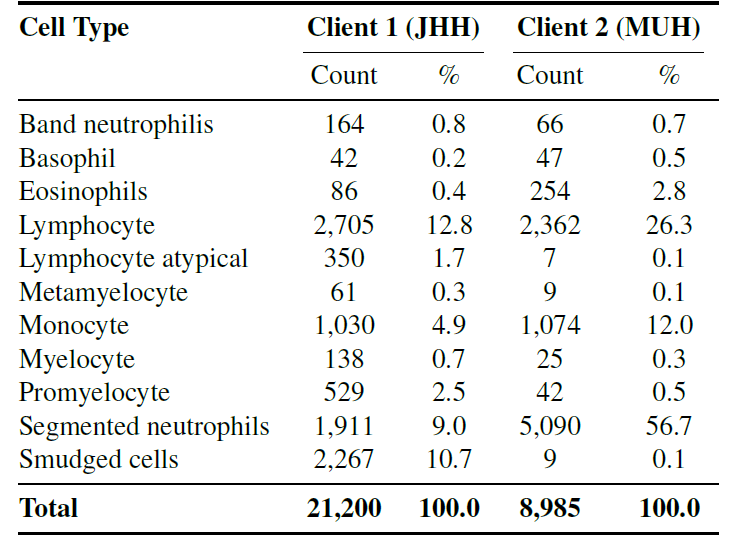
次の図は、さまざまなクライアント カテゴリの分布を示しています。
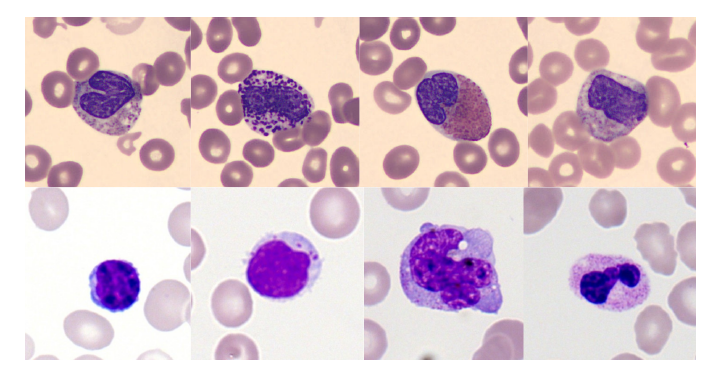
下の画像は、2 つのトレーニング データセットからのいくつかの細胞タイプの例を示しています。色付けスタイルの違いは明確に観察できますが、これはまさにモデルが克服する必要があるデータの偏りです。
さらに、全く未知の機関データに対するモデルのパフォーマンスを独立して評価するために、この研究では、バルセロナ臨床病院 (クライアント 3) から 12,992 枚の画像が保存されました。このデータセットは外部検証セットとして機能します。様々な画像装置、染色法、患者集団が含まれており、実世界の複数の施設にまたがるシナリオにおけるモデルの一般化能力を検証するために使用されます。
2種類のディープラーニングアーキテクチャと4つのフェデレーション集約戦略
この研究では、2 種類のディープラーニング アーキテクチャを採用しています。
* ResNet-34: ImageNet の事前トレーニング済み重みを使用する、畳み込みニューラル ネットワーク (CNN) に基づく従来のアーキテクチャ。
* DINOv2-Small: 自己教師あり Vision Transformer (ViT) をベースに、自己教師あり学習を通じてグローバルな画像の特徴をキャプチャします。
トレーニングは統一されたプロトコルに従います。フェデレーション モデルは 5 ラウンドのグローバル通信を実行し、各クライアントはラウンドごとに 5 回のローカル トレーニング サイクルを実行し、合計 25 回のトレーニング サイクルが実行されます。集中型ベースライン モデルは 25 回のトレーニング サイクルを使用し、次の図に示すように 4 段階のクロス検証を実行します。データは、60% トレーニング セット、13.33% 検証セット、13.33% ローカル テスト セット、および 13.33% グローバル テスト セットに分割されました。すべての画像は 224×224 ピクセルにサイズ変更され、診断形態情報を保持するために保守的なデータ拡張戦略 (移動 ±10%、回転 ±5°) が採用されました。
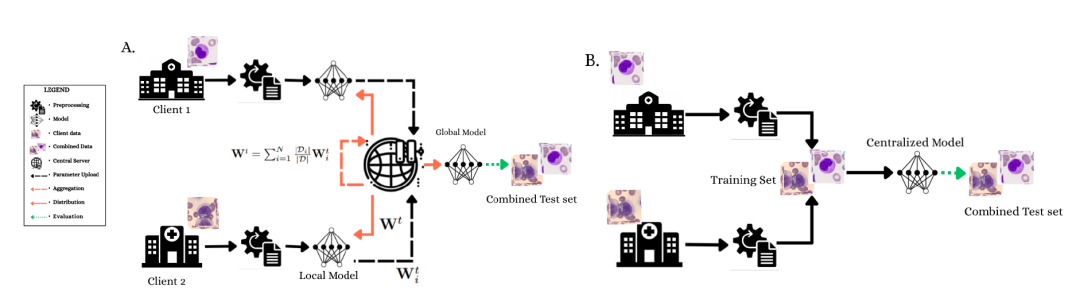
(A) 連合学習フレームワークは、クライアント 1 とクライアント 2 がローカルでモデルをトレーニングし、パラメータが中央サーバーに集約される、プライバシー保護の共同トレーニング プロセスを示します。
(B) 統合されたデータセットへのフルアクセスと 4 段階のクロス検証を備えた集中型トレーニング パラダイム。
両アーキテクチャとも選択的ファインチューニングを採用しました。ResNet-34は初期の層を固定し、最後の3つの残差ブロック(約1100万パラメータ)のみを学習しました。DINOv2-Smallは最初の8つのTransformerブロック(0~7)を固定し、ブロック8~11(約900万パラメータ)を学習しました。クライアント3のデータは学習プロセス全体を通して分離されたまま保持され、最終モデルの新しい機関データへの汎化能力を評価するためにのみ使用されました。
