Command Palette
Search for a command to run...
ただ! ACL 2024が最優秀論文7作品を発表、華中科技大学の学部生の研究が受賞

8月11日、世界的に有名な計算言語学協会(ACL)年次総会がタイのバンコクで正式に開幕した。 ACL 2024 は 6 日間にわたって開催され、メインカンファレンスに加えて 34 のワークショップが開催されます。
2022 年から、ACL は毎月の期限を設定するローリング レビュー メカニズム (ACL ローリング レビュー、ARR) を開始しました。今年1月にも当局は良いニュースを発表した。論文投稿の匿名期間が廃止され、著者は投稿期間中に自分の研究を宣伝することが許可されたというものだ。この規制は、公開後の次の審査サイクルでも直接発効します。
公式データによると、今年のメインカンファレンスの受け入れ率は 21.3%、調査結果の受け入れ率は 22.1% です。

ACL 2024では、高品質のオープンソース データセット、オープンソース モデル、オープンソース ソフトウェア、およびその他の関連研究結果を受け取る特別なトピック「再現可能な NLP 研究のためのオープン サイエンス、オープン データ、およびオープン モデル」も追加されたことは言及する価値があります。 、オープン サイエンスと再現可能な NLP 研究に関する業界の議論を刺激し、オープン ソース ソフトウェアの開発をサポートすることを目的としています。

8月14日、ACL 2024の一連の賞が発表された。このテーマには 22 の主要会議論文が採択され、トピック論文賞を受賞したのは「OLMo: Accelerated the Science of Language Models」でした。
用紙のアドレス:https://arxiv.org/pdf/2402.00838

Test of Time賞は、2014年に出版された「GloVe: Global Vectors for Word RepresentationGloVe」が受賞した。
用紙のアドレス:https://aclanthology.org/D14-1162.pdf

また、ACL 2024では、華中科技大学、アデレード大学、安陽師範大学、華南理工大学が共同発表した「拡散モデルによるOracle Bone Languageの解読」が最優秀論文7本を選出し、最優秀論文を受賞した。最初の著者は、華中科技大学ソフトウェア学部長の白祥教授のチームの 2021 年度学部生、グアン・ハイスです。 HyperAI スーパーニューラルについては、この記事で詳しく説明します。
公式アカウントをフォローし、バックグラウンドで「ACL 2024」と返信すると、すべての受賞論文をダウンロードできます
残る6本の受賞論文は以下の通り。
記憶プロファイルの因果関係の推定

* 紙のアドレス:https://arxiv.org/abs/2406.04327* 研究機関: ケンブリッジ大学、チューリッヒ工科大学 * 研究内容: 研究者らは、トレーニング プロセス全体を通じてモデルのごく一部のインスタンスの動作を観察するだけで済む、原理に基づいた効率的な新しいメモリ推定手法を提案しました。モデルの記憶特性、つまりトレーニング中の記憶傾向を特徴付けることが可能です。
