Command Palette
Search for a command to run...
オーディオ美学評価の新たなパラダイム!Audiobox-Aestheticsは4次元オーディオ定量化のパイオニアであり、670万件の事例を誇ります!Caselawが法務参考資料としてのコンプライアンスブループリントを解き放ちます

従来のオーディオ評価は、通常、手作業による聴取に依存しており、その主観的なバイアスにより、評価基準の統一が困難です。既存の評価方法やツールは一定の評価結果を提供しますが、その多くは全体的なオーディオ品質のみに焦点を当てており、局所的な詳細を的確に分析することができません。
この目的を達成するために、Meta AI は、オーディオ品質評価ツールである Audiobox-Aesthetics をリリースしました。音声、音楽、環境音の多次元自動分析を実現します。制作品質、制作の複雑さ、コンテンツの楽しさ、コンテンツの有用性という 4 つの主要な側面を通じて、オーディオ品質を総合的に評価します。手動リスニングや既存のツールの固有の欠陥を補うだけでなく、オーディオクリエイター、エンジニア、研究者にプロレベルの定量分析を提供し、オーディオの最適化のための正確なガイダンスを提供します。
現在、HyperAI公式サイトでは「AudioBox-Aesthetics オーディオ美学評価デモ」を公開していますので、ぜひお試しください。
オンラインでの使用:https://go.hyper.ai/FNpIQ
7月21日から7月25日まで、hyper.ai公式サイトが更新されます。
* 高品質の公開データセット: 10
* 高品質なチュートリアルの選択: 8
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
* 8月に締め切りを迎えるトップカンファレンス:9
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. 医療情報医薬品情報データセット
医療情報データセット(MIDデータセット)は、現在最大規模かつ最も代表的な医薬品情報データセットです。このデータセットには、44の異なる治療カテゴリーのデータが含まれており、192,000種類以上の医薬品を網羅しています。正確で信頼性の高い医薬品情報の提供、医薬品分類と治療ラベルのサポート、臨床試験管理の予測と効率性の向上を目的としています。
直接使用します:https://go.hyper.ai/qmGCW
2. Nemotron-Math-HumanReasoning 数学的推論データセット
Nemotron-Math-HumanReasoningは、NVIDIAが公開した数学的推論データセットで、DeepSeek-R1などのモデルの拡張推論スタイルをシミュレートすることを目的としています。このデータセットには、OpenMathReasoningデータセットから抽出した50問の数学問題、200問の手書き解答、そしてQwQ-32B-Previewによって生成された50問の解答が含まれています。
