Command Palette
Search for a command to run...
米国の失業率と貧困率を正確に予測するために、Google の基本的な人口動態モデル PDFM がオープンソース化されており、既存の地理空間モデルを強化できます。

病気、経済危機、失業、災害…人間の世界は長い間、さまざまな問題によって「侵略」されてきました。このような複雑な社会問題を解決するには、人口動態を理解することが不可欠です。政府当局者は、人口動態データを使用して病気の蔓延をシミュレーションしたり、住宅価格や失業率を予測したり、さらには経済危機を予測したりすることができます。しかし、人口動態を正確に予測することは、過去数十年にわたって研究者や政策立案者にとっての課題でした。
人口動態を理解する従来の方法は、多くの場合、国勢調査、調査、衛星画像データに依存しています。これらのデータは確かに貴重ですが、それぞれに独自の欠点があります。たとえば、国勢調査は包括的ではありますが、頻度が低く費用がかかります。調査は地域的な洞察を提供しますが、多くの場合、規模や一般性に欠け、衛星画像は広範な概要を提供しますが、人間の活動に関する詳細な情報は得られません。これらの欠点を改善するために、Google は人口動態の行動特性を理解することを期待して、長年にわたって大規模なデータセットを構築してきました。
最近、Google は、機械学習を使用して世界中で利用可能な豊富な地理空間データを統合し、従来の地理空間モデルの機能を大幅に拡張する新しい人口動態基盤モデル (PDFM) を提案しました。研究者らは、健康、社会経済、環境をカバーする 27 のタスクについて、内挿、外挿、および超解像度の問題に関して PDFM のベンチマークを実施しました。この研究では、PDFM が内挿の 27 タスクすべてで最先端のパフォーマンスを達成し、外挿および超解像度タスクのうち 25 のタスクで最高のパフォーマンスを達成したことがわかりました。研究者らはまた、PDFM を最先端の予測ベースモデル (TimesFM) と組み合わせることで、完全に監視された予測手法を上回る失業率と貧困率の予測に成功できることを実証しました。
関連する研究のタイトルは「人口動態基盤モデルによる一般地理空間推論」で、arXiv で公開されました。同時に、研究者らはすべての PDFM 埋め込みとサンプル コードを GitHub でリリースし、研究コミュニティが新しいユースケースに適用し、学術研究と実践をさらに強化できるようにしました。