アヤ モデル: 命令を微調整したオープンアクセス多言語モード

* 紙のアドレス:
https://arxiv.org/abs/2402.07827
※研究機関:Cohere For AI、ブラウン大学、Cohere、Cohere For AI Community、MIT、カーネギーメロン大学
*研究内容:研究者らは、101言語の指示に従い、言語カバー範囲を3倍にする大規模な多言語生成言語モデルAyaを立ち上げました。さらに、研究者らは、多言語評価テクノロジーを 99 言語に拡張する広範な新しい評価スイートを導入しました。
自然言語の充足性: 問題分布の調査とトランスフォーマーベースの言語モデルの評価
*現在、この論文のプレプリント版はありません*

* 紙のアドレス:https://arxiv.org/abs/2406.05930* 研究機関: カーネギーメロン大学、南カリフォルニア大学 * 研究内容: 研究者らは、少量のラベル付きデータと大量のラベルなしデータのみでモデルをトレーニングする半教師あり歴史再構成タスクを提案します。また、比較再構成ニューラル アーキテクチャである DPDBiReconstructor も開発しました。これは、言語学者の比較手法からの基本的な洞察と組み合わせることで、ラベルのない同族語のセットを活用し、新しいタスクで強力に半教師付きのベースラインを上回るパフォーマンスを発揮します。
ミッション: 不可能な言語モデル
* 紙のアドレス:https://arxiv.org/abs/2401.06416※研究機関:スタンフォード大学、カリフォルニア大学、テキサス大学
* 研究内容: 研究者らは一連の複雑で存在しない言語を合成し、これらの言語を学習する GPT-2 モデルの能力を評価した結果、GPT-2 は英語の学習よりも不可能な言語の学習に優れていることが判明しました。 。
変圧器にとって機密機能が難しいのはなぜですか

* 紙のアドレス:
https://arxiv.org/abs/2402.09963
※研究機関:ドイツ・ザールラント大学
* 研究内容: Transformer アーキテクチャでは、損失状況は入力空間の感度によって制限されます。理論と実践を通じて、この理論は Transformer の学習能力とバイアスに関する幅広い経験的観察を統合できます。
受賞論文の詳細な解釈
次、HyperAI は、モデル アーキテクチャ、データ セット、研究結果、チームという 4 つの側面を導入します。『拡散モデルを使ったOracle Bone Languageの解読』を誰でも理解できるよう徹底的に解説。
この研究では、華中科技大学のBai Xiang氏とLiu Yuliang氏の研究チームが、アデレード大学、安陽師範大学、華南理工大学と協力して、画像ベースの生成モデルを使用して、Oracle の解読用に最適化された条件付き拡散モデル Oracle Bone Script Decipher (OBSD) がトレーニングされました。このモデルは、甲骨碑文の目に見えないカテゴリを条件付き入力として使用して、対応する現代漢字画像を生成し、自然言語処理では解決するのが難しい古代文字認識タスクに新しい方法を提供します。
研究のハイライト:
* 画像生成技術を使用して、古文認識タスクに新しいアプローチを提供します
