Command Palette
Search for a command to run...
コーディングの悩みとはおさらば!Seed-Coderで効率的なプログラミングを実現。Mixture-of-Thoughtsでマルチドメインデータをカバーし、高品質な推論を実現

大規模モデルをめぐる競争が激化し、「技術のボリューム化とスケール化」の潮流が続く中、モデルの実際のユーザビリティとタスクパフォーマンスをいかに向上させるかが、より重要な課題となっています。中でも、コーディング能力は、大規模モデルのユーザビリティとタスクパフォーマンスを測る重要な指標です。これに基づき、ByteDance Seedチームは、軽量ながらも強力なオープンソースコード大規模言語モデル「Seed-Coder-8B-Instruct」をリリースしました。
このモデルは、Seed-Coder シリーズの微調整されたバージョンであり、Llama 3 アーキテクチャ上に構築され、8.2B のパラメータを持ち、最大長 32K トークンのコンテキスト処理をサポートします。Seed-Coder-8B-Instruct LLMは、最小限の人的介入でコード学習データを効率的に管理し、コーディング能力を大幅に向上させます。また、高品質な学習データをLLM自身で生成・スクリーニングすることで、モデルコード生成能力を大幅に向上させます。
現在、HyperAI Super Neuralはオンラインです 「vLLM+Open WebUIデプロイメントSeed-Coder-8B-Instruct」ぜひお試しください〜
オンラインでの使用:https://go.hyper.ai/BnO32
ライブ放送の予定
AppleのWWDC25グローバルカンファレンスは、6月10日午前1時(北京時間)に開催されます。HyperAI Super Neural Video Accountが基調講演をリアルタイムで配信します。見逃したくない方は、今すぐご予約ください!

6月3日から6月6日まで、hyper.ai公式サイトが更新されます。
* 高品質の公開データセット: 10
* 高品質のチュートリアル: 13
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:4件
* 人気のある百科事典のエントリ: 5
* 6月に締め切りを迎えるトップカンファレンス:2
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
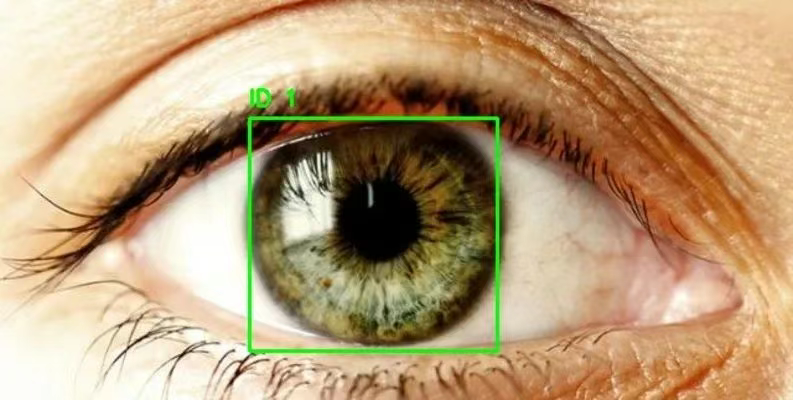
1. Eye Detection メガネ検出データセット
Eye Detectionは、約2,000枚の明確にラベル付けされた目領域画像を含む目検出データセットです。RCNNやYOLOなどのターゲット検出モデルを学習し、目領域の追跡と検出を行うことができます。このデータセットは、白内障検出モデルや視線追跡モデルなどの構築に使用できます。
直接使用します:https://go.hyper.ai/5IUPr
2. Yambda 音楽推奨データセット
Yambda-5Bは、音楽推薦、情報検索、ソートといった大規模言語モデル(LLM)の学習および評価リソースを提供することを目的とした、大規模なマルチモーダル音楽分析データセットです。このデータセットには、100万人のユーザーと939万曲を網羅した47億9000万件のインタラクション(視聴、いいね、いいね取り消しを含む)が含まれており、現在、公開されている音楽推薦データセットとしては最大級の規模を誇ります。
直接使用します:https://go.hyper.ai/VSL3J
3. 4倍衛星の衛星画像データセット
このデータセットは、4 倍の超解像度タスク用に設計された、高解像度 (HR) と低解像度 (LR) の衛星画像のペアを含む高解像度の衛星画像データセットです。
直接使用します:https://go.hyper.ai/TyCeW
4. MedXpertQA 医療推論データセット
このデータセットには、テキストと画像データを統合した 4,460 件のサンプル データが含まれており、医療に関する質問への回答、臨床診断、治療計画の推奨、基本的な医療知識の理解などのタスクをカバーしています。複雑な医療意思決定機能の研究開発をサポートし、医療分野における中規模モデルの微調整や評価に適しています。
直接使用します:https://go.hyper.ai/YGW7J
5. 動物の鳴き声 動物の鳴き声データセット