直接使用します:https://go.hyper.ai/udrjz
3. Updesh インド語合成テキストデータセット
Updeshは、Microsoftが公開したインド語の合成テキストデータセットで、インド語の大規模言語モデル(LLM)の学習後処理の促進を目的としています。このデータセットには、アッサム語やベンガル語などの言語を網羅する680万件の推論データと210万件の生成データが含まれています。
直接使用します:https://go.hyper.ai/wMWci
4. QMOF150量子化学データセット
QMOF150は、量子物質の発見を加速させることを目的として、Metaとケンブリッジ大学が公開した量子化学データセットです。このデータセットには、約14,000種類の金属有機構造体(MOF)と配位高分子が含まれています。これらの中には、実験的に特性評価されたMOFについて、DFTによる構造緩和後の計算特性が含まれており、最適化された構造、エネルギー、バンドギャップ、電荷密度、状態密度、部分電荷、スピン密度、結合次数などが含まれます。
直接使用します:https://go.hyper.ai/2rxVD
5. 安全ベスト検出 安全ベスト検出データセット
Safety Vests Detectionは、新しい物体検出アーキテクチャ(YOLOv8、Faster-RCNN、SSDなど)のベンチマーク、関連するPPE検出タスク(ヘルメット、手袋、ゴーグル)の転移学習、エッジ展開型安全モニターのプロトタイプ開発を目的として設計された安全ベスト検出データセットです。安全ベストを着用している人を自動的に識別・検出し、職場の安全性を向上させるモデルの開発とトレーニングに役立ちます。データセットには、3,897枚の高解像度写真、境界ボックスの注釈、画像コンテキストが含まれています。
直接使用します:https://go.hyper.ai/q0aEL

6. Open-Omega-Atom-1.5M 数学および科学的推論データセット
Open-Omega-Atom-1.5Mは、数学と科学分野における推論能力の向上を目的として設計された数学的・科学的推論データセットです。このデータセットには約150万点のデータが含まれており、数学、科学、コードアプリケーション向けに設計されており、その構成において数学的データが重要な役割を果たしています。
直接使用します:https://go.hyper.ai/ctAbA
7. AF-Chat 音声会話テキスト データセット
AF-Chatは、NVIDIAが会話生成モデルの学習と評価のために公開した音声会話テキストデータセットです。このデータセットには、音声、環境音、音楽など、約75,000件のマルチターン、マルチオーディオ会話(平均4.6セグメント、6.2ラウンド、範囲2~8セグメント、2~10ラウンド)が含まれています。
