Command Palette
Search for a command to run...
Google DeepMindは17万6千以上の碑文データを基に、古代ローマの碑文の任意の長さの復元を初めて達成したAeneasをリリースした。

人類初期文明の記憶はすべて、碑文と言葉の中に秘められています。碑文は最も古い書記形態の一つであり、古代文明の思想、言語、そして歴史を理解するための窓を提供してきました。皇帝の勅令から奴隷の墓石に至るまで、石板や青銅器に刻まれたこれらの言葉は、時代を特定し、文化を理解するための直接的な証拠となっています。現在でも毎年1,500点ものラテン語碑文が新たに発見されていると推定されていますが、碑文学の研究は、テキストの不完全さ、解釈の難しさ、知識の限界など、多くの困難に直面しています。
2025年7月23日、Google DeepMindの研究者は、ノッティンガム大学、ウォーリック大学などの大学と共同で、「生成ニューラルネットワークによる古代テキストの文脈化」と題する研究論文を、世界トップクラスの学術誌「ネイチャー」に掲載しました。
この研究には、3 つの主要な革新的なハイライトが含まれています。
* Aeneasは、碑文のテキスト転写と画像の両方を入力できます。画像は浅い視覚ニューラルネットワークによって処理され、テキスト特徴と組み合わせられます。これは、特に地理的属性の特定タスクに役立ちます。
* これまで、AI は既知の長さのテキストしか修復できませんでしたが、Aeneas は修復の制限を打ち破り、初めて「任意の長さのテキストを修復する」機能を開発しました。
* Aeneasの核となる機能は、対象の碑文に最も関連性の高い「対訳テキスト」を見つけることです。これらの対訳テキストは、類似したフレーズが含まれているだけでなく、文化的背景や社会的機能といった深いつながりを網羅しており、従来の文字列照合の限界をはるかに超えています。
モデルアーキテクチャ: マルチモーダル生成ニューラルネットワーク Aeneas
Aeneas はマルチモーダル生成ニューラル ネットワークです。Transformerベースのデコーダーを用いて碑文のテキストと画像を入力し、浅い視覚ニューラルネットワークを用いてラテン語碑文データセットから類似の碑文を検索し、関連性に基づいて並べ替えます。入力テキストは、モデルの中核部分である「胴体」によって処理されます。
Aeneasはラテン語碑文の文脈解析を目的として設計されています。そのアーキテクチャは、入力処理、コアモジュール、タスクヘッダー、そして文脈化メカニズムで構成されています。
入力処理:入力は碑文の文字列と224×224のグレースケール画像です。文字列は最大768文字で、長さが既知の欠落文字には「-」、長さが不明な欠落文字には「#」、文頭マーカーには「<」を使用します。
コアモジュール:テキストは、T5 Transformerデコーダーを改良したトルソー(16層、各層8つのアテンションヘッド、相対位置回転埋め込み機能搭載)で処理され、画像はResNet-8ビジュアルネットワークで処理されます。トルソーネットワークとビジュアルネットワークの出力は、ヘッド内の専用ニューラルネットワークに送られ、ヘッドはテキストを用いて文字の復元と年代測定を行います。各ヘッドは、3つの主要な碑文タスクを処理するようにカスタマイズされています。
タスクヘッダー(タスクヘッド):出力には、テキスト修復 (未知の長さの修復、ビーム検索を使用した仮説生成の補助ヘッドを含む)、地理的属性 (テキストと視覚的特徴を組み合わせて 62 のローマ属州を分類する)、および年代的属性 (日付を 160 の個別の 10 年間隔にマッピングする) の専用タスク ヘッドがあり、すべて顕著性マップを備えています。
コンテキスト化メカニズム:胴体と作業頭部の中間表現を統合して歴史的に豊富な埋め込みを生成することにより、コサイン類似性に基づいて関連する平行碑文が取得され、歴史家の研究を支援します。
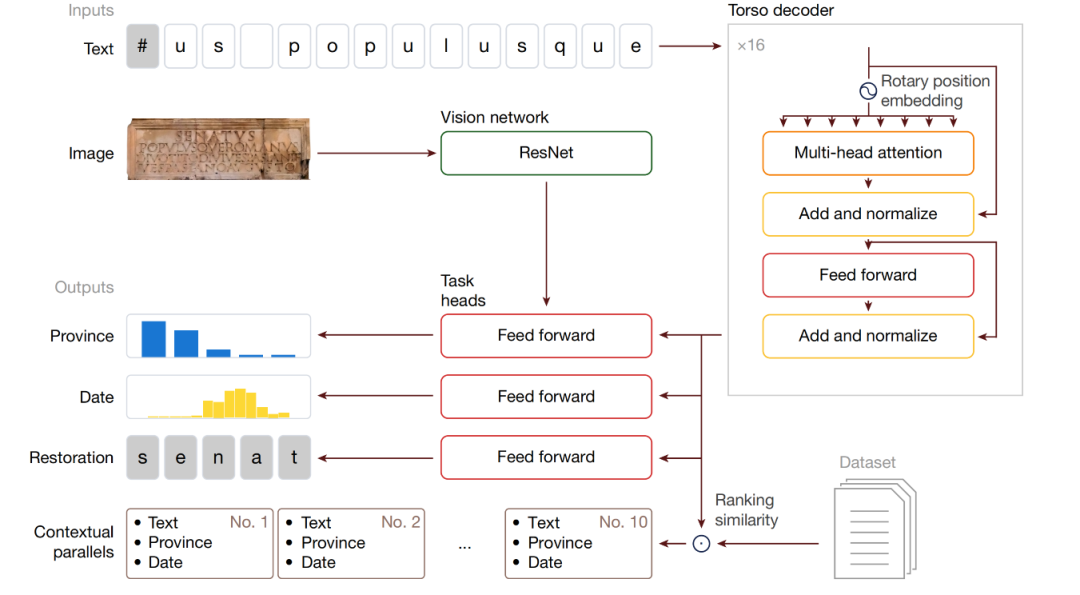