このデータセットには約 10,800 個のサンプルが含まれており、エナガやキンカチョウなどの鳥類、イヌ、エジプトオオコウモリ、オオカワウソ、マカク、シャチなど 7 種の音声をカバーしています。各オーディオの長さは 1 ~ 5 秒で、軽量モデルのトレーニングや高速な実験に適しています。
直接使用します:https://go.hyper.ai/asUR4
6. GeMS化学質量分析データセット
このデータセットには、数億件の質量スペクトル(GeMS-C1サブセットでは20億件)が含まれており、構造化数値データ(質量スペクトルの質量電荷比と強度のペア)とメタデータ(スペクトル源、実験条件など)が含まれています。これは、現在利用可能な最大規模の公開質量分析データセットの一つであり、超大規模モデルの学習をサポートできます。
直接使用します:https://go.hyper.ai/yXI9M
7. DeepTheorem定理証明データセット
DeepTheoremは、自然言語に基づく非公式定理証明を通じて、大規模言語モデル(LLM)の数学的推論能力を強化することを目的とした数学的推論データセットです。このデータセットには、複数の数学分野を網羅する121,000件のIMOレベルの非公式定理と証明が含まれています。各定理と証明のペアには、厳密に注釈が付けられています。
直接使用します:https://go.hyper.ai/fjnad
8. SynLogic推論データセット
SynLogicは、検証可能な報酬を用いた強化学習を通じて、大規模言語モデル(LLM)の論理的推論能力を強化することを目指しています。データセットには、自動検証機能を備えた35の多様な論理的推論タスクが含まれており、強化学習のトレーニングに最適です。
直接使用します:https://go.hyper.ai/iF5f2
9. 思考混合推論データセット
Mixture-of-Thoughtsは、数学、プログラミング、科学の3つの主要分野における高品質な推論トラックを統合した、マルチドメイン推論データセットです。大規模言語モデル(LLM)を段階的に推論を実行できるように学習することを目的としています。このデータセットの各サンプルには、複数回の対話ラウンドの形で推論プロセスを保存するメッセージフィールドが含まれており、モデルが段階的に推論能力を学習することをサポートします。
直接使用します:https://go.hyper.ai/7Qo2l
10. ラマ-ネモトロン推論データセット
このデータセットには、約2,206万件の数学データ、約1,010万件のコードデータ、そして残りは科学や指導実践などの分野のデータが含まれています。このデータは、Llama-3.3-70B-Instruct、DeepSeek-R1、Qwen-2.5といった複数のモデルによって共同生成されており、多様な推論スタイルと問題解決パスをカバーし、大規模モデル学習の多様なニーズに対応しています。
直接使用します:https://go.hyper.ai/4V52g
選択された公開チュートリアル
今週は、質の高い公開チュートリアルを 4 つのカテゴリにまとめました。
*AI for Scienceチュートリアル: 4
* 画像処理チュートリアル: 4
*コード生成チュートリアル: 3
*音声インタラクションチュートリアル:2
AI科学チュートリアル
1. オーロラ大規模大気基本モデルデモ
Auroraは、既存の運用予測システムを上回る性能を発揮しながら計算コストを大幅に削減し、高品質な気候・気象情報への幅広いアクセスを促進します。Auroraは、最先端の数値予測システムであるIFSの約5,000倍の速度であることが実証されています。
このチュートリアルでは、シングルカードのA6000をリソースとして使用します。コンテナを起動したら、APIアドレスをクリックしてWebインターフェースに入ります。
オンラインで実行:https://go.hyper.ai/416Xs
2. MedGemma-4b-itマルチモーダル医療AIモデルのワンクリック展開
MedGemma-4b-itは、医療分野向けに特別に設計されたマルチモーダル医療AIモデルです。MedGemmaスイートの命令調整バージョンです。SigLIP画像エンコーダーを採用しており、特別に事前学習済みで、胸部X線写真、皮膚科画像、眼科画像、組織病理切片など、匿名化された医療画像のデータを使用します。
このチュートリアルでは、リソースとして単一の RTX 4090 カードを使用します。コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります。
オンラインで実行:https://go.hyper.ai/31RKp
3. MedGemma-27b-text-it医療推論モデルのワンクリック展開