PDFM プロジェクトのオープンソース アドレス:
https://github.com/google-research/population-dynamic
研究のハイライト:
* 研究者らは、データ ソースごとに埋め込みディメンションを分割する分離された埋め込みアーキテクチャを導入しました。これにより、モデルがすべての入力に注意を払い、各タイプのデータに関連する情報を保持できるようにするとともに、下流のタスクにデータ ソース レベルの解釈可能性を提供します。
* 研究者らは、PDFM を使用して最先端の予測ベース モデル TimesFM を強化し、郡レベルの失業率と郵便番号レベルの貧困率の予測を改善する方法を示しています。同様のアプローチを使用して、PDFM 埋め込みを使用して他の既存の地理空間分類および回帰モデルを強化できます。
* 研究者らは、内挿、外挿、超解像度、および予測タスクにおける優れたパフォーマンスを通じて、PDFM が科学研究、慈善活動、公衆衛生および環境衛生、ビジネス分野など、地理空間モデリングを必要とするさまざまなアプリケーション シナリオに簡単に拡張できることを実証しています。

用紙のアドレス:
https://arxiv.org/abs/2411.07207
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
データセット: 5 つの一般的なデータセット
PDFM を開発するために、研究者らは、次のように、郵便番号および郡レベルで地理的エリアをカバーする 5 つの大規模なデータ セットを収集および整理しました。
① 検索トレンドの集計:研究者らは、2022 年 7 月の上位 500 件のクエリの集計数を計算しました。これには、各郵便番号内で少なくとも 20 件の検索が必要で、結果として 100 万件以上の一意のクエリが発生しました。次に、各クエリが発生した郵便番号の合計数によって測定される全国的な人気度によってこれらのクエリをランク付けし、全国の郵便番号レベルで集計された検索傾向活動を代表するものとして最も一般的な上位 1,000 のクエリを選択しました。
② 地図データセット(マップ):研究者らは、2024 年 5 月に Google マップで少なくとも郵便番号 5% に含まれる最も一般的な 1,192 の名所カテゴリを選択しました。各カテゴリは幅広い名所の場所をカバーしており、たとえば、「医療施設」カテゴリには小児病院や大学病院が含まれています。次に、各地理的境界内で利用可能な施設の総数を計算し、郵便番号および郡レベルで正規化された 1,192 次元の特徴ベクトルを生成しました。