直接使用します:https://go.hyper.ai/mx6G0
8. rStar Coder 競技レベルのコーディング問題データセット
rStar Coderは、Microsoftが公開した大規模な競技レベルのコーディング問題データセットです。大規模言語モデルのコード推論能力の向上を目的としており、特に競技レベルのコーディング問題への対応においてその効果を発揮します。データセットには、418,000件の競技レベルのプログラミング問題、580,000件の長文推論ソリューション、そして様々な難易度のテストケースが含まれています。各ソリューションは、難易度の異なる様々なシミュレーションテストケースによって検証されています。
直接使用します:https://go.hyper.ai/uJXHe
9. 判例法文献データセット
Caselawは、トロント大学が公開している法律文献データセットで、Caselaw Access ProjectとCourt Listenerから収集された670万件の判例を収録しています。Caselaw Access ProjectとCourt Listenerは、ハーバード大学ローライブラリ、議会法図書館、最高裁判所データベースなど、パブリックドメインの文書のみを含む、様々なソースから法データを取得しています。
直接使用します:https://go.hyper.ai/a1bET
10. APMタンパク質生成データセット
APMは、湖南大学、中国科学院大学、ByteDance Seedチームによって2025年に公開されたタンパク質生成データセットです。単鎖タンパク質データセットと多鎖タンパク質データセットで構成されています。
直接使用します:https://go.hyper.ai/p4qgN
選択された公開チュートリアル
1. AudioBox-Aesthetics オーディオ美学評価デモ
Audiobox-Aestheticsは、Meta AIがリリースしたオーディオ品質評価ツールです。ディープラーニング技術を基盤とし、音声、音楽、環境音の多次元自動分析を実現し、4つのコア要素を通してオーディオ品質を総合的に評価します。オーディオクリエイター、エンジニア、研究者にプロフェッショナルレベルの定量分析を提供します。
オンラインで実行:https://go.hyper.ai/FNpIQ
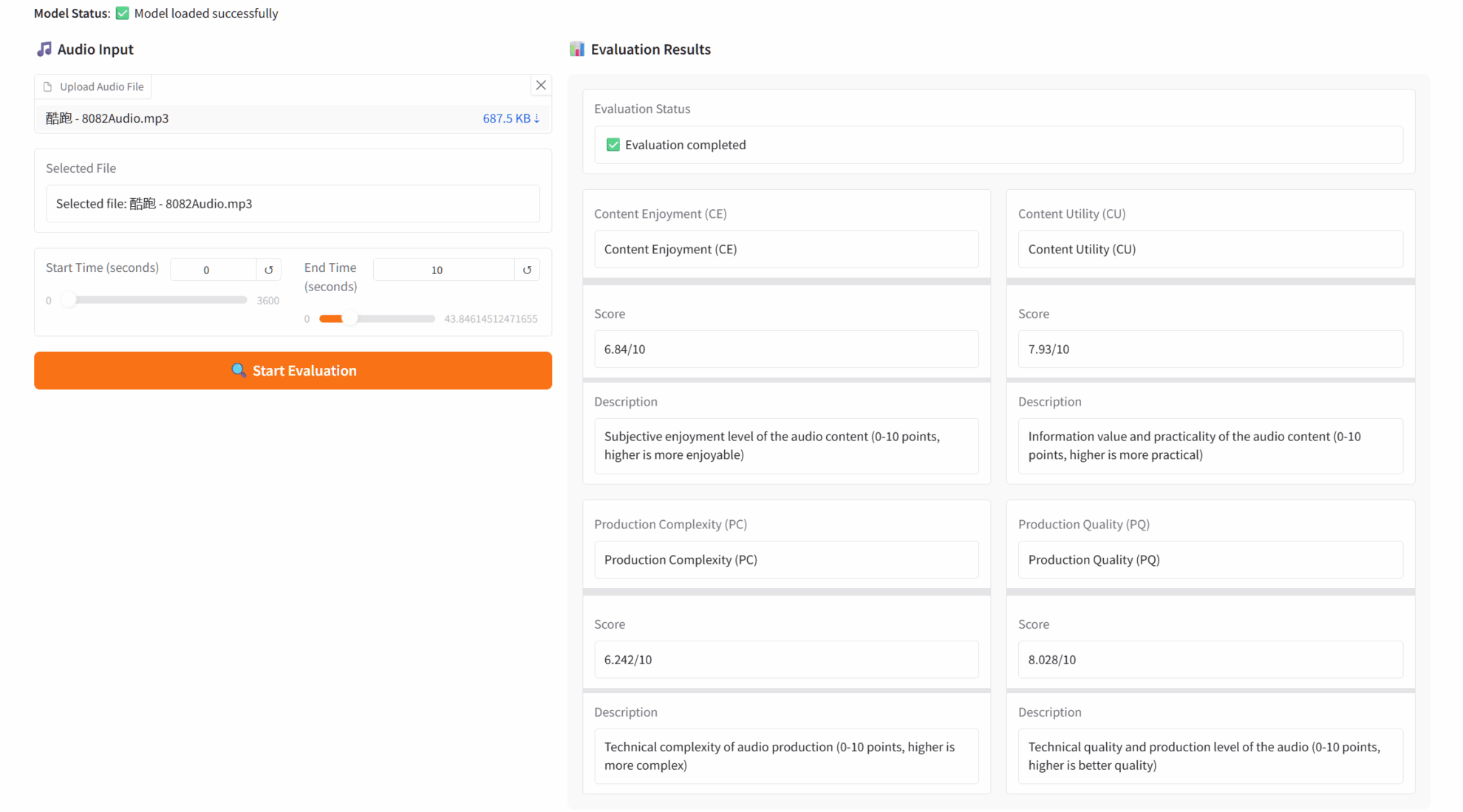
2. LFM2-1.2B: 効率的なエッジ展開テキスト生成モデル
LFM2-1.2Bは、Liquid AIがリリースしたLiquid Foundation Models(LFM)の第2世代です。ハイブリッドアーキテクチャに基づく生成AIモデルであり、業界最速のオンデバイス生成AIエクスペリエンスを提供することを目指しており、低レイテンシのオンデバイス言語モデルワークロード向けに設計されています。