このモデルは臨床テキストの処理に重点を置いており、特に患者のトリアージと意思決定支援に優れており、医師に迅速かつ貴重な患者の状態に関する情報を提供して、効率的な治療計画の策定を促進します。
このチュートリアルではデュアルSIM A6000のリソースを使用します。以下のリンクを開くと、ワンクリックで展開できます。
オンラインで実行:https://go.hyper.ai/2mDmF
4. vLLM+Open WebUIデプロイメントII-Medical-8B医療推論モデル
このモデルは Qwen/Qwen3-8B モデルをベースとしており、医療特有の推論データセットを使用して SFT (教師あり微調整) を使用し、ハード推論データセットで DAPO (可能な最適化手法) をトレーニングすることで、モデルのパフォーマンスを最適化します。
このチュートリアルで使用されるコンピューティング リソースは、単一の RTX 4090 カードです。
オンラインで実行:https://go.hyper.ai/1Qvwo
画像処理チュートリアル
1. DreamO: 統合画像カスタマイズフレームワーク
DreamOはDiT(Diffusion Transformer)アーキテクチャに基づいて、さまざまな画像生成タスクを統合し、衣装変更(IP)、顔変更(ID)、スタイル転送(Style)、複数被写体の組み合わせなどの複雑な機能をサポートし、単一モデルを通じてマルチ条件制御を実現します。
このチュートリアルでは、単一カード A6000 のリソースを使用します。
オンラインで実行:https://go.hyper.ai/zGGbh
2. BAGEL: マルチモーダル理解と生成のための統合モデル
BAGEL-7B-MoTは、テキスト、画像、動画などのマルチモーダルデータの理解と生成タスクを統一的に処理するように設計されています。BAGELは、マルチモーダル理解と生成、複雑な推論と編集、世界のモデリングとナビゲーションといったマルチモーダルタスクにおいて包括的な能力を実証しています。主な機能は、視覚理解、テキストから画像への生成、画像編集などです。
このチュートリアルでは、デュアルカード A6000 コンピューティング リソースを使用し、イメージ生成、Think を使用したイメージ生成、イメージ編集、Think を使用したイメージ編集、およびイメージ理解をテスト用に提供します。
オンラインで実行:https://go.hyper.ai/76cEZ

3. ComfyUI Flex.2 プレビューワークフローオンラインチュートリアル
Flex.2-previewは、入力されたテキスト記述に基づいて高品質の画像を生成できます。最大512トークンのテキスト入力をサポートし、複雑な記述を理解して対応する画像コンテンツを生成します。また、画像の特定領域の修復または置換もサポートしています。ユーザーが修復画像と修復マスクを提供すると、モデルは指定された領域に新しい画像コンテンツを生成します。
このチュートリアルでは、リソースとして単一の RTX 4090 カードを使用し、英語のプロンプトのみをサポートします。
オンラインで実行:https://go.hyper.ai/MH5qY
4. ComfyUI LanPaint画像修復ワークフローチュートリアル
LanPaintは、革新的な推論手法を用いて、様々な安定拡散モデル(カスタムモデルを含む)に追加の学習なしで適応し、高品質な画像復元を実現するオープンソースの画像ローカル復元ツールです。従来の手法と比較して、LanPaintは軽量なソリューションを提供し、学習データと計算リソースの要件を大幅に削減します。
このチュートリアルでは、RTX 4090カードを1枚使用します。以下のリンクを開くと、モデルのクローンを簡単に作成できます。
オンラインで実行:https://go.hyper.ai/QAuag
コード生成チュートリアル
1. vLLM+Open WebUIデプロイメントSeed-Coder-8B-Instruct
Seed-Coder-8B-Instructは、軽量ながらも強力なオープンソースのコード言語モデルです。Seed-Coderシリーズの命令を微調整したバージョンです。LLMは最小限の人的資源で、コード学習データを効果的に管理し、コーディング能力を大幅に向上させることができます。このモデルはLlama 3アーキテクチャ上に構築されており、8.2 Bのパラメータを持ち、32Kトークンの長いコンテキストをサポートします。
このチュートリアルで使用されるコンピューティング リソースは、単一の RTX 4090 カードです。
オンラインで実行:https://go.hyper.ai/BnO32
