Command Palette
Search for a command to run...
NeurIPS 2025 | MIT は、天文学、物理学、生物医学の異常データに非常に敏感な自動化された科学的発見ツールである AutoSciDACT を提案します。

歴史を通して、科学的発見にはしばしば偶然の要素が絡み合ってきました。例えば、ペニシリンはカビの生えたペトリ皿の中で偶然発見され、宇宙マイクロ波背景放射はアンテナが捉えた「異常なノイズ」から発生しました。こうした偶然の観測は、最終的に人類文明の進歩の重要な原動力となりました。今日の「データ集約型」研究環境においては、膨大な学際的データの中に、より奇妙で説明のつかない観測が含まれており、偶然の科学的発見の可能性は理論的に倍増しています。しかし、逆説的に言えば、複雑で膨大な研究データから「新たな発見」を正確に捉えることは、干し草の山から針を見つけるよりもはるかに困難です。
伝統的な科学的発見方法は、科学者の直感と専門知識に大きく依存しており、「新発見」の真の科学的価値を判断するには、観察、調査、仮説、実験、検証という複雑なプロセスを必要とします。しかし、科学データの爆発的な増加と複雑化に伴い、鋭い観察のみで「新発見」を特定することは事実上不可能になっています。人工知能と大規模言語モデルに基づく自動化された科学的探究方法は近年有望視されていますが、しかし、厳密かつ自動化された仮説検証と検証が可能な統合フレームワークが不足しているため、このような方法を用いても、「意志はあっても能力が足りない」ということは避けられません。
科学的発見の課題に対処するため、MIT、ウィスコンシン大学マディソン校、および国立科学財団の人工知能・基礎相互作用研究所 (IAIFI) のチームが、AutoSciDACT (異常対照テストによる自動科学的発見) と呼ばれる手法を提案しました。これを使用すると、科学的データにおける「新しい発見」の検出を自動化し、科学的調査を簡素化することができます。研究者らは、天文学、物理学、生物医学、画像処理の実際のデータセットと合成データセットでこの手法を検証し、この手法がすべての領域で少量の異常なデータ注入に対して非常に敏感であることを実証しました。
「AutoSciDACT: 対照的埋め込みと仮説検定による科学的発見の自動化」と題された関連研究成果が NeurIPS 2025 に掲載されました。
研究のハイライト:
* AutoSciDACT は、ドメイン間の転送可能性を備えた、科学データの新規性を検出するためのエンドツーエンドの一般的なフレームワークです。
* 科学的シミュレーション データ、手動でラベル付けされたデータ、および専門知識を比較次元削減ワークフローに統合することにより、体系的なプロセスが設計されました。
* 観測された異常の重要性を定量化し、異常が科学的に重要であるかどうかを統計的観点から判断するために、統計的に厳密な枠組みが構築されました。
* 結果は、4 つの大きく異なる科学分野における実際のデータで検証され、大きな有効性、説得力、および宣伝価値が実証されました。

用紙のアドレス:
https://openreview.net/forum?id=vKyiv67VWa
公開アカウントをフォローして「 オートサイダクト 完全なPDFを入手する
AIフロンティアに関するその他の論文:
https://hyper.ai/papers
データセット: 多様な学際的データセットがAutoSciDACTの優れたパフォーマンスを実証