③忙しさデータセット(忙しさ):研究者らは、地図データ内の各スポットのカテゴリごとに、それらのカテゴリ内の関連する場所への 1 か月間にわたる訪問の合計を計算し、それらのカテゴリの混雑度を要約しました。
④ 天気と空気の質:研究者らは気象と大気質のデータを収集し、2022 年 7 月の時間ごとのデータをまとめて、平均値、最小値、最大値を使用して説明しました。変数の完全なリストには、平均海面気圧、総雲量、10 メートルの U 風成分、10 メートルの V 風成分、2 メートルの気温、2 メートルの露点温度、日射量、総降水量、空気が含まれます。品質指数、一酸化炭素濃度、二酸化窒素濃度、オゾン濃度、二酸化硫黄濃度、吸入性粒子状物質(<10μm)濃度、微粒子状物質(<2.5μm)濃度。
⑤リモートセンシング:研究者らは、SatCLIP モデルの ViT16-L40 バージョンから生成された衛星画像埋め込みデータを組み合わせて、各郵便番号の重心によってインデックス付けされた埋め込みデータを取得しました。 SatCLIP モデルは、2021 年 1 月 1 日から 2023 年 5 月 17 日までの Sentinel-2 衛星画像から 100,000 個のタイルを集約する、ユニバーサル地理位置エンコーダーとして設計されています。
研究者らは、データセットをグラフ ニューラル ネットワーク (GNN) アーキテクチャと組み合わせて、タスク固有ではなく一般的なエンベディングを生成する基本モデルをトレーニングしました。
モデル アーキテクチャ: GNN を使用して地理空間問題を効率的かつ直感的に解決します
PDFM モデルの構造は次の図に示されています。 フェーズ 1 (フェーズ 1) では、研究者らは、データセットをグラフ ニューラル ネットワーク (GNN) アーキテクチャと組み合わせて、埋め込みを生成する基本モデルをトレーニングしました。これらの埋め込みは、特定のタスクに固有のものではなく、普遍的なものです。フェーズ 2 では、これらの埋め込みと既存のタスク固有のグラウンドトゥルース データを活用して、下流モデル (線形回帰、単純な多層パーセプトロン、勾配ブースト デシジョン ツリーなど) を学習し、内挿、外挿、スーパーなどのさまざまなタスクに適用します。 -解像度と予測。