2. Mellum-4b-baseはコード補完用に設計されたモデルです
Mellum-4b-baseは、コードの理解、生成、最適化タスク向けに設計されています。このモデルは、ソフトウェア開発プロセス全体において優れた機能を発揮し、AIを活用したプログラミング、インテリジェントなIDE統合、教育ツール開発、コード研究といったシナリオに適しています。
このチュートリアルでは、リソースとして単一の RTX 4090 カードを使用し、モデルはコードの最適化にのみ使用されます。
オンラインで実行:https://go.hyper.ai/2iEWz
3. OpenCodeReasoning-Nemotron-32Bのワンクリック展開
このモデルは、コード推論と生成のために設計された高性能な大規模言語モデルです。OpenCodeReasoning (OCR) モデルスイートのフラッグシップバージョンであり、32Kトークンのコンテキスト長をサポートします。
このチュートリアルで使用されるコンピューティング リソースは、デュアル カード A6000 です。
オンラインで実行:https://go.hyper.ai/jhwYd
音声インタラクションチュートリアル
1. VITA-1.5: マルチモーダルインタラクションモデルのデモ
ITA-1.5は、視覚、言語、音声を統合したマルチモーダル大規模言語モデルであり、GPT-4oと同等のレベルでリアルタイムの視覚と音声のインタラクションを実現するように設計されています。VITA-1.5は、インタラクションの遅延を4秒から1.5秒に大幅に短縮し、ユーザーエクスペリエンスを大幅に向上させます。
このチュートリアルでは、シングルカードの A6000 をリソースとして使用します。現在、AIインタラクションでは中国語と英語のみがサポートされています。
オンラインで実行:https://go.hyper.ai/WTcdM
2. Kimi-Audio: AIに人間を理解させる
Kimi-Audio-7B-Instructは、単一の統合フレームワーク内で様々なオーディオ処理タスクを処理できるオープンソースのオーディオインフラストラクチャモデルです。自動音声認識(ASR)、音声質問応答(AQA)、自動音声字幕作成(AAC)、音声感情認識(SER)、サウンドイベント/シーン分類(SEC/ASC)、エンドツーエンドの音声対話など、様々なタスクに対応します。
このチュートリアルでは、単一カード A6000 のリソースを使用します。
オンラインで実行:https://go.hyper.ai/UBRBP
今週のおすすめ紙
1. 地球システムの基礎モデル
本論文では、100 万時間を超える多様な地球物理学的データに基づいてトレーニングされた大規模な基本モデルである Aurora モデルを提案します。このモデルは、空気の質、海洋の波、熱帯低気圧の進路、高解像度の天気予報において、既存の運用予測システムよりも優れています。
論文リンク:https://go.hyper.ai/ibyij
2. Paper2Poster: 科学論文からのマルチモーダルポスター自動化に向けて
学術論文のポスター作成は、科学コミュニケーションにおいて極めて重要かつ困難なタスクです。長大なインターリーブ文書を、視覚的に一貫性のある1ページに圧縮する必要があります。この課題に対処するため、本稿では、22ページの論文を編集可能なpptx形式のポスターに変換できる、学術論文のポスター作成のための初のベンチマークおよび測定スイートを紹介します。
論文リンク:https://go.hyper.ai/Q4cQG
3. ProRL: 長期強化学習が大規模言語モデルの推論境界を拡大
強化学習がモデルの推論能力を本当に拡張するかどうかは、依然として議論の的となっている。本論文では、KLダイバージェンス制御、参照ポリシーリセット、そして多様なタスクスイートを組み合わせた新しい学習手法ProRLを提案する。これは、強化学習が言語モデルの推論能力の限界を有意に拡張する条件をより深く理解するための新たな知見を提供する。
論文リンク:https://go.hyper.ai/62DUb
4. GRPOによるマルチモーダルLLM推論のための教師なし事後学習
本研究では、安定性と拡張性に優れたオンライン強化学習アルゴリズムであるGRPOを用いて、外部からの教師なしに継続的な自己改善を実現し、マルチモーダル大規模言語モデルのためのシンプルで効果的な教師なし学習後フレームワークであるMM-UPTを提案する。実験結果から、MM-UPTはQwen2.5-VL-7Bの推論能力を大幅に向上させることが示された。