AutoSciDACTの優れた性能を厳密に検証するために、研究者たちは、まったく異なる分野の 5 つのデータセットでこれをテストしました。これらのデータセットには、天文学、物理学、生物医学、画像処理の 4 つの異なる分野のデータと、合成的に構築されたデータセットが含まれています。
天文学データセットに関しては、研究チームは、ワシントン州ハンフォードとルイジアナ州リビングストンにあるレーザー干渉計重力波観測所(LIGO)が2019年4月から2020年3月にかけて実施した第3回観測期間の重力波データを天文学的ベンチマークとして選定した。このデータは、2つのチャンネル(干渉計ごとに1チャンネル)からの50ミリ秒間隔の時系列信号で構成され、4096Hzの周波数でサンプリングされた(チャンネルあたり200回の測定)。データには、「純粋なノイズ」、「機器干渉」、「既知の天体物理学的信号」、そして「ホワイトノイズバースト(WNB)」と呼ばれる隠れた信号(異常現象として)など、様々なカテゴリーのデータが含まれていた。WNB信号は事前学習中に除外され、その後データに注入され、モデルが重力波信号からこの目に見えない信号を識別できるかどうかをテストした。
物理学データセット研究チームは、粒子物理学のベンチマークとしてJETCLASSデータセットを選択しました。これは、大型ハドロン衝突型加速器(LHC)における陽子-陽子衝突から得られたシミュレーションによる「ジェット」を含む大規模データセットです。本研究では、このデータセットのサブセット、すなわち量子色力学(QCD)過程(クォーク/グルーオン)、トップクォーク崩壊(t → bqq′)、およびW/Zベクトルボソン崩壊(V → qq′)からのジェットを使用しました。また、増強ヒッグス粒子からボトムクォークへの崩壊(H → bb¯)からのシグナルジェットも保持しました。研究チームは、粒子物理学に適したTransformerアーキテクチャの派生型であるParticle Transformer(ParT)をコントラスト・エンコーダとして使用しました。
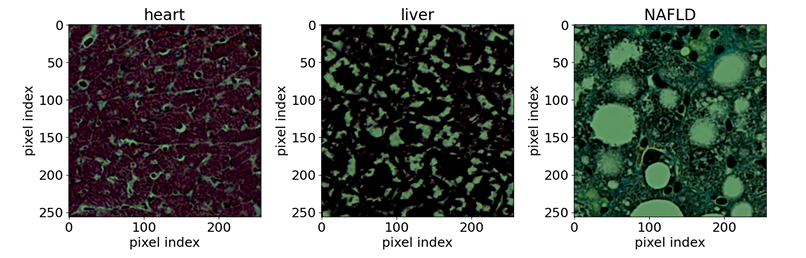
バイオメディカルの分野では、研究チームは、公開されている染色組織サンプルの光学顕微鏡画像を使用しました。参照サンプルには、マウスの7種類の組織(脳、心臓、腎臓、肝臓、肺、膵臓、脾臓)とラットの正常肝臓組織1種類が含まれていました。研究目的は、非アルコール性脂肪性肝疾患(NAFLD)によって引き起こされるマウスの異常肝臓組織を検出することでした。入力サンプルは、マッソントリクローム染色を用いて染色された全切片画像から抽出された256×256ピクセル解像度の組織切片です。バックボーンネットワークにはEfficientNet-B0を使用しました。
画像科学の観点から言えば、研究チームはCIFAR-10画像データセット(合計5万枚の画像)を使用し、最初のクラスを異常クラスとしてランダムに選択し、残りの9つのクラスについて事前学習を行いました。発見フェーズでは、CIFAR-10テストセットにCIFAR-5mから10万枚の画像を追加し、仮説検定に利用可能なデータポイント数を増やしました。エンコーダーバックボーンには、事前学習済みの重みを持つResNet-50を使用し、最後の全結合層のみをわずかに大きいMLPに置き換え、CIFARのコントラスト埋め込みタスクで微調整を行いました。