フェデレーテッド ラーニング フレームワークでは、中央サーバーがトレーニングの調整とグローバル パラメータの配布を担当しますが、元のデータにはアクセスしません。クライアントはローカルでトレーニングし、パラメータの更新のみを返します。
この調査では、4 つの連合集約戦略を採用しました。
* FedAvg: 極端なクラス分布に敏感なクライアント パラメータの加重平均を計算します。
* FedMedian: 各座標の中央値を取得します。異常なクライアントやビザンチンエラーに対してはロバストですが、少数派クラスのシグナルを抑制する可能性があります。
* FedProx: 非 IID データの収束安定性を高めるために、ローカル目的関数に近似制約を追加します。
* FedOpt: 集約された勾配に対して適応最適化 (Adam) を使用して学習率を動的に調整し、クライアントの異質性に対応して収束を高速化します。
さらに、深刻なクラス不均衡問題に対処するため、本研究では、Focal Loss、重み付きランダムサンプリング、勾配累積戦略を組み合わせることで、少数クラスからの学習信号が無視されないようにします。勾配クリッピング(最大ノルム1.0)により、学習中の安定した収束が保証されます。
モデルのパフォーマンスは、バランスのとれた精度を使用して評価され、さまざまな画像プロトコルと患者集団のデータに直面した場合のモデルの堅牢性をテストするための機関間の一般化能力に重点が置かれました。
フェデレーショントレーニングは、サイト間で優れたパフォーマンスを発揮し、未知の機関に一般化できる能力を備えています。
連合学習フレームワークの有効性を検証するために、研究者らは共同テストセット評価と外部分散データ一般化評価を実施しました。
① 共同テストセットの評価
このモデルは、2つのクライアントからのデータを含む共同データセットで評価され、その結果は以下の表に示されています。異なる集約手法は、異なるアーキテクチャ間でパフォーマンスに大きな違いをもたらすことが示されています。
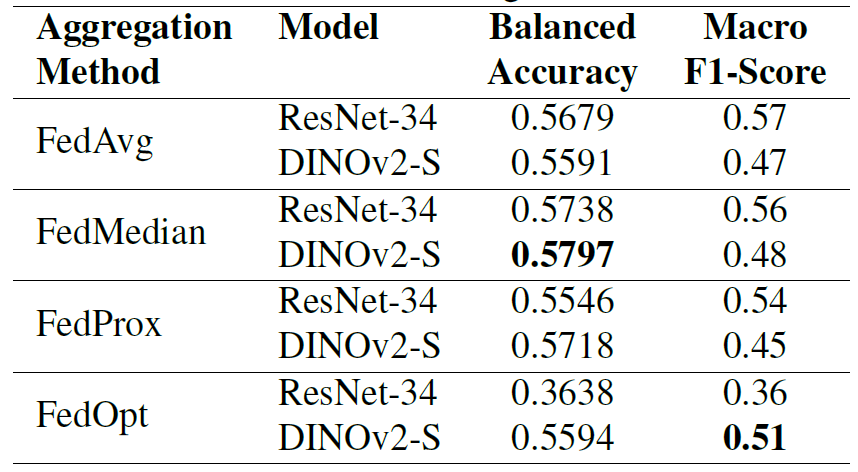
FedOpt が極端な変動性を示すことは注目に値します。ResNet-34 ではパフォーマンスが非常に低く (バランス精度 0.3638)、DINOv2-S では競争力のあるパフォーマンスを維持しています (バランス精度 0.5594)。比較すると、FedAvg と FedProx は両方のモデルで比較的安定したパフォーマンスを示しました。FedMedian は 2 つのアーキテクチャ間で最も一貫したパフォーマンスを発揮し、ResNet-34 では 0.5738、DINOv2-S では 0.5797 というバランスの取れた精度を達成しました。