* 補間タスク: 既知のデータ ポイントの値に基づいて、未知のデータ ポイントの値を推測して埋めることを指します。
* 外挿タスク: 既存のデータや経験を通じて、現在知られている範囲を超えた状況、傾向、結果を推測することを指します。
※超解像度タスク:低解像度の画像やデータをアルゴリズムによって高解像度にアップグレードすることを指します。
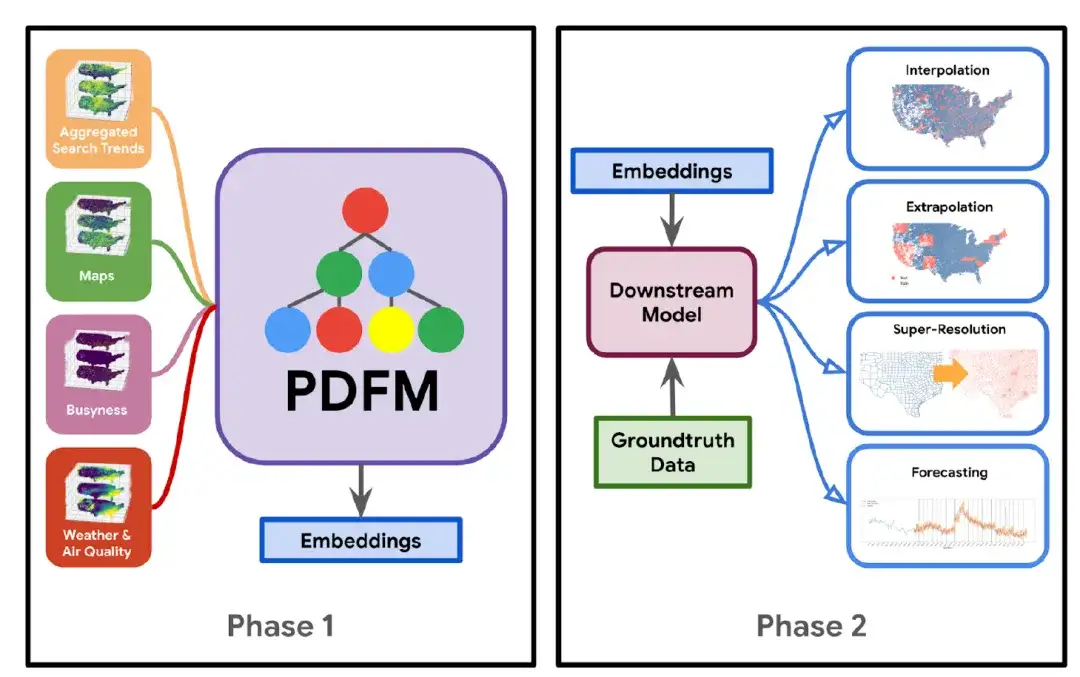
具体的には、PDFM モデルの中核となるのはグラフ ニューラル ネットワーク (GNN) であり、位置を情報豊富な低次元数値ベクトルにエンコードします。これは主に次の 5 つの部分で構成されます。
※グラフの構成:研究者らは、郡レベルと郵便番号をノードとして使用し、近隣関係を通じてエッジを確立して、異種地理空間グラフを構築しました。構築された地理空間グラフには、郵便番号と郡レベルのノードを同じタイプのノード セットとして扱う同種のノード セットと、ノードを接続する異なるタイプのエッジを持つ異種のエッジ セットが含まれます。
* サブピクチャのサンプリング:サブグラフ サンプリングは、大規模な GNN をトレーニングするためのサブグラフを作成し、モデルにランダム性を追加するために実行されます。これはシード ノードから開始され、幅優先の方法で各エッジ セットを横断し、重み付けされた方法で固定数のノードをサンプリングし、4 ホップに達したときに終了します。
具体的には、研究者らはシード ノードから開始し、幅優先の方法で各エッジ セットを横断し、重み付けされた方法で固定数のノードをサンプリングし、4 ホップの距離に達したときに終了しました。このアプローチにより、郵便番号および郡レベルのノードの合計数と同じ数のサブグラフが生成されます。
* 前処理:列方向の正規化がすべての特徴に適用され、特徴値の範囲の端点がクリッピングによって圧縮されます。
*モデリングとトレーニングの詳細:帰納的手法である GraphSAGE は、ノードの特徴情報を利用してノードの埋め込みを学習するために採用されています。 GraphSAGE は、ローカル近傍集合情報からエンベディングを生成する関数を学習します。集約アーキテクチャには、GraphSAGE で提案されているプーリング アーキテクチャが使用されます。このアーキテクチャでは、隣接ノードからのノード状態が ReLU 変換を使用して全結合層を通過し、変換された古い状態と隣接ノードの状態が要素ごとに追加されます。集計。研究者らは、GraphSAGE アーキテクチャを使用してワンショット メッセージ パッシングを容易にし、GNN 層の後にサイズ 330 の線形層を追加して、ノードレベルの表現を圧縮された埋め込みにエンコードしました。