* OBSD は、ローカル分析サンプリング技術を使用して、文字の複雑なパターンを区別して解釈するモデルの能力を強化します。
* 包括的なアブレーション研究とベンチマークを通じて、デコードにおける OSBD の有効性を証明
この研究で使用したデータセットのダウンロード リンク:
* EVOBC Oracle テキスト進化データ セット:
* HUST-OBS オラクル認識データ セット:
データセット: Oracle 最大のリポジトリを使用し、OCR テクノロジーを標準として使用
提案された OSBD モデルをトレーニングして評価するには、この研究では、HUST-OBS データ セットと EVOBC データ セットを選択しました。これらは Oracle 最大のリポジトリの 1 つであり、1,590 の異なるキャラクターを描いた 7,1698 枚の画像が含まれています。
未知の甲骨の解読には通常、より包括的な専門的検証が必要であることを考慮して、この研究では解読されたスクリプトのみをテストセットとして使用し、評価プロセス全体を簡素化しました。さらに重要なのは、この研究では、テスト セットで選択された文字カテゴリをトレーニング セットから明確に除外し、これまで処理されたことのない文字を解読するためにモデルが使用されたことを確認しました。データセットは 9:1 の比率でトレーニング セットとテスト セットに分割されており、評価のための信頼できるフレームワークを提供します。
さらに、OSBD モデルはイメージ生成の観点からオラクル解読を実行しますが、SSIM などの従来のイメージ生成メトリクスはこのタスクには適していません。したがって、この研究では、成功した解読結果のより客観的な尺度として OCR テクノロジーを使用します。具体的には、研究者らは、モデルの出力を評価するために、ResNet-101 バックボーン ネットワークの単純な分類子を使用して OBS-OCR ツールをカスタマイズし、特に 88,899 の現代漢字カテゴリを含む大規模なデータセットでトレーニングしました。
結果は次のことを示しています カスタマイズされた OCR ツールは 99.87% の認識精度を達成し、解読結果の信頼性が証明されました。同時に、この調査では、さらなる評価のために、オープンソースの中国語 OCR ツール PaddleOCR 1 も広範囲に導入されました。このデュアル OCR メソッドは、甲骨の解読におけるモデルの有効性を強力に保証します。
条件付き拡散モデルに基づいて OBSD モデルを再構築する
この調査では、トレーニング セットを S = {(si, ci) | si は Oracle インスタンス、ci∈C} として表します。つまり、Oracle インスタンスと既知のカテゴリ C の現代中国語文字のセットに対応します。不足している既存の新しい文字形式の提案と一致します。これを達成するには、この研究では、伝播モデルに基づいて、神託文字の画像 X を現代の漢字に変換します。
次の図に示すように、モデルは 2 つの段階に分かれています。
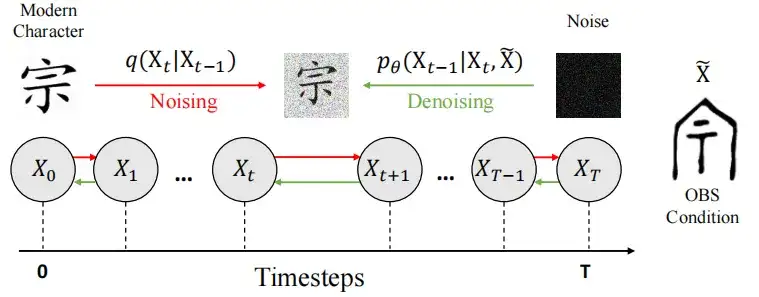
初期段階(ノイズ)では、研究者らは、現代の漢字画像 X0 にノイズを導入し、制御可能なマルコフ連鎖プロセスを使用して純粋なノイズに似た状態に遷移させ、最終的にガウス分布 N (0, I) を形成しました。
