Command Palette
Search for a command to run...
Alphafold3 依存データベースがパッケージ化され、オンラインになりました。 ICLR フルスコア用紙 IC-Light: ライトトーン特性を正確に識別

AlphaFold2 は、リリース以来 AI4S 分野でセンセーションを巻き起こし、今年のノーベル賞も受賞しました。 AlphaFold3 は、そのアップグレード版として、タンパク質の構造を予測できるだけでなく、リガンド (低分子)、核酸 (DNA および RNA) がどのように集まって相互作用するかなど、タンパク質と他のさまざまな生体分子との相互作用の構造も予測できます。
つい先月、Google DeepMind は、学術研究用に AlphaFold3 モデルの重みとその依存関係データベースをオープンソース化しました。 HyperAl は現在、AlphaFold3 依存データベースとオンラインになっています。論文を読みながら、AlphaFold3 によってもたらされる技術的進歩をぜひ体験してください。
オンラインでの使用:https://go.hyper.ai/wVItz
12 月 9 日から 12 月 13 日までの hyper.ai 公式 Web サイトの更新の概要:
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 3
* コミュニティ記事の選択: 5 記事
* 人気のある百科事典のエントリ: 5
※1月提出締切:9日
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
このデータベースには、AlphaFold 3 が依存する多数のタンパク質および RNA データベースが含まれています。これには、BFD small、MGnify、PDB、PDB seqres、UniProt、UniRef90、NT、RFam、RNACentral の 9 つのデータベースが含まれます。
直接使用します:https://go.hyper.ai/wVItz
2. Mol-Instructions 大規模生体分子命令データセット
このデータセットには、分子指向の命令、タンパク質指向の命令、生体分子テキスト命令の 3 種類の命令が含まれており、生体分子分野における大規模言語モデルの理解と予測能力を強化するための豊富な命令データを提供することを目的としています。
直接使用します:https://go.hyper.ai/Gut1y
3. CoSQL 会話テキストから SQL データ セットへ
CoSQL には 3,000 を超える会話グループ、合計 10,000 を超える注釈付き SQL クエリが含まれており、その内容は 200 のデータベースに及び、モデルの堅牢性を調べるために異なるデータ グループで使用されるデータベースは重複しません。
直接使用します:https://go.hyper.ai/9Blzy

このデータセットは WikiHop と MedHop の 2 つの部分で構成されており、マルチホップ推論を実行できる読解手法の構築を目的としています。つまり、異なる文書に散在する事実から新しい事実に到達するには複数の推論ステップが必要です。
直接使用します:https://go.hyper.ai/u1qRw

