Command Palette
Search for a command to run...
イェール大学は、2,000人を超えるAI化学専門家のチームを構築し、効率的な専門化と最適な合成経路の特定を可能にするMOSAICを提案しました。
現代の合成化学は、知識の急速な蓄積とその応用・変換の効率性の間に、顕著な矛盾に直面しています。毎年数十万件もの関連論文が発表され、利用可能な合成知識の総量は数百万に達しています。しかし、これらの知識の大部分は非構造化テキストの形で様々なデータベースに散在しており、著しい断片化を呈しています。従来の文献検索や手作業によるスクリーニングに頼ることは、時間と労力を要するだけでなく、異なる分野にまたがる反応の種類を体系的に網羅することも困難です。その結果、文献に埋もれた膨大な量の貴重な情報を抽出し、実行可能な実験プロトコルに変換することが困難になっています。
こうした知識管理のジレンマに直面し、合成実践における中核的なニーズは、高い再現性で完全な実験手順をいかに効率的に得るかにますます焦点が当てられています。これらの手順には、試薬の選択、化学量論制御、温度プログラミング、後処理手順など、多くの重要なパラメータが関わってきます。
現在のところ、この分野の発展は主に 2 つの側面によって制限されます。第一に、専門家の経験は、拡大し続ける反応空間をカバーするのに苦労しており、学際的な合成課題においてしばしば高い試行錯誤コストを伴います。第二に、人工知能の急速な発展にもかかわらず、化学における汎用モデルの応用は依然として信頼性の不足、「錯覚」の影響を受けやすく、信頼性評価が不十分であり、実験レベルの精度要件を満たせていません。したがって、膨大で断片的な化学知識を構造化された信頼性の高い合成ガイダンスに変換することが、この分野の効率性ボトルネックを克服するために不可欠となっています。
この文脈では、イェール大学の研究チームは最近、一般化された大規模言語モデルを多数の専門化学専門家から構成される共同システムに変換する MOSAIC モデルを提案しました。専門的な分業を通じてモデルの錯覚を効果的に抑制することで、定量化可能な不確実性評価を提供し、反応の記述から完全な実験プロトコルまでの体系的な生成を実現します。これにより、創薬や材料開発などの分野で科学研究の効率が大幅に向上すると期待されています。
「AI支援による化学合成のための集合知」と題された関連する研究成果がNature誌に掲載されました。

用紙のアドレス:
https://www.nature.com/articles/s41586-026-10131-4
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「MOSAIC」と返信すると、完全な PDF を入手できます。
AIフロンティアに関するその他の論文:
ピスタチオデータベースをベースに、それぞれの強みを持つ「AI化学専門家」を育成します。