ノイズ除去段階では、研究者らは、U-Net アーキテクチャを使用してモデル fθ をトレーニングしてノイズ e を予測し、画像を復元します。また、et 〜 N(0, I) を使用してランダム性を導入し、モデルが生成する最終的なデコード結果の多様性を高めます。ノイズ除去された画像 X0 を生成することです。
これに基づいて、OBSD モデルは、次の図に示すように、初期解読段階 (Initial Decipherment) とゼロショット学習段階 (Zero-shot Refinement) を統合して、解読精度を向上させます。
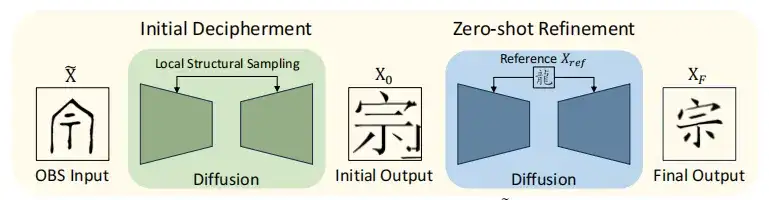
まず、初期画像 X0 をオラクル画像の条件付き拡散で近似します。改善プロセス中にテキスト構造に関する洞察を活用して、現代の漢字をベンチマークするテキスト結果 XF が最終的に生成されました。
LSS の概念を導入して、古代文字と現代漢字の間のモデルの接続能力を強化
ただし、実際のアプリケーションの場合、この方法でトレーニングされたモデルは、対応する現代中国語の文字を正確に生成できず、代わりに、下の図に示すように、多数のランダムな断片に基づいて意味不明の文字を形成します。

研究者らは、この結果の理由として、拡散モデルは主に自然画像を生成するように設計されているが、甲骨碑文を解読する過程で、甲骨碑文の画像と現代の漢字の構造に大きな違いがあるためではないかと推測している。このため、標準の条件付き拡散モデルでは、ターゲットの現代漢字を正確に再構築できなくなります。
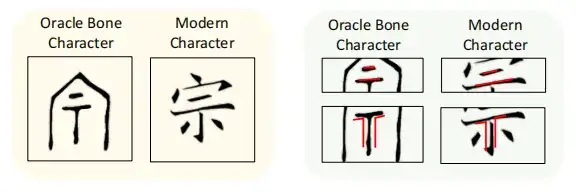
この課題に対処するために、この研究では、局所構造サンプリング (LSS) の概念が導入されました。Oracle の部分部首構造を対応する現代中国語の文字にマッピングする方法を拡散モデルが学習できるようにすることで、古代文字と現代中国語のモデルの接続能力が強化されます。この研究ではまた、古代の漢字から現代の漢字までかなりの構造的進化があったものの、一部の局所的な構造は保存されていることも判明した。
拡散モデルが局所構造の特性を学習できるようにするために、LSS モジュールはスライディング ウィンドウ法を使用して、ターゲットの現代漢字画像 X0∈RHxWx3 と対応する甲骨画像 X∈RHxWx3 を D 個のサイズの小さなブロックに分割します。 p×p、X( d) および Xt(D)∈Rp×p×3、D=1,2…D、p=64 として表されます。ここで、Xt は、タイム ステップ t でガウス ノイズ ϵt が追加された現代のテキスト画像を表します。
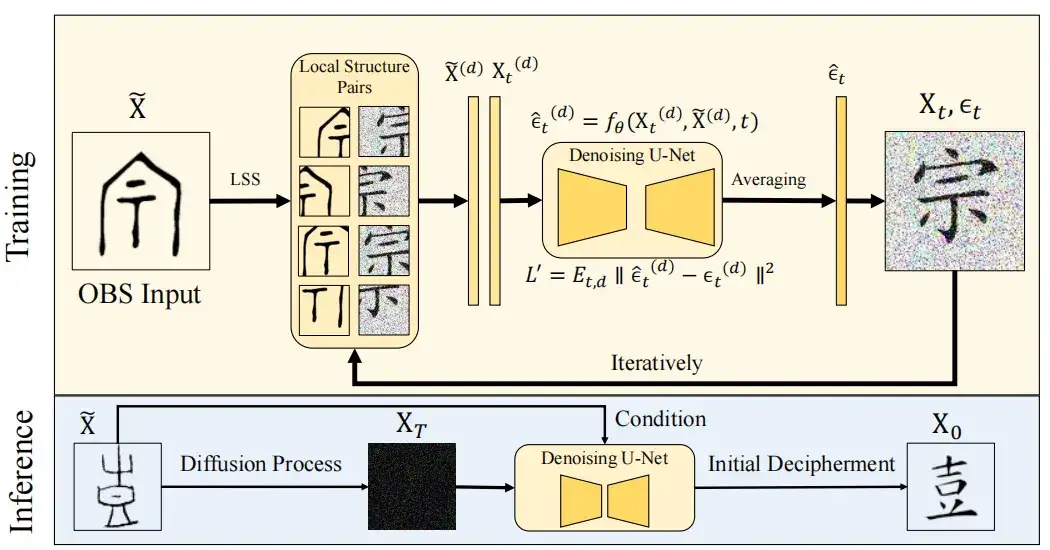
この方法に基づいて、このモデルは、甲骨の局所的な構造と漢字の構造の微妙な違いを学習することで、パッチを反復して最適化できます。この研究方法は、ノイズ除去を完了せずに、各タイム ステップ t で隣接する領域間のオーバーラップを平均して、共有領域内で均一な効果を保証するという点で独特です。同時に、この研究ではエッジの違いを回避し、スムーズなサンプリングプロセスにおける領域遷移を通じて再構成された画像の視覚的な一貫性を維持します。