結果は、フェデレーションラーニングによってパフォーマンスが大幅に向上し、単一機関のデータのみを使用してトレーニングされたモデルと比較して、データを共有せずに共同トレーニングを行うことの利点を実証しました(58% vs 52%、バランス精度)。フェデレーションモデルは、すべてのデータを集中的にトレーニングしたモデルよりもわずかにパフォーマンスが劣るものの、完全なデータプライバシーを維持しながら、同等の精度を達成しています。
② 外部分散データの一般化評価
バルセロナのクライアント3外部検証データセットを用いた評価では、下表に示すように、統合型学習法(FedMedianとFedOpt)の両方が、全く未知の機関データを用いた集中型学習法よりも優れた性能を示しました(バランス精度は67%対64%)。これは…フェデレーショントレーニング中に異種の組織的特徴(画像機器、患者集団、染色方法など)にさらされると、モデルはより一般化可能な形態学的特徴を学習できるようになります。
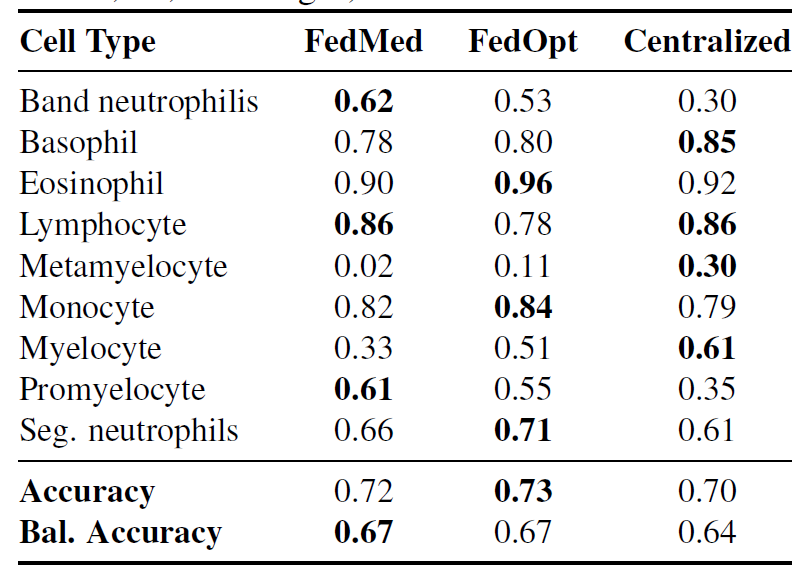
FedMedian は、特に少数の細胞タイプで顕著な改善を示しました。桿体好中球 F1: 0.62 対中心好中球 0.30 (TP3T 1071 増加)、および前骨髄球 F1: 0.61 対中心好中球 0.35 (TP3T 741 増加) です。結果は、診断上の特徴がさまざまな機関のプロトコルの下で効果的に保存されたことを示しています。しかし、すべての方法において後骨髄球の識別は依然として困難であり(F1:0.02~0.30)、これは極めてまれなクラスから堅牢な表現を学習することの根本的な難しさを反映しています。
③ アーキテクチャと集約戦略の相互作用法則
研究者らはさらに、アーキテクチャと集約戦略の主要な相互作用を特定しました。FedMedianはアーキテクチャ間の堅牢性を提供しますが、希少クラスには悪影響を及ぼします。一方、FedOptは少数クラスにおける細胞信号の忠実度を維持する点で優れていますが、アーキテクチャに依存します。DINOv2-Sの事前学習済みTransformerアーキテクチャは非IIDデータ分布に対して高い堅牢性を示しますが、ResNet-34は勾配衝突に対してより敏感です。
全体として、これらの調査結果により、連合学習は、血液画像分析のための堅牢でプライバシーを保護し、一般化可能なフレームワークとして位置付けられます。
フェデレーテッド ラーニングは、医療の「データ サイロ」を打破する鍵となります。
フェデレーテッドラーニングは、分散データ環境向けの協調型機械学習パラダイムです。その中核となる概念は、元のデータを集中管理することなく、モデルを共同で学習することです。フェデレーテッドラーニングのフレームワークでは、参加機関(病院、研究所、研究センターなど)がモデルをローカルで学習し、モデルパラメータまたは勾配の更新のみを中央サーバーにアップロードします。サーバーはこれらの更新を集約してグローバルモデルを生成し、各ノードに配布して反復学習を行います。この「データはドメイン内に留まり、モデルは協調する」というメカニズムにより、フェデレーテッド ラーニングにより、データ プライバシーを効果的に保護し、厳格なデータ コンプライアンス要件を満たしながら、組織間での知識共有が可能になります。