オンラインで実行:https://go.hyper.ai/fEtm9
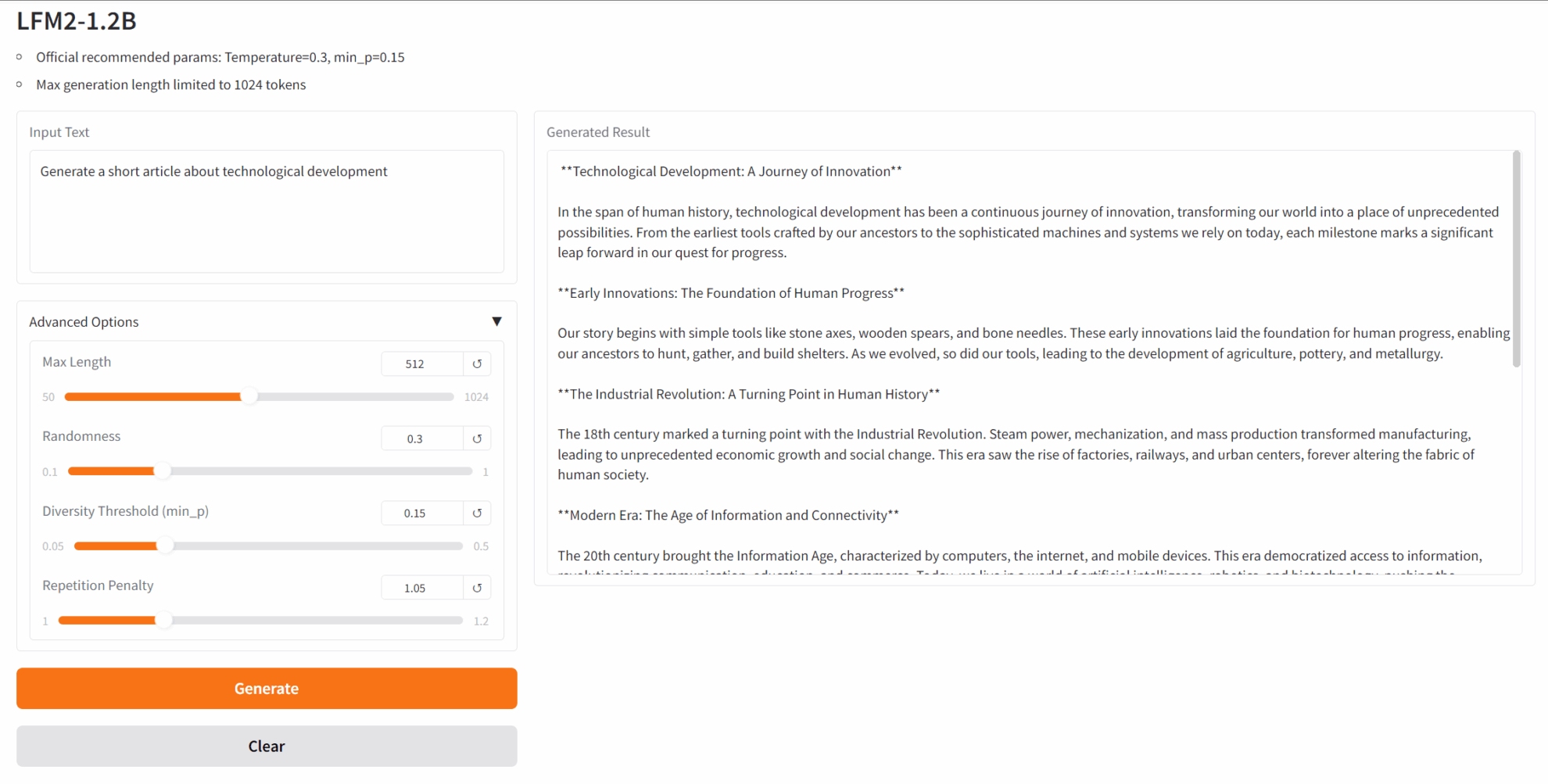
3. Osmosis-Structure-0.6B: 構造化された出力を持つ小さな言語モデル
Osmosis-Structure-0.6Bは、Osmosisがリリースした、構造化出力生成タスクを実行するために設計された、特殊な小規模言語モデル(SLM)です。パラメータサイズはわずか0.6Bですが、サポートされているフレームワークと組み合わせて使用することで、構造化情報の抽出において優れたパフォーマンスを発揮します。
オンラインで実行:https://go.hyper.ai/ayrhc
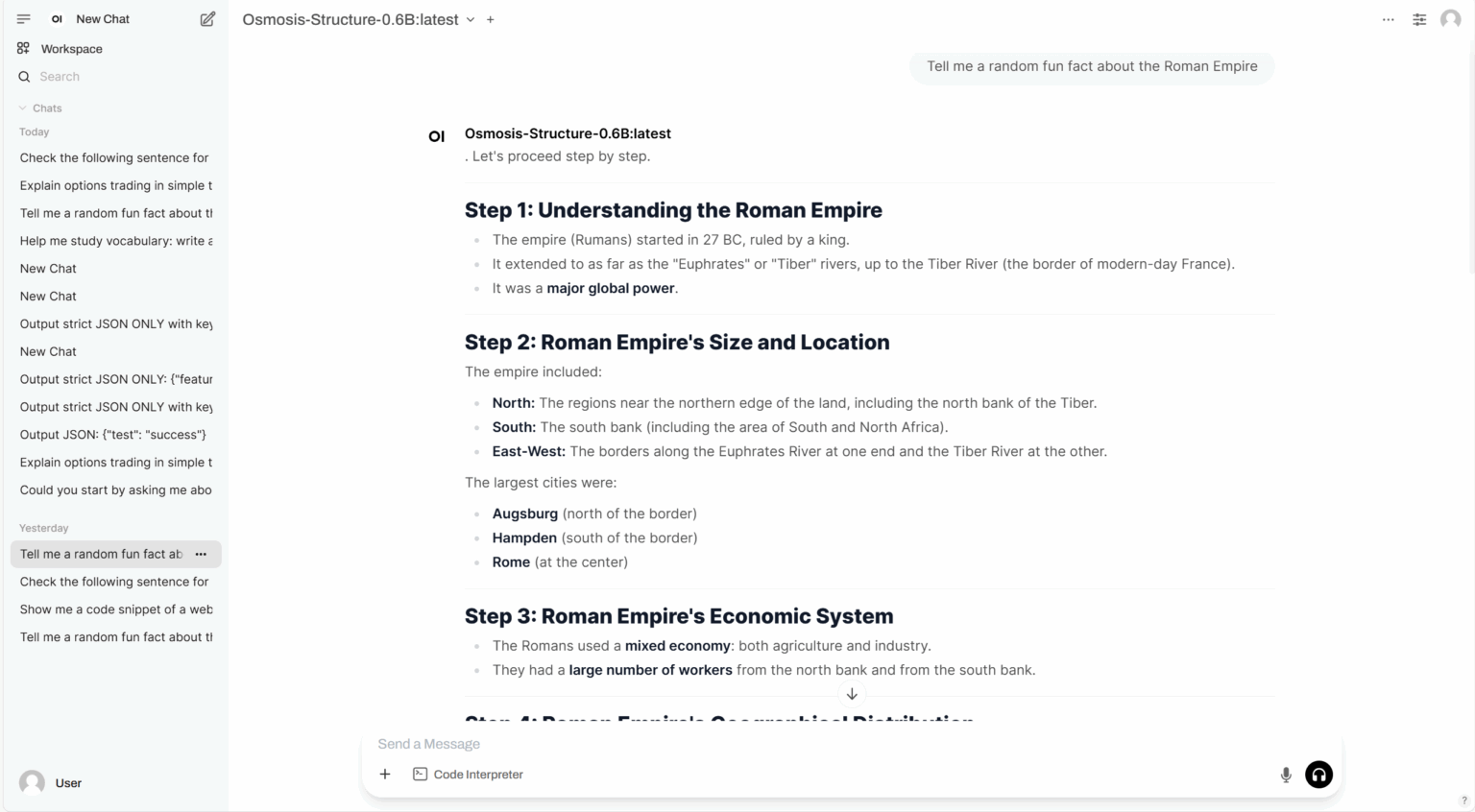
4. MOSS: テキスト音声対話生成
MOSS-TTSDは、OpenMOSSチームが公開したオープンソースのバイリンガル音声対話合成モデルで、中国語と英語に対応しています。2人の話者間の会話スクリプトを、自然で表現力豊かな会話音声に変換できます。MOSS-TTSDは音声クローニングと長い単一セグメント音声生成をサポートしており、AIポッドキャスト制作に最適です。
オンラインで実行:https://go.hyper.ai/FOpMa
5. isometric-skeumorphic-3d-bnb: アイソメトリック3Dスタイルのアイコン生成
isometric-skeumorphic-3d-bnb は、multimodalart グループが公開した LoRA モデルです。このグループは、スキューモーフィックなデザインの美学と様式化された特徴の両方を備えた 3D アイソメトリック アイコンの生成に重点を置いています。このモデルは、現実世界のオブジェクトや建築物のランドマークを非常によく処理し、それらを非常に認識しやすいアイコンスタイルのイラストに変換できます。
オンラインで実行:https://go.hyper.ai/3BnDy

6. DiffuCode-7B-cpGRPO: マスク拡散技術に基づくコード生成モデル
DiffuCoder-7B-cpGRPOは、Appleチームによって提案されたマスク拡散ベースのコード生成モデル(dLLM)です。このモデルは、従来の左から右への自己回帰生成ではなく、反復的なノイズ低減を通じてコードを生成および編集することを目的としています。
オンラインで実行:https://go.hyper.ai/CMfWm
7. LAMMPS: 単結晶アルミニウムを例に、材料の一軸引張をシミュレーションする
LAMMPS(大規模原子分子超並列シミュレータ)は、材料モデリングに特化した古典的な分子動力学シミュレーションコードです。このチュートリアルでは、材料の格子定数を変化させることで、材料に一軸ひずみが加わる状況をシミュレーションし、ひずみ-応力曲線を計算してプロットします。