Aeneasによる「Senatus populusque Romanus」というフレーズの処理を例に挙げましょう。碑文の画像とそのテキスト転写(長さ不明の破損部分には「#」とマークされています)が与えられた場合、Aeneasは胴体を用いてテキストを処理します。頭部は文字の復元、年代測定、地理的属性の特定(地理的属性特定タスクには視覚的特徴も組み込まれています)を担当します。胴体の中間表現は、統一された歴史的に豊富な埋め込みベクトルに統合され、ラテン語碑文データセット(LED)から類似の碑文を取得し、関連性に基づいて並べ替えます。
注目すべきはAeneas モデルは、地理属性ヘッドに対してのみ視覚ネットワークからの追加入力を組み込みます。テキスト修復および時系列属性タスクでは視覚モダリティは使用されません。復元タスクでは、偶発的な情報漏洩を防ぐため、視覚的な入力は除外されています。テキストの一部は人工的にマスクされており、画像内の正確な位置は不明であるため、モデルは視覚的な手がかりを用いて隠された文字を推測・復元する可能性があり、タスクの完全性が損なわれる可能性があります。
データセット: ラテン語碑文の最大の機械可読データセット
Aeneas モデルのトレーニングに使用されたコーパス データベースは、この研究ではラテン語碑文データセット (LED) と呼ばれており、これは現在までに機械で操作可能な最大のラテン語碑文データセットです。 LEDデータセットの包括的なコーパスデータは、紀元前7世紀から紀元後8世紀までの碑文を含む、最も包括的なラテン語碑文データベースであるローマ碑文データベース(EDR)、ハイデルベルク碑文データベース(EDH)、クラウス=スラビーデータベースの3つから取得されており、地理的範囲は西はローマ帝国のブリタニア(現在のブリテン)とルシタニア(ポルトガル)の属州から東はエジプトとメソポタミアまで広範囲にわたります。LEDデータセット全体の一貫性を確保するため、本研究ではTrismegistosデータプラットフォームの識別子を用いてデータの曖昧性を処理し、一連のフィルタリングルールを適用して人間による注釈を体系的に処理することで、テキストを機械で処理できるようにしました。
標準化されたメタデータを取得するには、この研究では、日付と歴史的期間に関連するすべてのメタデータを紀元前 800 年から西暦 800 年までの範囲の数値に変換しました。この範囲外の碑文は除外されました。モデルの学習および汎化能力を向上させるため、データセット内の実質的なテキストコンテンツは、以下の標準に従って機械が処理可能な形式に変換されました。
* 碑文に関する歴史家の注釈を削除または正規化し、元の碑文に最も近いバージョンを維持します。
* ラテン語の略語は解析されませんが、通時的、双方向的、または語形変化上の理由で代替スペルが表示される単語形式は保持され、モデルはそれらの碑文的、地理的、または年代的な特定のバリエーションを学習します。
* エディターによって復元された、または最終的に復元できなかった欠落文字を保持し、欠落文字の正確な数が不明な場合はプレースホルダーとしてポンド記号 (#) を使用し、余分なスペースを折りたたんで簡潔な出力を実現します。
* 非ラテン文字を削除し、ラテン文字、定義済みの句読点、プレースホルダーのみを残します。
* 重複する登録をフィルタリングします。90% コンテンツの類似性しきい値を超えるテキストは重複とみなされます。
フォーマットを変換した後、研究では、固有の刻印識別子の最後の桁に基づいて LED をトレーニング セット、検証セット、テスト セットに分割し、サブセット間で画像が均等に分散されるようにしました。

自動フィルタリング プロセスを実装した後、この研究では、色ヒストグラムにしきい値を適用して主に単一の純色で構成された画像を除外し、ラプラシアン マトリックスの分散を使用してぼやけた画像を識別して破棄し、クリーンアップされた画像をグレースケール画像に変換することで、データセットから使用可能な碑文画像を取得しました。 LED データセットには合計 176,861 個の碑文が含まれていますが、そのほとんどは部分的に破損しており、5% の碑文のみが対応する使用可能な画像を生成できます。
実験的結論/パフォーマンス
研究者らは、タスク実行、固有名詞学ベースライン、文脈化メカニズム、研究効率という3つの側面からAeneasモデルのパフォーマンスを評価しました。
