Command Palette
Search for a command to run...
MiniCPM-V 4.0 はパフォーマンスにおいて GPT-4.1-mini を上回り、デバイス上の画像モデリングで新たな高みに到達しました。HelpSteer3 は AI の応答を人間の思考に近づけます。

マルチモーダル大規模言語モデル(MLLM)の技術的進化は、AIエコシステムの発展を牽引しています。スマートフォンやタブレットなどのモバイルデバイスにおけるリアルタイムインタラクションに対するユーザーの需要は著しく高まっています。しかし、従来の大規模モデルは優れた性能を提供する一方で、パラメータ数が多く、モバイルやオフラインのシナリオにおいてデバイス上での展開や運用が困難です。エッジ上の大規模モデルでは、複雑なタスクに関係する場合、依然としてクラウド側のサポートと最適化が必要であり、エッジのパフォーマンスとマルチモーダル機能にはまだ改善の余地があります。
この文脈では、清華大学自然言語処理研究所とMianbi Intelligenceが共同で、効率的な大規模エンドツーエンドモデルMiniCPM-V 4.0を発表しました。このモデルは、前身となるMiniCPM-V 2.6の強力な単一画像、複数画像、動画理解性能を継承するだけでなく、OpenCompass評価において、GPT-4.1-mini-20250414、Qwen2.5-VL-3B-Instruct、InternVL2.5-8Bといった主流モデルを画像理解能力において凌駕しています。また、パラメータ削減は4.1Bと半減し、導入閾値を大幅に引き下げています。研究チームは同時に、iPhoneとiPad向けのiOSアプリケーションもオープンソース化し、ユーザーが携帯電話で「クラウドレベルの機能とエッジレベルの効率」を体験できるようにした。
MiniCPM-V 4.0 は、エンドサイド MLLM の重要な探求として、端末の軽量な展開を促進してより広い開発スペースを開拓し、音声やビデオなどの他のモダリティをエッジ デバイスに拡張するための良い例を提供します。
現在、HyperAI公式サイトでは「MiniCPM-V4.0:極めて効率的な大規模オンデバイスモデル」を公開しています。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/pZ5aZ
8月11日から8月15日までのhyper.ai公式サイトの更新内容を簡単にご紹介します。
* 高品質の公開データセット: 10
*厳選された高品質なチュートリアル: 6
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
※8月提出締切:2
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
NuminaMath-LEANは、NuminaとKimiチームが共同でリリースした数学問題データセットです。自動定理証明モデルの学習と評価のために、手動で注釈が付けられた形式的な記述と証明を提供することを目的としています。このデータセットには、国際数学オリンピック(IMO)や米国数学オリンピック(USAMO)といった権威ある大会での問題を含む、10万問の数学競技問題が含まれています。
直接使用します:https://go.hyper.ai/YSJM2
2. Trendyol セキュリティ指示チューニングデータセット
Trendyolは、防御的なサイバーセキュリティのための高度なAIアシスタントを訓練するために設計された、セキュリティ指示チューニングデータセットです。このデータセットには、クラウドネイティブの脅威、AI/MLセキュリティ、その他の最新のセキュリティ課題を含む200以上のサイバーセキュリティ領域をカバーする53,202件の指示チューニング例が含まれています。防御的なセキュリティAIモデルの訓練に高品質なコーパスを提供します。