オンラインで実行:https://go.hyper.ai/LAqAs
8. Voxtral-Mini-3B-2507音声理解モデルのデモ
Voxtralは、Mistral AIが開発した高度な音声モデルです。優れた音声転写と深い理解能力に基づき、音声を人間とコンピュータの自然なインタラクション手段として推進しています。このモデルは、複数の言語、長文コンテキスト処理、組み込みの質問応答機能と要約機能をサポートし、バックエンド関数の直接呼び出しも可能です。Voxtralのパフォーマンスは、複数のベンチマークにおいて既存のオープンソースモデルや独自APIを上回り、低コストでありながら様々なシナリオで広く利用されており、音声インタラクションの普及に貢献しています。
オンラインで実行:https://go.hyper.ai/PpjOs
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. GUI-G^2: GUIグラウンディングのためのガウス報酬モデリング
人間のクリック行動が自然にターゲット要素を中心としたガウス分布を形成するという事実に着想を得て、本論文ではGUI要素をインターフェース上の連続ガウス分布としてモデル化する原理ベースの報酬フレームワークであるGUIガウス局所化報酬(GUI-G^2)を紹介します。研究分析により、連続モデリングはインターフェースの変更に対する堅牢性を高め、未知のレイアウトへの汎用性を高めることが示され、GUIインタラクションタスクにおける空間推論の新たなパラダイムを確立します。
論文リンク:https://go.hyper.ai/wLUhD
2. MiroMind-M1: コンテキストを考慮した多段階ポリシー最適化による数学的推論のオープンソースの進歩
大規模言語モデルは近年、流暢なテキスト生成から複数のドメインにまたがる高度な推論へと進化し、推論言語モデル(RLM)が誕生しました。RLM開発の透明性を高めるため、研究者らはQwen-2.5フレームワーク上に構築された完全オープンソースのRLMシリーズであるMiroMind-M1シリーズを発表しました。このRLMは、既存のオープンソースRLMと同等かそれ以上の性能を備えています。
論文リンク:https://go.hyper.ai/EGWPq
3. 文脈の限界を超えて:長期的な推論のための潜在意識の糸
大規模言語モデル(LLM)のコンテキスト長の制限は、推論の精度と効率を制限します。この制限を克服するために、本論文では、再帰的および分解的問題解決に特化したLLMファミリーであるスレッド推論モデル(TIM)を提案します。また、コンテキスト制限を超えた長期的な構造化推論を可能にする推論ランタイム環境であるTIMRUNも提案します。