ここ数年、多くの組織がフェデレーテッドラーニングを活用してヘルスケア業界を強化する方法に取り組んできました。その代表的な例が、エンドツーエンドのAIバイオテクノロジー企業であるOwkinです。同社は、フランスの注目すべきAIスタートアップ20社、2023年最も注目すべき医療・テクノロジー系スタートアップ企業、最優秀医療技術賞、そしてForbes AI 50に選出されています。
Owkin は、AI テクノロジーを活用して、多様な患者データからさまざまなバイオマーカーを識別し、患者をサブグループに分類し、各患者を最適な治療対象とマッチングさせ、標的を絞った医薬品の開発を促進し、疾患診断ツールを最適化し、真に個別化された医療を実現することに取り組んでいます。上記の目標を達成するための鍵は、患者データのプライバシーを確保しながらデータを共有する方法にあります。この問題に対処するため、Owkinはフェデレーテッドラーニングを採用しています。この技術の普及を促進するため、Owkinはフェデレーテッドラーニングソフトウェア「Substra」をオープンソース化しました。Substraは臨床研究、医薬品開発、その他のアプリケーションで使用できます。
オープンソースのアドレス:
医用画像分野では、フェデレーテッドラーニングは「データサイロ」やプライバシーコンプライアンスの課題を克服するための重要な技術的アプローチと考えられています。医用画像データは非常に機密性が高く、患者のプライバシーや厳格な規制(GDPRやHIPAAなど)に関係します。従来の集中型のトレーニングでは、倫理的な承認、法的リスク、国境を越えたデータ転送の制限といった実際的な障害に直面することがよくあります。フェデレーテッドラーニングは、複数の病院が生の画像データを共有することなく共同でモデルをトレーニングすることを可能にし、異なるデバイス、染色プロトコル、患者集団にわたるモデルの汎化能力を向上させます。既存の研究では、放射線画像、デジタル病理学、超音波画像などの分野で、連合学習により集中型トレーニングに近い、あるいはそれを超える機関間一般化パフォーマンスを達成できることが示されています。特に外部データテストにおいて、より強力な堅牢性を発揮します。
より広い視点から見ると、連合学習に代表される「分散協調知能」モデルは、将来の医療AIの大規模展開において重要な基盤となりつつあります。プライバシー保護を前提とした大規模医療モデルの訓練を実現するだけでなく、機関横断的な臨床意思決定支援システムやグローバルな共同医療研究プラットフォームの技術基盤も構築します。血液形態解析などの特定の分野において、連合学習はAIを単一機関の実験室アプリケーションから、地域やシステムを横断する臨床グレードのインテリジェント診断サービスへと進化させ、精密医療やデジタルヘルスケアの重要な支援を提供することが期待されています。
参考文献:
1.https://arxiv.org/abs/2601.04121
2.https://mp.weixin.qq.com/s/Lf6N7EUHlhibLNc9YXWjTQ