直接使用します:https://go.hyper.ai/hfxLQ
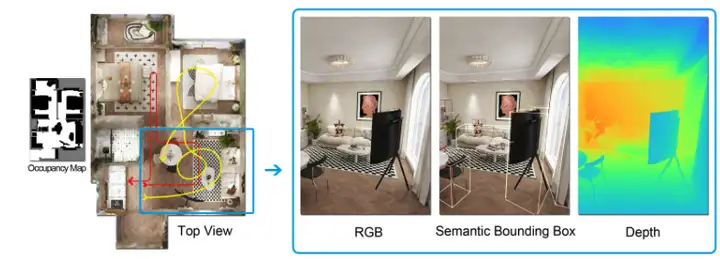
InteriorGSは、既存の屋内シーンデータセットの幾何学的完全性、セマンティックアノテーション、空間インタラクション機能の限界を克服するために設計された3D屋内シーンデータセットです。このデータセットは、高品質な3Dガウス散乱表現に加え、インスタンスレベルのセマンティックバウンディングボックスと、エージェントのアクセス可能な領域を示す占有マップを提供します。
直接使用します:https://go.hyper.ai/8pxTq
4. CognitiveKernel-Pro-クエリテキスト生成ベンチマークデータセット
CognitiveKernel-Pro-Queryは、Tencentが公開したテキスト生成ベンチマークデータセットで、長文テキスト処理におけるモデルのパフォーマンスを評価するために設計されています。このデータセットには10,000件以上の長文テキストが含まれており、ニュース記事、技術文書、書籍などの応用シナリオを網羅しています。
直接使用します:https://go.hyper.ai/onijU
Satellite Embeddingは、Googleが公開した地球観測データセットです。複数の情報源から空間、時間、測定コンテキストを統合し、地域規模から地球規模まで、地図や監視システムを正確かつ効率的に生成することで、非常に汎用性の高い地理空間表現を提供することを目的としています。
直接使用します:https://go.hyper.ai/Yfw8K

6. LongText-Bench テキスト理解ベンチマークデータセット
LongText-Benchは、中国語と英語の長い文章を正確に理解するモデルの能力を評価するために設計されたテキスト理解ベンチマークデータセットです。このデータセットには、長いテキストのレンダリングタスクを評価するための160個のプロンプトが含まれており、8つの異なるシナリオ(道路標識、ラベル付きオブジェクト、印刷物、ウェブページ、スライド、ポスター、見出し、会話)をカバーしています。
直接使用します:https://go.hyper.ai/k6Kj8
nuPlanは、Motionalが公開した自動運転データセットです。機械学習ベースのプランナー開発・トレーニングフレームワーク、軽量な閉ループシミュレーター、専用の動作計画メトリクス、そして結果を視覚化するためのインタラクティブツールを提供することを目的としています。このデータセットには、米国とアジアの4都市(ボストン、ピッツバーグ、ラスベガス、シンガポール)における1,200時間分の人間の運転データが含まれています。
直接使用します:https://go.hyper.ai/BcEC8

HelpSteer3は、NVIDIAが公開した人間の嗜好に関するデータセットです。人間のフィードバックと強化学習技術を用いて、ユーザーのプロンプトに対するモデルの応答性を向上させることを目的としています。このデータセットには40,476件の嗜好例が含まれており、それぞれにドメイン、言語、コンテキスト、2つの返答、2つの返答間の全体的な嗜好評価、そして最大3人のアノテーターによる個別の嗜好評価が含まれています。
直接使用します:https://go.hyper.ai/hByqe
NHR-Editは、多様な自然な編集指示に従うことができる汎用的な画像編集モデルの学習をサポートするために設計された画像編集データセットです。このデータセットには、286,608枚のユニークなソース画像と358,463枚の画像編集トリプレットが含まれています。各サンプルには、編集タイプ、スタイル、画像解像度などの追加メタデータも含まれており、きめ細やかで制御可能な画像編集モデルの学習に適しています。