ゼロサンプル学習手法を導入して、文字構造を理解するモデルの能力を強化します
ローカル構造サンプリングを使用して現代の漢字を生成する方法はある程度進歩していますが、初期の解読作業では依然として構造の歪みやアーティファクトなどの重大な障害に遭遇しています。

これは、複数の Oracle インスタンスを現代の漢字イメージにマッピングする、多対 1 のトレーニング方法が使用されているためです。キャラクターの進化を捉える際に混乱と不正確さを引き起こすまた、現代の漢字のサンプルが限られているため、不完全な構造が表示されます。
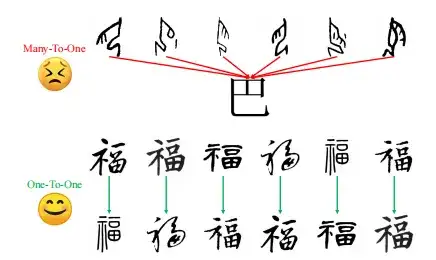
これらの課題を克服するには、この研究では、さまざまな現代漢字の書き方を使用することで、モデルの構造の理解を向上させるゼロショット学習戦略を提案します。実際の運用では、この研究では 20 種類の現代漢字フォントを使用してモジュールを 1 対 1 でトレーニングし、それによって異なる現代漢字の書体間の構造変化を学習し、モデルの文字構造の理解を強化しました。
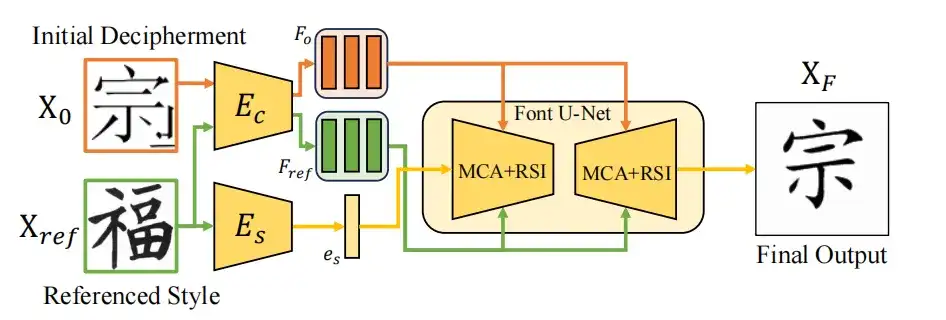
以下の図に示すように、このゼロショット学習方法はユニバーサル フォント スタイル変換フレームワークに基づいており、デュアル エンコーダー システムを使用して、コンテンツの整合性を維持しながら、ソース フォント イメージ X0 のスタイルをターゲット スタイル Xref に適合させます。スタイル エンコーダ Es は Xref からスタイル特徴 es を抽出し、コンテンツ エンコーダ Ec は Xo と Xref を処理してマルチスケール コンテンツ特徴 Fo を取得します。これは、マルチスケール コンテンツ アグリゲーション (MCA) と参照構造を使用して Font U-Net によって洗練されます。トレーニングが完了すると、ゼロショット学習モジュールを直接使用して、拡散モデルによって生成された結果を最適化できます。
OSBD性能評価:複数の評価基準において認識精度が最も高い
OSBD のパフォーマンスを定量的に評価するために、この研究では、シングルラウンド復号化とマルチラウンド復号化という 2 つの異なる評価基準を使用しました。オラクル解読用に特別に設計されたツールがないため、この研究では、主要な画像間変換手法をこのタスクに適応させる比較フレームワークを採用しています。
具体的には、これらの手法には、Pix2Pix、CycleGAN、DRIT++ などの GAN ベースの手法や、CDE、Palette、BBDM などの拡散モデルが含まれます。この設定により、OBSD メソッドを最先端の画像変換のコンテキストで評価できるようになり、公平で一貫したトレーニングおよびテスト条件が保証されます。
1 回の復号化評価で、OBSD には、オラクルをクラッキングする際の修正された画像から画像への変換方法に比べて大きな利点があります。以下に示すように。
OBS-OCR と PaddleOCR を介して OSBD によって達成されるトップ 1 の精度は、それぞれ 41.0% と 30.0% であり、他の方法よりも優れています。ランキングが上がるにつれて、精度が明らかに向上する傾向が見られ、上位 500 位の精度では、OSBD は 64.5% の OBS-OCR 認識精度に達します。