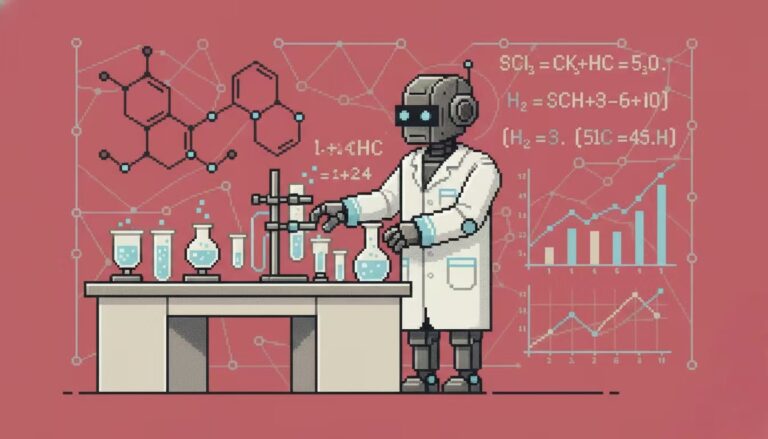
この研究は、主に世界中の特許文献を情報源とする、高度に構造化された化学反応に関する商用知識ベースであるPistachioデータベースを用いて実施されました。特許に記載されている反応物、生成物、試薬、溶媒、収率、主要工程のテキスト記述を体系的に抽出・標準化することで、データベースはこれらの記述を機械可読形式(例えば「SMILES」という文字列)に統一的にエンコードしています。研究チームは、データセット全体を直接使用するのではなく、厳格な品質審査プロセスを実施しました。主な基準は、反応記録には実験手順の詳細かつ実用的な説明が含まれている必要があるというものでした。これにより、反応物と生成物の関係を単にマッピングするのではなく、トレーニング対象のモデルが「反応の結果が何であるか」だけでなく「反応を達成する方法」を学習できるようになります。
フィルタリングされたデータは、特別に設計されたカーネルメトリックネットワークによって、128次元の反応固有の指紋に変換されました。このデジタル表現は、化学反応の本質的な変換特性を捉えることを目的としており、すべての指紋ベクトルは、広大な化学知識空間を表す「反応宇宙」を構成します。このベクトル空間に基づき、本研究では、FAISSライブラリを用いて実装された教師なしボロノイクラスタリングアルゴリズムを用いて、2,489個の重複しない特殊領域に分割しました。各領域は、化学的性質が非常に類似した反応タイプをクラスタリングしています。
最終的に、各ボロノイ領域内の応答テキストは、専用の Llama-3.1-8B-Instruct モデルを個別に微調整するために使用されました。その結果、それぞれが独自の強みを持つ2,489人の「AI化学専門家」が誕生しました。MOSAICフレームワーク全体の知識範囲と機能の限界は、この特許中心の学習データセットによって根本的に決定されます。これは、急速に発展している最先端分野(光化学など)において、システムのパフォーマンスが比較的限られている理由も説明しています。これらのコンテンツは、既存の特許データベースではまだ十分にカバーされていないからです。
MOSAIC: 多数の化学専門家から構成される分散型共同システム。
MOSAIC モデルの核となる設計思想は、汎用大規模言語モデル Llama-3.1-8B-instruct を多数の専門化学専門家で構成された分散型共同システムに変換することです。この探索駆動型アーキテクチャは、ハードウェアリソースの需要を大幅に削減し、大規模なコンピューティングクラスターに依存せずに、特定のタスクサブセットの学習に中規模のコンピューティング構成(例えば4基のGPU)のみを必要とします。このシステムは、エキスパート分業メカニズムを通じてモデルの錯覚を効果的に抑制し、定量化可能な不確実性評価を提供するとともに、システム全体を再学習することなく新しいエキスパートの動的な拡張をサポートすることで、柔軟性と持続可能性において大きなメリットを発揮します。