* 固有名詞学とは、人名、地名、部族名、神名などの固有名の起源、構造、進化、意味を研究する学問です。
タスク実行インジケーター
この研究では、テキストの修復、地理的帰属、時間的帰属という 3 つの指標を使用して評価の枠組みを形成します。その中で、研究者らは人工的な方法を使用して任意の長さのテキストを破壊し、モデルを提出して修復されたオブジェクトを生成しました。地理的帰属タスクでは、標準的なトップ1およびトップ3の精度指標を使用してパフォーマンスを評価しました。時間帰属については、説明可能な指標を使用して、予測結果と実際のデータ間の時間的な近接性を評価しました。
実験により、Aeneas のアーキテクチャがマルチモーダル機能を提供することが示されました。長さが不明なテキストシーケンスを復元できるまた、古代の言語やパピルス、硬貨などの文字媒体にも適応でき、古代テキスト研究の文脈化プロセスにおいて碑文と歴史のつながりを捉えることができます。
固有名詞ベースライン
Aeneas モデルによる固有名詞学から得られたメタデータの自動評価は、その帰属予測機能の重要な指標になります。ローマ字の固有名詞のあらかじめまとめられたリストがないので、研究チームは、固有名詞を表さない 350 個の項目を固有名詞リポジトリから手動で削除しました。使用法が曖昧なため、短いエントリやラテン文字以外の文字を含むエントリは除外され、結果として約 38,000 個の固有名詞の厳選されたリストが作成されました。
この手法の堅牢性を高めるために、データセット内で最も一般的な単語が特定され、厳選された固有名詞リストのエントリのみで構成されるようにフィルタリングされました。その後、トレーニング データセット内でのそれらの平均的な時間的および地理的な分布が計算され、Aeneas モデルは処理済みの固有名詞データを活用して、新しい碑文を分析する際にその日付と由来を予測できるようになりました。
このタスクの Aeneas モデルの評価方法はデータセット全体に適用でき、スケーラビリティが向上します。
文脈化メカニズムと研究効率
この研究では、歴史研究の基本ツールとしてのアエネアス モデルの文脈化メカニズムの有効性を評価しました。さまざまな背景を持つ 23 人の碑文学者が匿名で評価に参加しました。3 つの碑文タスクを実行した経験に基づいて、研究補助ツールとして Aeneas の文脈化メカニズムを使用する効率が評価されました。
* Aeneas モデルは、関連情報の検索にかかる時間を大幅に短縮し、研究者がより深い歴史的解釈と研究課題の構築に集中できるようにします。
* Aeneas モデルによって取得された情報は正確であり、碑文の種類と文脈に関する貴重な洞察を提供し、研究タスクの推進に役立ちます。
* Aeneas は、重要だがこれまで気づかれなかった関連情報や見落とされていたテキストの特徴を特定することで、検索範囲を広げ、結果を絞り込みます。
一部の専門家は信憑性を疑っている
「Aeneasは歴史分野における人工知能の始まりです」と、人工知能分野の技術専門家であるデイビッド・ガルブレイス氏は述べています。Aeneasの画期的な進歩は、単なる技術進歩ではなく、人文科学とAIの深い融合の兆候でもあります。歴史家にとって、Aeneasは学者の代わりではなく、むしろ機械的な労力を軽減し、研究の視野を広げる「スーパーアシスタント」です。同時に、AI分野においては、複雑な人文科学データの処理におけるマルチモーダルかつ文脈化されたモデルの潜在能力を証明し、他の古代言語研究の今後の発展のモデルを提供しています。
Aeneasにはまだ限界がある。Aeneasの画期的な進歩に対し、別の人工知能専門家は「AIに過度に依存して欠陥を埋めようとすると、その信頼性に疑問が生じる」と懸念を表明した。

確かに、AIはツールであり、真の代替手段ではありません。学習データには、画像が添付されている碑文がわずか5%しかなく、一部の地域(シチリア島など)や時代(紀元前600年以前など)の碑文の数が不足しているため、予測精度が低下しています。これらはすべて、現在のAI技術が未成熟であることを警告しており、科学研究と生活におけるAIの活用割合を合理的に選択する必要があります。