このデータ セットには、秦王朝以前から清王朝後期および中華民国までの医学の古典をカバーする約 700 の古代中国医学書が含まれています。これらの文書には、医学理論、処方箋、薬理学などが含まれているだけでなく、豊富な臨床症例や医学百科事典の知識も含まれています。
直接使用します:https://go.hyper.ai/8Vh6A
6. IndustryCorpus2 ヘルスケア データ セットのサブセット
このデータセットは、特に医療および健康分野での研究と応用を対象とした高品質のデータ リソース ライブラリであり、データの正確性と信頼性を確保するために厳格なスクリーニングおよびクリーニング プロセスが行われています。医療記録、医学文献、患者からのフィードバックなど、ヘルスケア分野のさまざまな種類のデータを幅広くカバーしており、研究者や開発者に探索と革新のための包括的な視点を提供します。
直接使用します:https://go.hyper.ai/G9qn2
7. P-MMEval 多言語マルチタスク ベンチマーク データ セット
このデータ セットには、3 つの基本的な自然言語処理 (NLP) データ セットと 5 つの高度な機能固有のデータ セットが含まれており、コード生成、知識理解、数学的推論、論理的推論、命令追従などのタスクをカバーします。
直接使用します:https://go.hyper.ai/qbzhv
8. 神農 TCM データセット 神農 TCM データセット
データセットには 110,000 を超える指示データが含まれており、これらは伝統的な中国医学の分野における中心的なエンティティとさまざまな意図シナリオに焦点を当てた、エンティティ中心の自己指示メソッドを通じて生成され、モデルのパフォーマンスを向上させることができるだけではありません。 、モデルのパフォーマンスも向上しますが、伝統的な中国医学に関連する質問に答える機能は、伝統的な中国医学の診断を支援し、個別の医療アドバイスを提供することもできます。
直接使用します:https://go.hyper.ai/Okruv
9. DS-1000 コード生成ベンチマーク データ セット
このデータ セットには、StackOverflow から生成された 1,000 件の実際のデータ サイエンスの質問が含まれており、NumPy、Pandas、TensorFlow など、Python で広く使用されている 7 つのデータ サイエンス ライブラリをカバーしています。
直接使用します:https://go.hyper.ai/AL4h0
10. IndustryCorpus2-tourism-geography 観光地理データセット
このデータ セットは、Zhiyuan 産業データ セット IndustryCorpus2 の観光地理学データ セットのサブセットであり、観光スポットの紹介、旅行ガイド、観光客のレビュー、地理情報など、観光地理学分野のさまざまなデータ タイプを幅広くカバーしています。 、自然言語処理、機械学習などに使用されます。学習、データ マイニング、旅行推奨システムなどのさまざまな研究および応用分野で、豊富な応用シナリオが提供されます。
直接使用します:https://go.hyper.ai/FIAM9
選択された公開チュートリアル
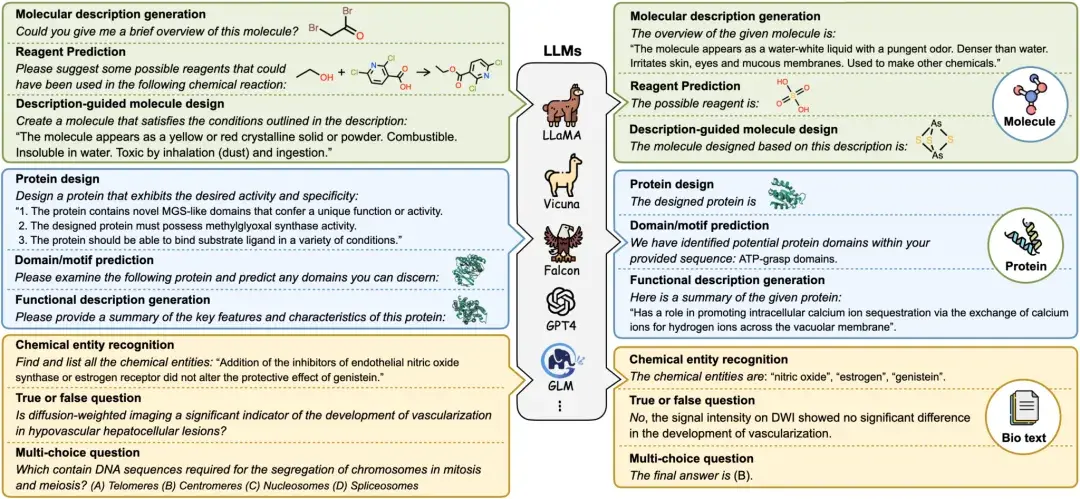