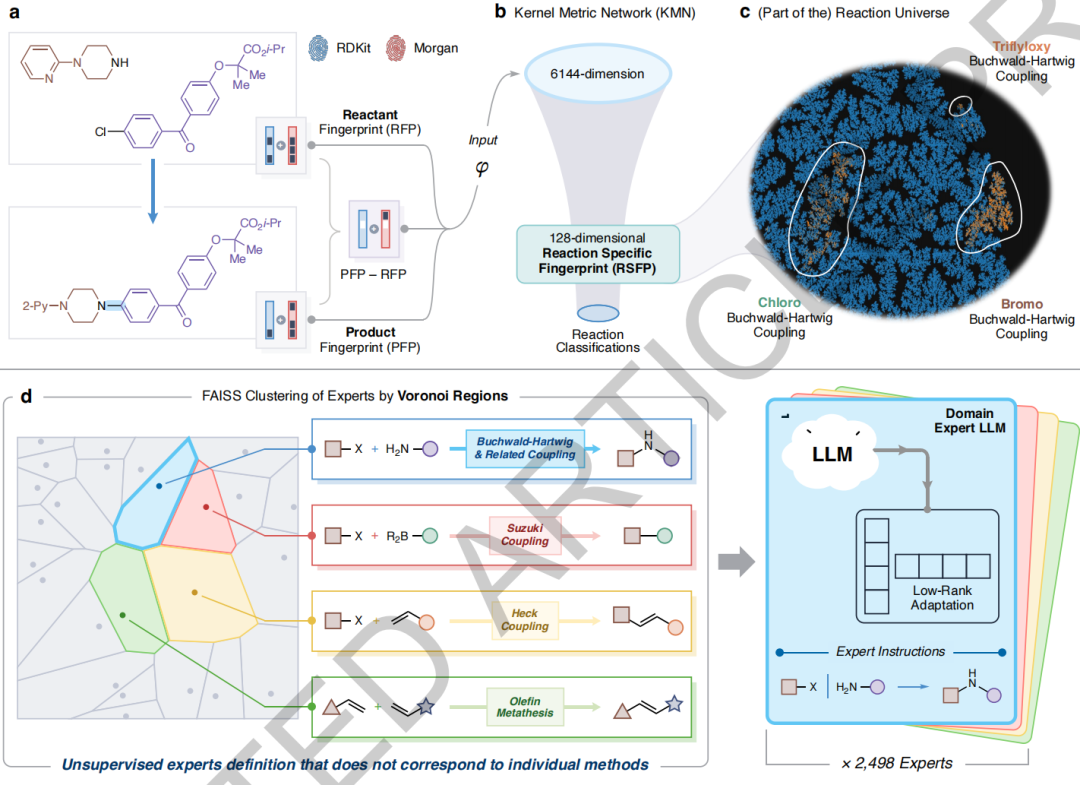
大規模なデータセットをトレーニングする際に大規模言語モデルが直面する計算と調整のボトルネックを克服するために、MOSAIC は次の 3 つの段階的なコンポーネントから構築されています。
応答類似度の測定:
本研究では、化学反応間の類似性を定量化するために、ニューラルネットワークベースの非線形マッピング(カーネルメトリックネットワーク、KMN)を設計した。SMILESによってエンコードされた反応を128次元の反応特異的フィンガープリント(RSFP)に変換し、それらのユークリッド距離を用いて反応カテゴリーの関係を近似することで、反応の本質的な変換特性を捉える。
知識空間のクラスタリング:
FAISS ライブラリの効率的なインデックス作成機能を活用して、RSFP ベクトル空間で教師なしボロノイ クラスタリングが実行され、高度にクラスタ化された化学特性を持つ 2,498 の特殊な領域に自動的に分割されます。各領域は化学知識の特定のドメインを表します。
ドメイン専門家のトレーニング:
反応データのクラスターごとに、専用のエキスパートモデルが個別に微調整されます。本研究では、2段階のトレーニング戦略を採用しています。まず、基本モデルをデータセット全体で微調整し、次に各クラスターのデータを用いて対応するエキスパートのドメイン知識を深めます。これにより、エキスパートは化学の一般的な理解を維持しながら、深い専門知識を習得できるようになります。
MOSAICはまずクエリ反応をRSFPとしてエンコードし、次にFAISSを用いてボロノイ領域と対応する専門家を迅速に特定します。例えば、クロロ芳香族炭化水素のブッフバルト・ハートウィッグカップリング反応の場合、システムはこの分野の専門家に依頼して、完全かつ読みやすい合成手順を生成します。実験検証により、手順に正確に従うことで、96% の収量で目的の製品が得られることがわかりました。
MOSAIC は、94.81% の TP3T コンポーネント カバレッジと 711% の TP3T 合成成功率を達成しました。
本研究では、多次元評価システムを通じてMOSAICモデルの総合的な性能をさらに検証しました。その核心的な価値は、膨大な文献知識を信頼性の高い合成知能に変換することにあります。
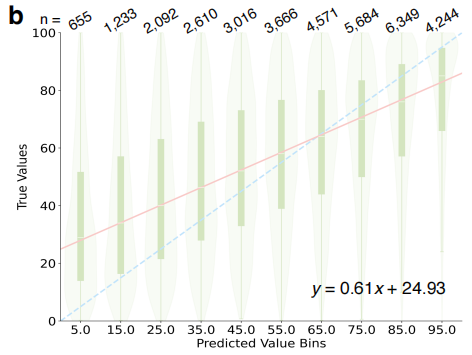
収量予測とコアコンポーネントの識別に関してはMOSAICモデルは、実験手順テキスト全体を解析することで、反応収率の定量的な予測を実現します。下図に示すように、ビニング戦略を適用した後、予測区間の中心は実際の収率の中央値と有意な相関を示しました(R² = 0.811)。このモデルは、主要な反応成分(試薬、溶媒)の特定において優れたカバレッジを示しています。上位 3 人の専門家の予測を統合した後、正しいコンポーネントの少なくともいくつかを特定する全体的な成功率は 94.8% と高くなります。予測条件が文献の記録と完全に一致しない場合でも、出力は化学的に実現可能な代替案であることが多く、深いレベルの専門的判断を反映していることは注目に値します。