直接使用します:https://go.hyper.ai/LZtkd

A-WetDriは、悪天候下における自動運転認識モデルの堅牢性と汎用性を向上させるために設計された、悪天候運転データセットです。このデータセットには、4つの環境シナリオ(雨、霧、夜間、雪、晴天)と様々な物体カテゴリ(自動車、トラック、自転車、オートバイ、歩行者、交通標識と信号)にわたる42,390件のサンプルが含まれています。
直接使用します:https://go.hyper.ai/W2XE7

選択された公開チュートリアル
1. MiniCPM-V4.0: 極めて効率的な大規模エンドツーエンドモデル
MiniCPM-V 4.0は、清華大学自然言語処理研究所とMianbi Intelligenceによってオープンソースで開発された、非常に効率的で大規模なオンデバイスモデルです。OpenCompassテストでは、MiniCPM-V 4.0は画像理解能力においてGPT-4.1-mini-20250414、Qwen2.5-VL-3B-Instruct、InternVL2.5-8Bを上回りました。
オンラインで実行:https://go.hyper.ai/pZ5aZ

2. 探索的データ分析 | XGBoost の SHAP 値の説明
このチュートリアルは、「最適な肥料を予測する」という多重分類問題を中心に展開し、データ探索からモデルトレーニング、解釈可能な分析までのエンドツーエンドのプロセスを詳しく説明します。
オンラインで実行:https://go.hyper.ai/41z6K
dots.ocrは、Xiaohongshuのhi研究室が開発した多言語文書レイアウト解析モデルです。17億パラメータの視覚言語モデル(VLM)をベースとし、レイアウト検出とコンテンツ認識を統合することで、適切な読み順を維持します。このモデルはシンプルで効率的なアーキテクチャを備えており、入力プロンプトを変更するだけでタスクを切り替えることができます。推論速度が速いため、様々な文書解析シナリオに適しています。
オンラインで実行:https://go.hyper.ai/JewLR

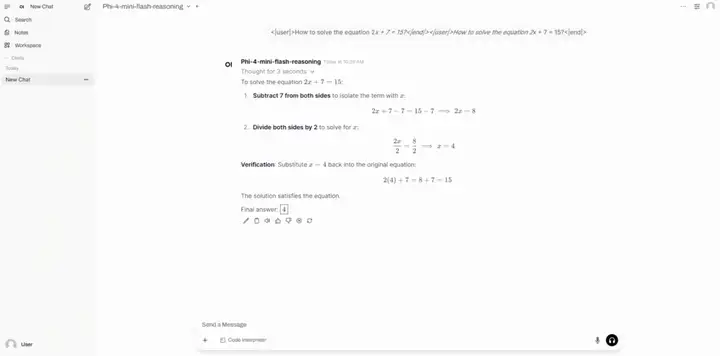
4. vLLM+Open-WebUIを使用してPhi-4-mini-flash推論を展開する
Phi-4-mini-flash-reasoningは、Microsoftチームがリリースした軽量なオープンソースモデルです。合成データに基づいて構築され、高品質で高密度な推論データに焦点を当て、さらに微調整することで、より高度な数学的推論機能を実現します。Phi-4モデルファミリーに属するこのモデルは、64Kのトークンコンテキスト長をサポートし、デコーダー・ハイブリッド・デコーダーアーキテクチャ、アテンションメカニズム、状態空間モデル(SSM)を組み合わせることで、優れた推論効率を実現しています。
オンラインで実行:https://go.hyper.ai/ENYcL
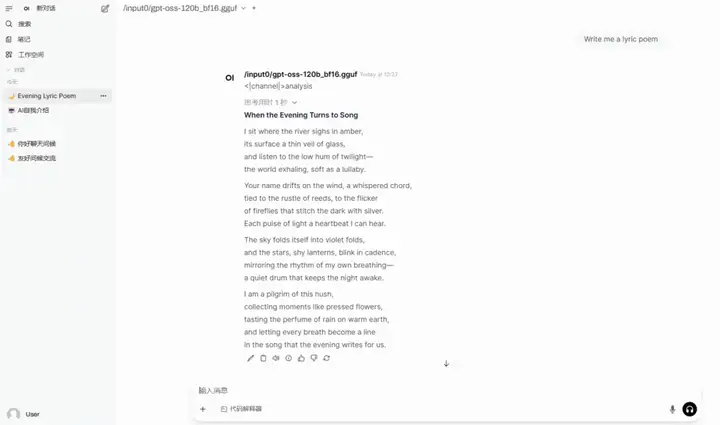
5. llama.cpp+Open-WebUI gpt-oss-120b をデプロイする
gpt-oss-120bは、OpenAIがリリースしたオープンソースの推論モデルで、強力な推論、エージェントベースのタスク、そして多様な開発シナリオ向けに設計されています。MoEアーキテクチャに基づくこのモデルは、128kのコンテキスト長をサポートし、ツール呼び出し、少数ショットの関数呼び出し、連鎖推論、健康に関する質問応答において優れた性能を発揮します。
オンラインで実行:https://go.hyper.ai/3BnDy
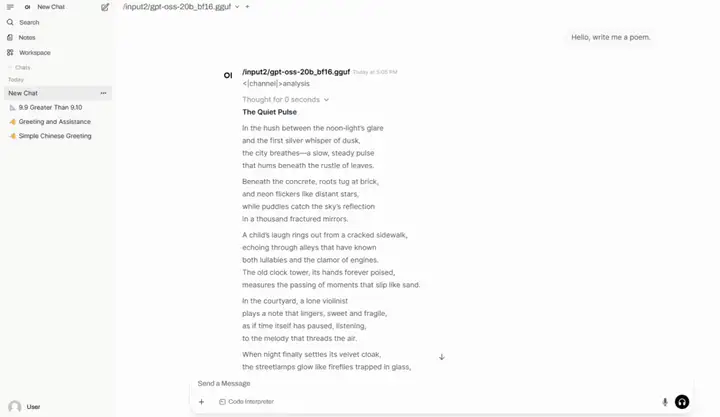