Allegro には、基本的なテキスト入力を、720p 解像度、1 秒あたり 15 フレーム、最大 6 秒のビデオ長の高解像度ビデオ コンテンツに変換する機能があります。 このモデルは、ビデオ合成の分野で優れたパフォーマンスを発揮し、品質と時間的コヒーレンスの両方に優れています。
このチュートリアルはモデル推論チュートリアルです。モデルのビデオ生成には時間がかかるため、このチュートリアルでは 5 秒のビデオ効果を生成できます。
オンラインで実行:https://go.hyper.ai/MgUVZ
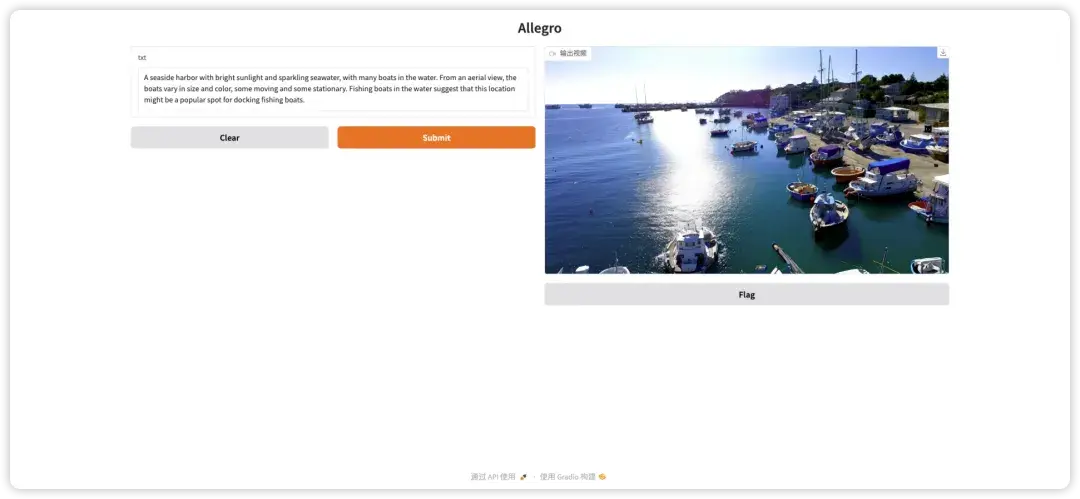
2. IC-Light v2:AI照明制御アップグレードデモ
IC-Light は Imusing Consistent Light の略で、機械学習モデルを通じて画像の再照明を実現することを目的としたプロジェクトです。このチュートリアルは、IC-Light v2 のアップグレード バージョンです。オリジナルの IC-Light と比較して、このバージョンは Flux モデルに基づいてトレーニングされているため、画像の照明トーンの特性をより正確に識別し、より詳細な表現を実現できます。リアルな融合効果。
以下のリンクを入力し、チュートリアルの指示に従って、画像内の照明効果を制御します。
オンラインで実行:https://go.hyper.ai/hg0cM
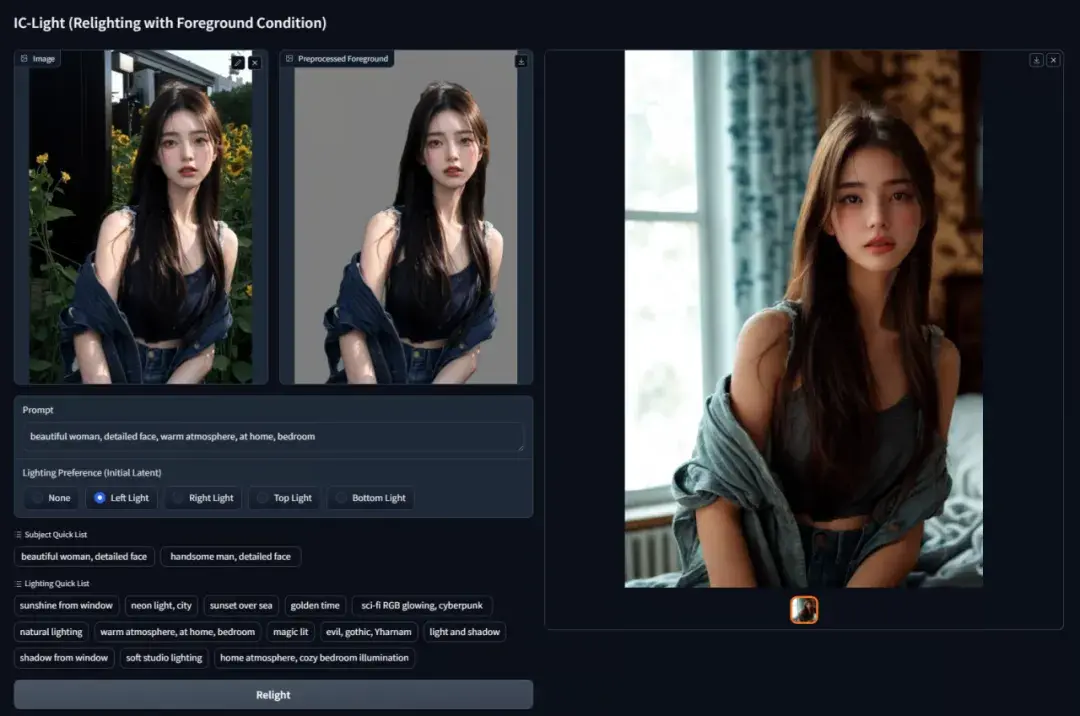
3. Hunyuan3D: わずか 10 秒で 3D アセットを生成
Hunyuan3D は、軽量バージョンと標準バージョンを含む 3D 生成拡散モデルで、どちらもテキストと画像の入力から高品質の 3D アセットの生成をサポートします。定性的および定量的な多次元評価の後、Hunyuan3D-1.0 は、幾何学的詳細、テクスチャ詳細、テクスチャとジオメトリの一貫性、3D 合理性、および指示への準拠性の点で非常に優れたパフォーマンスを発揮しました。
このチュートリアルは Hunyuan3D の軽量バージョンであり、下のリンクをクリックしてチュートリアルのガイドラインに従って 3D モデルの生成を体験してください。
オンラインで実行:https://go.hyper.ai/Rsrno
注目のコミュニティ記事
1. AI のゴッドファーザーであるヒントンが責任者を務め、材料スタートアップ CuspAI は英国で最も注目されるスタートアップの 1 つとなっています。
新興企業としての CuspAI の強みを過小評価することはできません。そのシードラウンドでは 3,000 万米ドルが調達され、その年のヨーロッパ最大のシードラウンドの 1 つとなりました。さらに、機械学習の第一人者であるマックス ウェリングは同社の共同創設者の 1 人であり、ノーベル賞とチューリング賞を受賞したジェフリー ヒントンは彼の会社の取締役顧問です。この記事では CuspAI について詳しく説明します。
レポート全体を表示します。https://go.hyper.ai/3fQFG
2. 時系列予測の「ブラックボックス」問題を突破!華中科技大学は、患者の生存率の重要な指標を明らかにするために CGS-Mask を提案しました