合成データセットに関しては、AutoSciDACTの中核機能を実証し、実際の科学データセットの特定の詳細がAutoSciDACTの性能に影響を与えないことを確認することが主な目的です。合成データセットはX⊂R^D+Mで構成され、D個の意味のある次元とM個のノイズ次元を含みます。ノイズ次元は0から1まで均一に生成され、意味のある次元は、均一な0-1平均とランダムに生成された共分散(均一分布0、0.5)を持つN個のガウスクラスターで構成されます。その後、すべての次元はランダムに回転され、元の有効な識別変数が隠蔽されます。トレーニングは対照埋め込み法を用いて行われ、N-1個のクラスターのみをトレーニングデータとして使用し、1つのクラスターを検出対象の「シグナル」として確保します。トレーニングに使用される基本モデルは、単純多層パーセプトロン(MLP)です。
さらに、モデルのクロスドメイン汎化能力をさらに検証するため、蝶の雑種を識別するためのゲノムデータセットや、LHCヒッグス粒子におけるテトラレプトンの崩壊に関する実データなど、他のデータセットを用いた補足検証も実施しました。まとめると、これらの異なるデータセットはすべて「背景データ」と「異常信号データ」を用いて構築され、それぞれモデルの事前学習と、モデルが新規性を検出できるかどうかの検出に使用されました。検証結果はすべて、AutoSciDACTが科学データにおける新規性を検出するための汎用的なプロセスとして有効であること、そしてクロスドメイン汎化能力も実証しています。
モデルアーキテクチャ:「事前トレーニング」+「発見」の2段階プロセスが科学的発見のための新しい方法を生み出す
AutoSciDACT の中核は、「事前トレーニング - 検出」という 2 つのステップです。低次元の特徴埋め込みと統計テストを組み合わせることで、高次元の科学データから統計的に有意な「新しいシグナル」を抽出できます。
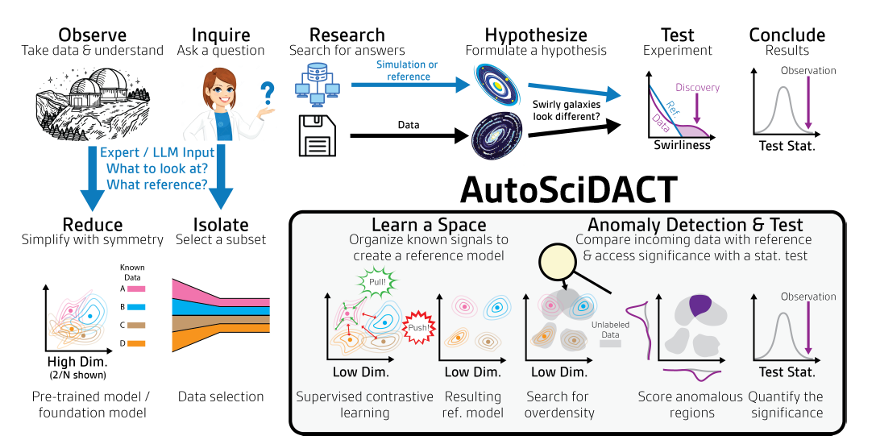
具体的には、事前学習段階では高次元データの冗長性の問題に対処します。主に、元の科学データに含まれる可能性のある数百または数千次元の入力特徴を低次元ベクトルに圧縮し、データの主要な意味的特徴、つまり科学的な意味でのコア情報を保持することで、後続の分析の基盤を築きます。
実装面では、事前学習済みパイプラインのバックボーンは、対照学習によって学習されたエンコーダ fθ : X → Rᵈ です。これは、高次元入力空間 X の生データを Rᵈ の低次元表現にマッピングします。対照学習の目的は、学習空間において類似入力(正のペア)間のアライメントを最大化し、類似しない入力(負のペア)を分離するように設計されています。基盤となるフレームワークは、エンコーダ fθ と射影ヘッド gϕ を学習する SimCLR を使用しています。トレーニング後、最終的な低次元埋め込みを出力するためにエンコーダー fθ のみが保持されます。実際には、教師あり対照学習(SupCon)が用いられます。この学習では、ラベル付き学習データを用いて、同じクラスの正対と異なるクラスの負対を作成します。損失関数はSupConの損失です。正対ペアの構築を補完するために、ドメイン知識を組み込んだデータ拡張戦略を設計できます。さらに、教師ありクロスエントロピー損失(LCE)をオプションで追加することができ、その結果、損失はL = LSupCon + λCELCEとなります(λCEは、分類目的が支配的にならないように0.1から0.5の範囲です)。
検出フェーズでは、異常検出と仮説検定のために、NPLM (New Physics Learning Machine) フレームワーク内の前のステップで取得された低次元埋め込みを利用します。検索データ内の潜在的な「新しいシグナル」を検索し、統計的テストを通じてその重要性を定量化します。