6. llama.cpp+Open-WebUI gpt-oss-20b をデプロイする
gpt-oss-20bは、OpenAIがリリースしたオープンソースの推論モデルです。低レイテンシ、ローカル、または特殊な垂直アプリケーションに適しています。コンシューマーグレードのハードウェア(ノートパソコンやエッジデバイスなど)でスムーズに動作し、o3-miniに匹敵するパフォーマンスを備えています。
オンラインで実行:https://go.hyper.ai/28FXJ
今週のおすすめ紙
1. ReasonRank: 強力な推論能力で文章のランキングを強化
推論集約性の高い学習データの不足により、既存のリランカーは多くの複雑なランキングシナリオにおいて性能が低下しており、ランキング機能はまだ開発の初期段階にあります。本論文では、推論集約性の高い学習データを自動的に合成するフレームワークを初めて提案します。このフレームワークは、複数のドメインから学習クエリと段落を抽出し、DeepSeek-R1モデルを用いて高品質の学習ラベルを生成します。さらに、データ品質を確保するために、自己整合的なデータフィルタリングメカニズムが設計されています。
論文リンク:https://go.hyper.ai/nmaou
2. WideSearch: エージェントによる広範な情報探索のベンチマーク
本論文では、大規模な情報収集タスクにおけるエージェントの信頼性を評価するために設計された新しいベンチマーク「WideSearch」を紹介します。これは、実際のユーザークエリに基づいて、15以上の異なる分野から厳選された200の質問で構成されています。各タスクでは、エージェントが大量のアトミック情報を収集し、明確に構造化された出力に整理することが求められます。
論文リンク:https://go.hyper.ai/87pbh
3. WebWatcher: 視覚言語ディープラーニングエージェントの新たな境地を切り開く
本論文では、視覚言語推論能力を強化したマルチモーダルDeep Researchエージェント「WebWatcher」を紹介します。このエージェントは、高品質な合成マルチモーダル軌跡を用いて効率的なコールドスタート学習を実現し、複数のディープリーディングツールを組み合わせ、強化学習によって汎化能力をさらに向上させます。
論文リンク:https://go.hyper.ai/n9IKZ
4. Matrix-3D: 全方向探索可能な3Dワールド生成
本論文では、パノラマ表現を用いて大規模かつ完全に探索可能な3D世界を生成するMatrix-3Dフレームワークを提案する。これは、条件付きビデオ生成とパノラマ3D再構成技術を組み合わせたものである。研究者らはまず、シーンメッシュレンダリングを条件として、軌跡誘導型パノラマビデオ拡散モデルを学習させることで、高品質で幾何学的に一貫性のあるシーンビデオ生成を実現した。
論文リンク:https://go.hyper.ai/ojvKE
5. Voost: 双方向のバーチャル試着・試着オフのための統合型スケーラブル拡散トランスフォーマー
バーチャル試着は、対象となる衣服を着用した人物のリアルな画像を生成することを目的としていますが、衣服と人体の対応関係を正確にモデル化することは、特にポーズや外見のバリエーションがある場合に、依然として課題となっています。本論文では、単一の拡散変換器を介してバーチャル試着タスクと試着解除タスクを共同学習する、統合型でスケーラブルなフレームワーク「Voost」を提案します。
論文リンク:https://go.hyper.ai/qCCaH
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. Google DeepMind は、約 15,000 種をカバーする Perch 2.0 をリリースし、生物音響分類および検出の最先端技術を刷新しました。