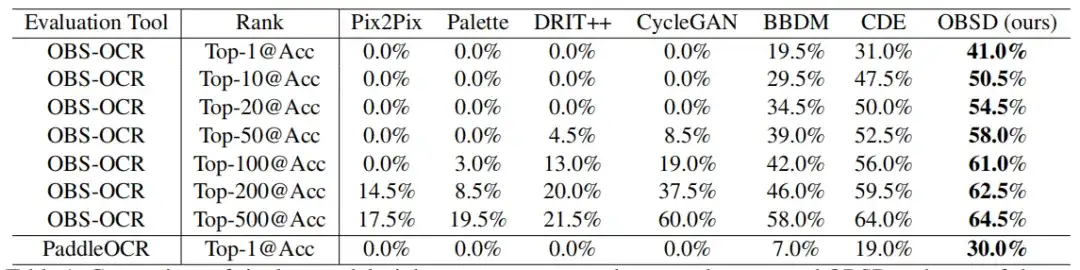
この場合、すべての GAN ベースのメソッド (Pix2Pix、Palette、DRIT++、CycleGAN など) が最悪の有効性を示し、トップ 1 の精度が 0% であることに注意してください。これは、GAN 自体がオラクルの解読に必要な複雑かつ微妙なマッピング関係を捕捉することが難しいという事実によるものと考えられます。
複数回の復号化評価で、OBS-OCR の成功率は、何度か試行するうちに徐々に向上していきました。以下の図に示すように、インジケーターの成功率は 41.0% から 80.0% まで増加し続けています。
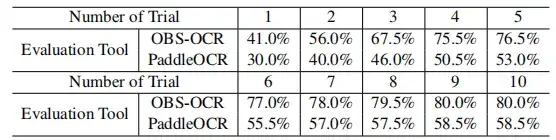
PaddleOCR インジケーターの成長傾向も上昇傾向を示し、30.0% から始まり、最終的に 58.5% に達しました。これらの結果は、継続的な試行によって段階的な改善が達成できることを検証します。
各コンポーネントの影響をさらに調べるために、この研究では、LSS モジュールとゼロショット学習に焦点を当てたアブレーション研究も実施しました。この結果は、基本的な条件付き拡散モデルのみを使用したオラクルの解読には限界があり、精度が大幅に低いことを示しています。具体的には、拡張を行わずに拡散モデルをトレーニングすると、本質的に意味のない出力が得られます。
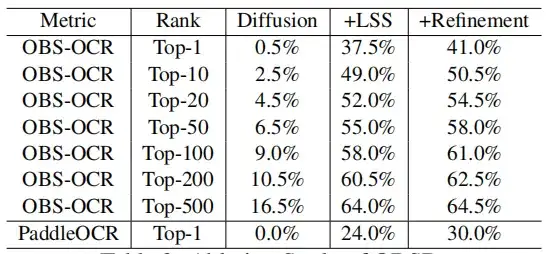
LSSモジュールを導入することで、OBS-OCRの認識精度は37.5%まで向上しており、PaddleOCRは24%に改良されました。 LSS でゼロショット学習モジュールを使用すると、OBS-OCR と PaddleOCR のトップ 1 精度がさらに向上し、それぞれ 3.5% と 6% が追加されます。
最後に、この研究では、さまざまな画像間の変換モデルに関する定性的研究も実施されています。
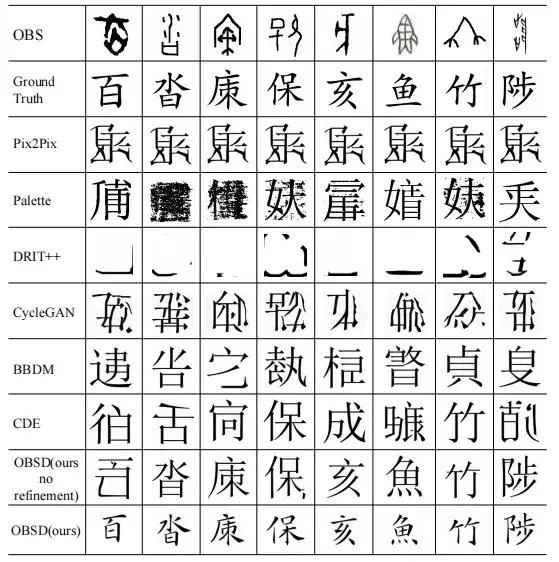
その結果、OBSD方式で甲骨文字を入力すると、現代漢字を最も正確に解読でき、甲骨文字の複雑な詳細を識別できることがわかり、OSBDの有効性だけでなく、専門家としての可能性も浮き彫りとなった。甲骨文字言語を解読するためのツール。
AI+Oracle の先駆者として輝く研究チーム
華中科技大学は、古代文字研究、特に甲骨碑文の研究の分野で常に時代の最前線に立っており、中国で最初に独立した甲骨碑文図書館を設立した大学の一つです。人工知能技術の急速な発展に伴い、インテリジェントなテキストおよび画像処理は、かつて白翔氏と劉玉良氏の研究チームに代表される華中科技大学の注目の分野の1つとなった。再びテキストと画像のインテリジェンスの先駆者およびリーダーになります。
全国優秀青少年および IAPR フェローとして、Bai Xiang 教授は現在、華中科技大学ソフトウェア学部長であり、湖北省マシン ビジョンおよびインテリジェント システム工学研究センターの所長を務めています。以前、Bai Xiang 教授が率いる Monkey マルチモーダル大規模モデルは、OpenCompass のオープン ソース バージョンの大規模モデルの信頼できるリストで 1 位にランクされました。その結果は、武漢の大手ソフトウェア企業の革新的な製品に適用されています。