* ハイパーパラメータ調整:20% のシード ノード (郡および郵便番号を含む) から均一にサンプリングされ、チューニング用の検証セットを形成します。チューニング用のハイパーパラメータには、ドロップアウト率、ノードの埋め込みのサイズ、GraphSAGE の隠れユニットと層の数、埋め込みが含まれます。サイズ、正則化、学習率。
研究結果: 内挿、外挿、超解像、予測タスクで優れたパフォーマンスを発揮
PDFM は、米国本土全体にわたるさまざまな地理空間上の課題に対処できる柔軟なベース モデリング フレームワークです。多様なデータセットを統合することにより、PDFM は 27 の健康、社会経済、環境タスクに組み込まれ、SatCLIP や GeoCLIP などの既存の最先端 (SoTA) 位置エンコード方式を上回ります。
内挿タスクでは、PDFM は 27 タスクすべてで良好なパフォーマンスを示し、外挿タスクと超解像度タスクでは 25 タスクで優れています。さらに、研究者らは、PDFM 埋め込みがどのように TimesFM などの予測モデルのパフォーマンスを向上させ、それによって郡レベルの失業率や郵便番号レベルの貧困率などの重要な社会経済指標の予測を改善できるかを示しています。これは、研究、社会福祉、公衆衛生および環境衛生、ビジネスにおける幅広い応用の可能性を浮き彫りにしています。
具体的な実験結果は以下の通りです。
①補間実験
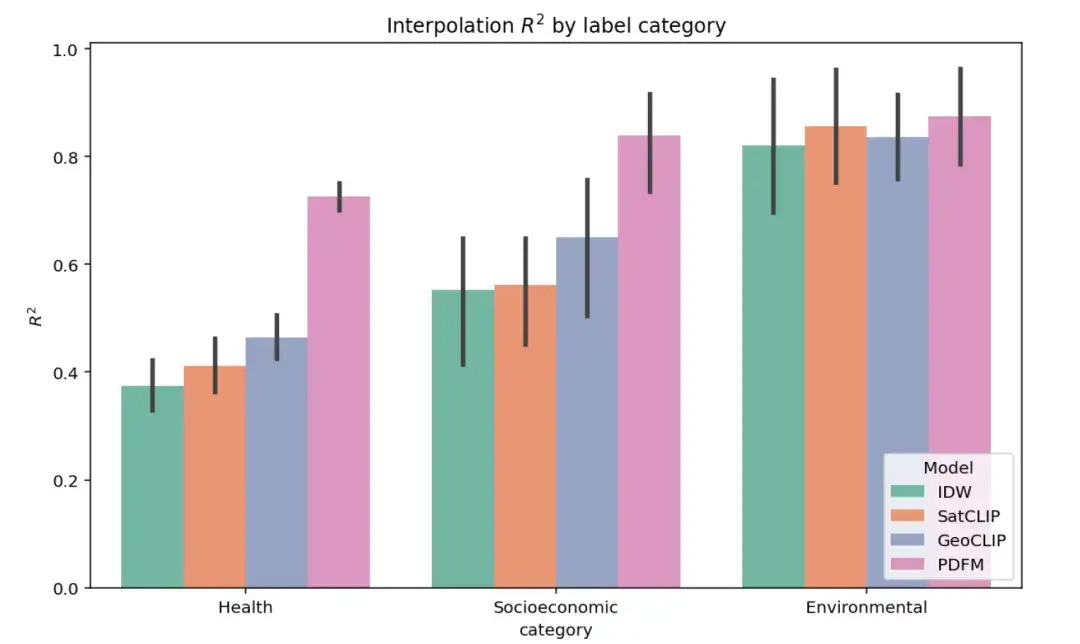
以下の図は、健康、社会経済カテゴリ、環境の 3 つのカテゴリにおける 27 のタスクに関する完全な内挿実験結果を示しています。 ² 指標は、さまざまなモデルのパフォーマンスを評価するために使用されます (値が高いほど、より優れたモデルを示します) は、ターゲットの分散を説明します。変数ラベル)。図に示されているように、PDFM は社会経済および健康タスク カテゴリにおいて SatCLIP および GeoCLIP を大幅に上回っています。
次の表は、収入 (Income)、住宅価値 (HomeValue)、夜間照明 (NightLights)、人口密度 (PopulationDensity)、樹木被覆率 (TreeCover)、標高 ( PDFM は一貫して良好なパフォーマンスを示し、27 タスクすべてで平均 2 を達成しました。は 0.83 で、21 の健康関連タスクの平均 ² は 0.73 です。