論文リンク:https://go.hyper.ai/W5nO5
5. 推論言語モデルのための強化学習のエントロピーメカニズム
本論文は、大規模強化学習(RL)における推論に大規模言語モデル(LLM)を用いる際の大きな障害、すなわち方策エントロピーの崩壊を克服することを目指しています。この目的のため、研究者らは2つのシンプルかつ効果的な手法、Clip-CovとKL-Covを提案しました。前者は共分散の高いトークンをクリップし、後者はこれらのトークンにKLペナルティを課します。実験結果は、これらの手法が探索行動を促進し、方策がエントロピー崩壊を回避し、下流のパフォーマンスを向上させるのに役立つことを示しています。
論文リンク:https://go.hyper.ai/rFSoq
AIフロンティアに関するその他の論文:https://go.hyper.ai/UuE1o
コミュニティ記事の解釈
1. チェコ科学アカデミーは、2億の分子質量スペクトルを網羅し、世界最大の質量分析データセットGeMSを構築するためのDreaMSモデルをリリースしました。
チェコ科学アカデミー有機化学・生化学研究所の研究チームは、言語分野における GPT シリーズの飛躍的進歩を利用して、Global Natural Products Social Molecular Network (GNPS) から 7 億件の MS/MS スペクトルをマイニングし、史上最大の質量分析データセット GeMS の構築に成功し、1 億 1,600 万のパラメータを持つ Transformer モデル DreaMS をトレーニングしました。
レポート全体を表示します。https://go.hyper.ai/P9qvl
2. AIコンパイラ技術サロン | AMD/北京大学/Muxi/上海Chuangzhiが北京に集結、TVM/Triton/TileLangがそれぞれの強みを披露
HyperAIは、最先端の研究と応用シナリオをより密接に結び付けるため、7月5日に北京で第7回Meet AI Compiler Technology Salonを開催します。AMD、北京大学、Muxi Integrated Circuitなどから多くの上級専門家を招待し、AIコンパイラのベストプラクティスとトレンド分析を共有できることを嬉しく思います。
レポート全体を表示します。https://go.hyper.ai/FPxw2
3. 深層強化学習(DRL)は都市火災の最適化を可能にする。中国科学院のチームは、施設配置の問題を解決するための新たなDRL手法を提案した。
中国科学院宇宙情報イノベーション研究所の梁浩建博士は、中国地理学会地理モデル及び地理情報分析専門委員会2025年度学術年会において、「階層的深層強化学習に基づく都市緊急消防施設配置の最適化手法の研究」と題する講演を行いました。都市消防施設配置の最適化を出発点として、地理空間最適化分野における従来の最適化手法を体系的に検証し、深層強化学習(DRL)に基づく最適化手法の利点と可能性を詳細に紹介しました。本稿は、梁浩建博士の講演のハイライトを抜粋したものです。
レポート全体を表示します。https://go.hyper.ai/xvnAI
4. オンラインチュートリアル | シンガポール国立大学ショーラボがOmniConsistencyモデルをリリースし、プラグアンドプレイの画像スタイル転送を実現
シンガポール国立大学のShow Labは、大規模拡散トランスフォーマー(DiT)を使用したユニバーサル一貫性プラグイン「OmniConsistency」を2025年5月28日にリリースしました。これは、FluxフレームワークのあらゆるスタイルのLoRAと互換性のある完全なプラグアンドプレイ設計であり、様式化された画像ペアの一貫性学習メカニズムに基づいて堅牢な一般化を実現します。
レポート全体を表示します。https://go.hyper.ai/etmWQ
人気のある百科事典の項目を厳選
1. DALL-E
2. 人間と機械のループ
3. 逆ソート融合
4. 双方向の長短期記憶
5. 大規模マルチタスク言語理解
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
サミットの締め切りは6月
S&P 2026 6月6日 7:59:59
ICDE 2026 6月19日 7:59:59
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
以上が今週の編集長セレクトの内容です。含めたい場合は ハイパーアイ 公式サイト上のリソースについては、メッセージを残したり、ご意見をお寄せいただくこともできます。
また来週お会いしましょう!