AI技術が私たちの日常生活に広く適用されるにつれて、モデルの「解釈可能性」は徐々に解決すべき緊急の課題になりました。この問題は、時系列予測タスクで特に顕著です。時系列予測を「目に見える」プロセスにするために、華中科技大学のLu Feng氏のチームは、シドニー大学および同済病院のZomaya学者チームと協力して、新しい方法であるCGS-Maskを提案しました。時系列予測と解釈可能性を組み合わせることで、この方法はモデルの予測精度を向上させ、予測結果をより直感的で解釈しやすくすることができます。この記事は、論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/TFEsd
3. いち早くデモを体験してみよう!基本ゲノムモデル Evo が Science の表紙に掲載され、分子スケールからゲノムスケールまでの予測と生成が可能になります
スタンフォード大学と米国アーク研究所の研究チームがゲノムベースのモデルEvoを提案し、Science誌の表紙記事として掲載された。 DNA、RNA、タンパク質のマルチモーダルタスクにおいてゼロサンプル予測と高精度生成を実現できます。 HyperAI スーパー ニューラル チュートリアル セクション「Evo: Prediction and Generation from Molecule to Genome Scale」がオンラインになり、ワンクリックでクローンを作成するだけですぐに体験できます。
レポート全体を表示します。https://go.hyper.ai/5WPGm
4. AIの名付け親であるヒントンは天才一家に生まれたが、70歳を超えてチューリング賞とノーベル賞を連続受賞した落ちこぼれの常習犯。
AI のゴッドファーザーであるヒントンは天才的な家庭に生まれましたが、学校を中退した常習犯です。彼の立ち上げた会社はたった 3 人しかいなかったのに、彼が費やした 4,400 万ドルで Google に買収されました。ニューラルネットワークの開発に半世紀を費やしましたが、率直に後悔しました...それはどのような人生経験であり、今の彼を形作ったのでしょうか?この記事はヒントンについての詳細なレポートです。
レポート全体を表示します。https://go.hyper.ai/EHWs6
5. 最初の vLLM 中国語ドキュメントがオンラインになりました。最新バージョンのスループットは 2.7 倍に向上し、レイテンシは 5 倍に短縮され、大規模な言語モデルの推論が高速化されています。
vLLM は、大規模な言語モデルの推論を高速化するために特別に設計されたフレームワークで、KV キャッシュ メモリの無駄をほぼゼロにします。最新バージョン v0.6.4 では、マルチステップ スケジューリングと非同期出力処理が導入され、GPU 使用率がさらに最適化され、処理効率が向上します。国内の開発者が vLLM のバージョン アップデートや最先端の開発についてより便利に学べるように、HyperAI コミュニティは vLLM の中国語ドキュメントのローカライズを完了しました。
vLLM の中国語ドキュメントを表示します。https://vllm.hyper.ai/
人気のある百科事典の項目を厳選
1.メル・ケプストラムMFCC
2. 相互ソーティング融合 RRF
3. マスクされた言語モデリング MLM
4. パレートフロント パレートフロント
5. データの拡張
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