論文リンク:https://go.hyper.ai/18j9w
4. 見えない鎖:RLVRがその起源から逃れられない理由
本研究は、理論的および実証的分析を通じてRLVRの潜在的な限界に関する新たな知見を提供し、推論の限界を拡張するRLVRの潜在的な限界を明らかにしています。この目に見えない制約を打ち破るには、明示的な探索メカニズムや、解空間の過小評価された領域に確率的質量を導入するハイブリッド戦略など、将来のアルゴリズム革新が必要になる可能性があります。
論文リンク:https://go.hyper.ai/kkRo2
5. 仮面の裏に潜む悪魔:拡散法学修士課程における新たな安全上の脆弱性
拡散型大規模言語モデル(dLLM)は、自己回帰型大規模言語モデルの強力な代替として近年登場しており、並列デコードと双方向モデリングにより、推論速度の向上と高いインタラクティブ性を実現しています。しかしながら、既存のアライメント機構では、マスクされた入力を用いたコンテキストアウェアな敵対的プロンプト攻撃からdLLMを保護することができず、新たな脆弱性が露呈しています。この目的を達成するために、本論文では、dLLMに特有のセキュリティ上の弱点を体系的に研究・構築する初の脱獄攻撃フレームワークであるDIJAを提案し、この新興言語モデル群における安全なアライメント機構の再考の緊急性を浮き彫りにします。
論文リンク:https://go.hyper.ai/dyDhr
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
基調講演「Triton-distributed: 高性能通信のためのネイティブ Python プログラミング」では、ByteDance のシード研究科学者 Zheng Size 氏が、大規模モデルのトレーニング、クロスプラットフォームの適応性、および Python プログラミングを通じて通信とコンピューティングの高度な統合を実現する方法における Triton-distributed の通信効率の飛躍的向上について詳細に分析しました。
レポート全体を表示します。https://go.hyper.ai/L2rfl
2. データノイズ除去/生物学的シグナル強化/ドロップアウト軽減、深層学習モデルSUICAは空間トランスクリプトームスライス内の任意の位置での遺伝子発現予測を実現します
東京大学の鄭銀強教授のグループとマギル大学の丁軍教授のグループは共同で、空間トランスクリプトームデータのモデリング手法SUICAを提案しました。これは、暗黙的ニューラル表現とグラフオートエンコーダに基づく深層学習モデルです。SUICAによって処理された空間トランスクリプトームデータは、より高品質でノイズが少なく、より強い生物学的シグナルを持つ可能性があることが示されました。この研究成果は、ICML 2025に選出されました。
レポート全体を表示します。https://go.hyper.ai/5esoL