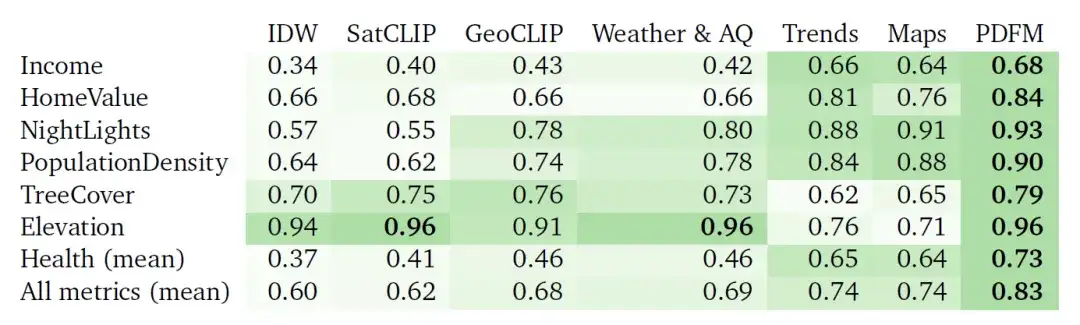
表: Interpolation² の結果 (値が高いほど優れています)。これらの実験では、GBDT をダウンストリーム モデルとして使用し、逆距離重み付け (IDW) ベースの内挿、SatCLIP 埋め込み、GeoCLIP 埋め込み、PDFM 埋め込み、およびそれらのサブコンポーネント (天候と大気質、集約された検索傾向、地図と忙しさ) のパフォーマンスを比較します。
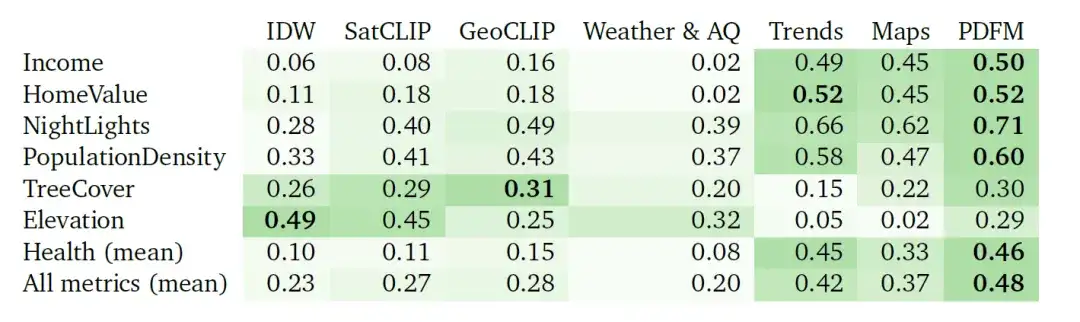
② 外挿実験
以下の図は、健康、社会経済カテゴリ、環境という 3 つのカテゴリの 27 タスクに関する完全な外挿実験結果を示しています。² 指標は、モデルのパフォーマンスを評価するために今でも使用されています。図に示すように、GeoCLIP は環境タスクの処理においてわずかに優れていますが、PDFM は健康および社会経済的変数の予測において他のすべてのベースライン モデルを大幅に上回っています。
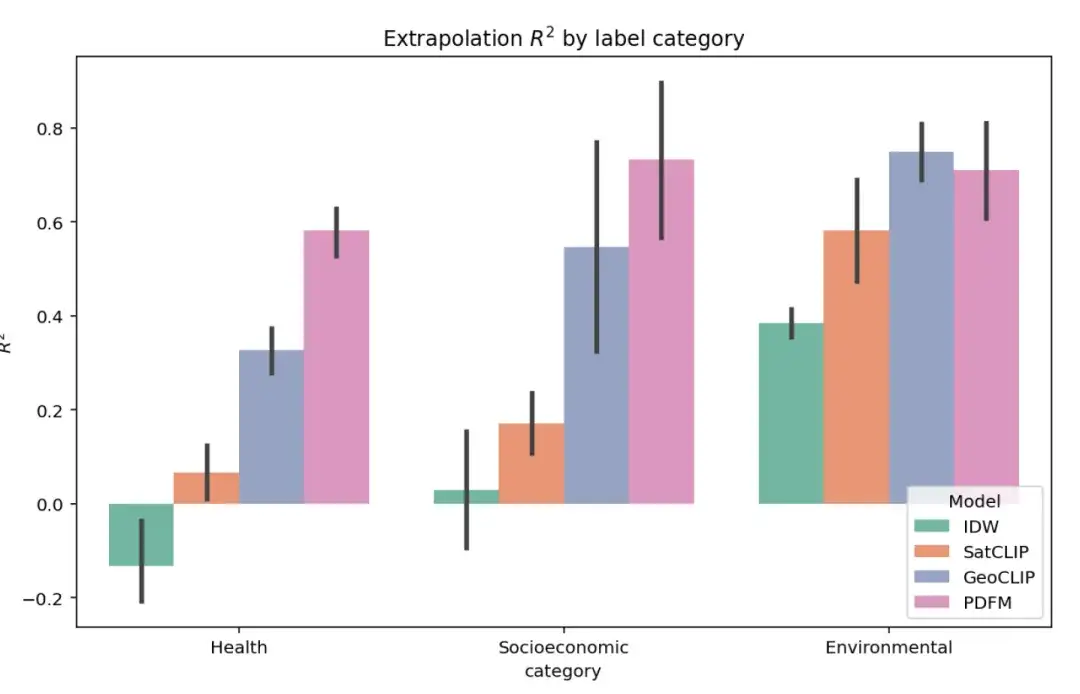
外挿タスクは、ラベル付きデータに重大な欠落があるため、困難なタスクです。この場合、PDFM は、以下の表に示すように、すべてのメトリクスの平均 ² が 0.70、健康関連メトリクスの ² が 0.58 という優れたパフォーマンスを示しています。ジオタグ付き画像を使用する GeoCLIP は、樹木被覆 (TreeCover) 予測で優れたパフォーマンスを発揮し、 ² =0.69 に達し、PDFM や他の単一モダリティを上回ります。ただし、全体として、PDFM は 27 タスク中 25 タスクでベースライン モデルを上回っており、外挿シナリオにおける PDFM の有効性が際立っています。
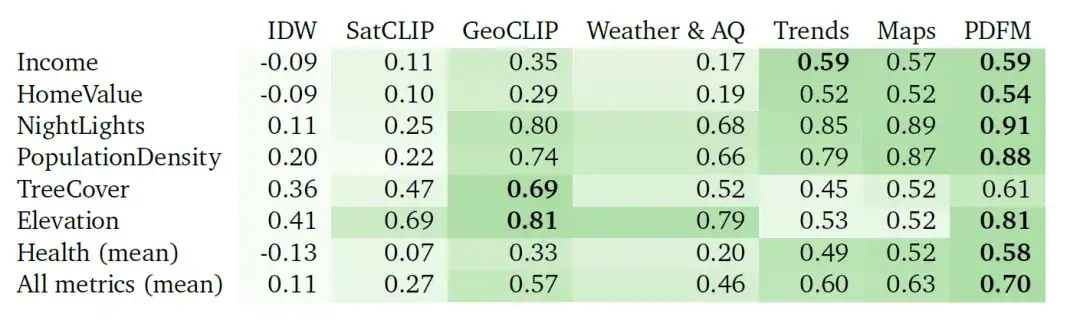
③超解像実験
以下の図は、郡の平均ピアソン相関係数 (r) を指標として使用して、27 のタスクの超解像度実験の完全な結果を示しています (高い値との比較)。モデルの予測が郵便番号レベルでの実際のラベルとより密接に関連していること)。
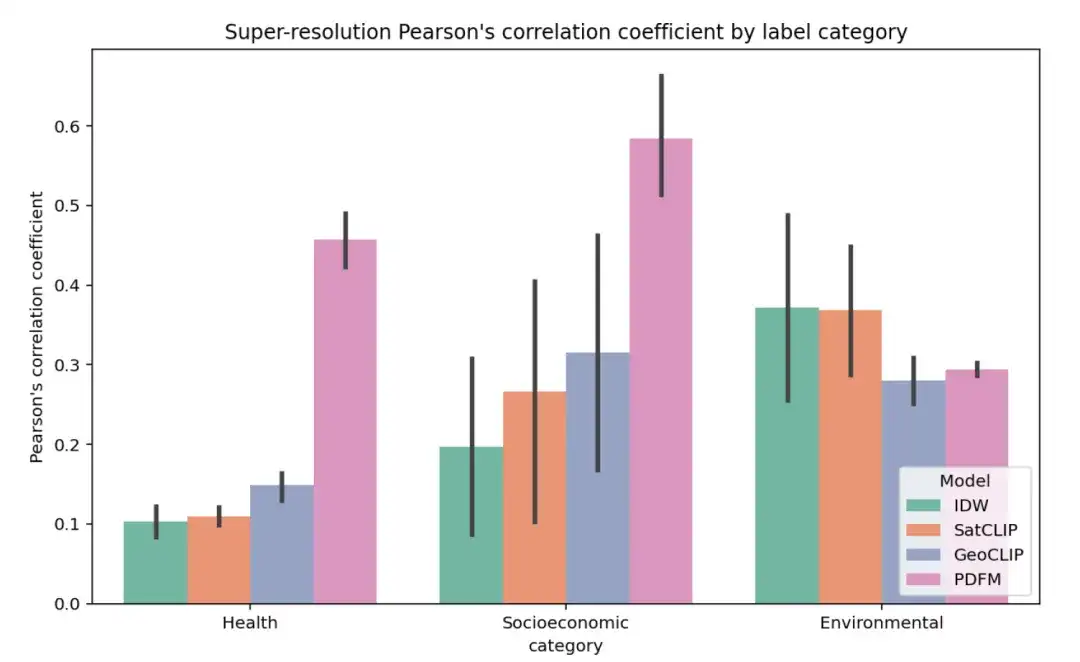