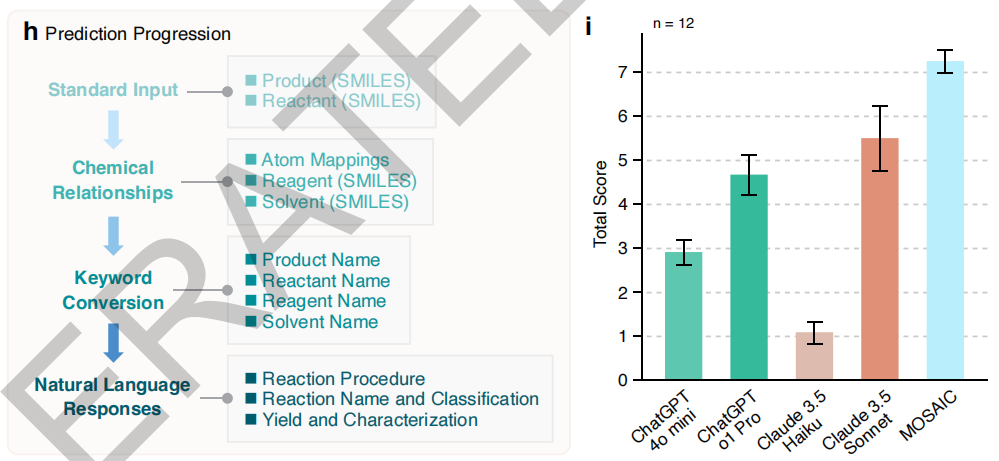
下図に示すように、12の重要な反応(鈴木カップリング、ブッフバルト・ハートウィッグアミノ化など)の比較試験において、MOSAICはChatGPT-4oやClaude 3.5などの汎用モデルを一貫して凌駕し、明確で実現可能な合成ガイダンスを提供しています。この優位性は、モデルのパラメータ数がわずか80億個であることを考えると特に顕著であり、ドメイン固有の微調整の有効性を実証しています。さらに重要なのは、MOSAIC は、不安定な命令コンプライアンスや恣意的な応答など、化学タスクにおける一般的なモデルに共通する問題を克服し、安定した信頼性の高い出力を提供します。これは実際の実験にとって非常に重要です。
提案されたフレームワークの実用性、汎用性、信頼性を評価するため、本研究では、現代の化学合成における基本反応について、高精度かつ最高レベルの予測を行うことで、広範な実験検証も実施しました。研究者らは、医薬品および材料開発に不可欠な、広く応用可能な触媒反応に焦点を当てました。ブッフバルト・ハートウィッグアミノ化によって形成される炭素-窒素結合は医薬品分子に広く見られるため、これらの困難な反応の条件を正確に予測しました。医薬品グレードの骨格の効率的な構築が達成され、天然物から機能性材料に至るまでの幅広い用途に不可欠なオレフィン変換において特に優れた利点が実証されました。
さらに、MOSAIC モデルの実用性は、多数の新規化合物の合成成功によって強力に実証されています。合成された 37 個のターゲット化合物のうち、35 個がモデルの最初の推奨で成功し、全体的な成功率は 71% でした。検証の範囲は、古典的なカップリング反応から選択的変換まですべてをカバーし、新しいアザインドール環化法の開発を導く能力を示す革新的なケーススタディも含まれます。
最も重要なのは、モデル内の信頼度指数(最も近い専門家の重心までの距離)が実験の成功率と明確な正の相関を示していることです。つまり、高信頼度の予測(距離<100)の成功率は75%を超えています。これは化学者に貴重な定量的な意思決定支援を提供し、高成功率の目標と探索的な試みの間でリソースを効果的に配分することを可能にします。
化学合成は精密インテリジェント製造の新時代へ
インテリジェントな化学合成を推進する世界的なプロセスにおいて、学界と産業界は分子の発見からプロセス生産までのチェーン全体を再構築するために、補完的な道に沿って協力しています。
大学の研究は、基盤となるコンピューティングの限界を克服し、科学研究のパラダイムを革新することに重点を置いた、未知の分野の先駆的な探究のようなものです。MITの研究者たちは、画像生成に使われる「拡散モデル」を化学反応の分野に巧みに応用した。主要な「遷移状態」構造の超高速計算を実現し、通常は完了に数日かかるタスクを数秒に圧縮し、0.08 オングストロームの原子レベルの精度で反応予測に関する前例のない微視的洞察を提供します。