このフェーズでは、研究者は埋め込みベクトルfθを用いて未知のデータセットを処理し、低次元空間における背景分布から逸脱する異常なクラスター、密度の歪み、または外れ値を探します。この探索プロセスでは、古典的な科学的仮説検定アプローチが採用されています。既知の背景で構成される参照データセットRと、構成が未知の観測データセットDを比較し、RとDが同じ分布を持つという帰無仮説を採択または棄却します。この仮説検定は、Neymanらによって提案された古典的な尤度比検定に基づくNPLMアルゴリズムを用いて行われます。表現力豊かな学習済み埋め込みベクトルと組み合わせると、このモデルは新しい信号に対して非常に敏感になります。
事前学習における次元削減は非常に重要です。なぜなら、NPLMを含むあらゆる統計的検定手法の有効性は、データの次元数が増加するにつれて著しく低下するからです。言い換えれば、高次元化には統計的に有意な小さな信号を検出するためにより大きなサンプルサイズが必要になりますが、実際の科学研究では、サンプルサイズがそのような高次元の要件を満たせないことがよくあります。したがって、高次元データを圧縮することによってのみ、NPLMのようなツールは効果的に機能し、統計的に有意な異常を発見し、その科学的価値を高めることができます。
実験結果: 多次元かつ広範なドメインの比較により、AutoSciDACTの移転可能性とドメイン間機能が明らかになった。
研究者たちは、同じ方法を使用して各データセットで AutoSciDACT をトレーニングおよび評価し、各データセットの特定のニーズに合わせて事前トレーニング段階でわずかな調整のみを行いました。
すべてのエンコーダの埋め込み次元はd=4です。埋め込み結果は下の図のように視覚化されています。さらに、この実験では、教師ありベンチマーク、理想的な教師ありベンチマーク、マハラノビス ベースラインの 3 種類の比較ベンチマークを設定しました。
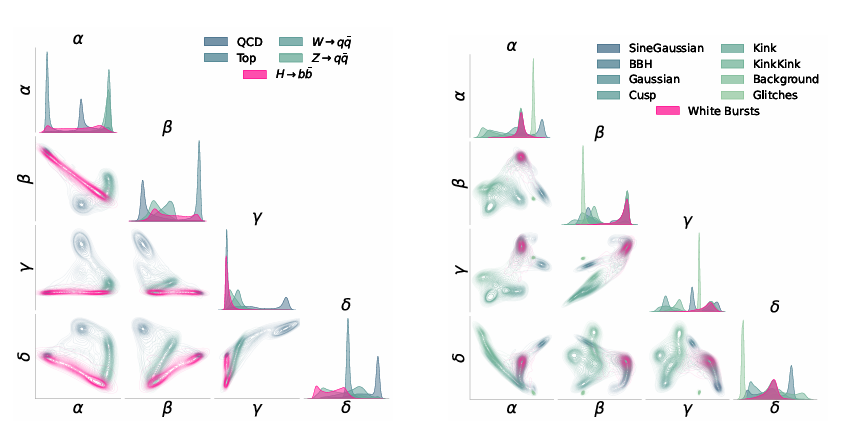
下図に示すように、NPLMは11TP³Tという低い信号比率でも、統計的に非常に有意なバイアス(Z≳3またはp≲10⁻³)を検出できることが結果から示されています。埋め込み空間における信号分布を完全に理解した2つの教師ありベースラインは、信号感度の妥当な上限を提供し、場合によってはNPLMのパフォーマンスがこの限界に近づきます。約5σを超えると、一部の傾向は無効になりますが、この有意水準(p∼10⁻⁷)では、結果は機械定義です。
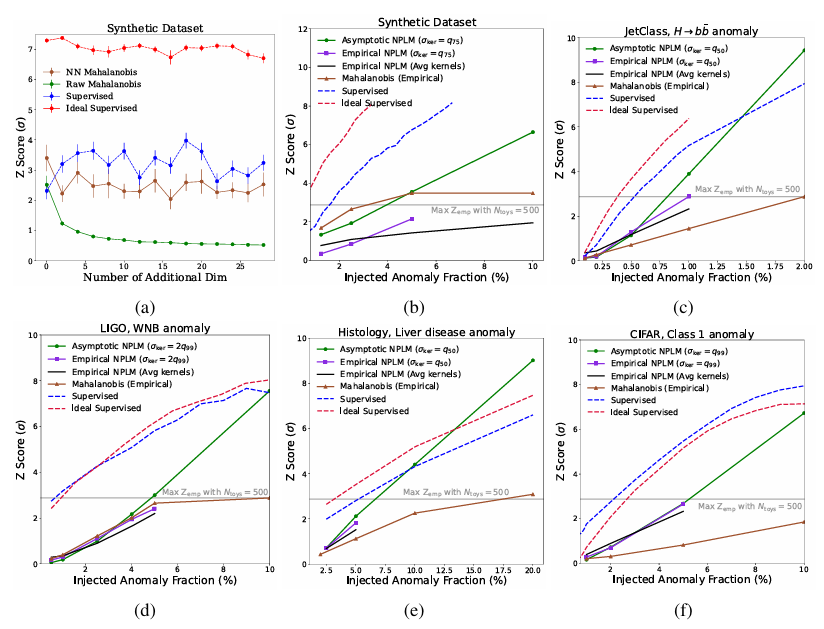
合成データに加えて他のすべてのデータセットでは、NPLM は Mahalanobis 距離ベースラインを大幅に上回ります。これは、入力空間内のさまざまな歪みをモデル化できるためです。
LIGOおよびJETClassデータセットにおいて、提案手法はZスコア3で教師あり学習の上限に近づきました。これは、それぞれの分野におけるすべての異常検出アルゴリズムに匹敵するか、それを凌駕する数値です。天文学と素粒子物理学では、統計的に進化した異常検出技術が長年利用されてきましたが、組織学への適用は、科学分野を超えた方法論の移植性を示しています。
組織学的には、実験では、ラベル情報を使用して構築された埋め込み空間が、データ拡張のみに基づいて構築された埋め込み空間よりも優れていることが示されています。AutoSciDACTの助けを借りて、研究者たちは、組織のごく一部にしか存在しない可能性のある局所的な異常を検出できる新たな手法を導入しました。この能力は、疾患の早期発見や、病理学者による毒性化合物の特定を支援する上で非常に重要です。
データが爆発的に増加する時代に、「AI 科学者」が現実のものとなりました。