超解像度タスクはより困難であり、結果は次の表にまとめられています。IDW は予測標高タスク (標高タスク) で最も優れたパフォーマンスを示しますが、GeoCLIP は樹木被覆率タスクで最も優れたパフォーマンスを示します。全体として、PDFM は 27 タスク中 25 タスクで良好なパフォーマンスを示し、平均ピアソン相関係数は 0.48 でした。
④ 予測タスク
研究者らはまた、一般的な単変量予測基本モデルである TimesFM の予測誤差を修正するために PDFM エンベディングを使用する有効性も評価しました。主な目的は、将来の期間 (6 か月の失業率予測と 2 年間の失業率予測) にわたるこれらのエンベディングのパフォーマンスを評価することでした。貧困率予測の改善)。以下の表の結果は、PDFM 埋め込みと組み合わせたモデルが MAPE メトリクスで TimesFM のベースライン パフォーマンスを上回り、ARIMA よりも優れていることを示しています。これは、PDFM 埋め込みが TimesFM の予測効果を大幅に強化できることを示しています。
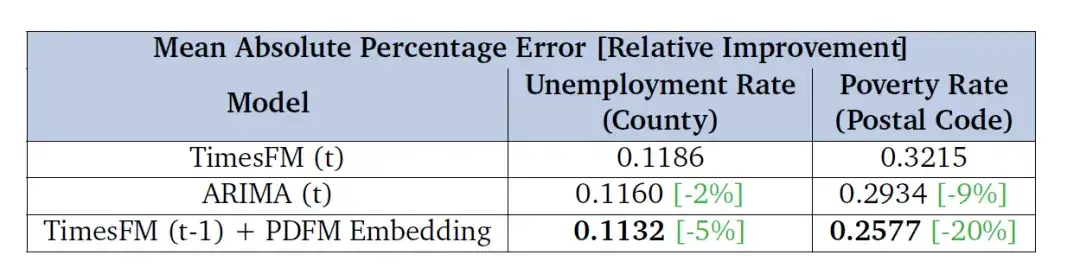
研究者らは、米国の郡レベルの失業率と郵便番号レベルの貧困率に基づいてパフォーマンスを評価し、平均絶対パーセント誤差(MAPE)を表に示し、値が低いほどパフォーマンスが良いことを示しています。
地理空間人工知能 (GeoAI) が急成長している
PDFM モデルの誕生は、地理空間データのもう一つの徹底的な探求と活用であると言えます。いわゆる地理空間データには、通常、さまざまなソースからさまざまな形式で収集された大量の時空間データが含まれます。これには、国勢調査データ、衛星画像、気象データ、携帯電話データ、地図画像、ソーシャル メディア データなどの情報が含まれます。科学的な方法で地理空間データを共有、分析、使用すると、失業率や住宅価格の予測、特定の薬物の影響や災害後の人口移動のシミュレーションなど、人間社会の発展に役立つ多くの洞察が得られます。
ただし、大量の地理空間データを効果的に処理する方法は課題です。人工ニューラル ネットワーク モデルの出現により、地理空間人工知能 (GeoAI) の概念が歴史的な瞬間に登場し、業界もこの分野で多くの研究を行ってきました。