3. タイルレベルのプリミティブと自動推論メカニズムが統合されています。TileAIコミュニティの創設者がTileLangのコアテクノロジーと利点を深く分析しています。
TileAI コミュニティの創設者である王磊博士は、「現代の AI ワークロードにおけるプログラマビリティとパフォーマンスの橋渡し」と題した講演を行い、革新的なオペレータープログラミング言語 TileLang をわかりやすく紹介し、その中核となる設計コンセプトと技術的な利点を共有しました。
レポート全体を表示します。https://go.hyper.ai/AkeOJ
4. タンパク質生成・折り畳み・逆折り畳みをサポート。HUST/USTC/Byteは、全原子設計と機能最適化を実現するAPMモデルを提案した。
湖南大学は、中国科学院大学およびByteDance Seedチームと共同で、新たな全原子タンパク質生成モデルAPM(All-Atom Protein Generative Model)を提案しました。このモデルは原子レベルの情報を統合し、擬似配列結合に依存せずに多重鎖タンパク質の生成、フォールディング、逆フォールディングをサポートします。抗体設計やペプチド結合設計といった下流タスクにおいて、既存のSOTAを超える性能を実現します。
レポート全体を表示します。https://go.hyper.ai/fJvpi
5. Google DeepMindは17万6千点以上の碑文データを基に、古代ローマの碑文の任意の長さの復元を初めて実現したAeneasをリリースした。
Google DeepMindの研究者らは、ノッティンガム大学、ウォーリック大学などの大学と共同で、世界トップクラスの学術誌「ネイチャー」に「生成ニューラルネットワークによる古代テキストの文脈化」と題する研究論文を発表し、アイネイアスが古代ローマの碑文の任意の長さの修復を初めて達成したと発表した。
レポート全体を表示します。https://b23.moe/cYtSI
人気のある百科事典の項目を厳選
1. DALL-E
2. 相互ソート融合RRF
3. パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
サミットの締め切りは8月
8月1日 7:59:59 インフォコム2026
8月1日 7:59:59 KDD 2026
8月2日 7:59:59 HPCA 2026
8月2日 7:59:59 ユビキタスコンピューティング 2025
8月2日 11:59:59 2026年
8月2日 19:59:59 AAAI 2026
8月7日 7:59:59 NDSS 2026
8月21日 11:59:59 ASPLOS 2026
8月27日 7:59:59 USENIXセキュリティシンポジウム2025
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