AIの波は押し寄せ、あらゆるものを破壊しようとしています。科学研究の最前線である科学探究は、AIの力によってかつてない変化を遂げており、AIの波によって大きく変貌を遂げた中核分野となっています。
前述の論文で言及されているAutoSciDACTに加えて同じ分野では、Google、スタンフォード大学などのチームも、人間の科学者を模倣できるAI共同科学者を提案している。人間と同じように、アイデアを生み出し、議論し、疑問を投げかけ、最適化と改善を行うことができます。具体的には、Gemini 2.0を基盤とするマルチエージェントシステムであり、科学者が新たな独創的な知識を発見し、既存のエビデンスに基づき、Science Journalが提供する研究目標とガイダンスと連携して、実証可能な革新的な研究仮説と解決策を提案するのを支援します。
論文のタイトル:AI共同科学者を目指して
用紙のアドレス:https://arxiv.org/abs/2502.18864
さらに、AIの科学研究能力は拡大を続けており、「電子に関する研究を自動で考える」から「完全な科学論文を書く」まで進化しています。オックスフォード大学とコロンビア大学のチームは、そのようなAI科学者を提唱しています。これは、完全に自動化された科学的発見のための最初の包括的なフレームワークです。これにより、高度な大規模言語モデルが独立して研究を行い、その成果を発信することが可能になります。簡単に言えば、このAI科学者は、斬新な研究アイデアを生み出し、コードを記述し、実験を行い、結果を視覚化し、完全な科学論文を執筆して成果を記述し、そして評価のための模擬査読プロセスを実行することができます。
論文のタイトル:AI科学者:完全自動化されたオープンエンドの科学的発見に向けて
用紙のアドレス:https://arxiv.org/abs/2408.06292
今年上半期、AI Scientistは重要なアップグレードを実施し、AI Scientist-v2へと進化しました。前バージョンと比較して、AI Scientist-v2 は、人間が移植可能なコード テンプレートに依存しなくなり、さまざまな機械学習ドメインにわたって効果的に一般化できます。AI Scientist-v2は、専用の試験管理エージェントによって管理される、革新的なプログレッシブエージェントツリー探索法を採用し、視覚言語モデル(VLM)フィードバックループを統合することでAIレビューコンポーネントを強化し、グラフの内容と美観を反復的に最適化します。研究者は、ICLRの査読ワークショップに完全に自ら執筆した3本の論文を提出することでAI Scientist-v2を評価し、非常に肯定的な結果を得ました。そのうち1本の論文は、人間の平均的な閾値を超える高いスコアを獲得し、完全にAIによって生成された論文が査読を通過した初めてのケースとなりました。
論文のタイトル:AI サイエンティスト v2: エージェントツリー探索によるワークショップレベルの自動科学的発見
用紙のアドレス:https://arxiv.org/abs/2504.08066
AIと科学探究は、仮説形成の支援から完全に自律的な科学研究、そして単一領域の検証から幅広い学際的応用へと、深く融合し進化していることは明らかです。これらのシステムは、従来の科学的発見における効率性のボトルネックを打破するだけでなく、「経験主導型」から「データ主導型」への科学的発見の変革を推進します。将来、人間と機械の協働モデルの実現により、AIは科学界にとって効率的な発見の新たな章を開き、世界文明の発展に新たな勢いをもたらすでしょう。