たとえば、2024 年 4 月、鉱化予測モデルの解釈可能性と、鉱化プロセス中に地質学的要因によって引き起こされる空間的非定常性を改善するために、浙江大学の研究チームは、新しい地理空間人工知能手法を提案しました。ネットワーク加重ロジスティック回帰 (GNNWLR)。このモデルは、空間パターンとニューラル ネットワークを統合し、Shapley の加法的説明理論と組み合わせることで、予測の精度を大幅に向上させるだけでなく、複雑な空間シーンにおける鉱物予測の解釈可能性も向上させます。
クリックして詳細レポートを表示: 5 つの高度なモデルよりも優れた、浙江大学の Du Zhenhong チームは GNNWLR モデルを提案しました: 鉱化予測の精度を向上
2024 年 6 月、浙江大学 GIS 研究所の研究者は、ニューラル ネットワーク手法を革新的に導入した「地理的重み付け回帰アプローチにおける空間的近接性の尺度を最適化するニューラル ネットワーク モデル: 武漢の住宅価格に関するケーススタディ」というタイトルの論文を発表しました。観測点間のさまざまな空間的近接尺度 (ユークリッド距離、移動時間など) を測定するため非線形結合を実行して最適化された空間近接測定 (OSP) を取得することで、住宅価格の予測におけるモデルの精度が向上します。シミュレートされたデータセットと武漢の住宅価格の経験的ケースの研究を通じて、論文で提案されたモデルは世界的に優れたパフォーマンスを持ち、複雑な空間プロセスと地理的現象をより正確に記述できることが証明されました。
クリックして詳細レポートを表示: 武漢の住宅価格を正確に予測!浙江大学の GIS 研究室は、複雑な空間プロセスと地理現象を正確に記述する osp-GNNWR モデルを提案しました。
将来的には、AI技術の継続的な発展により、地理情報産業はより強固な技術基盤とより便利な開発ツールを手に入れ、人類が地理空間インテリジェンスの時代に突入することを促進するでしょう。
参考文献:
1.https://arxiv.org/abs/2411.07207
2.https://research.google/blog/insights-into-population-dynamics-a-foundation-model-for-geospatial-inference/
3.https://www.ibm.com/cn-zh/topics/geospatial-data
4.https://mp.weixin.qq.com/s/eQz5N-cFTtGIkDk7IqMZxA
5.https://www.xinhuanet.com/science/2