Bai Xiang チームの中心メンバーとして、Liu Yuliang は第 9 回中国科学技術協会青少年人材促進プロジェクトに選ばれ、テキストと画像のインテリジェンスに重点を置き、ドキュメントのインテリジェント分析、ビジュアルおよびナチュラルの分野で一連の成果を達成しました。言語理解、およびマルチモーダルな大規模モデルの結果。
技術の発展が徐々に成熟する中、Bai Xiang教授、Liu Yuliang教授、Yi Ran教授は、甲羅骨碑文の研究でより大きな進歩を遂げるために、甲骨碑文のトップ機関の1つである安養師範大学との緊密な協力を行うことを選択しました。中国での研究。 2018年、教育省の安養師範大学オラクル情報処理重点研究室は、オラクルの文献データベース、書誌データベース、フォントデータベースを統合したオラクルのビッグデータプラットフォーム「ying Qiwen」のプロジェクト構築を承認された。研究所によって構築された深淵は全世界に開かれています。これは、世界で最も完全で、標準化され、権威のある Oracle データ プラットフォームです。その始まりは、オラクル研究がインテリジェンスの時代に突入したことを示しています。
この記事の責任著者の 1 人である Liu Yongge 氏が、安養師範大学教育部 Oracle Information Processing 主要研究室の所長であることは注目に値します。
甲骨碑文に関する研究成果をより適切に記録し、広めるために、同研究所は2023年の2つの主要なイベントに焦点を当てる予定である。 一方で、中国考古学研究所の安養ワークステーションであるテンセントSSVと提携する。社会科学院と安養市文化財局が共同で「甲骨碑文」を立ち上げる 「グローバルデジタル返還計画」は数億画素のカメラを使用し、デジタル空間で物理的な甲骨の高忠実度の復元と保護を実現する。一方、同研究所とテンセントが共同で立ち上げた「グレートオラクル」アプレットは、オラクルを一般の人々に近づけた。
偶然にも、学者が甲骨結合に関する情報を見つけやすくし、研究の初期データ収集段階での時間を短縮するために、復丹大学出土文書・古代碑文研究センターの博士課程学生、楊毅氏、黄波氏、鄭明輝氏は、2023年初めに甲骨結合情報データベース「朱雨連珠」を共同作成した。「Oracle Bone Inscriptions Collection」の出版以来、多くの学者による6,700件を超える甲骨碑文の結果が集約されており、学術コミュニティが甲骨碑文の主な結果を検索するためのオンラインツールとなっているだけでなく、多くの人々を魅了しています。 「象牙の塔」の外にいる多くの甲骨碑文愛好家は、甲骨片の調査に参加し、誤った情報や新しい甲骨結合情報を提供する機会を得ることができます。
ビッグデータ、クラウドコンピューティング、人工知能などのデジタルテクノロジーの助けにより、オラクルの研究は新たな時代に入ったことがわかります。研究が深まるにつれ、近い将来、この「不人気の秘密」がさらに多くの暗号に解読され、他の古代文字を解読するための非常に重要な参考になると私は信じています。