一方、スタンフォード大学のチームは、研究の実施方法そのものを改革することに尽力しています。このシステムは、多分野にわたる仮想チームを自律的に形成できる AI 駆動型の「仮想実験室」を構築します。「主任研究員AI」の調整により、数秒で共同研究と議論が行われ、ワクチン設計などの複雑なテーマにおいて、従来のアプローチを凌駕する革新的なアイデアが生まれます。さらに、ハーバード大学などの研究機関による研究は、人工知能のシミュレーション能力をマクロスケールにまで押し上げています。彼らが提案する統一フレームワークは、数百万個の原子を含む複雑な強誘電体材料の精密シミュレーションに成功し、次世代の機能性材料を根本的に設計するための強力なデジタルレンズを提供しています。
学術界のパイオニア精神と比較すると、企業のイノベーションは、最先端のアルゴリズムを生産性と市場競争力につなげ、現実世界の課題を解決することに重点を置いています。ドイツの化学大手BASFは、AIをグローバルに展開し、研究開発を支援する「AI Chemist Copilot」だけでなく、…60%により新素材の開発サイクルが大幅に短縮されました。さらに、AI は生産最適化、物流計画、予知保全に深く統合されており、研究室から工場までのバリュー チェーン全体にわたって効率向上を実現します。
製薬分野では、スイスに本社を置くノバルティスのような企業がAIを「エンドツーエンド」で活用しています。Isomorphic LabsやSchrödingerといった専門企業との緊密な連携を通じて、新規ターゲットの発見、化合物の生成、安全性予測、臨床試験設計の最適化に至るまで、あらゆる重要な段階に人工知能を適用し、医薬品開発の確実性と成功率を大幅に向上させています。
学術界と産業界にまたがるこれらのブレークスルーを見ると、かつては個人の経験と試行錯誤の繰り返しに大きく依存していた伝統的な学問分野である化学研究は、データとアルゴリズムによって根本的に変革されつつあり、予測可能で計画可能、そして自動化された精密科学の新たな時代へと着実に進んでいます。疾病を克服する革新的な医薬品から、持続可能な開発に貢献するグリーンマテリアルまで、インテリジェントな化学合成のこの広範な変革は、現代の最も差し迫った課題への取り組みを支援する、前例のない中核的能力を生み出しています。
参考記事:
1.http://edu.people.com.cn/n1/2025/0730/c1006-40532541.html
2.https://cen.acs.org/pharmaceuticals/drug-development/Q-Novartiss-biomedical-research-head/103/web/2025/01