Google DeepMindとGoogle Researchは共同でPerch 2.0をリリースし、生物音響学研究を新たな高みへと押し上げました。前バージョンと比較して、Perch 2.0は種の分類を主要な学習タスクとして重視しています。鳥類以外のグループからの学習データをより多く取り入れるだけでなく、新しいデータ拡張戦略と学習目標も採用しています。これにより、BirdSETとBEANSの両方の生物音響学ベンチマークにおいて、最先端の結果が得られました。
レポート全体を表示します。https://go.hyper.ai/B7ZUk
2. オンラインチュートリアル: MediCLIPは最小限の医療画像データのみを使用して、異常検出と位置特定において最先端の技術を実現します
北京大学の研究チームが、効率的な少数ショットの医用画像異常検出ソリューション「MediCLIP」を提案しました。この手法は、最小限の正常医用画像のみを必要とし、異常検出および位置特定タスクにおいて卓越した性能を発揮します。幅広い種類の医用画像において、様々な疾患を効果的に検出し、優れたゼロショット汎化能力を発揮します。
レポート全体を表示します。https://go.hyper.ai/VAhFb
3. 研究者たちは「幸せな居場所」を失っているのか? Paper With Code は閉鎖され、ネットユーザーは Hugging Face の新セクションに不満を抱いている。
Paper With Codeが正式に運営を停止したことを受け、世界中のディープユーザーから声が上がっています。一方では、機械学習研究におけるこのウェブサイトの価値を高く評価する一方で、論文とオープンソースコードの対応に加え、SOTAやリーダーボードといった機能も同様に重要であるという真摯なニーズも表明されています。
レポート全体を表示します。https://go.hyper.ai/poRWa
4. 出力のばらつきが大幅に減少!UCLAは、仮想染色結果の再現性を向上させる双方向ブラウン橋拡散モデルをリリースしました。
UCLAの研究チームは、イメージング質量分析における組織化学染色の問題を解決するために、拡散モデルに基づく仮想組織学的染色法を提案しました。この方法は、空間分解能を高め、ラベルフリーのヒト組織の質量分析画像に細胞形態のコントラストをデジタル的に導入することで、低解像度のIMSデータに基づく高解像度の細胞組織病理構造の予測を実現します。
レポート全体を表示します。https://go.hyper.ai/gcZ5U
Ainnova Techは、90%を超える精度を備えた3秒検出プラットフォームを開発しています。臨床試験計画はFDAのガイダンスを受けています。
ヘルステック企業であるAinnova Techは、眼底画像に基づくインテリジェント診断技術を活用したVision AIプラットフォームを構築しました。このプラットフォームは、糖尿病網膜症(TP3Tの90.1%を超える精度)、心血管リスク、その他の多臓器疾患を数秒で検出できます。20カ国以上でサービスを提供するAinnova Techは、2025年7月にFDAとの申請前ミーティングを無事に完了し、現在、ラテンアメリカで無料スクリーニングモデルを開始し、慢性疾患の早期診断におけるイノベーションを推進しています。
レポート全体を表示します。https://go.hyper.ai/Ete2g
人気のある百科事典の項目を厳選
1.ダルイー
2. 相互ソーティング融合 RRF
3. パレートフロント パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
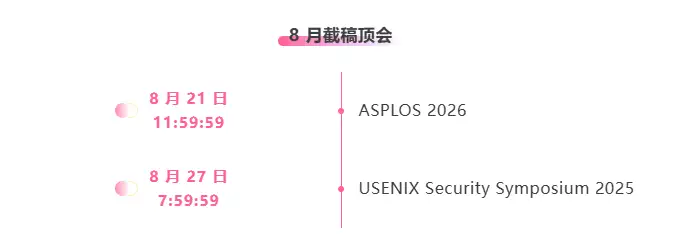
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








